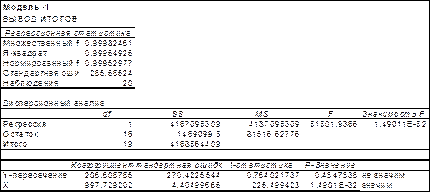|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Санкт-Петербургский государственный горный институт им Г.В. ПлехановаСтр 1 из 5Следующая ⇒
Санкт-Петербургский государственный горный институт им Г.В. Плеханова (технический университет)
Кафедра информатики и компьютерных технологий Эконометрика МНОЖЕСТВЕННАЯ РЕГРЕССИЯ Методические указания к лабораторным работам для студентов специальности 080109
САНКТ-ПЕТЕРБУРГ Федеральное агентство по образованию Санкт-Петербургский государственный горный институт им Г.В. Плеханова (технический университет)
Кафедра информатики и компьютерных технологий Эконометрика МНОЖЕСТВЕННАЯ РЕГРЕССИЯ Методические указания к лабораторным работам для студентов специальности 080109
САНКТ-ПЕТЕРБУРГ УДК 519.86: 622.3.012 (075.83)
ЭКОНОМЕТРИКА. Множественная регрессия. Методические указания к лабораторным работам / Санкт-Петербургский государственный горный институт (технический университет). Сост.: В.В. Беляев, Г.Н.Журов, Т.А. Виноградова, Т.Р. Косовцева. СПб, 2009., 61 с.
Методические указания содержат сведения, необходимые для лабораторных работ по эконометрике. Приведены необходимые теоретические сведения и примеры выполнения заданий по исследованию корреляционных и регрессионных связей между характеристиками экономического процесса, которые являются теоретической основой применения эконометрических методов. Все решения выполнены с использованием электронных таблиц MS Excel, в том числе с применением надстройки «Пакет анализа». Методические указания предназначены для студентов специальности 080109 «Бухгалтерский учет, анализ и аудит» дневной формы обучения.
Табл.3. Рис.23. Библиогр.: 7 назв.
Научный редактор ст. преп. Е.В.Быкова
© Санкт-Петербургский горный институт им. Г.В.Плеханова, 2009 г. ВВЕДЕНИЕ Как правило, реальные экономические явления достаточно сложны и выявление характера связи между различными свойствами(параметрами) таких явлений является сложной задачей. Парная регрессия, рассмотренная в предыдущих лабораторных работах, описывает исследуемую характеристику экономического явления (отклик) в зависимости от одной объясняющей характеристики (фактора) в предположении, что влиянием других факторов можно пренебречь. Адекватное уравнение в этом случае удается построить далеко не всегда, поскольку причиной изменения отклика является одновременное воздействие множества факторов. Для того, чтобы учесть это воздействие необходимо использовать модель множественной регрессии. Построение модели множественной регрессии включает несколько этапов: - выбор формы связи (уравнения регрессии); - отбор факторных признаков. Выбор формы связи затрудняется тем, что, теоретическая зависимость между признаками может быть выражена большим числом различных функций. Поскольку уравнение регрессии строится главным образом для объяснения и количественного отображения взаимосвязей, оно должно хорошо отражать сложившиеся между откликом и исследуемыми факторами фактические связи. В данной работе описан математический аппарат для построения линейного уравнения множественной регрессии. Важным этапом построения уже выбранного уравнения множественной регрессии является отбор и последующее включение факторных признаков. Проблема отбора факторных признаков для построения моделей может быть решена на основе эвристических или многомерных статистических методов анализа. В данной работе показан метод включения, в определенной степени решающий проблему отбора факторов Лабораторная работа 7. МНОЖЕСТВЕННАЯ регрессия Цель: освоить на практике нахождение с помощью табличного процессора MS Excel числовых характеристик множественной регрессии, а также изучить основные свойства теории корреляции. Множественная корреляция Тесноту совместного влияния факторов на результат показывают коэффициент множественной детерминации и индекс множественной корреляции. Качество построенной модели в целом оценивается коэффициентом множественной детерминации, который определяется формулой:
где
Для линейной регрессии можно доказать следующее равенство: Остаточная сумма квадратов отклонений Все свойства коэффициента детерминации Таблица 7.1 Шкала Чеддок а
Величину
Индекс множественной корреляции
Очевидно что, значение При линейной зависимости коэффициент множественной корреляцииможно определить через матрицу парных коэффициентов корреляции:
где
определитель матрицы межфакторной корреляции, полученный из матрицы парных коэффициентов корреляции вычеркиванием первой строки и первого столбца. Таблица 7.2. Матричная форма записи Матричная форма записи для определения коэффициентов множественной линейной регрессии полностью аналогична таковой для парной регрессии (5.28), т.е.
