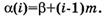|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Последовательная организация.⇐ ПредыдущаяСтр 12 из 12
Если отведенная память для СУБД – это логически связанная последовательность, то для файловой системы – это последовательность кластеров. Последовательное распределение – простой и естественный способ хранения линейного списка. В этом случае узлы списка размещаются в последовательных элементах памяти. Нужно иметь доступ к любой записи и обеспечить эффективность следующих операций с ними: – чтение записи; – модификация записи; – удаление записи. Длина записи может быть фиксированной или переменной. а) Записи фиксированной длины Записи размещаются последовательно непосредственно друг за другом. Вектор данных логически отделен от описания структуры хранимых данных. Например, если структура данных представляет собой линейный список (файл записей фиксированной длины), то описание структуры хранится в отдельной записи и содержит: а) N – размер вектора данных, т.е. количество элементов списка записей; б) т – размер элемента списка, т.е. размер записи, например, в байтах; в) β – адрес базы, указывающий на начало вектора данных в памяти.
В этом случае адрес каждой записи можно вычислить с помощью адресной функции, отображающей логический индекс, идентифицирующий запись в структуре, в адрес физической памяти
б) Записи имеют различную длину При неравной длине записей для определения границ между записями требуются дополнительные средства. Это может быть хранение в записи адреса начала следующей записи или длины текущей записи, введение специальных меток начала (конца) записи. При неравной длине записи выборка замедляется из-за необходимости последовательного перебора до нужной записи. Для повышения быстродействия в этом случае может использоваться искусственное выравнивание записей.
1) Хранение адреса следующей записи
2) Хранение длины следующей записи
3) Выравнивание записей.
Добавление записи при последовательной организации трудоемко из-за необходимости перемещения всех записей, следующих за добавляемой, для освобождения места под новую запись. Поэтому прямая вставка не эффективна, рекомендуется добавление в конец. При страничной организации для улучшения характеристик применяют неполное заполнение страниц, что позволяет локализовать перемещение записей одной страницей. Аналогичные трудности возникают при операции удаления, когда записи перемещаются для заполнения освободившегося места. Здесь для повышения быстродействия и для избавления от массовой перезаписи файла часто используется пометка записей на удаление без немедленного сжатия данных. При этом разделяют физическое и логическое удаление (например, в Visual Fox Pro: PACK – физическое удаление, DELETE – логическое удаление. Физическое удаление предполагает монопольный режим и выполняется медленно, поэтому вызывается редко). Модификация записи при равной длине выполняется просто, но при неравной длине записей снова могут возникать проблемы, связанные с необходимостью перезаписи больших объемов данных. При записях одинаковой длины, просто добавляется в пустое место или в конец, иначе при записях неодинаковой длины – запись в конец. Для повышения эффективности доступа применяют также выравнивание записей. Для этого существует два метода: 1) Выполняется поиск записи максимальной длины, выполняется расширение до этого размера (плюс некоторый запас) всех строк. Используется: когда разброс длин невелик и длина небольшая. (VARCHAR – строка переменной длины). 2) Невыравненные части записей выносятся в отдельное хранение. Используется при большом разбросе длин записей (Например, в VisualFoxPro используется описание " memo", в InterBase – " blob", указатель занимает 4 байта).
Списковое хранение Связанное представление линейного списка называется связанным списком. При связанном распределении памяти для построения структуры необходимо задать отношения следования и предшествования элементов с помощью указателей. Указателями служат адреса, хранимые в записях данных. В отличие от последовательного распределения памяти, при котором с помощью адресной функции вычисляется адрес следующего элемента, при связанном распределении памяти значение адресной функции можно получить только путем просмотра хранящихся указателей. Такой метод распределения памяти позволяет расширить либо сократить структуру без перемещения самих данных в памяти ЭВМ, однако при этом требуется больше памяти для хранения структуры по сравнению с последовательным распределением. Связанное распределение – более сложный, но и более гибкий способ хранения линейного списка. Каждый узел содержит указатель на следующий узел списка, т.е. адрес следующего узла списка. При связанном распределении не требуется, чтобы список хранился в последовательных элементах памяти. Наличие адресов связи в данном способе хранения позволяет размещать узлы списка произвольно в любом свободном участке памяти. При этом линейная структура списка обеспечивается указателями.
