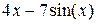|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Лабораторная работа №1. Рекурсивные функцииСтр 1 из 7Следующая ⇒
УДК 681.3.061 (075.8) ББК 32.973.26-018.1 я 73
Содержание
Лабораторная работа №1. Рекурсивные функции.. 4 1.1. Краткие теоретические сведения. 4 1.2. Пример выполнения задания. 4 1.3. Индивидуальные задания. 7 Лабораторная работа №2. Алгоритмы поиска и сортировки в массивах.. 9 2.1. Краткие теоретические сведения. 9 2.2. Индивидуальные задания. 12 Лабораторная работа №3. Динамическая структура СТЕК.. 14 3.1. Краткие теоретические сведения. 14 3.2. Пример выполнения задания. 17 3.3. Индивидуальные задания. 20 Лабораторная работа №4. Динамическая структура ОЧЕРЕДЬ.. 21 4.1. Краткие теоретические сведения. 21 4.2. Пример выполнения задания. 24 4.3. Индивидуальные задания. 25 Лабораторная работа №5. Обратная польская запись.. 25 5.1. Краткие теоретические сведения. 25 5.2. Пример выполнения задания. 25 5.3. Индивидуальные задания. 25 Лабораторная работа №6. Нелинейные списки.. 25 6.1. Краткие теоретические сведения. 25 6.2. Пример выполнения задания. 25 6.3. Индивидуальные задания. 25 Лабораторная работа №7. Алгоритмы поиска корней уравнений.. 25 7.1. Краткие теоретические сведения. 25 7.2. Пример выполнения задания. 25 7.3. Индивидуальные задания. 25 Лабораторная работа №8. Аппроксимация функций.. 25 8.1. Краткие теоретические сведения. 25 8.2. Пример выполнения задания. 25 8.3. Индивидуальные задания. 25 Лабораторная работа №9. Алгоритмы вычисления интегралов.. 25 9.1. Краткие теоретические сведения. 25 9.2. Пример выполнения задания. 25 9.3. Индивидуальные задания. 25 Литература.. 25
Лабораторная работа №1. Рекурсивные функции
Цель работы: изучить способы реализации алгоритмов с использованием рекурсии. Лабораторная работа №2. Алгоритмы поиска и сортировки в массивах
Цель работы: изучить способы сортировки и поиска в массивах структур и файлах. Краткие теоретические сведения При обработке баз данных часто применяются массивы структур. Обычно база данных накапливается и хранится на диске в файле. К ней часто приходится обращаться, обновлять, перегруппировывать. Работа с базой может быть организована двумя способами. 1. Внесение изменений и поиск осуществляется прямо на диске, используя специфическую технику работы со структурами в файлах. При этом временные затраты на обработку данных (поиск, сортировку) значительно возрастают, но нет ограничений на использование оперативной памяти. 2. Считывание всей базы (или необходимой ее части) в массив структур. При этом обработка производится в оперативной памяти, что значительно увеличивает скорость, однако требует больших затрат памяти. Наиболее частыми операциями при работе с базами данных являются «поиск» и «сортировка». При этом алгоритмы решения этих задач существенно зависят от того, организованы структуры в массивы или размещены на диске. Обычно элемент данных (структура) содержит некое ключевое поле (ключ), по которому его можно найти. Ключом может служить любое поле структуры, например, фамилия, номер телефона или адрес. Основное требование к ключу в задачах поиска состоит в том, чтобы операция проверки на равенство была корректной, поэтому при поиске данных по ключу, имеющему вещественное значение, следует указывать не его конкретное значение, а интервал, в который это значение попадает. Алгоритмы поиска Предположим, что у нас имеется следующая структура: struct Ttype { type key; // Ключевое поле типа type ... // Описание других полей структуры } *a; // Указатель для динамического массива структур Задача поиска требуемого элемента в массиве структур a (размер n – задается при выполнении программы) заключается в нахождении индекса i_key, удовлетворяющего условию a[i_key].key = f_key, key – интересующее нас поле структуры данных, f_key – искомое значение