где X матрица размерности
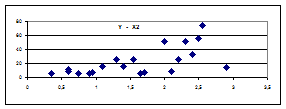
К пункту 1. 1. Описательные статистики для отклика и всех факторов X1 и X2, могут быть вычислены с помощью с помощью надстройки MS Excel «Пакет Анализа – Описательные статистики». К пункту 2. Вытянутость облака точек на диаграмме рассеяния (рис. 7.5 а) вдоль наклонной прямой позволяет сделать предположение о том, что существует линейная связь между значениями переменных X1 - весом груза и Y- стоимостью грузовой автомобильной перевозки. Анализируя рис.7.5.б, можно заметить наличие прямой линейной связи между значениями переменных X2 - расстоянием и Y - стоимостью грузовой автомобильной перевозки.
Рис.7.4 б. Описательная статистика для исходных данных задачи с помощью с помощью надстройки MS Excel «Пакет Анализа – Описательные статистики».
Рис. 7.5 а. Облако рассеяния Y - X1
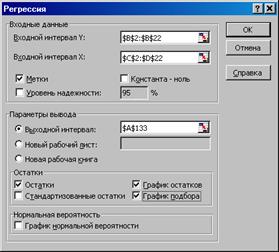
Рис. 7.5 б. Облако рассеяния Y - X2 К пункту 3. Значения линейных коэффициентов парной корреляции определяют тесноту попарно связанных переменных, использованных в данном уравнении множественной регрессии. Линейные коэффициенты частной корреляции оценивают тесноту связи значений двух переменных, исключая влияние всех других переменных, представленных в уравнении множественной регрессии. Матрицу парных коэффициентов корреляции переменных можно рассчитать, используя инструмент « Анализ данных» > Корреляция. Для этого: 1). В главном меню последовательно выберите пункты Сервис> Анализ данных> Корреляция. Щелкните по кнопке ОК; 2). Заполните диалоговое окно ввода данных и параметров вывода (рис. 7.6 а).
Рис. 7.6 а. Диалоговое окно ввода данных и параметров вывода для вычисления коэффициентов парной корреляции Значения коэффициентов парной корреляции указывают на заметную связь стоимости перевозок Y как с весом груза – X1 , так и расстоянием – X2 (ryx1=0, 66 и ryx2=0, 63). В то же время межфакторная связь rx1x2 =0, 12 довольно слабая, т.е. явной мультиколлинеарности нет. В связи с вышеизложенным, можно сделать предварительный вывод, что нет оснований исключать факторы X1 или X2 из данной модели. Коэффициенты частной корреляции дают более точную характеристику тесноты связи двух признаков, чем коэффициенты парной корреляции, так как очищают парную зависимость от взаимодействия данной пары признаков с другими признаками, представленными в модели.
Рис. 7.6 б. Результаты вычисления коэффициентов корреляции (интервал A54: D56) и коэффициентов частной корреляции.
