
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Сетевая и иерархическая модели
Важным этапом жизненного цикла информационной системы и, в частности, проектирования базы данных, является выбор целевой СУБД. Предлагаемые в разделе методы пригодны и к оценке новых продуктов, поступающих на рынок. Основная цель при подборе СУБД – выбор системы, удовлетворяющей текущим и прогнозируемым требованиям организации при оптимальном уровне затрат. В общем виде процесс выбора СУБД включает следующие этапы: 1) определение списка показателей, по которым будут оцениваться СУБД; 2) определение списка сравниваемых СУБД; 3) оценка продуктов по выбранным показателям; 4) принятие обоснованного решения, подготовка отчета. Для оценки СУБД могут использоваться самые разнообразные параметры, которые могут быть сгруппированы следующим образом: § параметры определения данных; § физические параметры; § параметры доступности; § параметры обработки транзакций; § утилиты; § средства разработки... и т.д. Даталогические модели данных Модель данных – фиксированная система понятий и правил для представления структуры данных, состояния и динамики проблемной области в базах данных. Как правило, задается языком определения данных и языком манипулирования данными. Примерами модели данных, получившими широкое распространение, являются модели данных сетевая, иерархическая, реляционная и др. Логическая модель описывает логическую организацию данных предметной области с учетом типа выбранной СУБД, но без относительно физической реализации хранения. Логическая модель учитывает ограничения, накладываемые видом модели и выбранной СУБД.
Модель данных состоит из трех компонент. 1. Структурная - с труктура данных для представления точки зрения пользователя на базу данных. Описывает допустимые структуры организации данных и способы их связывания. Пример: практически все СУБД не поддерживают связку многие ко многим. 2. М анипуляционная - д опустимые и необходимые операции, выполняемые на структуре данных. Они составляют основу языка данных рассматриваемой модели данных. Одной лишь хорошей структуры данных недостаточно. Необходимо иметь возможность работать с этой структурой при помощи различных операций языка определения данных и языка манипулирования данными. Богатая структура данных ничего не стоит, если нет возможности оперировать ее содержимым. 3. Ц елостностная - ограничения для контроля целостности. Определяет ограничения, накладываемые структурой, связями и набором операций. Модель данных должна быть обеспечена средствами, позволя ющими сохранять ее целостность и защищать ее.
Прежде, чем перейти к детальному и последовательному изучению получивших широкое распространение реляционных систем БД, целесообразно ознакомиться с ранними СУБД. В этом есть смысл по трем причинам: во-первых, эти системы исторически предшествовали реляционным, и для правильного понимания причин повсеместного перехода к реляционным системам нужно знать хотя бы что-нибудь про их предшественников; во-вторых, внутренняя организация реляционных систем во многом основана на использовании методов ранних систем; в-третьих, некоторое знание в области ранних систем будет полезно для понимания путей развития постреляционных СУБД.
Сетевая модель данных Строится по рекомендациям CODASYL (конференция по символьным языкам). С точки зрения теории графов сетевой модели соответствует произвольный граф (возможно имеющий циклы и петли). В узлах графа помещаются типы записей, а ребра интерпретируются как связи между типами записей. ─ Модель не накладывает ограничения на связи. ─ Узлы сети описывают типы объектов. ─ Дуги – связи между экземплярами разных типов. В описании базы включается множество описаний типов, множество описаний связей. Сетевая БД состоит из набора записей и набора связей между этими записями, а если говорить более точно, из набора экземпляров каждого типа из заданного в схеме БД набора типов записи и набора экземпляров каждого типа из заданного набора типов связи. Тип связи определяется для двух типов записи: предка и потомка. Экземпляр типа связи состоит из одного экземпляра типа записи предка и упорядоченного набора экземпляров типа записи потомка.
Для описания типа о писывается структура записи этого типа. Структура может быть линейной:
По минимуму надо хранить: имя, тип и размерность. Описание связок: Связь описывается набором. Описание набора содержит указание типа владельца набора, указание типа члена набора, описание характеристик связи.
Важный элемент описания связи – класс членства. Указывается для подчиненного типа. Для главного типа – указание связи не обязательно. Три класса членства: 1) Не обязательное членство: подчиненная запись не обязана иметь владельца. 2) Обязательное членство: подчиненная запись обязана иметь владельца, но может его сменить. 3) Фиксированное членство: подчиненная запись обязана иметь владельца и не может его сменить. По соединениям типов разрешается: 1) множественное владение:
2) множественное членство:
3) множественное связывание двух:
4) рекурсивная (петлевая) связь:
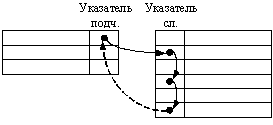
По соединениям типов НЕ разрешается: 1) Отношение " многие ко многим". 2) Включение экземпляра в несколько связей из одного набора. Связывание реализуется с помощью физических указателей: Основной вариант – кольцо:
Сетевая модель базы при выборке работает медленнее, чем реляционная.