того же типа что и key. После нахождения индекса i_key обеспечивается доступ ко всем другим полям найденной структуры a[i_key]. Линейный поиск используется, когда нет никакой дополнительной информации о разыскиваемых данных, и представляет собой последовательный перебор всех элементов массива. Если поле поиска является уникальным, то поиск выполняется до обнаружения требуемого ключа или до конца, если ключ не обнаружен. Если же поле поиска не уникальное, приходится перебирать все данные до конца массива: int i_key = 0, kod = 0; for (i = 1; i < n; i++) if (a[i].key == f_key) { kod = 1; // Обработка найденного элемента, например, вывод i_key = i; // break; – если поле поиска уникальное } if(kod == 0) // Вывод сообщения, что элемент не найден Поиск делением пополам используется, если данные упорядочены по возрастанию (по убыванию) ключа key. Алгоритм поиска осуществляется следующим образом: – берется средний элемент m; – если элемент массива a[m].key < f_key, то все элементы i Приведем пример, реализующий этот алгоритм int i_key = 0, j = n–1, m; while(i_key < j) { m = (i_key + j)/2; if (а[m].key < f_key) i_key = m+1; else j = m; } if (a[i_key].key! = key) return -1; // Элемент не найден else return i; Проверка совпадения a[m].k = f_key в этом алгоритме внутри цикла отсутствует, т.к. тестирование показало, что в среднем выигрыш от уменьшения количества проверок превосходит потери от нескольких «лишних» вычислений до выполнения условия i_key = j, Алгоритмы сортировки Под сортировкой понимается процесс перегруппировки элементов массива, приводящий к их упорядоченному расположению относительно ключа. Цель сортировки – облегчить последующий поиск элементов. Метод сортировки называется устойчивым, если в процессе перегруппировки относительное расположение элементов с равными ключами не изменяется. Основное условие при сортировке массивов – это не вводить дополнительных массивов, т.е. все перестановки элементов должны выполняться в исходном массиве. Сортировку массивов принято называть внутренней, а сортировку файлов – внешней. Методы внутренней сортировки классифицируются по времени их работы. Хорошей мерой эффективности может быть число операций сравнений ключей и число пересылок (перестановок) элементов. Прямые методы имеют небольшой код и просто программируются, быстрые, усложненные методы требуют меньшего числа действий, но эти действия обычно более сложные, чем в прямых методах, поэтому для достаточно малых значений n ( n £ 50 ) прямые методы работают быстрее. Значительное преимущество быстрых методов начинает проявляться при n ³ 100. Среди простых методов наиболее популярны следующие. 1. Метод прямого обмена (пузырьковая сортировка): for (i = 0; i < n–1; i++) for (j = i+1; j < n; j++) if (a[i].key > a[j].key) { // Переставляем элементы r = a[i]; a[i] = a[j]; a[j] = r; } 2. Метод прямого выбора: for (i = 0; i < n–1; i++) { m = i; for (j = i+1; j < n; j++) if (a[j].key < a[m].key) m = j; r = a[m]; // Переставляем элементы a[m] = a[i]; a[i] = r; } Реже используются: 3) сортировка с помощью прямого (двоичного) включения; 4) шейкерная сортировка (модификация пузырьковой). К улучшенным методам сортировки относятся следующие. 1. Метод Д. Шелла (1959), усовершенствование метода прямого включения. 2. Сортировка с помощью дерева, метод HeapSort, Д.Уильямсон (1964). 3. Сортировка с помощью разделения, метод QuickSort, Ч.