Вычислим коэффициенты частной корреляции по рекуррентным формулам
Наиболее тесно связаны Y и X1 (ryx1 x2 =0, 7513), связь Y и X2 чуть слабее: ryx2 x1=0, 7376, а межфакторная зависимость X1 и X2 не очень сильная |rx1x2 y| = 0, 4987 Если сравнить коэффициенты парной и частной корреляции, то можно увидеть, что из-за наличия между факторной зависимости они отличаются друг от друга: ryx1= 0, 6552; ryx1 x2= 0, 7513; ryx2=0, 6346; ryx2 x1=0, 7376. Частные коэффициенты корреляции Y и X1 , Y и X2 свидетельствуют о более сильных взаимосвязях независимых переменных, чем это показывают значения парных коэффициентов корреляции. Это произошло потому, что парный коэффициент корреляции завысил тесноту связи между X1 и X2 , занизив при этом тесноту связи между Y и X1 , Y и X2 К пункту 4. Вычисление параметров линейного уравнения множественной регрессии. Система нормальных уравнений (7.3) в случае двух факторов будет иметь вид:
Вычисление коэффициентов этой системы и решение ее с помощью обратной матрицы приведено на рис. 7.7. Коэффициенты регрессии содержатся в интервале ячеек I96: I97. Таким образом, уравнение регрессии примет вид:
Рис. 7.7. Вычисление параметров линейного уравнения множественной регрессии с помощью системы нормальных уравнений. Нахождение коэффициентов регрессии можно выполнить, используя функцию ЛИНЕЙН() (рис. 7.8 ).
Рис. 7.8. Результаты применения функции ЛИНЕЙН(). Нахождение коэффициентов регрессии матричным методом показано на рис. 7.9. Коэффициенты регрессии содержатся в интервале ячеек I127: I129.
Рис. 7.9. Вычисление параметров линейного уравнения множественной регрессии с помощью матричного метода. Операцию нахождения коэффициентов регрессии можно провести с помощью инструмента «Анализ Данных» «Регрессия». Следует помнить, что в отличие от парной регрессии в диалоговом окне при заполнении параметра «входной интервал Х» следует указать не один столбец, а все столбцы, содержащие значения факторных признаков (см.рис. 7.10.а ). Результат приведен на рис. 7.10.б По результатам всех вычислений уравнение множественной регрессии имеет вида Величины b1 и b2 указывают, что с увеличением значений X1 и X2 на единицу отклик увеличивается соответственно на 1, 16 и на 15, 10 тыс.руб.
Рис. 7.10 а. Диалоговое окно инструмента «Анализ Данных» «Регрессия».
Рис. 7.10 б. Результаты применения инструмента «Анализ Данных» «Регрессия». К пункту 5. Для вычисления коэффициентов уравнения регрессии в стандартизованном масштабе используем формулы (7.6).
С учетом этого, уравнение регрессии в стандартном масштабе будет иметь вид:
То есть, с ростом груза на одну сигму при неизменном расстоянии стоимость грузовых автомобильных перевозок увеличивается в среднем на 0, 58 сигмы. Поскольку значения коэффициентов отличаются друг от друга незначительно, то влияние на стоимость грузовых автомобильных обоих факторов приблизительно одинаково. К пункту 6. Рассчитаем средние коэффициенты эластичности
С увеличением среднего веса груза на 1% от его среднего уровня средняя стоимость перевозок возрастет на 0, 71% от своего среднего уровня; при увеличении среднего расстояния перевозок на 1% - средняя стоимость доставки груза увеличится на 1, 05%. Различия в силе влияния факторов на результат, полученные при сравнении уравнения регрессии в стандартизованном масштабе и коэффициентов эластичности, объясняются тем, что при вычислении коэффициентов эластичности учитывают поведение уравнения регрессии в окрестности средних значений. К пункту 7 Вычислить множественный коэффициент корреляции Все промежуточные вычисления и результаты расчетов в MS Excel приведены на рис.7.11. Получено значение Вычисление индекса корреляции с использованием формулы Полученный результат совпадает с результатом, полученным с помощью надстройки «Анализ Данных» > «Регрессия», содержащимся в ячейке В136 («Множественный R») на рис.7.10.б.
Рис. 7.11 а. Вычисление индекса корреляции в MS Excel в режиме отображения данных.
Рис. 7.11 б. Вычисление индекса корреляции в MS Excel в режиме отображения формул.
