
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Проверка правильности операторов
Задачи проверки правильности операторов: 1) выяснить, все ли переменные, встречающиеся в операторах, описаны; 2) установить соответствие типов в операторе присваивания слева и справа от символа «: =»; 3) определить, является ли выражение Е в операторах условия и цикла булевым. Данные задачи решаются путем включения в правило S ранее рассмотренной процедуры checkid, а также новых процедур eqtype и eqbool, имеющих следующий вид: procedure eqtype; begin outst(t2); outst(t1); if t1< > t2 then ERR end; procedure eqbool; begin outst(t); if t< > bool then ERR end;
Правило S с учетом процедур СеА примет вид:
S® I < checkid> : = E < eqtype> | if E < eqbool> then S else S while E < egbool> do S | write (E) | read (I < checkid> ) Генерация кода Результатом СиА должно быть некоторое внутреннее представление исходной цепочки лексем, которое отражает ее синтаксическую структуру. Программа в таком виде может либо транслироваться в объектный код, либо интерпретироваться. Генерация объектного кода - это перевод компилятором внутреннего представления программы в цепочку символов выходного языка. Генерация объектного кода порождает результирующую объектную программу на языке ассемблера или непосредственно на машинном языке (в машинных кодах). Внутреннее представление программы может иметь любую структуру в зависимости от реализации компилятора, в то время как результирующая программа всегда представляет собой линейную последовательность команд. Поэтому генерация объектного кода (объектной программы) в любом случае должна выполнять действия, связанные с преобразование сложных синтаксических структур в линейные цепочки.
Формы внутреннего представления программы Возможны различные формы внутреннего представления синтаксических конструкций исходной программы в компиляторе. Но формы представления, используемые на этапах синтаксического анализа, оказываются неудобными при генерации и оптимизации объектного кода. Поэтому перед оптимизацией и непосредственно перед генерацией объектного кода внутреннее представление программы может преобразовываться в одну из соответствующих форм записи. Выделяют следующие общепринятые способы внутреннего представления программы: 1) многоадресный код с явно именуемым результатом (тетрады); 2) многоадресный код с неявно именуемым результатом (триады); 3) синтаксические деревья; 4) постфиксная запись; 5) машинные команды или ассемблерный код. Тетрады Тетрады представляют собой запись операций в форме из четырех составляющих: операция, два операнда и результат операции. Например, тетрады могут выглядеть так: < операция> (< операнд1>, < олеранд2>.< результат> ). Тетрады представляют собой линейную последовательность команд. При вычислении выражения, записанного в форме тетрад, они вычисляются одна за другой последовательно. Каждая тетрада в последовательности вычисляется так: операция, заданная тетрадой, выполняется над операндами и результат ее выполнения помещается в переменную, заданную результатом тетрады. Если какой-то из операндов (или оба операнда) в тетраде отсутствует (например, если тетрада представляет собой унарную операцию), то он может быть опущен или заменен пустым операндом (в зависимости от принятой формы записи и ее реализации). Результат вычисления тетрады никогда опущен быть не может, иначе тетрада полностью теряет смысл. Порядок вычисления тетрад может быть изменен, ни только если допустить наличие тетрад, целенаправленно изменяющих этот порядок (например, тетрады, вызывающие переход па несколько шагов вперед или назад при каком-то условии). Тетрады представляют собой линейную последовательность, а потому для них несложно написать тривиальный алгоритм, который будет преобразовывать Тетрады требуют больше памяти для своего представления, чем триады, они также не отражают явно взаимосвязь операций между собой. Кроме того, есть сложности с преобразованием тетрад в машинный код, так как они плохо отображаются в команды ассемблера и машинные коды, поскольку в наборах команд большинства современных компьютеров редко встречаются операции с тремя операндами. Например, выражение A: =B*C+D-B*10, записанное в виде тетрад, будет иметь вид: * ( B, C, T1 ) + ( T1, D, T2 ) * ( В, 10, ТЗ ) - ( Т2, ТЗ, Т4) : = ( Т4, 0, А ) Здесь все операции обозначены соответствующими знаками (при этом присвоение также является операцией). Идентификаторы Т1, …, Т4 обозначают временные переменные, используемые для хранения результатов вычисления тетрад. Следует обратить внимание, что в последней тетраде (присвоение), которая требует только одного операнда, в качестве второго операнда выступает незначащий операнд «0».
