|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Архитектура суперскалярных процессоров типа Pentium
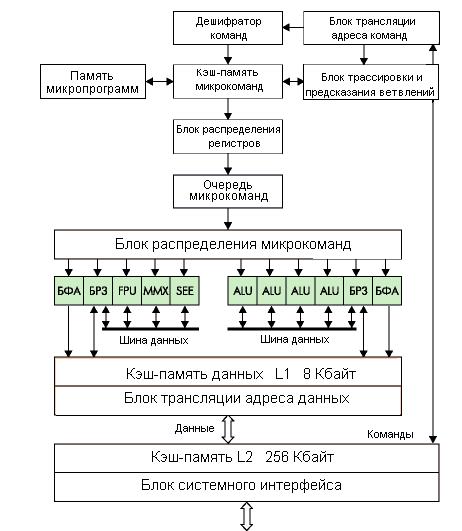
Рассмотрим особенности архитектуры суперскалярных процессоров на примере процессоров Pentium III и IV. В этих процессорах наряду с внутренним КЭШем первого уровня (L1-кэш) размером 64 Кбайт (32 Кбайт для данных + 32 Кбайт для команд), введен кэш второго уровня (L2-кэш) объемом 512 и более Кбайт. Ядро процессора Pentium III состоит из двух частей: декодера и RISC–ядра (рисунок 7.6). Декодер получает из кэша команд ассемблерные команды, представляющие собой полный комплект команд компьютера (CISC-команды) и преобразует их в микрооперации сокращенного набора команд (RISC-команды). В декодере имеется три преобразователя кодов. RISC–ядро выполняет полученные микрооперации (мкоп) параллельно несколькими блоками обработки (АЛУ) в произвольном порядке и выдает результат обработки в порядке, заданном исходной ассемблерной программой. Pentium III обладает десятью блоками обработки, которые объединены в 5 групп. За один машинный такт на блоки обработки одновременно может быть подано максимум 5 микроопераций, причем на каждую их групп не более одной микрооперации. Первые две группы содержат по одному ММХ-АЛУ и блок генерации адреса. Кроме того, в них имеется вычислительные блоки для мультимедийных команд с плавающей точкой (ММХ пл.тчк). Оставшиеся три блока обработки служат для выполнения операций обращения к памяти: чтения и записи операндов или промежуточных результатов. Операнды располагаются (с большой вероятностью) в двухпортовом кэше данных. Для одновременной записи в кэш адреса и данных блоки генерации адреса и передачи данных выполнены раздельно и работают параллельно. Устройство функционирует следующим образом. CISC–декодер загружает х86-команды без предварительной обработки в 32-байтный буфер команд. Из этого буфера команды извлекаются предварительным декодером (предекодером), который определяет длину команды и группу, к которой она принадлежит. Кроме этого предекодер выделяет команды ветвления и заносит их адреса в буфер адресов ветвления емкостью 512 слов. Если обнаружена команда ветвления, то буфер команд заполняется командами, адреса которых определены блоком предсказания. За один такт машинного цикла процессора на три преобразователя кодов ПК могут быть поданы максимум три х86-команды. Задачей ПК является преобразование х86-команд в RISC–микрооперации. Преобразователи кодов отличаются тем, что два из них обрабатывают только «простые» команды (MOV, INR, …) и генерируют одну RISC –операцию. Любая микрооперация имеет фиксированную длину 118 бит. Третий преобразователь предназначен для «сложных» команд и на каждую х86-инструкцию генерирует от 1 до 4-х микроопераций. Однако среди сложных команд имеются такие, которые для их выполнения требуют целую микропрограмму. Такие команды преобразуются в блоке микропрограммного управления. За один такт из трех ПК на RISC–ядро процессора могут быть подано максимум 6 микроопераций. Они предварительно заносятся в 6-словный буфер микроопераций и оттуда подаются в командный пул (буфер динамически выделяемой памяти). Вычислительные блоки обрабатывают команды не в том порядке, в каком он был задан исходной ассемблерной программой, а в порядке, который позволяет наиболее полно реализовать параллельное выполнение нескольких микроопераций одновременно группой АЛУ. Распределение RISC-микроопераций по соответствующим вычислительным блокам осуществляет блок диспетчеризации команд, который на схеме не показан. Он сначала осуществляет изменение порядка выполнения команд, который предписан исходной ассемблерной программой, а затем после завершения выполнения группы команд, восстанавливает выдачу результата в необходимой последовательности. RISC-микрооперации заносятся в буфер переупорядочивания (ROB-ReOrder Buffer). Для каждой внесенной микрооперации в этом буфере каждому архитектурному регистру (ЕАХ, ЕВХ, …) выделяется внутренний регистр буфера переупорядочивания. Кроме этого, в каждой мкоп устанавливаются статусные биты, которые характеризуют очередность поступления и соответствие регистров. Далее команды перемещаются в так называемую резервирующую станцию, представляющую собой группу регистров, в которой команды ожидают на освобождение соответствующего вычислительного блока либо на получения операнда - результата выполнения предыдущей операции. По мере получения операнда или освобождения вычислителя команды изымаются из резервирующей станции и подаются на обработку. В связи с тем, что команды в вычислительных блоках могут выполняться в порядке, отличном от заданного программой, результаты вычислений сначала заносятся в буфер переименований.