К пункту 8. Величина коэффициента множественной детерминации
Рис. 7.12 а. Вычисление коэффициента множественной детерминации в MS Excel в режиме отображения данных.
Рис. 7.12 б. Вычисление коэффициента множественной детерминации в MS Excel в режиме отображения формул. Полученный результат совпадает с результатом, полученным с помощью надстройки «Анализ Данных» > «Регрессия», содержащимся в ячейке В136 («Множественный R») на рис.7.10.б. Поскольку коэффициент множественной детерминации оценивает долю вариации результата за счет представленных в уравнении факторов в общей вариации результата и К пункту 9. Оценку надежности уравнения регрессии в целом и показателя тесноты связи По данным дисперсионного анализа, представленным в интервале ячеек A142: F146 на рис.7.10.б, Fнабл=24, 17. Вероятность случайно получить такое значение F – критерия составляет 1, 07*10-5 , ячейка F144 («Значимость F»), что не превышает допустимый уровень значимости 5%. Следовательно, полученное значение не случайно, оно сформировалось под влиянием существенных факторов, т.е. подтверждается статистическая значимость всего уравнения и показателя тесноты связи Значения скорректированного и нескорректированного линейных коэффициентов множественной детерминации приведены в разделе регрессионная статистика. К пункту 10. Вычислить исправленный (скорректированный, adjustable) коэффициент детерминации Заметим, что К пункту 11. Значения случайных ошибок параметров a, b1 и b2 с учетом округления: ma=6, 4471; mb1=0, 2463; mb2=3, 3530. Эти значения используются для расчета t - критерия Стьюдента по формуле 7.20:
Модули вычисленных величин следует сравнить с tкрит. Для практических расчетов достаточно помнить, чтоесли значение t-критерия > 2-3, можно сделать вывод о существенности данного параметра, который формируется под воздействием неслучайных причин. Здесь статистически значимыми являются a , b1 и b2. Процедура проверки значимости коэффициентов уравнения с помощью инструмента «Анализ Данных» «Регрессия» существенно проще, поскольку все промежуточные операции выполняются автоматически. На рис. 7.10.б. в интервале B149: Е151 приведены значения коэффициентов регрессии, стандартных ошибок, t – статистики (t-наблюдаемые) и Р – значения соответственно. Для анализа значимости коэффициентов регрессии столбец «P-значение» в интервале Е86: Е88: если онменьше принятого нами уровня значимости (в настоящей работе уровень значимости принят равным 0, 05), делают вывод о неслучайной природе данного значения коэффициента, т.е. о том, что он статистически значим и надежен. В противоположном случае принимается гипотеза о случайной природе значения этого коэффициента уравнения. Здесь все P< 0, 05, что позволяет подтвердить сделанный ранее вывод о статистической значимости всех параметров регрессии. К пункту 12. Для оценки целесообразности включения в модель фактора xi после фактора х2 и фактора х2 после фактора х1 вычислим значения частных F-критериев Фишера
Частный F-критерий –
Поменяем первоначальный порядок включения факторов в модель и рассмотрим вариант включения x1 после x2. Для этого вычислим Fчасти x1, оно равно 22, 03. При том же уровне значимости a =0, 05 (5%). Fкрит=4, 45 и. К пункту 13. Вычислим значение каждого фактора с учетом того, что максимальные значения и размахов уже были вычислены и приведены на рис.7.4.б. Полученные результаты вычислений подставим в уравнение множественной регрессии
Общий вывод состоит в том, что множественная линейная модель
с факторами Х1 и Х2 имеет коэффициент детерминированности
Рис. 7.13 а. Вычисление точечного значения прогноза в MS Excel в режиме отображения данных.
Рис. 7.13 б. Вычисление точечного значения прогноза в MS Excel в режиме отображения формул. . Задание Для ряда регионов представлена информация об объёмах Y (у.е.) продаж фирмы «Галактика»и ее затратах на рекламу в этих регионах – X1, а также индекс потребительских доходов в этих регионах – X2. Построить и оценить линейную модель множественной регрессии по плану, приведенному в примере, изложенном выше. Исходные данные взять из файла «Econometric_LabRab_7.xls».
