|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Знакомство с основными понятиями архитектуры «клиент-сервер», принципы построения web-сервера.Стр 1 из 4Следующая ⇒
Лабораторная работа 2 Основные понятия архитектуры «клиент-сервер», принципы построения web-сервера. 1. Цель работы: Знакомство с основными понятиями архитектуры «клиент-сервер», принципы построения web-сервера. Задание на лабораторную работу Сделать краткий конспект.
Методические указания к лабораторной работе
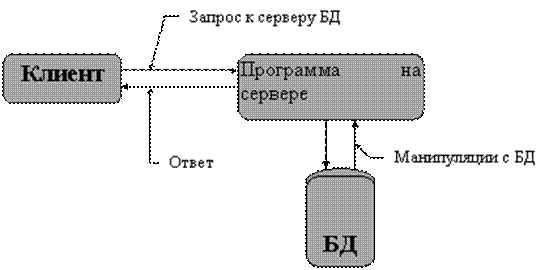
Основные особенности архитектуры «клиент-сервер» Одна из моделей взаимодействия компьютеров в сети получила название «клиент-сервер» (Рис. 1Клиент-серверные архитектуры распределенной обработки данных
Практически все модели организации взаимодействия пользователя с базой данных, построены на основе модели «клиент-сервер». Одна из моделей взаимодействия компьютеров в сети получила название «клиент-сервер» (Рис. 1.).
То есть предполагается, что приложения, реализующие какой-либо тип модели, отличаются способом распределения функций ранее приведенных групп обработки данных между как минимум двумя частями: - клиентской, которая отвечает за целевую обработку данных и организацию взаимодействия с пользователем; - серверной, которая обеспечивает хранение данных, обрабатывает запросы и посылает результаты клиенту для специальной обработки. В общем случае предполагается, что эти части приложения функционируют на отдельных компьютерах, т. е. к серверу БД с помощью сети подключены компьютеры пользователей (клиенты). Сервер - это программа, реализующая функции собственно СУБД: определение данных, запись-чтение данных, поддержка схем внешнего, концептуального и внутреннего уровней, диспетчеризация и оптимизация выполнения запросов, защита данных. Клиент- это различные программы, написанные как пользователями, так и поставщиками СУБД, внешние или «встроенные» по отношению к СУБД. Программа-клиент организована в виде приложения, работающего «поверх» СУБД и обращающегося для выполнения операций над данными к компонентам СУБД через интерфейс внешнего уровня. Инструментальные средства, в том числе и утилиты, не отнесены к серверной части очень условно. Являясь не менее важной составляющей, чем ядро СУБД, они выполняются самостоятельно, как пользовательское приложение. Основной принцип технологии «клиент—сервер» заключается в разделении функций стандартного интерактивного приложения на четыре группы, имеющие различную природу: - функции ввода и отображения данных: - чисто прикладные функции, характерные для данной - фундаментальные функции хранения и управления информационными ресурсами (базами данных, файловыми системами и т. д.); - служебные, играющие роль интерфейсов между функциями первых трех групп. Выделяются четыре основных подхода, реализованные в следующих моделях (или схемах): •файловый сервер (File Server — FS); •доступ к удаленным данным (Remote Data Access — RDA); •север базы данных (DataBase Serveг — DBS); •сервер приложений (Application Server — AS).