Хоар (1962), улучшенная версия пузырьковой сортировки, являющийся на сегодняшний день самым эффективным методом. Идея метода разделения QuickSort в следующем. Выбирается значение ключа среднего m-го элемента x = a[m].key. Массив просматривается слева – направо до тех пор, пока не будет обнаружен элемент a[i].key > x. Затем массив просматривается справа – налево, пока не будет обнаружен элемент a[j].key < x. Элементы a[i] и a[j] меняются местами. Процесс просмотра и обмена продолжается до тех пор, пока i не станет больше j. В результате массив оказывается разбитым на левую часть a[L], 0 £ L £ j с ключами меньше (или равными) x и правую a[R], i£ R< n с ключами больше (или равными) x. Алгоритм такого разделения очень прост и эффективен: i = 0; j = n – 1; x = a[(L + R)/2].key; while (i < = j) { while (a[i].key < x) i++; while (a[j].key > x) j--; if (i < = j) { r = a[i]; // Переставляем элементы a[i] = a[j]; a[j] = r; i++; j--; } } Чтобы отсортировать массив, остается применять алгоритм разделения к левой и правой частям, затем к частям частей и так до тех пор, пока каждая из частей не будет состоять из одного единственного элемента. Алгоритм получается итерационным, на каждом этапе которого стоят две задачи по разделению. К решению одной из них можно приступить сразу, для другой следует запомнить начальные условия (номер разделения, границы) и отложить ее решение до момента окончания сортировки выбранной половины. Сравнение методов сортировок показывает, что при n > 100 наихудшим является метод пузырька, метод QuickSort в 2-3 раза лучше, чем HeapSort, и в 3-7 раз, чем метод Шелла. 2.2. Индивидуальные задания Написать программу обработки файла данных, состоящих из структур, в которой реализованы следующие функции: с тандартная обработка файла (создание, просмотр, добавление); линейный поиск в файле; сортировка массива (файла) методами прямого выбора и QuickSort; двоичный поиск в отсортированном массиве. 1. В магазине формируется список лиц, записавшихся на покупку товара. Вид списка: номер, Ф.И.О., домашний адрес, дата учета. Удалить из списка все повторные записи, проверяя Ф.И.О. и адрес. Ключ: дата постановки на учет. 2. Список товаров на складе включает: наименование товара, количество единиц товара, цену единицы и дату поступления товара на склад. Вывести в алфавитном порядке список товаров, хранящихся больше месяца, стоимость которых превышает 100 000 р. Ключ: наименование товара. 3. Для получения места в общежитии формируется список: Ф.И.О. студента, группа, средний балл, доход на каждого члена семьи. Общежитие в первую очередь предоставляется тем, у кого доход меньше двух минимальных зарплат, затем остальным в порядке уменьшения среднего балла. Вывести список очередности. Ключ: доход на каждого члена семьи. 4. В справочной автовокзала хранится расписание движения автобусов. Для каждого рейса указаны его номер, пункт назначения, время отправления и прибытия. Вывести информацию о рейсах, которыми можно воспользоваться для прибытия в пункт назначения раньше заданного времени. Ключ: время прибытия. 5. На междугородной АТС информация о разговорах содержит дату разговора, код и название города, время разговора, тариф, номер телефона в этом городе и номер телефона абонента. Вывести по каждому городу общее время разговоров с ним и сумму. Ключ: общее время разговоров. 6. Информация о сотрудниках фирмы включает: Ф.И.О., табельный номер, количество проработанных часов за месяц, почасовой тариф. Рабочее время свыше 144 ч. считается сверхурочным и оплачивается в двойном размере. Вывести размер заработной платы каждого сотрудника фирмы за вычетом подоходного налога (12% от суммы заработка). Ключ: размер заработной платы. 7. Информация об участниках спортивных соревнований содержит: Ф.И.О. игрока, игровой номер, возраст, рост, вес, наименование страны, название команды. Вывести информацию о самой молодой команде. Ключ: возраст. 8. Для книг, хранящихся в библиотеке, задаются: номер книги, автор, название, год издания, издательство и количество страниц. Вывести список книг с фамилиями авторов в алфавитном порядке, изданных после заданного года. Ключ: автор. 9. Различные цеха завода выпускают продукцию нескольких наименований. Сведения о продукции включают: наименование, количество, номер цеха. Для заданного цеха необходимо вывести изделия по каждому наименованию в порядке убывания их количества. Ключ: количество выпущенных изделий. 