Теоретические сведения Чаще всего в качестве факторов (объясняющих переменных) в регрессионных моделях рассматриваются экономические переменные, принимающие количественные значения в некотором интервале. Вместе с тем может оказаться необходимым включить в модель фактор, имеющий два или более качественных уровней. Это могут быть разного рода атрибутивные признаки, такие, например, как профессия, пол, образование, климатические условия, принадлежность к определенному региону. Чтобы ввести такие переменные в регрессионную модель, им должны быть присвоены те или иные цифровые метки, т.е. качественные переменные должны быть преобразованы в количественные. Такого вида сконструированные переменные в эконометрике принято называть фиктивными переменными (“dummy variables”). Фиктивность состоит в том, что количественная переменная описывает качественный признак. В отечественной литературе можно встретить термины «структурные переменные» или «индикаторные переменные». Фиктивными переменные, принимающие ровно два значения называются дихотомическими или бинарными. Включение в модель фиктивных переменных может иметь цель отразить в модели неоднородность совокупности. По идее, можно построить уравнение регрессии для каждого элемента совокупности, а затем изучать различия между ними, но введение фиктивных переменных позволяет исследовать одно уравнение сразу для всех элементов совокупности. Однако нельзя рассматривать фиктивные переменные как панацею при применении методов регрессии к неоднородным данным.
Пример 1 . Рассмотрим применение фиктивных переменных для описания аварийности на перекрестке автомобильных дорог в зависимости от интенсивности движения и освещенности в различное время суток (возможные значения - дневное или ночное время). Предположим, что изучается линейная зависимость, которая в общем виде для совокупности обследуемых перекрестков имеет вид:
где y - количество аварий; x – интенсивность движения(автомобилей/мин). Аналогичные уравнения могут быть найдены отдельно для дневного времени:
и ночного:
Различия в количестве аварий в зависимости от времени суток может проявиться в различии средних Положим
В этом случае возможно построение общего уравнения регрессии с включением в него фактора «время суток» в виде фиктивной переменной. Например, включать в модель фактор «время суток» в виде фиктивной переменной можно в следующем виде:
Коэффициент регрессии при фиктивной переменной интерпретируется как среднее изменение зависимой переменной при переходе от одной категории к другой при неизменном значении остальных параметров. На основе t-критерия Стьюдента делается вывод о значимости влияния фиктивной переменной, существенности расхождения между категориями. Предположим, что определено уравнение (т.е. методом наименьших квадратов вычислены коэффициенты A, С1 и b ). Теоретические значения размера аварийности в дневное время будут получены из уравнения
Для ночного времени соответствующие значения получим из уравнения
Сопоставляя эти результаты, видим, что различия в уровне аварийности для ночного и дневного времени состоят в различии свободных членов данных уравнений: В этом примере существенным является, то, что угловые коэффициенты наклона прямых регрессии были приблизительно одинаковыми, т.е. выполнялось соотношение Однако в общем случае это не так, поэтому целесообразно учесть взаимодействие между факторами. Этот учет взаимодействия достигается путем введения в модель дополнительного слагаемого:
После того, как уравнение будет построено, следует последовательно проверить ряд гипотез: 1. Гипотеза 2. Если гипотеза Если качественный признак принимает не два, а большее количество значений, то вводится не одна, а несколько фиктивных переменных по схеме, приведенной ниже. Допустим, что требуется исследовать зависимость цены (Y) квартиры от ее площади (X) и типа дома (блочный, кирпичный, монолитный). Фактор «тип дома» можно включить в модель в виде двух фиктивных переменных в следующем виде:
т.е. блочному дому соответствует комбинация (z1, z2)=(1, 0), кирпичному дому соответствует комбинация (z1, z2)=(0, 1), а монолитному дому соответствует комбинация (z1, z2)=(0, 0). Пример 2. Исследовать зависимость цены (Y) квартиры от ее площади (X) и типа дома (блочный, кирпичный). Таблица с данными приведена на рис.8.1. Требуется: 1). Оценить визуально, построив соответствующие облака рассеяния величины Y в зависимости от Х, целесообразность использования линейного уравнения регрессии. 2). Построить модель (Модель - 0.), которая не содержит фиктивной переменной,
оценить ее качество. Проанализировать коэффициенты уравнения.