Примеры связанных линейных списков: а) однонаправленный список; б) тот же список после удаления узла 4 и включения узлов 2а и 5
Свободное размещение записей, связанных указателями, затрудняет выборку нужной записи из-за необходимости последовательного перемещения по указателям до нужного места. Для операций же добавления, удаления и модификации записи списковая организация обеспечивает высокое быстродействие, т.к. обработке подвергаются только обрабатываемая запись и связанные с ней указатели в смежных записях. Для повышения эффективности и возможности перемещения по списку в обоих направлениях используется двунаправленный список.
Важной разновидностью представления в памяти линейного списка является циклический список.Циклически связанный линейный список обладает той особенностью, что связь от последнего узла идет к первому узлу списка. Циклический список позволяет получить доступ к любому узлу списка, отправляясь от любого заданного узла. Циклические списки называются также кольцевыми структурами или кольцами.
Однонаправленный циклический список
Использование списковой организации приводит к необходимости решать дополнительную задачу управления свободной памятью, которая по мере работы с записями динамично меняет свой размер и подвергается все большей фрагментации (разбросана мелкими кусками по всей базе). Для учета свободных мест в отведенной области используются два основных подхода: 1) Пометка свободных позиций специальным кодом. Недостаток – потеря времени на поиск достаточного свободного места для размещения новой записи.
2) Ведения списка пустых (свободных) блоков, связанных аналогично записям указателями, для соединения их в одну последовательность. В каждой пустой записи хранится указатель на следующий блок и длина этого свободного блока.
Индексная организация Записи размещаются в отведенной области произвольно, для указания местоположения и логической последовательности записей используется индекс – дополнительный линейный список. При простейшей организации индекс представляет собой фактически последовательно упорядоченный набор указателей, перемещенных из отдельных записей в единое место хранения.
Линейный связанный список с индексом
Хэшированная организация Записи размещаются в отведенной области по вычисляемым адресам. Адрес хранения записи расчитывается по значениям ключа хэширования (поля или набора полей) для данной записи. Выборка записи выполняется из адреса, вычисленного для требуемого значения ключа хэширования. Таким образом, вместо поискового перебора записей выполняется прямое обращение к нужному адресу памяти. Проблемой хэшированной организации являются возможные конфликты наложения записей.
В целом можно указать, что последовательная организация имеет простую реализацию, но низкое быстродействие для всех операций, кроме выборки при равной длине записей. Списковая и индексная организации связаны с более сложной реализацией, но обеспечивают высокое быстродействие для большинства операций.
17. Методы поиска в БД Производительность программной системы во многом зависит от методов доступа к данным. Поэтому, если есть возможность выбора СУБД, знание используемых в ней алгоритмов работы с данными может быть полезным. Простейший вариант поиска в таблице БД состоит в поиске (выборке) записи с заданным порядковым номером. При последовательном равномерном размещении записей выполняется быстрый поиск путем прямого вычисления местонахождения записи, при других вариантах организации размещения записей приходится использовать медленный последовательный поиск. Однако поиск по номеру записи не является для БД основным, а играет чаще вспомогательную техническую роль в других видах поиска. Характерным же для БД является поиск записи по содержанию информации, хранящейся в ней. Рассмотрим методы поиска подходящей записи в БД по информации, содержащейся в некотором поле записи (поиск по ключу). Типичными являются следующие методы поиска:
1. Последовательный поиск: Записи просматриваются последовательно, начиная с первой. Для каждой записи значение поля поиска сравнивается со значением ключа поиска. Окончание поиска – по соответствию значения поля искомому значению. В целом, последовательный поиск имеет очень низкое быстродействие и применим только для небольших таблиц. К достоинствам поиска относятся простота выполнения и универсальность, основывающаяся на отсутствии необходимости в поддержке служебных данных, упорядочиваний и т.д. Для ускорения поиска можно использовать упорядочивание по значению записей. Выигрыш - если при просмотре запись не нашлась, то часть таблицы, которая ниже нужной, не просматривается. Но при этом проигрываем в том, что необходимо поддерживать упорядоченность. Можно упорядочить по важности информации. И если чаще нужна наиболее важная информация, то чаще всего поиск будет заканчиваться на наиболее важной информации. Последовательный поиск используется в последовательной и списковой организации. Метод не применяется там, где необходим быстрый доступ к данным большого объема. Но его можно использовать в тех случаях, когда по характеру задачи следует выбирать записи последовательно (например, полное копирование данных), а также при очень небольших объемах данных в силу простоты алгоритма доступа.