10. Информация о сотрудниках предприятия содержит: Ф.И.О., номер отдела, должность, дату начала работы. Вывести списки сотрудников по отделам в порядке убывания стажа. Ключ: дата начала работы. 11. Ведомость абитуриентов, сдавших вступительные экзамены в университет, содержит: Ф.И.О., номер группы, адрес, оценки. Определить количество абитуриентов, проживающих в г. Минске и сдавших экзамены со средним баллом не ниже 8.5, вывести их фамилии в алфавитном порядке. Ключ: Ф.И.О. 12. В справочной аэропорта хранится расписание вылета самолетов на следующие сутки в виде: номер рейса, тип самолета, пункт назначения, время вылета. Вывести информацию для заданного пункта назначения в порядке возрастания времени вылета. Ключ: пункт назначения. 13. В кассе хранится информация о поездах на ближайшую неделю: дата выезда, пункт назначения, время отправления, число свободных мест. Необходимо зарезервировать m мест до города N на k-й день недели с временем отправления поезда не позднее t часов. Вывести время отправления или сообщение о невозможности выполнить заказ. Ключ: число свободных мест. 14. Ведомость абитуриентов, сдавших вступительные экзамены в университет, содержит: Ф.И.О. абитуриента, 4 оценки. Определить средний балл по университету и вывести список абитуриентов, средний балл которых выше среднего балла по университету в порядке убывания балла. Ключ: средний балл. 15. В ателье хранятся квитанции о сданной в ремонт аппаратуре в виде: наименование группы изделий (телевизор, радиоприемник и т.п.), марку изделия, дату приемки, состояние готовности заказа (выполнен, не выполнен). Вывести информацию о состоянии заказов на текущие сутки по группам изделий.Ключ: дата приемки в ремонт. 16. Информация о сотрудниках института содержит: Ф.И.О., факультет, кафедру, должность, объем нагрузки (часов). Вывести списки сотрудников по кафедрам в порядке убывания нагрузки. Ключ: объем нагрузки. Односвязные списки Шаблон элемента структуры, информационной частью которого является целое число (аналогично стеку), будет иметь следующий вид: struct Spis1 { int info; Spis1 *next; } *begin, *end; // Указатели на начало и на конец Основные операции с очередью следующие: – формирование очереди; – обработка очереди (просмотр, поиск, удаление); – освобождение занятой памяти. Формирование очереди состоит из двух этапов: создание первого элемента и добавление нового элемента в конец очереди. Функция формирования очереди из данных объявленного выше типа Spis1 с добавлением новых элементов в конец может иметь следующий вид (b – начало очереди, e – конец): void Create(Spis1 **b, Spis1 **e, int in) { // in – переданная информация Spis1 *t = new Spis1; t -> info = in; // Формирование информационной части t -> next = NULL; // Формирование адресной части if(*b == NULL) // Формирование первого элемента *b = *e = t; else { // Добавление элемента в конец (*e) -> next = t; *e = t; } } Обращение к функции Create(& begin, & end, in); Алгоритмы просмотра и освобождения памяти выполняются аналогично рассмотренным ранее для Стека (см. л.р. 3). Двухсвязные списки Двухсвязным (двунаправленным) является список, в адресную часть которого кроме указателя на следующий элемент включен и указатель на предыдущий. Зададим структуру, в которой адресная часть состоит из указателей на предыдущий (prev) и следующий (next) элементы: struct Spis2 { int info; Spis2 *prev, *next; } *begin, *end; Формирование двунаправленного списка проводится в два этапа – формирование первого элемента и добавление нового, причем добавление может выполняться как в начало (begin), так и в конец (end) списка. Создание первого элемента 1. Захватываем память под элемент: Spis2 *t = new Spis2; 2. Формируем информационную часть (t -> info = StrToInt(Edit1-> Text)); 3. Формируем адресные части: t -> next = t -> prev = NULL; 4. Устанавливаем указатели начала и конца списка на первый элемент: begin = end = t; Добавление элемента Добавить в список новый элемент можно как в начало, так и в конец. Захват памяти и формирование информационной части выполняются аналогично предыдущему алгоритму (п.