Рисунок 8.6 – Структурная схема процессора Pentium III
После того, как по соответствующим статусным битам установлено завершение команды, происходит обратное переименование «внутренний регистр - архитектурный регистр». Затем блок завершения команд восстанавливает результаты выполненных команд в порядке, установленном исходной программой. Для быстрого преобразования виртуальных адресов в физические в процессоре аппаратно реализован буфер быстрого преобразования адресов TLB (Translation look-aside buffer). Он состоит из двух частей: буфера преобразования адресов команд (Instruction TLB) и буфера преобразования адресов данных (Data TLB). Одним из недостатков такой архитектуры процессоров является то, что при выполнении программных циклов происходит преобразование одних и тех же ассемблерных команд в RISC-команды в каждом цикле. Это приводит к снижению производительности. Отличие архитектуры Pentium 4 от Pentium III состоит в том, что внутренний кэш команд размещен за блоками преобразования команд и в нем помещаются уже преобразованные команды (RISC-микрооперации). Вследствие этого исключаются дополнительные непроизводительные преобразования и повышается быстродействие процессора в целом. Обобщенная структурная схема процессора Pentium 4 изображена на рисунке 8.7.
Кроме этого, отличительными особенностями Pentium 4 от его предшественников являются: 1) введение гиперконвейера (Hyper Pipeling), позволяющего размещать и выполнять одновременно 20 микроопераций; 2) усовершенствование динамического исполнения позволяет в единицу времени выполнять в 3 раза больше микроопераций; 3) частота процессора превысила 3 ГГц, а системной шины 800 МГц; 4) в два раза повышена скорость выполнения операций в АЛУ целых чисел; 5) введено дополнительно 144 новых мультимедийных команд. В процессоре P-4 большинство операций целочисленной арифметики выполняется в устройствах, работающих на двойной частоте (Double Pumped ALU). Таких устройств два. Латентность этих операций (время выполнения в зависимых цепочках) составляет всего 0.5 такта. Для того чтобы обеспечить такую низкую задержку каждое их этих двух 32-битных арифметико-логических устройств реализовано в виде двух отдельных 16-битных блоков, обрабатывающих соответственно младшие и старшие 16 разрядов операндов. Из-за возможного переноса разрядов из младшей половины слова блок обработки старшей половины работает с временным сдвигом на полтакта. Таким образом, старт-стопное время выполнения операции составляет целый такт (два полутакта). Однако выполнение новой операции, зависящей от результатов текущей, начинается немедленно после получения младшей половины слова. Это правило распространяется также на логические операции, команды пересылки и чтения из памяти. Таким образом, операция обращения к памяти начинает выполняться, не дожидаясь готовности старших 16 разрядов адреса — поиск данных в L1-кэше начинается на основе младших 16 разрядов. Благодаря этому, полное время считывания данных из кэша составляет всего 2 такта. Операции сдвигов обрабатываются отдельно, в так называемом медленном устройстве. Их задержка (латентность) составляет 4 такта, а темп выполнения — 1 операция за такт. Также в медленном устройстве исполняются целочисленные умножения, деления и другие редкие операции.
Популярное:
|
Последнее изменение этой страницы: 2017-03-11; Просмотров: 1136; Нарушение авторского права страницы