Файловый сервер (FS)
Модель является базовой для локальных сетей персональных компьютеров. В свое время она была исключительно популярной среди отечественных разработчиков, использовавших такие системы, как FoxPro, Clipper, Clarion, Paradox и т. д. Один из компьютеров в сети считается файловым сервером и предоставляет услуги по обработке файлов другим компьютерам. Здесь мы имеем дело с распределенной файловой системой. Файловый сервер работает под управлением сетевой операционной системы (например, Novell NetWare) и играет роль компонента доступа к информационным ресурсам (т. е. к файлам). На других компьютерах в сети функционируют приложения, в кодах которых совмещены компонент представления и прикладной компонент (рис.2, а). Протокол обмена представляет собой набор низкоуровневых вызовов, обеспечивающих приложению доступ к файловой системе на файл-сервере. FS-модель послужила фундаментом для расширения возможностей персональных СУБД в направлении поддержки многопользовательского режима. В таких системах на нескольких персональных компьютерах выполняется как прикладная программа, так и копия СУБД, а базы данных содержатся в разделяемых файлах, которые находятся на файловом сервере. Когда прикладная программа обращается к базе данных, СУБД направляет запрос на файловый сервер. В этом запросе указаны файлы, где находятся запрашиваемые данные. В ответ на запрос файловый
сервер направляет по сети требуемый блок данных. СУБД, получив его, выполняет над данными действия, которые были декларированы в прикладной программе. К технологическим недостаткам модели относят высокий сетевой трафик (передача множества файлов, необходимых приложению), узкий спектр операций манипулирования данными («данные это файлы»), отсутствие адекватных средств безопасности доступа к данным (защита только на уровне файловой системы) и т. д. Собственно, перечисленное не есть недостатки, но следствие внутренне присущих FS-модели ограничений, определяемых ее характером. Недоразумения возникают в том случае, когда FS-модель используют не по назначению -например, пытаются интерпретировать как модель сервера базы данных. Удаленный доступ (RDA)
Более технологичная RDA-модель существенно отличается от FS-модели характером компонента доступа к информационным ресурсам. Это, как правило, SQL-сервер. В RDA-модели коды компонента представления и прикладного компонента совмещены и выполняются на компьютере-клиенте. Последний поддерживает как функции ввода и отображения данных, так и чисто прикладные функции. Доступ к информационным ресурсам обеспечивается либо операторами специального языка (языка SQLЬ, например, если речь идет о базах данных) или вызовами функций специальной библиотеки (если имеется соответствующий интерфейс прикладного программирования — АРI). Клиент направляет запросы к информационным ресурсам (например, к базам данных) по сети удаленному компьютеру. На нем функционирует ядро СУБД, которое обрабатывает запросы, выполняя предписанные в них действия и возвращает клиенту результат, оформленный как блок данных (рис. 2.1, б). При этом инициатором манипуляций с данными выступают программы, выполняющиеся на компьютерах-клиентах, в то время как ядру СУБД отводится пассивная роль — обслуживание запросов и обработка данных. Далее будет показано, что такое распределение обязанностей между клиентами и сервером базы данных -не догма: сервер БД может играть более активную роль, чем та, которая предписана ему традиционной парадигмой. RDA-модель избавляет от недостатков, присущих как системам с централизованной архитектурой, так и системам с файловым сервером. Основное достоинство RDA-модели заключается в унификации интерфейса «клиент—сервер» в виде языка SQL. Действительно, взаимодействие прикладного компонента с ядром СУБД невозможно без стандартизованного средства общения. Запросы, направляемые программой ядру, должны быть понятны обеим сторонам. Для этого их следует сформулировать на специальном языке. Но в СУБД уже существует язык 8SQL о котором речь шла выше. Поэтому было бы целесообразно использовать его не только в качестве средства доступа к данным, но и как стандарта общения клиента и сервера. К сожалению, RDA-модель не лишена ряда недостатков. Во-первых, взаимодействие клиента и сервера посредством SQL-запросов существенно загружает сеть. Во-вторых, удовлетворительное администрирование приложений в RDA-модели практически невозможно из-за совмещения в одной программе различных по своей природе функций (функции представления и прикладные функции).
Сервер баз данных (DBS) Наряду с RDA-моделью все большую популярность приобретает DBS-модель (рис. 2.1, в). Последняя реализована в некоторых реляционных СУБД (Informix, Ingres, Oracle). Ее основу составляет механизм хранимых процедур - средство программирования SQL-сервера. Процедуры хранятся в словаре базы данных, разделяются между несколькими клиентами и выполняются на том же компьютере, где функционирует SQL-сервер. Язык, на котором разрабатываются хранимые процедуры, представляет собой процедурное расширение языка запросов SQL и уникален для каждой конкретной СУБД. В DBS-модели компонент представления выполняется на компьютере-клиенте, в то время как прикладной компонент оформлен как набор хранимых процедур и функционирует на компьютере-сервере БД. Там же выполняется компонент доступа к данным, т. е. ядро СУБД. Достоинства DBS -модели очевидны: это и возможность централизованного администрирования прикладных функций, и снижение трафика (вместо SQL-запросов по сети направляются вызовы хранимых процедур), и возможность разделения процедуры между несколькими приложениями, и экономия ресурсов компьютера за счет использования единожды созданного плана выполнения процедуры. К недостаткам можно отнести ограниченность средств, используемых для написания хранимых процедур, которые представляют собой разнообразные процедурные расширения SQL, не выдерживающие сравнения по изобразительным средствам и функциональным возможностям с языками третьего поколения, такими, как Си или Паскаль. Сфера их использования ограничена конкретной СУБД, в большинстве СУБД отсутствуют возможности отладки и тестирования разработанных хранимых процедур. На практике часто используются смешанные модели, когда поддержка целостности базы данных и некоторые простейшие прикладные функции выполняются хранимыми процедурами (DBS-модель), а более сложные функции реализуются непосредственно в прикладной программе, которая работает на компьютере-клиенте (RDA-модель). Так или иначе, современные многопользовательские СУБД опираются на RDA- и DBS-модели и при создании ИС, предполагающем использование только СУБД, выбирают одну из этих двух моделей либо их разумное сочетание.