п. 1-2). Если элемент добавляется в начало списка, то выполняется следующая последовательность действий: t -> prev = NULL; // Предыдущего нет t -> next = begin; // Связываем новый элемент с первым begin -> prev = t; // Изменяем адрес prev бывшего первого begin = t; // Переставляем указатель begin на новый В конец элемент добавляется следующим образом: t -> next = NULL; // Следующего нет t -> prev = end; // Связываем новый с последним end -> next = t; // Изменяем адрес next бывшего последнего end = t; // Изменяем указатель end Просмотр списка Просмотр списка можно выполнять с начала, или с конца списка. Просмотр с начала выполняется так же, как для однонаправленного списка (в функции View() лаб.раб. 3 необходимо изменить структурный тип). Просмотр списка с конца 1. Устанавливаем текущий указатель на конец списка: t = end; 2. Начало цикла, работающего до тех пор, пока t ! = NULL. 3. Информационную часть текущего элемента t -> info выводим на экран. 4. Переставляем текущий указатель на предыдущий элемент, адрес которого находится в поле prev текущего элемента: t = t -> prev; 5. Конец цикла. Бинарное дерево поиска Наиболее часто для работы со списками используются бинарные (имеющие степень 2) деревья (рис. 6.1). В дереве поиска ключи расположены таким образом, что значения ключа у левого сына имеет значение меньшее, чем значение предка, а правого сына – большее. Сбалансированными, или AVL-деревьями, называются деревья, для каждого узла которых высó ты его поддеревьев различаются не более чем на 1. Дерево по своей организации является рекурсивной структурой данных, поскольку каждое его поддерево также является деревом. В связи с этим действия с такими структурами чаще всего описываются с помощью рекурсивных алгоритмов.
При работе с бинарным деревом простейшего вида, т.е. ключами которого являются целые числа (уникальные, т.е. не повторяются), необходимо использовать структуру следующего вида: struct Tree { int info; Tree *left, *right; } *root; // root - указатель корня В общем случае при работе с деревьями необходимо уметь: – сформировать дерево (добавить новый элемент); – обойти все элементы дерева (например, для просмотра или выполнения некоторой операции); – выполнить поиск элемента с указанным значением в узле; – удалить заданный элемент. Формирование дерева поиска состоит из двух этапов: создание корня, являющегося листом, и добавление нового элемента (листа) в найденное место. Для этого используется функция формирования листа: Tree* List(int inf) { Tree *t = new Tree; // Захват памяти t -> info = inf; // Формирование информационной части t -> left = t -> right = NULL; // Формирование адресных частей return t; // Возврат созданного указателя } 1. Первоначально (root = NULL), создаем корень ( первый лист дерева ): root = List (StrToInt(Edit1-> Text)); 2. Иначе (root! = NULL) добавляем информацию (key) в нужное место: void Add_List(Tree *root, int key) { Tree *prev, *t; // prev – указатель предка нового листа bool find = true; t = root; while ( t & & find) { prev = t; if( key == t-> info) { find = false; // Ключ должен быть уникален ShowMessage(" Dublucate Key! " ); } else if ( key < t -> info ) t = t -> left; else t = t -> right; } if (find) { // Нашли нужное место t = List(key); // Создаем новый лист if ( key < prev -> info ) prev -> left = t; else prev -> right = t; } } Метод простой итерации Функцию f(x) записывают в виде разрешенном, относительно x: x = j(x). (7.1) Переход от записи исходного уравнения к эквивалентной записи (7.1) можно сделать многими способами, например, положив j(x) = x + y(x)× f(x), (7.2) где y(x) – произвольная, непрерывная, знакопостоянная функция (часто достаточно выбрать y = const). Члены рекуррентной последовательности в методе простой итерации вычисляются по правилу xk = j(xk-1); k = 1, 2, … Метод является одношаговым, т.