
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
ИНФОРМАЦИЯ, ЕЕ КОЛИЧЕСТВО И КАНАЛЫ ПЕРЕДАЧИ
2.1. Характеристики системы передачи информации
Передача информации (данных) осуществляется между двумя абонентами, называемыми источником сообщения (ИС) и получателем сообщения (ПС). Источником и получателем могут быть люди либо технические средства. ИС и ПС обмениваются информацией посредством канала передачи. Таким образом, простейшая информационная система состоит из трех перечисленных элементов. Ее обобщенная структурная схема приведена на рис. 2.1.
Рис. 2.1. Обобщенная структурная схема информационной системы (системы передачи информации)
В современных информационных системах качество передачи достигается применением трех базовых методов преобразования информации: 1) помехоустойчивого кодирования; 2) сжатия (компрессии) данных; 3) криптографического преобразования. Информационной характеристикой алфавита (источника сообщений на основе этого алфавита) является энтропия. Этот термин применительно к техническим системам был введен Шенноном и Хартли. Энтропию алфавита
Заметим, что С физической точки зрения энтропия показывает, какое количество информации приходится в среднем на один символ алфавита. Частным случаем энтропии Шеннона является энтропия Хартли. Дополнительным условием при этом является то, что все вероятности одинаковы и постоянны для всех символов алфавита. С учетом этого формулу (2.1) можно преобразовать к следующему виду: Например, энтропия Хартли для латинского (английского) алфавита составляет 4, 7 бит. Если подсчитать энтропию Шеннона и энтропию Хартли для одного и того же алфавита, то они окажутся не равными. Это несовпадение указывает на избыточность любого алфавита (при Сообщение
Нетрудно предположить и просто убедиться, что количество информации в сообщении, подсчитанное по Шеннону, не равно количеству информации, подсчитанному по Хартли. На основе этого парадокса строятся и функционируют все современные системы сжатия (компрессии) информации.
Суть метода состоит в преобразовании исходного информационного сообщения Xk (k – длина сообщения), называемого также информационным словом. К слову Xk дополнительно присоединяют (наиболее часто – по принципу конкатенации) избыточные символы длиной r бит, составляющие избыточное слово Xr. Таким образом, формируют кодовое слово Xn длиной n = k + r двоичных символов: Xn = Xk Xr. Информацию содержит только информационное слово. Назначение избыточности Xr – обнаружение и исправление ошибок. Вес по Хеммингу произвольного двоичного слова Х (w(X)) равен количеству ненулевых символов в слове. Пример 3.1. X = 1101. Тогда w(X = 1101) = 3. Расстояние по Хеммингу или кодовое расстояние (d) между двумя произвольными двоичными словами (X, Y) одинаковой длины равно количеству позиций, в которых X и Y отличаются между собой.