Триады Триады представляют собой запись операций в форме из трех составляющих: операция и два операнда. Например, триады могут иметь вид: < операция> (< операнд1>, < операнд2> ). Особенностью триад является то, что один или оба операнда могут быть ссылками на другую триаду в том случае, если в качестве операнда данной триады выступает результат выполнения другой триады. Поэтому триады при записи последовательно нумеруют для удобства указания ссылок одних триад на другие (в реализации компилятора в качестве ссылок можно использовать не номера триад, а непосредственно ссылки в виде указателей — тогда при изменении нумерации и порядка следования триад менять ссылки не требуется). Триады представляют собой линейную последовательность команд. При вычислении выражения, записанного в форме триад, они вычисляются одна за другой последовательно. Каждая триада в последовательности вычисляется так: операция, заданная триадой, выполняется над операндами, а если в качестве одного из операндов (или обоих операндов) выступает ссылка на другую триаду, то берется результат вычисления той триады. Результат вычисления триады нужно сохранять во временной памяти, так как он может быть затребован последующими триадами. Если какой-то из операндов в триаде отсутствует (например, если триада представляет собой унарную операцию), то он может быть опущен или заменен пустым операндом (в зависимости от принятой формы записи и ее реализации). Порядок вычисления триад, как и для тетрад, может быть изменен, но только если допустить наличие триад, целенаправленно изменяющих этот порядок (например, триады, вызывающие переход на несколько шагов вперед или назад при каком-то условии). Триады представляют собой линейную последовательность, а потому для них несложно написать тривиальный алгоритм, который будет преобразовывать последовательность триад в последовательность команд результирующей программы (либо последовательность команд ассемблера). В этом их преимущество перед синтаксическими деревьями. Однако здесь требуется также и алгоритм, отвечающий за распределение памяти, необходимой для хранения промежуточных результатов вычисления, так как временные переменные для этой цели не используются. В этом отличие триад от тетрад. Так же как и тетрады, триады не зависят от архитектуры вычислительной системы, на которую ориентирована результирующая программа. Поэтому они представляют собой машинно-независимую форму внутреннего представления программы. Триады требуют меньше памяти для своего представления, чем тетрады, они также явно отражают взаимосвязь операций между собой, что делает их применение удобным. Необходимость иметь алгоритм, отвечающий за распределение памяти для хранения промежуточных результатов, не является недостатком, так как удобно распределять результаты не только по доступным ячейкам временной памяти, но и по имеющимся регистрам процессора. Это дает определенные преимущества. Триады ближе к двухадресным машинным командам, чем тетрады, а именно эти команды более всего распространены в наборах команд большинства современных компьютеров. Например, выражение A: =B*C+D-B*10. записанное в виде триад, будет иметь вид: 1) * (B, C) 2) + (^1, D) 3) * (B, 10) 4) – (^2, ^3) 5): = (A, ^4) Здесь операции обозначены соответствующим знаком (при этом присвоение также является операцией), а знак ^ означает ссылку операнда одной триады на результат другой.