3). Построить две раздельные модели (Модель - 1 и Модель - 2), которые не содержат фиктивной переменной. При этом Модель - 1:
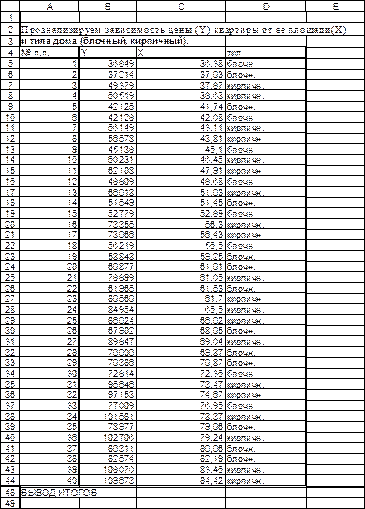
Рис.8.1. Проанализировать коэффициенты уравнений и сравнить их между собой. 4). Построить Модель - 3, которая учитывает площадь и тип дома в едином уравнении множественной регрессии (ввести фиктивную переменную - Z - тип дома). Провести анализ этого уравнения, оценить значимость его параметров, пояснить их экономический смысл. Решение. К пункту 1. Построим облако рассеяния данных(X-Y). (рис.8.2)
Рис.8.2. Очевидно, что в этом облаке явно можно выделить две группы точек, одна из которых соответствует блочным домам, другая кирпичным. К пункту 2. Построим модель (Модель - 0.), которая не содержит фиктивной переменной.
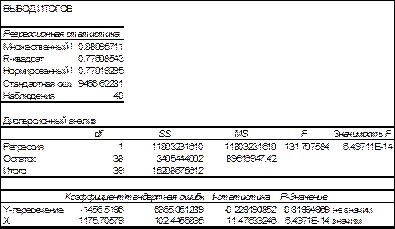
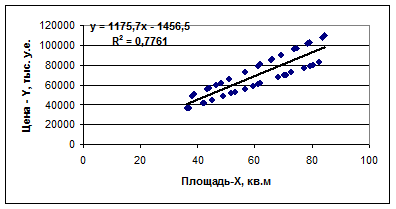
Для определения коэффициентов воспользуемся графическими возможностями EXCEL и надстройкой « Пакет анализа»-«Регрессия ». Результаты приведены на рис.8.3-8.4.
Рис.8.3.
Рис.8.4 Уравнение примет вид Y =1175.7 X -1456.5 Анализ полученных результатов показывает следующее: Коэффициент детерминации R2 = 0.77 и он значим. Свободный член (Y-пересечение) равен 1456.5 и он не значим. Коэффициент b, равный 1175.7, значим. Этот коэффициент имеет простой экономический смысл - стоимость квадратного метра жилья без учета типа дома. К пункту 3. Построим еще две модели (Модель - 1 и Модель - 2.), которые не содержат фиктивной переменной. При этом Модель - 1 При этом Модель - 2 Для определения коэффициентов воспользуемся графическими возможностями MS Excel и надстройкой «Пакет анализа» -«Регрессия». Для Модели - 1 результаты приведены на рис.8.5-8.6.
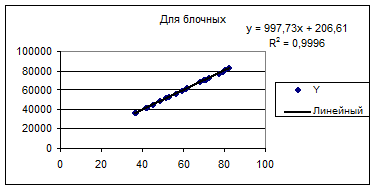
Рис.8.5
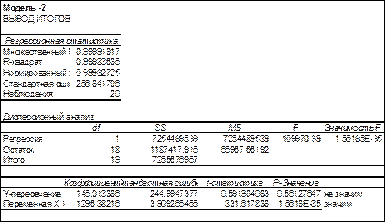
Рис.8.6 Уравнение примет вид Y=997.7X+206.6. Анализ полученных результатов показывает следующее: R2 -= 0.99 и значим. Свободный член (Y-пересечение) равный 206.6 не значим. Коэффициент b равный 997.7, значим. Это значение имеет простой экономический смысл - стоимость квадратного метра жилья в домах блочного типа. Для Модели - 2 результаты приведены на рис.8.7-8.8.