Пример 3.2. X = 101, Y = 111. Очевидно, что d(X, Y) = 1. Кодовое расстояние можно вычислить как вес от суммы по модулю 2 этих двух слов: d(X, Y) = w(X Å Y). Длина слова и расстояние Хемминга – основополагающие понятия в теории помехоустойчивого кодирования информации. Все многообразие существующих кодов для обнаружения и исправления ошибок можно разделить на два больших класса: линейные и нелинейные коды. Коды первого класса базируются на использовании линейных (как правило, умножение и сложение по модулю 2 соответствующих символов) операций над данными, коды второго класса – соответственно нелинейных операций. 3.2. Теоретические основы линейных блочных кодов
Линейные блочные коды – это класс кодов с контролем четности, которые можно описать парой чисел (п, k). Первое из чисел определяет длину кодового слова Xn, второе – длину информационного слова Xk. Отношение числа бит данных к общему числу бит данных k/n именуется степенью кодирования (code rate) – доля кода, которая приходится на полезную информацию. Для формирования проверочных символов (кодирования) используется порождающая матрица. Совокупность базисных векторов будем далее записывать в виде матрицы G размерностью k × n с единичной подматрицей I в первых k строках и столбцах: Матрица G называется порождающей матрицей линейного корректирующего кода в приведенно-ступенчатой форме. Кодовые слова являются линейными комбинациями строк матрицы G (кроме слова, состоящего из нулевых символов). Кодирование, результатом которого является кодовое слово Xn, заключается в умножении вектора сообщения длиной k (Xk) на порождающую матрицу по правилам матричного умножения (все операции выполняются по модулю 2). Очевидно, что при этом первые k символы кодового слова равны соответствующим символам сообщения, а последние r символов (Xr) образуются как линейные комбинации первых. Для всякой порождающей матрицы G существует матрица Н размерности r × n, задающая базис нулевого пространства кода и удовлетворяющая равенству: Матрица Н, называемая проверочной, может быть представлена так: В последнем выражении I – единичная матрица порядка r. Кодовое слово Xn может быть получено на основе следующего тождества:
Результат умножения сообщения Yn на транспонированную проверочную матрицу Н называется синдромом (вектором ошибки) S:
где Yn = у1, у2, …, уn. Слово Yn обычно представляют в следующем виде:
где Е = е1, е2, …, еn – вектор ошибки. Если все r символов синдрома нулевые (S = 0), то принимается решение об отсутствии ошибок в принятом сообщении, в противном случае – об их наличии. В общем случае код, характеризующийся минимальным кодовым расстоянием dmin между двумя произвольными кодовыми словами, позволяет обнаруживать t0 ошибок, где
Избыточный код простой четности. Простейший избыточный код основан на контроле четности (либо нечетности) единичных символов в сообщении. Количество избыточных символов r всегда равно 1 и не зависит от k. Значение этого символа будет нулевым, если сумма всех символов кодового слова по модулю 2 равна нулю. Назначение Xr в данном алгоритме – обнаружение ошибки. Код простой четности позволяет обнаруживать все нечетные ошибки (нечетное число ошибок), но не позволяет их исправить. Нетрудно убедиться, что данный код характеризуется минимальным кодовым расстоянием, равным 2. Пример 3.5. Пусть информационная последовательность будет Xk = 10101, тогда Проверочная матрица для данного случая будет состоять из одной строки и шести столбцов и примет следующий вид: Н = 11111 1. Кодовое слово Xn, вычисленное в соответствии с (3.4), будет равно 10101 1. Как видим, w(Xn) имеет четное значение. Слово Xn будет передаваться от ИС к ПС. Пусть на приемной стороне имеем Yn = 11101 1: Yk = 11101 и Yr = 1 (ошибочный символ подчеркнут). Для определения синдрома ошибки в соответствии с (3.5) достаточно выполнить следующие простые действия: а) вычислить дополнительное слово (в данном случае – символ) б) найти синдром
Код Хемминга Данный кодхарактеризуется минимальным кодовым расстоянием dmin = 3. При его использовании кодирование сообщения также должно удовлетворять соотношению (3.4). Причем вес столбцов подматрицы А должен быть больше либо равен 2. Второй особенностью данного кода является то, что используется расширенный контроль четности групп символов информационного слова, т. е. r > 1. Для упрощенного вычисления r можно воспользоваться следующим простым соотношением:
В сравнении с предыдущим кодом данный позволяет не только обнаруживать, но и исправлять одиночную ошибку в кодовом слове (см. (3.7)). В нашем случае подматрицу А можно определить как
Элемент этой подматрицы (0 или 1) hij относится к i-й строке и j-му столбцу ( Вычислим проверочные символы в соответствии с (3.4):
Определим синдром: Таким образом, код Хемминга с dmin = 3 гарантированно обнаруживает и исправляет одиночную ошибку в любом разряде кодового слова. Популярное:
|
Последнее изменение этой страницы: 2017-03-03; Просмотров: 682; Нарушение авторского права страницы

 по Шеннону рассчитывают по следующей формуле:
по Шеннону рассчитывают по следующей формуле:  (2.1)
(2.1)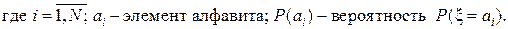


 ).
). которое состоит из
которое состоит из  символов, должно характеризоваться определенным количеством информации
символов, должно характеризоваться определенным количеством информации  :
:  . (2.2)
. (2.2) (3.1)
(3.1) (3.2)
(3.2) . (3.3)
. (3.3) (3.4)
(3.4) (3.5)
(3.5) (3.6)
(3.6) , если d – четно, и
, если d – четно, и  , если d – нечетно. Количество исправляемых кодом ошибок tи определяется следующим образом:
, если d – нечетно. Количество исправляемых кодом ошибок tи определяется следующим образом: 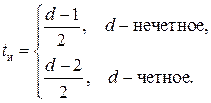 (3.7)
(3.7) .
. которое является сверткой по модулю 2 слова Yk:
которое является сверткой по модулю 2 слова Yk:  =
=  ;
;  . Неравенство синдрома нулю означает, что получено сообщение с ошибкой (или с ошибками).
. Неравенство синдрома нулю означает, что получено сообщение с ошибкой (или с ошибками). (3.8)
(3.8)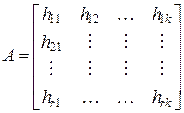 . (3.9)
. (3.9) ).
). (3.10)
(3.10) (3.11)
(3.11)