Сервер приложений (АS)
В AS -модели (рис. 2.1, г) процесс, выполняющийся на компьютере-клиенте, отвечает обычно за интерфейс с пользователем (т. е. реализует функции первой группы). Обращаясь за выполнением услуг к прикладному компоненту, этот процесс играет роль клиента приложения (Application Client — АC). Прикладной компонент реализован как группа процессов, выполняющий прикладные функции, и называется сервером приложения (Application Server — АS). Все операции над информационными ресурсами выполняются соответствующим компонентом, по отношению к которому AS играет роль клиента. Из прикладных компонентов доступны ресурсы различных типов - базы данных, очереди, почтовые службы и др. RDA и DBS-модели опираются на двухзвенную схему разделения функций. В RDA-модели прикладные функции приданы программе-клиенту, в DBS-модели ответственность за их выполнение берет на себя ядро СУБД. В первом случае прикладной компонент сливается с компонентом представления, во втором - интегрируется в компонент доступа к информационным ресурсам. В АS-модели реализована трехзвенная схема разделения функций, где прикладной компонент выделен как важнейший изолированный элемент приложения, для его определения используются универсальные механизмы многозадачной операционной системы, и стандартизованы интерфейсы с двумя другими компонентами. АS-модель является фундаментом для мониторов обработки транзакций (Transaction Processing Monitor -TRM), или, проще, мониторов транзакций, которые выделяются к особый вид программного обеспечения. В заключение отметим, что часто, говоря о сервере базы данных, подразумевают как компьютер, так и программное обеспечение — ядро СУБД. При описании архитектуры «клиент—сервер» под сервером базы данных мы имели в виду компьютер. Ниже сервер базы данных будет пониматься как программное обеспечение — ядро СУБД.
Технология Parser Технология Parser была разработана в Студии Web-дизайна Артемия Лебедева в 1997 году. Parser автоматизирует создание и обновление сайтов, страницы которых схожи по оформлению, содержанию или структуре. Применение технологии Parser позволяет HTML-программисту единожды описать повторяющиеся элементы информационного наполнения и разметки страниц, а затем ссылаться на них в коде каждой страницы сайта. Средствами Parser можно дать описание структуры, а затем использовать его для формирования единообразно устроенных страниц. При этом если мы изменяем описание структуры или элемента разметки, то в дальнейшем все страницы генерируются с учетом внесенных корректив. Parser пригодна для решения большинства задач, которые обычно требуют программирования CGI-скриптов, например, для формирования страниц с результатами запросов к реляционным базам данных. В технологии Parser предусмотрены средства для работы с полями форм, строками запроса, переменными окружения Web-сервера. Интерпретатор Parser устанавливают на сервере. Web-сервер конфигурируют таким образом, что HTML-файлы до пересылки их браузеру обрабатываются модулем Parser. Если в тексте файла обнаруживаются Parser операторы, модуль выполняет их разбор и заменяет вычисленными значениями. Например, вызов оператора ^uri[] будет заменен адресом обрабатываемой страницы, вызов ^date[] — текущей датой, вызов ^macro[value] — результатом разбора макроса value. Остальной текст, в том числе тэги языка HTML, остается без изменений. Технология Parser строится на базе нескольких конструкций. К ним относятся операторы, макросы и некоторые другие конструкции. Оператором называется конструкция следующего вида: ^имя_оператора[аргумент1; аргумент2;...