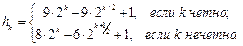|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Задачи сортировки таблиц и массивов
Из сравнения эффективности алгоритмов линейного и бинарного поиска видно, насколько для ускорения поиска в массиве (или таблице) важно, чтобы значения ключей располагались в порядке возрастания (или, наоборот, в порядке убывания, если это почему-либо удобнее в конкретном случае). Если предполагается выполнять поиск по одному и тому же массиву много раз, то имеет смысл один раз потратить время на перестановку записей в нужном порядке, чтобы потом можно было применять быстрый бинарный поиск вместо медленного линейного. Процедура перестановки записей таблицы в порядке возрастания значений заданного ключа называется сортировкой [1] таблицы. Для массива сортировка – это перестановка его элементов в порядке возрастания. Процедура сортировки в большинстве случаев выполняется как предварительная операция для ускорения последующего поиска, однако в некоторых случаях сортировка полезна и сама по себе, безотносительно к поиску. Например, часто нужно просто вывести данные на печать или на экран в упорядоченном виде (скажем, распечатать список студентов группы по алфавиту). Еще одна задача, решаемая с помощью сортировки, – проверка, содержатся ли в массиве совпадающие значения и какие именно. После сортировки такие значения окажутся стоящими рядом, и их можно будет выявить за один проход по массиву. В настоящее время известно много алгоритмов выполнения сортировки. Их разнообразие определяется особенностями конкретных задач. В данном разделе описаны наиболее важные из алгоритмов сортировки таблиц, представленных массивом в оперативной памяти компьютера. В одном из подразделов рассматриваются также особенности сортировки файлов. Простые алгоритмы сортировки К простым алгоритмам относятся несколько широко известных алгоритмов, основанных на простых и очевидных идеях. В том случае, когда программист, незнакомый с теорией, сталкивается с необходимостью отсортировать массив, он обычно самостоятельно переоткрывает один из этих алгоритмов. Алгоритм пузырька (BubbleSort) Идея алгоритма заключается в следующем. Сравним элементы массива с индексами 1 и 2. Если первый больше второго, то поменяем эти элементы местами. Затем таким же образом сравним (и, если нужно, переставим) элементы с индексами 2 и 3, потом 3 и 4 и т.д. После сравнения элементов (n–1) и n первый проход алгоритма завершается. Можно гарантировать, что после этого прохода максимальный элемент массива находится на последнем месте (т.е. имеет индекс n). На втором проходе сравниваем пары 1 и 2, 2 и 3, ... (n–2) и (n–1). Далее аналогично. После n–1 прохода все элементы займут свои законные места. У многих программистов появляется желание сократить число проходов, отмечая с помощью специального флажка, были ли сделаны какие-либо перестановки на очередном проходе. Если ни одной перестановки за весь проход не было, то массив, очевидно, уже отсортирован и работу алгоритма можно завершить досрочно. Однако такое усовершенствование редко дает заметный выигрыш. Нетрудно показать, что для массива, заполненного случайным образом, с вероятностью 75 % все равно будут выполнены все проходы алгоритма. Алгоритм выбора (SelectionSort) Идея этого алгоритма еще проще. Найдем минимальный элемент массива и поменяем его местами с первым элементом. Затем повторим ту же процедуру, начиная со второго элемента массива, затем начиная с третьего и т.д. После n–1 проходов все элементы станут на места. Алгоритм вставок (InsertionSort) Идея заключается в следующем. Пусть к некоторому моменту работы алгоритма первые k элементов массива уже отсортированы, т.е. расположены по возрастанию. На очередном проходе постараемся добиться, чтобы стали отсортированными k+1 элементов. Для этого запомним значение элемента ak+1 в рабочей переменной r и будем сравнивать r со значениями элементов ak, ak–1, ak–2 и т.д. Если значение сравниваемого элемента больше r, то этот элемент перемещается на одну позицию правее. Сравнения продолжаются, пока не будет найдено место, куда должен быть помещен элемент r (это случится либо когда очередной сравниваемый элемент меньше или равен r, либо когда мы дойдем до начала массива). Таким образом, на очередном проходе отсортированная часть массива удлиняется на 1 элемент. Начав со значения k = 1, можно за n–1 проход отсортировать весь массив. Алгоритм вставок можно немного улучшить, если выбирать место для вставки k+1-го элемента не последовательным просмотром элементов от k до 1, а бинарным поиском по уже отсортированной части масива (т.е. сравнить r с элементом j = (k+1) div 2, затем продолжить поиск на одном из интервалов [1.. j–1] или [j+1.. k] и т.д.). Этот подход, называемый алгоритмом бинарных вставок, позволяет существенно сократить число сравнений, но, к сожалению, не влияет на число перестановок. Общая характеристика простых алгоритмов Теоретическое и экспериментальное сравнение трех описанных алгоритмов друг с другом показывает, что алгоритм пузырька является самым медленным из них. Это можно объяснить большим числом перестановок элементов: для того, чтобы всего лишь поменять местами два соседних элемента, нужно выполнить целых 3 присваивания. Алгоритмы выбора и вставки работают в 1, 5 – 2 раза быстрее и показывают схожие друг с другом результаты по скорости, за исключением одного важного случая. Если исходный массив оказывается уже «почти» сортированным (т.