к. для начала вычислений достаточно знать одно начальное приближение x0 = a, или x0 = b, или x0 = (a + b)/2. Метод секущих Данный метод является модификацией метода Ньютона, позволяющей избавиться от явного вычисления производной путем ее замены приближенной формулой: xk = xk-1 – f(xk-1)× q / [ f(xk-1) – f(xk-1 – q)] = j(xk-1), k = 1, 2, … Здесь q – некоторый малый параметр метода, который подбирается из условия наиболее точного вычисления производной (q = h). Метод Вегстейна Этот метод является модификацией предыдущего метода секущих. В нем при расчете приближенного значения производной используется вместо точки xk-1 – q ранее полученная точка xk-2. Расчетная формула метода Вегстейна: xk = xk-1 – f(xk-1)× (xk-1 – xk-2) / [ f(xk-1) – f(xk-2)] = j(xk-1, xk-2), k = 1, 2, … Метод является двухшаговым (m = 2), и для начала вычислений требуется задать 2 начальных приближения x0 = a, x1 = b. Функция, реализующая данный метод может иметь вид: double Metod1(type_f f, double x0, double x1, double eps) { double y0, y1, x2, de; y0=f(x0); y1=f(x1); do { x2=x1-y1*(x1-x0)/(y1-y0); de=fabs(x1-x2); x0=x1; x1=x2; y0=y1; y1=f(x2); } while (de> eps); return x2; // Возвращаем значение, для которого достигнута точность } Понятие аппроксимации Одной из наиболее часто встречающихся задач является установление характера зависимости между различными величинами, что позволяет по значению одной величины определить значение другой. Математической моделью зависимости одной величины от другой является понятие функции y = f(x). В практике расчетов, связанных с обработкой экспериментальных данных, вычислением f(x), разработкой вычислительных методов, встречаются следующие ситуации: - установить вид функции y = f(x), если известны только некоторые значения, заданные таблицей {(xi, yi), i = 1, …, m}; - упростить вычисление известной функции f(x) или ее характеристик (производной, максимума и т.п.), если f(x) имеет слишком сложный вид. Ответы на эти вопросы даются теорией аппроксимации функций, основная задача которой состоит в нахождении функции y = j(x), близкой (т.е. аппроксимирующей) к исходной функции. Основной подход к решению этой задачи заключается в том, что аппроксимирующая функция j(x)выбирается зависящей от нескольких свободных параметров В зависимости от способа подбора параметров вектора Наиболее простой является линейная аппроксимация, при которой выбирают функцию
Здесь {j1(x), …, jn(x)} – известная система линейно независимых функций, в качестве которых могут быть выбраны любые элементарные функции или их комбинации. Важно, чтобы эта система была полной, т.е. обеспечивающей аппроксимацию f(x) многочленом (8.1) с заданной точностью при При интерполяции обычно используется система линейно независимых функций {jk(x) = xk-1}. Для среднеквадратичной аппроксимации удобнее в качестве jk(x) брать ортогональные на интервале [-1, 1] многочлены Лежандра: {j1(x) = 1; j2(x) = х; jk+1(x) = [(2k + 1)xjk(x) - kjk-1(x)]; k = 2, 3, …, n};
Интерполяция является одним из способов аппроксимации функций. Суть ее состоит в следующем. В области значений x, представляющей некоторый интервал [a, b], где функции f и jдолжны быть близки, выбирают упорядоченную систему точек (узлов) В случае линейной аппроксимации (8.1) система для нахождения коэффициентов