Синтаксические деревья Результатом синтаксического разбора является дерево вывода. Оно содержит массу избыточной информации, которая для дальнейшей работы компилятора не требуется. Эта информация включает в себя все нетерминальные символы, содержащиеся в узлах дерева, — после того как дерево построено, они не несут никакой смысловой нагрузки и не представляют для дальнейшей работы интереса. В синтаксическом дереве внутренние узлы (вершины) соответствуют операциям, а листья представляют собой операнды. Как правило, листья синтаксического дерева связаны с записями в таблице идентификаторов. Структура синтаксического дерева отражает синтаксис языка программирования, на котором написана исходная программа. Синтаксические деревья могут быть построены компилятором для любой части входной программы. Не всегда синтаксическому дереву должен соответствовать фрагмент кода результирующей программы — например, возможно построение синтаксических деревьев для декларативной части языка. В этом случае операции, имеющиеся в дереве, не требуют порождения объектного кода, но несут информацию о действиях, которые должен выполнить сам компилятор над соответствующими элементами. В том случае, когда синтаксическому дереву соответствует некоторая последовательность операций, влекущая порождение фрагмента объектного кода, говорят о дереве операций. Дерево операций можно непосредственно построить из дерева вывода, порожденного синтаксическим анализатором. Для этого достаточно исключить из дерева вывода цепочки нетерминальных символов, а также узлы, не несущие семантической (смысловой) нагрузки при генерации кода. Примером таких узлов могут служить различные скобки, которые меняют порядок выполнения операций и операторов, но после построения дерева никакой смысловой нагрузки не несут, так как им не соответствует никакой объектный код. Алгоритм преобразования дерева семантического разбора в дерево операций можно представить следующим образом. Шаг 1 Если в дереве больше не содержится узлов, помеченных нетерминальными символами, то выполнение алгоритма завершено; иначе — перейти к шагу 2. Шаг 2 Выбрать крайний левый узел дерева, помеченный нетерминальным символом грамматики и сделать его текущим. Перейти к шагу 3. Шаг 3 Если текущий узел имеет только один нижележащий узел, то текущий узел необходимо удалить из дерева, а связанный с ним узел присоединить к узлу вышележащего уровня (исключить из дерева цепочку) и вернуться к шагу 1; иначе — перейти к шагу 4. Шаг 4 Если текущий узел имеет нижележащий узел (лист дерева), помеченный терминальным символом который не несет семантической нагрузки, тогда этот лист нужно удалить из дерева и вернуться к шагу 3; иначе - перейти к шагу 5. Шаг 5 Если текущий узел имеет один нижележащий узел (лист дерева), помеченный терминальным символом, обозначающим знак операции, а остальные узлы помечены как операнды, то лист, помеченный знаком операции, надо удалить из дерева, текущий узел пометить этим знаком операции и перейти к шагу 1; иначе — перейти к шагу 6. Шаг 6 Если среди нижележащих узлов для текущего узла есть узлы, помеченные нетерминальными символами грамматики, то необходимо выбрать крайний левый среди этих узлов, сделать его текущим узлом и перейти к шагу 3; иначе — выполнение алгоритма завершено. Пусть в результате синтаксического разбора получено дерево разбора для цепочки (a+a)*b, имеющее следующий вид:
Рисунок 4.7 Дерево разбора
В результате применения алгоритма преобразования деревьев синтаксического разбора в дерево операций к дереву, представленному на рис. 4.7, получим дерево операций, представленное на рис. 4.8.
Рисунок 4.8 – Дерево операций
Польская инверсная запись Польская инверсная запись — это постфиксная запись операций. Она была предложена польским математиком Я. Лукашевичем, откуда и происходит ее название. В этой записи знаки операций записываются непосредственно за операндами. По сравнению с обычной (инфиксной) записью операций в польской записи операнды следуют в том же порядке, а знаки операций — строго в порядке их выполнения. Тот факт, что в этой форме записи все операции выполняются в том порядке, в которой они записаны, делает ее чрезвычайно удобной для вычисления выражений на компьютере. Польская запись не требует учитывать приоритет операций, в ней не употребляются скобки, и в этом ее основное преимущество. Она чрезвычайно эффективна в тех случаях, когда для вычислений используется стек. Ниже будет рассмотрен алгоритм вычисления выражений в форме обратной польской записи с использованием стека. Главный недостаток обратной польской записи также проистекает из метода вычисления выражений в ней: поскольку используется стек, то для работы с ним всегда доступна только верхушка стека, а это делает крайне затруднительной оптимизацию выражений в форме обратной польской записи. Практически выражения в форме обратной польской записи почти не поддаются оптимизации. Но там, где оптимизация вычисления выражений не требуется или не имеет большого значения, обратная польская запись оказывается очень удобным методом внутреннего представления программы. Перевод в ПОЛИЗ выражений. Пример Для выражения в обычной (инфиксной записи) a*(b+c)-(d-e)/f ПОЛИЗ будет иметь вид: abc+*de-f/-. Справедливы следующие формальные определения. Определение Если Е является единственным операндом, то ПОЛИЗ выражения Е – это этот операнд. Определение ПОЛИЗ выражения Е1 q Е2, где q - знак бинарной операции, Е1 и Е2 – операнды для q, является запись Определение ПОЛИЗ выражения qЕ, где q - знак унарной операции, а Е – операнд q, есть запись Определение ПОЛИЗ выражения (Е) есть ПОЛИЗ выражения Е.