Пример: Найти сотрудника Иванова и найти его отпуска. Достоинства сетевой модели: ─ высокое быстродействие ─ компактность Недостатки: ─ низкая надежность за счет возможности потери указателей. ─ " позаписная" работа, т.е. привыборке последовательно просматриваются все записи. ─ невозможность оперативной работы, т.е. сетевая модель способна отвечать только на заранее запрограммированные запросы
Операции сетевой модели 1) операции с данными: ─ удалить ─ добавить ─ изменить 2) операции со связями: ─ подключить ─ отключить ─ переключить 3) навигация по данным: ─ переход на подчиненную ─ возможность перехода на следующую подчиненную ─ переход на владельца Отличие сетевой структуры от иерархической заключается в том, что каждый элемент в сетевой структуре может быть связан с любым другим элементом (см. рис. 2.3). Пример простой сетевой структуры показан на рис. 2.4.
Достоинствомсетевой модели данных является возможность эффективной реализации по показателям затрат памяти и оперативности. Недостаткомсетевой модели данных являются высокая сложность и жесткость схемы БД, построенной на ее основе. Наиболее известными сетевыми СУБД являются IDMS, db_VistaIII, СЕТЬ, СЕТОР и КОМПАС. Простой пример сетевой схемы БД приведен на рис. 2.22.
Рис. 2.22. Пример схемы сетевой БД
Примерный набор операций при использовании сетевой модели может быть следующим [8]. § Найти конкретную запись в наборе однотипных записей (инженера Петрова). § Перейти от предка к первому потомку по некою рой связи (к первому сотруднику отдела 42). § Перейти к следующему потомку в некоторой связи (от Петрова к Иванову). § Перейти от потомка к предку по некоторой связи (найти отдел Петрова). § Создать новую запись. § Уничтожить запись. § Модифицировать запись. § Включить в связь. § Исключить из связи. § Переставить в другую связь и т.д.
Иерархическая модель данных Является частным случаем сетевой модели. Иерархическая БД состоит из упорядоченного набора деревьев; более точно, из упорядоченного набора нескольких экземпляров одного типа дерева. Тип дерева состоит из одного «корневого» типа записи и упорядоченного набора из нуля или более типов поддеревьев (каждое из которых является некоторым типом дерева). Тип дерева в целом представляет собой иерархически организованный набор типов записи
.
Пример типа дерева (схемы иерархической БД) представлен на рис. 2.19.
Рис. 2.19. Пример схемы иерархической БД
На рис. 2.19 ОТДЕЛ является предком для НАЧАЛЬНИК и СОТРУДНИКИ, а НАЧАЛЬНИК и СОТРУДНИКИ - потомки ОТДЕЛ. Между типами записи поддерживаются связи.
Для учета общих данных выполняется связывание деревьев: ─ в одном дереве храниться оригинал ─ в других – копии, содержащие ссылки на оригинал При удалении записей подчиненные записи удаляются каскадно, по связкам:
Виды членства: Класс членства всегда фиксирован. При удалении – каскадирование. Все экземпляры данного типа потомка с общим экземпляром типа предка называются близнецами. Для БД определен полный порядок обхода - сверху-вниз, слева-направо. Примерами типичных операторов манипулирования иерархически организованными данными могут быть следующие. § Найти указанное дерево БД (например, отдел 42, рис.2.19). § Перейти от одного дерева к другому. § Перейти от одной записи к другой внутри дерева (например, от отдела – к первому сотруднику). § Перейти от одной записи к другой в порядке обхода иерархии. § Вставить новую запись в указанную позицию. § Удалить текущую запись. Автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя. Иерархическая структура реализует отношение ОДИН-КО-МНОГИМ между исходным и порожденным типами записей. Это отображение полностью функционально, т.к. дерево не может содержать порожденный узел без исходного узла (за исключением «корня»). Однако для представления отображения МНОГИЕ-КО-МНОГИМ необходимо дублирование деревьев, а значит, реализация сложных связей требует больших затрат памяти. Другой проблемой иерархий является невозможность хранения в БД порожденного узла без соответствующего исходного, т.е. в этом случае необходимо ввести пустой исходный узел. Соответственно удаление данного исходного узла влечет удаление всех порожденных узлов (поддеревьев), связанных в ним. Эти ограничения создают проблемы применения иерархической модели для некоторых приложений. Достоинством иерархической структуры является компактность. Она имеет максимальные характеристики по объёму памяти и быстродействию.
Популярное:
|
Последнее изменение этой страницы: 2017-03-03; Просмотров: 623; Нарушение авторского права страницы











 Структура – дерево.
Структура – дерево. 