Для большинства практически важных приложений при интерполяции наиболее удобны обычные алгебраические многочлены. Интерполяционным многочленом называют алгебраический многочлен степени n - 1, совпадающий с аппроксимируемой функцией в выбранных n точках. Общий вид алгебраического многочлена Наиболее часто в приложениях используют интерполяционные многочлены в форме Лагранжа и Ньютона, т.к. многочлены в этой форме прямо записаны через значения таблицы {(xi, yi), i = 1, …, n}. Формула средних Формула средних получается, если на каждом i-м отрезке взять один центральный узел xi+1/2 = (xi + xi+1)/2, соответствующий середине отрезка. Функция на каждом отрезке аппроксимируется многочленом нулевой степени (константой) P0(x) = yi+1/2 = f(xi+1/2). Заменяя площадь криволинейной фигуры площадью прямоугольника высотой yi+1/2 и основанием h, получим формулу средних (рис. 9.1):
Рис. 9.1
Формула трапеций Формула трапеций получается при аппроксимации функции f(x)на каждом отрезке [xi, xi+1]интерполяционным многочленом первого порядка, т.е. прямой, проходящей через точки
Рис. 9.2
Формула Симпсона Формула Симпсона получается при аппроксимации функции f(x)на каждом отрезке [xi, xi+1]интерполяционным многочленом второго порядка (параболой) c узлами xi, xi+1/2, xi+1. После интегрирования параболы получаем (рис.9.3)
Рис. 9.3 После приведения подобных членов получаем более удобный для программирования вид:
Формулы Гаусса При построении предыдущих формул в качестве узлов интерполяционного многочлена выбирались середины и (или) концы интервала разбиения. При этом оказывается, что увеличение количества узлов не всегда приводит к уменьшению погрешности, т.е. за счет удачного расположения узлов можно значительно увеличить точность. Суть методов Гаусса порядка n состоит в таком расположении n узлов интерполяционного многочлена на отрезке [xi, xi+1], при котором достигается минимум погрешности квадратурной формулы. Анализ показывает, что узлами, удовлетворяющими такому условию, являются нули ортогональнoго многочлена Лежандра степени n (см. подразд. 8.1). Для n = 1 один узел должен быть выбран в центре отрезка, следовательно, метод средних является методом Гаусса 1-го порядка. Для n = 2 узлы должны быть выбраны следующим образом:
и соответствующая формула Гаусса 2-го порядка имеет вид
Для n = 3 узлы выбираются следующим образом:
и соответствующая формула Гаусса 3-го порядка имеет вид
9.2. Пример выполнения задания Написать и отладить программу вычисления интеграла от функции f(x) = 4x - 7sinx на интервале [-2, 3] методом Симпсона с выбором: по заданному количеству разбиений n и заданной точности e. Панель диалога будет иметь вид, представленный на рис. 9.4. Как и в предыдущих примерах, приведем только тексты функций-обработчиков соответствующих кнопок: typedef double (*type_f)(double); double fun(double); double Simps(type_f, double, double, int); //--------------------- Текст функции-обработчика кнопки РАСЧЕТ -------------------- double a, b, x, eps, h, Int1, Int2, pogr; int n, n1; a = StrToFloat(Edit1-> Text); b = StrToFloat(Edit2-> Text); eps = StrToFloat(Edit3-> Text); n = StrToInt(Edit4-> Text); h = (b - a)/100; // Шаг вывода исходной функции Chart1-> Series[0]-> Clear(); for(x = a-h; x< b+h; x+=h) Chart1-> Series[0]-> AddXY(x, fun(x)); switch(RadioGroup2-> ItemIndex) { case 0: Memo1-> Lines-> Add(" Расчет по разбиению на n = " + IntToStr(n)); Int1 = Simps(fun, a, b, n); break; case 1: n1=2; Memo1-> Lines-> Add(" Расчет по точности eps" ); Int1 = Simps(fun, a, b, n1); do { n1*=2; Int2 = Simps(fun, a, b, n1); pogr = fabs(Int2-Int1); Int1 = Int2; } while(pogr > eps); Memo1-> Lines-> Add(" При n = " +IntToStr(n1)); break; } Memo1-> Lines-> Add(" Значение интеграла = " + FloatToStrF(Int1, ffFixed, 8, 6)); //------------------------- Метод Симпсона ------------------------------- double Simps(type_f f, double a, double b, int n) { double s=0, h, x; h=(b-a)/n; x=a; for(int i=1; i< =n; i++) { s+=f(x)+4*f(x+h/2)+f(x+h); x+=h; } return s*h/6; } //----------------- Подынтегральная функция f(x) --------------------- double fun(double x) { return 4*x - 7*sin(x); // На интервале [-2, 3] значение 5, 983 }
