
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Оценка качества модели регрессии
Для оценки качества модели множественной регрессии вычисляют коэффициент детерминации R2 и коэффициент множественной корреляции (индекс корреляции) R. Чем ближе к 1 значение этих характеристик, тем выше качество модели. Значение коэффициентов детерминации и множественной корреляции можно найти в таблице Регрессионная статистика (см. рис. 2) или вычислить по формулам: а) коэффициент детерминации:
Коэффициент детерминации показывает долю вариации результативного признака под воздействием изучаемых факторов. Следовательно, около 86% вариации зависимой переменной учтено в модели и обусловлено влиянием факторов, включенных в модель; б) коэффициент множественной корреляции:
Коэффициент множественной корреляции показывает высокую тесноту связи зависимой переменной Y с двумя включенными в модель объясняющими факторами. Точность модели оценим с помощью средней ошибки аппроксимации:
Модель неточная. Фактические значения объема реализации отличаются от расчетных в среднем на 10, 65%. Оценка значимости уравнения регрессии и его коэффициентов Проверку значимости уравнения регрессии произведем на основе F-критерия Фишера: Значение F-критерия Фишера можно найти в таблице Дисперсионный анализ протокола Еxcel (см. рис. 2). Табличное значение F-критерия при доверительной вероятности α = 0, 95 и числе степеней свободы, равном ν 1 = k = 2 и ν 2 = n – k – 1= 16 – 2 – 1 = 13 составляет 3, 81. Поскольку Fрасч > Fтабл, уравнение регрессии следует признать значимым, то есть его можно использовать для анализа и прогнозирования. Оценку значимости коэффициентов полученной модели, используя результаты отчета Excel, можно осуществить тремя способами. Коэффициент уравнения регрессии признается значимым в том случае, если: 1) наблюдаемое значение t-статистики Стьюдента для этого коэффициента больше, чем критическое (табличное) значение статистики Стьюдента (для заданного уровня значимости, например, α = 0, 05 и числа степеней свободы df = n – k – 1, где n – число наблюдений, а k – число факторов в модели); 2) Р-значение t-статистики Стьюдента для этого коэффициента меньше, чем уровень значимости, например, α = 0, 05; 3) доверительный интервал для этого коэффициента, вычисленный с некоторой доверительной вероятностью (например, 95%), не содержит ноль внутри себя, то есть если нижняя 95% и верхняя 95% границы доверительного интервала имеют одинаковые знаки. Значимость коэффициентов Р-значение( Р-значение( Следовательно, коэффициенты Нижние и верхние 95% границы доверительного интервала имеют одинаковые знаки (см. рис. 2), следовательно, коэффициенты
Определение объясняющей переменной, от которой может зависеть дисперсия случайных возмущений. Проверка выполнения условия гомоскедастичности остатков по тесту Голдфельда–Квандта При проверке предпосылки МНК о гомоскедастичности остатков в модели множественной регрессии следует вначале определить, по отношению к какому из факторов дисперсия остатков более всего нарушена. Это можно сделать в результате визуального исследования графиков остатков, построенных по каждому из факторов, включенных в модель. Та из объясняющих переменных, от которой больше зависит дисперсия случайных возмущений, и будет упорядочена по возрастанию фактических значений при проверке теста Гольдфельда–Квандта. Для двухфакторной модели нашего примера графики остатков относительно каждого из двух факторов имеют вид, представленный на рис. 3 (эти графики легко получить в отчете, который формируется в результате использования инструмента Регрессия в пакете Анализ данных ).
Рис. 3. Графики остатков по каждому из факторов двухфакторной модели
Из графиков на рис. 3 видно, что дисперсия остатков более всего нарушена по отношению к фактору Затраты на рекламу. Проверим наличие гомоскедастичности в остатках двухфакторной модели на основе теста Гольдфельда–Квандта. 1. Упорядочим переменные Y и Исходные данные
Данные, отсортированные по возрастанию Х2
2. Уберем из середины упорядоченной совокупности С = 1/4 · n = 1/4 · 16 = 4 значения. В результате получим две совокупности соответственно с малыми и большими значениями Х2. 3. Для каждой совокупности выполним расчеты:
Результаты данной таблицы получены с помощью инструмента Регрессия поочередно к каждой из полученных совокупностей. 4. Найдем отношение полученных остаточных сумм квадратов (в числителе должна быть большая сумма): F = 5176, 462/1763, 03 = 2, 936117. 5. Вывод о наличии гомоскедастичности остатков делаем с помощью F-критерия Фишера с уровнем значимости α = 0, 05 и двумя одинаковыми степенями свободы
Так как
|
Последнее изменение этой страницы: 2017-03-14; Просмотров: 129; Нарушение авторского права страницы
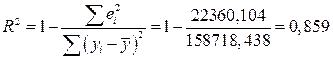
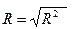 = 0, 927.
= 0, 927.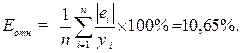
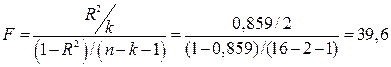
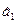 и
и 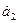 проверим по второму и третьему способам, используя данные рис. 2:
проверим по второму и третьему способам, используя данные рис. 2: 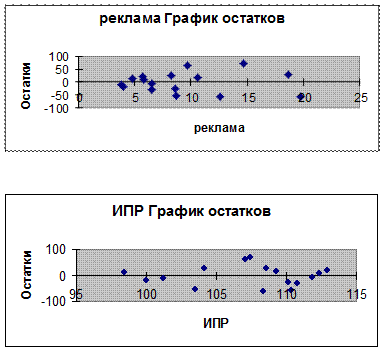
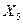 по возрастанию фактора
по возрастанию фактора 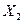 (в Excel для этого можно использовать команду Данные – Сортировка – по возрастанию Х2 ):
(в Excel для этого можно использовать команду Данные – Сортировка – по возрастанию Х2 ): 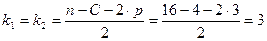 , где р – число параметров уравнении регрессии:
, где р – число параметров уравнении регрессии: 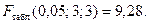
 , то подтверждается гомоскедастичность в остатках двухфакторной регрессии.
, то подтверждается гомоскедастичность в остатках двухфакторной регрессии.