Блочный поиск. Записи разбиты на блоки, упорядочены по значению поля поиска. Выполняется последовательная проверка, но, в отличие от предыдущего метода, производится не сплошная, а выборочная проверка записей. Проверяются записи, выбираемые с принятым шагом (по числу записей, по размеру блока памяти). В итоге для проверяемого блока определяется возможность наличия записи. Если это так, то выполнется поиск внутри блока. Данный вид поиска характерен для страничной организации памяти. При этом записи размещаются по страницам упорядоченно по ключу, и каждая проверка определяет наличие искомой записи в очередной проверяемой странице.
Бинарный поиск Записи для применения поиска должны быть упорядочены по ключу. При каждой проверке проверяется центральная запись области поиска. В результате проверки либо обнаруживается искомая запись, либо из поиска исключается верхняя или нижняя половина области поиска. В оставшейся области снова проверяется центральная запись и так далее. Таким образом, в бинарном поиске реализуется алгоритм деления пополам. Если записи имеют фиксированную длину, то смещаемся на нужную запись, если длина записей нефиксированная, то смотрим по меткам, то есть обращаемся в середину памяти и смещаемся далее до первой встретившейся метки. Теоретически данный метод является самым быстрым, но реальная его эффективность снижается из-за потерь на обращение к внешнему носителю для считывания отдельных разрозненный записей.
Индексный поиск Наиболее распространенный в БД метод поиска. В основе индексных методов доступа лежит создание вспомогательной структуры – индекса, содержащего ключи поиска и ссылки на физические адреса данных. Термин «ключ поиска» не обязательно подразумевает его уникальность, это просто атрибут (комбинация атрибутов), который должен удовлетворять критерию поиска. Индекс хранит описание логической последовательности записей по заданному ключу. Он представляет собой структуру, при обращении к которой входными данными является искомое значение ключа, а выходным – указатель на запись, содержащую это значение (или указание на отсутствие подходящей записи). Требуемая упорядоченность по ключу поиска поддерживается индексом, в котором и проводится поиск. Доступ к данным производится в два этапа. Вначале в индексе (индексном файле) находятся требуемые значения ключей, затем из основного файла по ссылке извлекается требуемая информация. Производительность системы в целом может стать достаточно высокой. Для ее увеличения обычно требуют, чтобы индекс целиком размещался в оперативной памяти. Факторами ускорения поиска являются: - меньшее число проверок при выполнении поиска за счет упорядоченности данных в индексе; - быстрая выборка проверяемой позиции индекса за счет небольшого объема индекса и выравненности размеров позиций; - отсутствие необходимости расчета проверяемого значения для записей, т.к. в индексе хранятся уже рассчитанные значения. Индексы могут быть устроены по-разному. Различаются первичные и вторичные индексы в зависимости от вида ключа поиска. Если поиск и выборка производится по комбинации атрибутов (индексному выражению), соответствующий индекс называется составным. Индекс, построенный на иерархии ссылок, называется многоуровневым. Индекс, который содержит ссылки не на все записи, а на некоторый диапазон, называется неплотным. Плотный индекс содержит ссылки на все записи. Элемент индекса часто называют статьей. Существует множество индексных методов доступа. Внутренняя организация индекса может основываться на последовательной или списковой организации данных. Простейшей и сравнительно малоэффективной является последовательная организация. В этом случае в индексе хранятся упорядоченные по значению ключа пары «значение ключа – указатель на запись».
Недостаток такого индекса состоит в трудоемкости его модификации при добавлении, удалении, модификации контролируемых записей, что ограничивает область его применения в основном работой с постоянной и условно-постоянной информацией. При списковой организации индекса он строится в виде дерева. В основном используются два вида деревьев: бинарные и В-деревья. Узел бинарного дерева содержит одно значение ключа и две ссылки на подчиненные узлы: левую – на код дерева с меньшими значениями ключа, правую – на код дерева с большими значениями.
Бинарное дерево характеризуется большой глубиной и несбалансированностью ветвей, что снижает эффективность поиска. Например, заполнение дерева следующими значениями записей: 12, 35, 40, 100, 1, 2, 83, 5, 10, получим дерево, имеющее некоторые очень большие ветви, в то время как другие могут отсутствовать.