аргументN]В качестве значений аргументов в оператор могут быть подставлены произвольные фрагменты HTML-кода, в том числе занимающие в файле несколько строк. Если аргументы оператора заключают в себе другие операторы, Parser сначала вычисляет их значения и подставляет в аргументы, которые затем использует при вычислении значения оператора. Глубина вложения операторов при этом не ограничена. Некоторые операторы не имеют аргументов. Набор доступных операторов определяется используемой версией модуля Parser. При обработке файла модулем оператор заменяется фрагментом, который получается в результате его разбора. Более подробная информация по этой технологии может быть найдена на [8]. Необходимо отметить, что, хотя Parser и содержит ряд конструкций, позволяющих управлять ходом интерпретации шаблона документа, функциональные характеристики этой технологии весьма ограничены. Хотя в пользовательской документации [8] и сказано, что использование предлагаемых этим «языком» “возможностей не требует высокой квалификации в области программирования”, по сути, само написание и применение операторов и макросов этой технологии требует значительной подготовки. Из-за применения вложенности операторов и макросов синтаксис языка становится не читаем. Функциональная схема данной технологии полностью аналогична схеме технологии PHP, за исключением того, что роль обработчика PHP играет обработчик инструкций Parser. По мнению автора, применение технологии Parser на текущий момент наиболее оправдано для создания комплексов составных легко модифицирующихся Web-страниц. В случае необходимости создания интерактивных Web-документов Parser может быть заменена языком программирования PHP, обладающим более широкими возможностями, более легким и понятным синтаксисом. Сравнение технологий Рассмотрев наиболее распространенные технологии, попытаемся сравнить их. Прежде всего, сопоставим перечисленные средства Web-программирования с предложенной нами ранее классификацией, и попытаемся выявить некоторые определяемые технологией функциональные особенности. Далее обратим внимание на такие характеристики, как безопасность, быстродействие (рассматривается качественно), нагрузка на сеть. Область применения каждой технологии была определена нами при их рассмотрении. Все перечисленные технологии относятся к технологиям создания интерактивных Web-документов. Технологии PHP, CGI, Parser и ASP относятся к выполняемым на сервере. PHP и Parser требуют для своего функционирования дополнительной программной надстройки к Web-серверу, которая будет интерпретировать и выполнять инструкции на соответствующем языке в теле документа. Выполнение CGI-сценариев возлагается на операционную систему. Только в случае, если сценарий написан на интерпретируемом языке, требует наличия в системе соответствующего интерпретатора. Если CGI-программа написана на компилируемом языке, то для ее работы не требуется никаких дополнительных средств. Технология ASP преимущественно ориентирована на Windows-платформы. Обработка DHTML-документов производится на стороне клиента. Для этого браузер клиента должен иметь поддержку используемых в странице языков сценариев – JavaScript или VBScript. Вывод Подытожим вышеизложенные сравнения следующим выводом. При применении Web-сервера на базе ОС Unix для реализации интерактивных Web-документов на стороне сервера предпочтительным является использование языка PHP. В случае повышенных требований к быстродействию при обработке больших объемов информации рекомендуется использование интерфейса CGI со сценариями, написанными на компилируемых языках. На серверах на базе Windows предпочтительно применение технологии ASP. Для проверки больших объемов информации перед передачей их на сервер или для реализации обработки информации на стороне пользователя рекомендуется использовать компоненты DHTML. Выбор оптимального с точки зрения быстродействия решения возможен лишь при сравнении нескольких способов решения одной задачи с применением различных технологий. Сведем рассмотренные характеристики в таблицу (см. табл. 2.1): Таблица 2.1 Характеристики Web- технологий
примечание: W – MS Windows, U – Unix.
4. Требования к содержанию и оформлению отчета Отчет по данной работе не оформляется
5. Контрольные вопросы
Литература
Лабораторная работа 2 Основные понятия архитектуры «клиент-сервер», принципы построения web-сервера. 1. Цель работы: Знакомство с основными понятиями архитектуры «клиент-сервер», принципы построения web-сервера. Задание на лабораторную работу Сделать краткий конспект.
Популярное:
|
Последнее изменение этой страницы: 2016-05-03; Просмотров: 1357; Нарушение авторского права страницы