Рис.8.7
Рис.8.8 Уравнение примет вид Y=1296.4X+145. Анализ полученных результатов показывает следующее: R2 -= 0.99 и этот коэффициент значим. Свободный член (Y-пересечение) равен 145 и он не значим. Коэффициент b равен 1296.4, он значим. Это значение имеет простой экономический смысл – стоимость квадратного метра жилья в кирпичных домах. Сравним три модели (Модель - 0, Модель - 1 и Модель - 2.) между собой (табл.8.2.). Таблица 8.2.
Заметим, что стоимость квадратного метра различается в зависимости от типа дома (приблизительно 1000 и 1300 у.е. соответственно) и существенно различаются между собой. Популярное:
|
Последнее изменение этой страницы: 2016-05-03; Просмотров: 587; Нарушение авторского права страницы
 , (7.8)
, (7.8) - остаточная сумма квадратов отклонений,
- остаточная сумма квадратов отклонений,  - общая сумма квадратов отклонений значений
- общая сумма квадратов отклонений значений  от среднего арифметического значения отклика Y.
от среднего арифметического значения отклика Y.  , где
, где  - факторная или регрессионная сумма квадратов отклонений.
- факторная или регрессионная сумма квадратов отклонений. характеризует суммарное отклонение наблюдаемых (эмпирических) данных от теоретических значений, найденных по уравнению регрессии. Факторная или регрессионная сумма квадратов отклонений
характеризует суммарное отклонение наблюдаемых (эмпирических) данных от теоретических значений, найденных по уравнению регрессии. Факторная или регрессионная сумма квадратов отклонений  характеризует разброс теоретических значений относительно среднего арифметического значения наблюдаемого значения (отклика).
характеризует разброс теоретических значений относительно среднего арифметического значения наблюдаемого значения (отклика).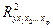 указаны в ЛР №5. Так, значение этого коэффициента лежит в пределах от 0 до 1. Это значение показывает долю объясненной вариации результативного признака (отклика) за счет включенных в уравнение p факторов, т.е. насколько хорошо уравнение, полученное с помощью регрессионного анализа, объясняет взаимосвязь между откликом и факторами. Доля необъясненной вариации отклика других, не учтенных в модели факторов, равна
указаны в ЛР №5. Так, значение этого коэффициента лежит в пределах от 0 до 1. Это значение показывает долю объясненной вариации результативного признака (отклика) за счет включенных в уравнение p факторов, т.е. насколько хорошо уравнение, полученное с помощью регрессионного анализа, объясняет взаимосвязь между откликом и факторами. Доля необъясненной вариации отклика других, не учтенных в модели факторов, равна  . Коэффициент детерминированности служит показателем тесноты связи между независимой переменной и факторами. Показателю тесноты связи можно дать качественную оценку (шкала Чеддока):
. Коэффициент детерминированности служит показателем тесноты связи между независимой переменной и факторами. Показателю тесноты связи можно дать качественную оценку (шкала Чеддока): 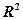 для уравнения множественной регрессии в стандартизованном масштабе можно определить по формуле
для уравнения множественной регрессии в стандартизованном масштабе можно определить по формуле (7.9)
(7.9) так же характеризует тесноту связи между факторами и откликом. Индекс множественной корреляции
так же характеризует тесноту связи между факторами и откликом. Индекс множественной корреляции  естественным соотношением.
естественным соотношением. (7.10)
(7.10) , где
, где  парный индекс корреляции.