Перевод в ПОЛИЗ операторов. Каждый оператор языка программирования может быть представлен как n-местная операция с семантикой, соответствующей семантике оператора. Оператор присваивания I: =E в ПОЛИЗе записывается: IE: =,
где «: =» - двуместная операция, I, E – операнды операции присваивания; I – означает, что операндом операции «: =» является адрес переменной I, а не ее значение. Пример Оператор x: =x+9 в ПОЛИЗе имеет вид: x x 9 +: =. Оператор перехода в терминах ПОЛИЗа означает, что процесс интерпретации необходимо продолжить с того элемента ПОЛИЗа, который указан как операнд операции перехода. Чтобы можно было ссылаться на элементы ПОЛИЗа, будем считать, что все они пронумерованы, начиная с единицы (например, последовательные элементы одномерного массива). Пусть ПОЛИЗ оператора, помеченного меткой L, начинается с номера p, тогда оператору безусловного перехода goto L в ПОЛИЗе будет соответствовать:
p!, где! – операция выбора элемента ПОЛИЗа, номер которого равен p.
Условный оператор. Введем вспомогательную операцию – условный переход «по лжи» с семантикой if (not B) then goto L. Это двуместная операция с операндами B и L. Обозначим ее! F, тогда в ПОЛИЗе она будет записываться:
B p ! F, где p – номер элемента, с которого начинается ПОЛИЗ оператора, помеченного меткой L.
С использованием введенной операции условный оператор if B then S1 else S2 в ПОЛИЗе будет записываться:
B p1 ! F S1p2 ! S2, где p1 – номер элемента, с которого начинается ПОЛИЗ оператора S2, а p1 – оператора, следующего за условным оператором.
Пример ПОЛИЗ оператора if x> 0 then x: =x+8 else x: =x-3 представлен в таблице 4.3
Таблица 4.3 – ПОЛИЗ оператора if
Оператор цикла. С учетом введенных операций оператор цикла while B do S в ПОЛИЗе будет записываться:
B p1 ! F S po!, где po – номер элемента, с которого начинается ПОЛИЗ выражения B, а p1 – оператора, следующего за данным оператором цикла.
Операторы ввода и вывода языка М одноместные. Пусть R – обозначение операции ввода, а W – обозначение операции вывода, тогда оператор read(I) в ПОЛИЗе запишется как I R, а оператор write(E) – E W. Составной оператор begin S1; S2;...; Sn end в ПОЛИЗе записывается как S1 S2... Sn. Пример ПОЛИЗ оператора while n> 3 do begin write(n*n-1); n: =n-1 end представлен в таблице 4.4
Таблица 4.4 – ПОЛИЗ оператора while
Популярное:
|
Последнее изменение этой страницы: 2016-04-11; Просмотров: 1095; Нарушение авторского права страницы


 , где
, где 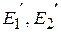 - ПОЛИЗ выражений Е1 и Е2 соответственно.
- ПОЛИЗ выражений Е1 и Е2 соответственно. , где
, где  - ПОЛИЗ выражения Е.
- ПОЛИЗ выражения Е.