Реализация бинарного дерева позволяет сократить время поиска данных по сравнению с бинарным поиском, однако возрастает требуемый объем внешней памяти. Более сложные в организации В-деревья обеспечивают малую глубину дерева за счет размещения оптимального числа ключей и ссылок в узлах и сбалансированность ветвей за счет специальных алгоритмов построения дерева.
а) Неплотный индекс Пусть основной файл F упорядочен по полю ключа К. Построим дополнительный файл FD по следующему правилу: 1) записи файла FD имеют формат FD(K, Р), где К – поле, принимающее значение ключа первой записи блока основного файла F; Р – указатель на этот блок; 2) записи файла FD упорядочены по полю К.
Полученный файл FD называется неплотным индексом. Количество записей файла FD равно количеству блоков основного файла F. Для организации файла FD требуется дополнительная внешняя память. Поиск вначале выполняется в индексе для нахождения адреса блока основного файла, а за тем этот блок считывает в оперативную память и в нем, например, с помощью последовательного поиска, определяется требуемая запись.
В-дерево. Так как неплотный индекс упорядочен по ключевому полю, то над ним можно построить еще один неплотный индекс (неплотный индекс неплотного индекса) и т.д., пока на самом последнем, верхнем уровне не останется всего один блок. Полученная структура называется В-деревом порядка т, где т – количество записей в блоке индекса. Такое дерево должно иметь в каждом узле не менее т/2зависимых узлов и все листья должны располагаться на одном уровне.
Для осуществления последовательного поиска блоки первого уровня могут быть связаны в цепь по возрастанию значения ключа. Поиск в В-дереве выполняется так же, как и в неплотном индексе. Удачный и неудачный поиск записи в В-дереве требует h обменов, где h – число уровней В-дерева. При поиске по интервалу значений а ≤ К ≤ b вначале выполняется поиск по К = а в В-дереве, а затем – последовательный поиск по условию К ≤ b в блоках 1-го уровня В-дерева. б) Плотный индекс Пусть по каким-либо причинам невозможно упорядочить основной файл F по ключу К. Построим дополнительный файл FD по правилу: 1) записи файла FD имеют формат FD(K, Р), где К – поле, принимающее значение ключа записи основного файла F; Р – указатель на эту запись; 2) записи файла FD упорядочены по полю К.
Полученный файл называется плотным индексом. Он строится почти так же, как и неплотный индекс. Различие заключается в том, что для каждого значения ключа К в файле FD имеется отдельная запись, а в неполном индексе - только для значения ключа первой записи блока. Над плотным индексом можно также построить В-дерево.
Хешированный поиск Этот метод называется еще методом перемешанных таблиц. Он представляет собой расширение метода прямого доступа на случай отсутствия взаимно однозначного соответствия между ключом и адресом записи. Существует адресная функция (хеш-функция), которая по ключу формирует адрес, однако, не исключено, что один и тот же адрес выделится разным ключам. Быстродействие обеспечивается заменой переборных и поисковых процедур на прямое вычисление местоположения искомой записи по искомому значению ключа. Вычисление содержит три основных шага: 1) преобразование значения ключа в числовое значение (при нечисловом ключе), 2) хэширование, заключающееся в пересчете числового эквивалента ключа в значение рандомизированной переменной с предположительно равномерным законом распределения. Для пересчета используется выбранная хэш-функция, дающая желаемый эффект рандомизации, 3) масштабирование рандомизированной переменной для приведения получаемых значений к выделенному диапазону адресов памяти (определение адресов в памяти). Проблемой хэшированного поиска является наличие коллизий, выражающееся получением одинаковых значений адреса хранения записи для различающихся значений ключа. Для решения проблемы коллизий приходится принимать дополнительные меры, такие так выделение дополнительных областей памяти для размещения цепочек перекрывающихся записей. Этот алгоритм прост, но неэффективен по времени при заполнении таблицы более чем наполовину. Кроме того, при неравномерном распределении ключей этот алгоритм приводит к локальным сгущениям записей и увеличению числа коллизий при относительно свободной таблице.
Популярное:
|
Последнее изменение этой страницы: 2017-03-03; Просмотров: 676; Нарушение авторского права страницы