е. лишь небольшое количество элементов расположены не там, где им следовало бы быть), то алгоритм вставок оказывается во много раз быстрее других. В том крайнем случае, когда исходный массив полностью сортирован, алгоритм вставок выполняет всего лишь один проход по массиву, т.е. работает за линейное время. Для двух других алгоритмов факт сортированности может повлиять на уменьшение числа перестановок, но практически не влияет на число сравнений. Этим преимуществом алгоритма вставок не стоит пренебрегать, поскольку на практике достаточно часто встречается ситуация, когда нужно повторно отсортировать массив, который ранее уже был сортирован, но после этого претерпел небольшие изменения, нарушившие порядок элементов. Однако, подсчитав число итераций циклов, можно показать, что для всех простых алгоритмов сортировки имеет место оценка эффективности T(n) = O(n2) как для максимального, так и для среднего времени. Плохо это или хорошо? Квадратичная оценка была бы хороша для алгоритма, который должен выполняться, скажем, раз в сутки или еще реже, при этом для значений n, не превышающих нескольких сотен или, в крайнем случае, тысяч. Однако для задач сортировки характерна гораздо большая частота выполнения, а зачастую и гораздо большие значения n. Уже для n = 100 000 квадратичный алгоритм потребует выполнить около 10 миллиардов итераций, что вряд ли можно считать приемлемым. Поэтому в следующих параграфах будут рассмотрены усовершенствованные алгоритмы, значительно более сложные, но зато обеспечивающие во много раз большую скорость сортировки. Алгоритм Шелла (ShellSort) Идея этого алгоритма в следующем. Разобьем элементы сортируемого массива на h цепочек, каждая из которых состоит из элементов, отстоящих друг от друга на расстояние h (здесь h – произвольное натуральное число). Первая цепочка будет содержать элементы a1, ah+1, a2h+1, a3h+1 и т.д., вторая – a2, ah+2, a2h+2 и т.д., последняя цепочка – ah, a2h, a3h и т.д. Отсортируем каждую цепочку как отдельный массив, используя для этого метод простых или бинарных вставок. Затем выполним все вышеописанное для ряда убывающих значений h, причем последний раз – для h = 1. Очевидно, массив после этого окажется сортированным. Неочевидно, что все проходы при h > 1 не были пустой тратой времени. Тем не менее, оказывается, что дальние переносы элементов при больших h настолько приближают массив к сортированному состоянию, что на последний проход остается очень мало работы. Большое значение для эффективности алгоритма Шелла имеет удачный выбор убывающей последовательности значений h. Казалось бы, самая естественная убывающая последовательность чисел это степени двойки: …, 64, 32, 16, 8, 4, 2, 1. Сам автор алгоритма Дональд Шелл первоначально предложил использовать именно эти числа. На самом же деле выбор этой последовательности – один из самых неудачных! Пусть, например, в исходном массиве все нечетные по номеру элементы отрицательны, а четные – положительны. Как будет выглядеть такой массив после выполнения всех проходов, кроме последнего (с h = 1)? Поскольку все использованные h были четными, ни один элемент не мог переместиться с четного места на нечетное и наоборот. Таким образом, все нечетные элементы по-прежнему будут отрицательны (хотя и отсортированы между собой), а четные – положительны. Подобный массив трудно назвать «почти сортированным»! На последний проход алгоритма вставки остается слишком много работы. Чтобы избежать подобной неприятности, желательно, чтобы при соседних значениях k значения hk не были кратны друг другу. В литературе обычно рекомендуется использовать одну из двух последовательностей: hk+1 = 3hk+1 или hk+1 = 2hk+1. В обоих случаях в качестве начального hk выбирается такое значение из последовательности, при котором все сортируемые цепочки имеют длину не меньше 2. Чтобы воспользоваться, например, первой из этих формул, надо сначала положить h1: =1, а затем в цикле увеличивать значение h по формуле hk+1: = 3*hk+1, пока для очередного hk не будет выполнено неравенство hk ³ (n–1) div 3. Это значение hk следует использовать на первом проходе алгоритма, а затем можно получать следующие значения по обратной формуле: hk–1: = (hk–1) div 3, вплоть до h1=1. Для каждой из этих двух последовательностей время работы в худшем случае оценивается как Tмакс(n) = O(n3/2). Это значительно лучше, чем O(n2) для простых алгоритмов. Для среднего времени работы известны только эмпирические оценки, показывающие, что время растет примерно как O(n1.25) или O(n1.3). Ряд авторов на основе теоретического анализа сортировки Шелла предложили использовать более сложные последовательности, повышающие эффективность алгоритма. Одной из лучших считается последовательность, предложенная Р.Седжвиком:
Доказано, что при выборе hk по Седжвику максимальное время работы алгоритма есть O(n4/3). Среднее время по эмпирическим оценкам равно примерно O(n7/6). На практике удобно раз и навсегда вычислить достаточное количество членов последовательности Седжвика (вот они: 1, 5, 19, 41, 109, 209, 505, 929, 2 161, 3 905, 8 929, 16 001, 36 289, 64 769, 14 6305, 260 609, 587 521, 1 045 505, ...), затем по заданному n выбрать такое k, при котором hk > = (n–1) div 3, а далее в цикле выбирать значения последовательности hk по убыванию k. Популярное:
|
Последнее изменение этой страницы: 2016-04-11; Просмотров: 1009; Нарушение авторского права страницы