парный индекс корреляции. , (7.11)
, (7.11) , (7.12)- определитель матрицы парных коэффициентов корреляции;
, (7.12)- определитель матрицы парных коэффициентов корреляции;  -, (7.13)
-, (7.13) (7.28)
(7.28) , B – вектор коэффициентов размерности
, B – вектор коэффициентов размерности 







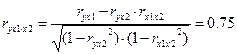











 с использованием матрицы парных коэффициентов корреляции по формуле (7.11).
с использованием матрицы парных коэффициентов корреляции по формуле (7.11). приведено в ячейке С179 на том же рис.7.11
приведено в ячейке С179 на том же рис.7.11
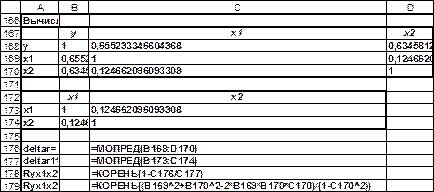


 , то эта доля составляет 74 % и указывает на весьма высокую степень обусловленности вариации результата вариацией факторов, иными словами – на весьма тесную связь факторов с результатом. О шкале Чеддока сила связи оценивается как высокая.
, то эта доля составляет 74 % и указывает на весьма высокую степень обусловленности вариации результата вариацией факторов, иными словами – на весьма тесную связь факторов с результатом. О шкале Чеддока сила связи оценивается как высокая. дает F- критерий Фишера.
дает F- критерий Фишера.
 с использованием соотношения
с использованием соотношения  , где р - количество факторов (здесь р=2). Получаем
, где р - количество факторов (здесь р=2). Получаем  =0, 7092. Такое же значение получено в ячейке В138 («Нормированный R-квадрат») на рис.7.10.б.
=0, 7092. Такое же значение получено в ячейке В138 («Нормированный R-квадрат») на рис.7.10.б. , что соответствует теории.
, что соответствует теории.


 показывает статистическую зависимость включения фактора x2 в модель после того, как в нее включен фактор x1.
показывает статистическую зависимость включения фактора x2 в модель после того, как в нее включен фактор x1.

 =0, 73. Она содержит информативные факторы X1 и X2. Уравнение парной регрессии является простым, хорошо детерминированным, пригодным для анализа и для прогноза
=0, 73. Она содержит информативные факторы X1 и X2. Уравнение парной регрессии является простым, хорошо детерминированным, пригодным для анализа и для прогноза
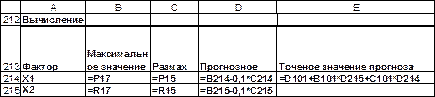
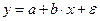
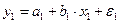
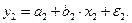
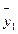 и
и 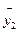 . Вместе с тем сила влияния x на y может быть одинаковой, т.е.
. Вместе с тем сила влияния x на y может быть одинаковой, т.е. 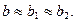
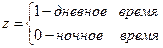
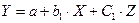
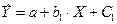
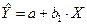
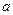 – для ночного и
– для ночного и 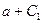 – для дневного.
– для дневного.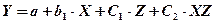
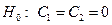 . Альтернативная гипотеза
. Альтернативная гипотеза  . Если гипотеза
. Если гипотеза 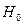 будет принята, то можно пользоваться одной моделью независимо от значения фиктивной переменной. Если будет принята гипотеза
будет принята, то можно пользоваться одной моделью независимо от значения фиктивной переменной. Если будет принята гипотеза 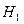 , то приходим к выводу, что модели не одинаковы.
, то приходим к выводу, что модели не одинаковы.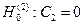 . Если
. Если 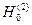 принимается, то заключаем, что уравнения регрессии имеют одинаковые углы наклона и отличаются только свободным членом.
принимается, то заключаем, что уравнения регрессии имеют одинаковые углы наклона и отличаются только свободным членом.

 ,
, 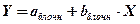 , только по данным, относящимся к блочным домам. Модель - 2:
, только по данным, относящимся к блочным домам. Модель - 2:  , только по данным, относящимся к кирпичным домам.
, только по данным, относящимся к кирпичным домам.