Рис. 9.4 9.3. Индивидуальные задания Написать и отладить программу вычисления интеграла указанным методом двумя способами – по заданному количеству разбиений n и заданной точности e (метод 1). Реализацию указанного метода оформить отдельной функцией, алгоритм которой описать в виде блок-схемы. Таблица 9.1
Литература 1. Бусько, В. Л. Основы программирования в среде С++ Builder: лаб.практикум по курсу «Основы алгоритмизации и программирования» для студ. 1 – 2-го курсов БГУИР. В 2 ч. Ч. 1 / Бусько В. Л. [и др.]. – Минск: БГУИР, 2007. 2. Батура, М. П. Основы алгоритмизации и программирования. Язык Си: учеб.пособие / М. П. Батура, В. Л. Бусько, А. Г. Корбит, Т. М. Кривоносова. – Минск: БГУИР, 2007. 3. Синицын, А. К. Программирование алгоритмов в среде Builder C++: лаб.практикум по курсам «Программирование» и «Основы алгоритмизации и программирование» для студ. 1-2 курсов всех спец. БГУИР дневн. и веч. форм обуч.: в 2 ч. / А. К. Синицын – Минск: БГУИР. Ч. 1. – 2004, Ч. 2. – 2005. 4. Вирт, Н. Алгоритмы и структуры данных / Н. Вирт – СПб.: Невский диалект, 2001. 7. Архангельский, А. Я. Программирование в С++ Builder 6 / А. Я. Архангельский. – М.: ЗАО “Издательство БИНОМ”, 2002. 8. Демидович, Е. М. Основы алгоритмизации и программирования. Язык СИ / Е. М. Демидович. – Минск: Бестпринт, 2001. 9. Кнут, Д. Искусство программирования: т. 1–3. Основные алгоритмы / Д. Кнут – М.: Издательский дом «Вильямс», 2004. 10. Топп, У. Структуры данных в С++: пер. с англ. / У. Топп, У. Форд – М.: ЗАО «Издательство БИНОМ», 2000. 11. Синицын, А. К. Алгоритмы вычислительной математики: учебно-метод. пособие по курсу «Основы алгоритмизации и программирования» / А. К. Cиницын, А. А. Навроцкий. – Минск: БГУИР, 2007. 12. Калиткин, Н. Н. Численные методы / Н. Н. Калиткин – М.: Наука, 1978. 13. Бахвалов, Н. С. Численные методы / Н. С. Бахвалов – М.: Наука, 1975. 14. Егоров, А. А. Вычислительные алгоритмы линейной алгебры: учеб. пособие / А. А. Егоров – Минск: БГУ, 2005. 15. Волков, Е. А. Численные методы / Е. А. Волков – М.: Наука, 1982. 16. Васильков, Ю. В. Компьютерные технологии вычислений в математическом моделировании / Ю. В. Васильков, Н. Н. Василькова – М.: Финансы и статистика, 2001. 17. Крылов, В. И. Вычислительные методы высшей математики. Т.1 / В. И. Крылов и др. – Минск: Выш. шк., 1972. 18. Крылов, В. И. Вычислительные методы высшей математики. Т.2 / В. И. Крылов и др. – Минск: Выш. шк., 1975.
Популярное:
|
Последнее изменение этой страницы: 2016-07-13; Просмотров: 847; Нарушение авторского права страницы
 m исключаются из дальнейшего поиска, иначе – исключаются все элементы с индексами i> m.
m исключаются из дальнейшего поиска, иначе – исключаются все элементы с индексами i> m. , т.е.
, т.е.  , значения которых подбираются из условия близости f(x)и j(x).
, значения которых подбираются из условия близости f(x)и j(x). получают различные методы аппроксимации.
получают различные методы аппроксимации. 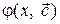 , линейно зависящую от параметров
, линейно зависящую от параметров 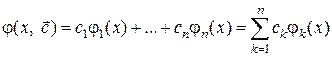 . (8.1)
. (8.1)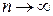 .
.  .
. (обозначим
(обозначим  ), число которых равно количеству искомых параметров
), число которых равно количеству искомых параметров  . Далее параметры
. Далее параметры  . (8.2)
. (8.2) . (8.3)
. (8.3) . (9.1)
. (9.1)
 ,
,  . Площадь криволинейной фигуры заменяется площадью трапеции с основаниями
. Площадь криволинейной фигуры заменяется площадью трапеции с основаниями  и высотой h (рис.9.2):
и высотой h (рис.9.2): 
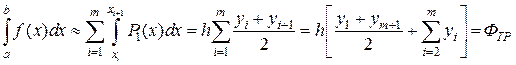 . (9.2)
. (9.2)
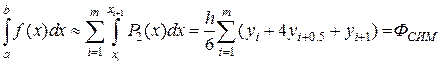 . (9.3)
. (9.3) .
. ,
,  .
. ,
,  .
.