
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
ТЕМА 8. СТАТИСТИЧЕСКОЕ ИЗУЧЕНИЕ КОРРЕЛЯЦИОННЫХ ВЗАИМОСВЯЗЕЙ
1. Понятие о статистической и корреляционной связи. 2. Статистические методы выявления корреляционной связи между признаками. 3. Парная корреляция. 4. Уравнение парной регрессии. 5. Статистическая оценка надежности параметров парной корреляции. 6. Вычисление параметров парной линейной корреляции на основе аналитической группировки. 7. Частная и множественная корреляции. 8. Уравнение множественной регрессии. 9. Использование регрессий в социально-экономических исследованиях. 10. Измерение связей неколичественных переменных.
Окружающий нас мир полон всевозможных взаимосвязей: между отношением к труду и производительностью, между корпоративной стратегией и долей рынка, между вмешательством государства и состоянием экономики, между объемом выпускаемой продукции и затратами, между сбытом и доходами и т.п. В предыдущих темах говорилось о расчете среднего значения, отклонений и других статистических характеристик, которых обычно бывает достаточно, когда приходится иметь дело с одномерными данными (т.е. лишь с одним измерением — например, заработной платой) о каждой элементарной единице (например, о служащем). При работе с двумерными данными (например, заработной платой и образованием), всегда есть возможность изучать каждое измерение по отдельности — как часть одномерной совокупности данных. Однако при совместном изучении обоих измерений появляются новые возможности для анализа, в частности, возможность выявить взаимосвязь между ними. Различают два типа связей между различными явлениями и их признаками: функциональную и статистическую. Функциональные связи характеризуются полным соответствием между изменением факторного признака и изменением результативной величины, и каждому значению признака-фактора соответствуют определенные значения результативного признака. Статистические связи проявляются в том, что при изменении значения фактора изменяется распределение результативного признака. При статистической связи разным значениям одной переменной (фактора х) соответствуют разные распределения другой переменной (результата у). Корреляционная связь — частный случай статистической связи, при котором разным значениям переменной соответствуют разные средние значения другой переменной. Корреляционная связь предполагает, что изучаемые переменные имеют количественное выражение, статистическая связь – более широкое понятие и не включает ограничений на уровень измерения показателей. Корреляционная связь может возникать разными способами: причинно-следственные связи, связи соответствия, т.е. сопряженное изменение двух признаков, оба признака могут быть и причиной, и следствием. Существуют два базовых инструмента, с помощью которых анализируют двумерные данные: корреляционный анализ, позволяющий оценить степень взаимосвязи между двумя факторами (если такая взаимосвязь вообще существует), и регрессионный анализ, показывающий, как можно предсказать или управлять одной из двух переменных с помощью другой. Проверка статистических гипотез позволяет оценить взаимосвязь, которая, как вам кажется, существует в изучаемых данных, и выяснить, является ли она значимой или может быть объяснена исключительно случайностью. Изучая взаимосвязи в двумерных данных, следует всегда помнить о следующих трех основных целях . Первая. Описание и понимание взаимосвязи. Это самая общая цель, обеспечивающая получение базовой информации, с помощью которой можно лучше понять истинное устройство окружающего нас мира. При изучении сложной системы очень важно знать, какие факторы наиболее тесно взаимодействуют друг с другом, а какие вообще не оказывают влияния друг на друга. Знание этой информации может оказать значительную помощь в долгосрочном планировании и принятии других стратегических решений. Вторая. Прогнозирование и предсказание нового наблюдения. Понимание некоторой взаимосвязи может позволить использовать информацию об одном из измерений для более качественного предсказания другого измерения. Если, например, вам известно, что в этом квартале количество заказов на продукцию увеличилось, можно ожидать и увеличения объема сбыта. Если вы проанализировали взаимосвязь между количеством заказов и объемами сбыта в прошлом, у вас есть все шансы сделать достоверный прогноз сбыта на будущее, основываясь на текущем количестве заказов. Третья. Регулирование и управление процессом. Когда вы вмешиваетесь в какой-либо процесс (например, регулируете уровень производства, вводя некоторые технологические изменения или новый тип обслуживания), необходимо определить объем этого вмешательства. Если существует непосредственная взаимосвязь между вмешательством и результатом и вы эту взаимосвязь понимаете, то такое знание может помочь вам выполнить оптимальное регулирование. Для того чтобы ответить на вопрос: есть ли связь или ее нет, используется ряд специфических методов: • сопоставление двух параллельных рядов; • аналитическая группировка; • графический метод. Если данные представлены в виде аналитической группировки, то можно вычислить дисперсию общую, межгрупповую и внутригрупповую. Общая дисперсия измеряет вариацию признака во всей совокупности под влиянием всех факторов, обусловливающих эту вариацию:
или
Межгрупповая дисперсия характеризует систематическую вариацию, т.е. различия в величине изучаемого признака, возникающие под влиянием признака-фактора, положенного в основание группировки. Она рассчитывается по формуле:
где Внутригрупповая дисперсия отражает случайную вариацию, т.е. часть вариации, происходящую под влиянием неучтенных факторов и не зависящую от признака-фактора, положенного в основание группировки. Она исчисляется следующим образом:
где Внутригрупповые дисперсии, рассчитанные для отдельных групп, объединяются в средней величине внутригрупповой дисперсии:
Существует закон, связывающий три вида дисперсий. Общая дисперсия равна сумме средней из внутригрупповых и межгрупповой дисперсий:
Данное соотношение называют правилом сложения дисперсий. Согласно этому правилу общая дисперсия, возникающая под влиянием всех факторов, равна сумме дисперсий, возникающих под влиянием всех прочих факторов, и дисперсии, возникающей за счет группировочного признака. Зная любые два вида дисперсий, можно определить или проверить правильность расчета третьего вида. На основании правила сложения дисперсий можно определить показатель тесноты связи между группировочным (факторным) и результативным признаками. Он называется эмпирическим корреляционным отношением и рассчитывается по формуле:
Эмпирическое корреляционное отношение изменяется в пределах от 0 до 1, чем ближе его значение к 1, тем теснее связь между изучаемыми признаками. Для измерения тесноты связи между двумя признаками в случае линейной связи служит линейный коэффициент корреляции (rxy), основанный на расчете нормированных отклонений (tx и ty).
Коэффициент корреляции представляет собой среднее произведение этих нормированных отклонений:
Линейный коэффициент корреляции может принимать любые значения в пределах от -1 до +1. Чем ближе коэффициент корреляции по абсолютной величине к 1, тем теснее связь между признаками. Знак при линейном коэффициенте корреляции указывает на направление связи — прямой зависимости соответствует знак плюс, а обратный зависимости — знак минус. Если с увеличением значений факторного признака х, результативный признак у имеет тенденцию к увеличению, то величина коэффициента корреляции будет находиться между 0 и 1. Если же с увеличением значений х результативный признак у имеет тенденцию к снижению, коэффициент корреляции может принимать значения в интервале от 0 до -1. Квадрат коэффициента корреляции r2yx называется коэффициентом детерминации и показывает долю вариации результативного признака объясняемую вариацией факторного признака. Регрессионный анализ позволяет предсказывать одну переменную на основании другой с использованием прямой линии, характеризующей взаимосвязь между двумя этими переменными. Точно так же как средняя величина используется как обобщенная характеристика индивидуальных значений признака, так и линия может выступать в качестве характеристики предполагаемой линейной связи между двумя переменными. Однако прямая линия, являясь весьма важным инструментом анализа и предсказания, все же не идеальна, поскольку присутствует случайность. Если установлено наличие зависимости между переменными, из которых одна является фактором, а другая — результатом, то эту зависимость стремятся представить в математическом виде:
Математически описание зависимости в среднем изменений переменной у от переменной х называется уравнением парной регрессии. Наиболее часто используется линейное уравнение парной регрессии:
где Параметры уравнения парной регрессии находятся с помощью методов наименьших квадратов (МНК). Исходное условие МНК формулируется следующим образом:
Для отыскания значений параметров a и b, при которых функция принимает минимальное значение, приравниваем нулю первые частные производные функции:
После несложных преобразований получаем систему нормальных уравнений:
Решая систему уравнений относительно b, получим следующую формулу для определения этого параметра
или
Значение параметра a получим, разделив обе части на n:
Прямая линия описывается двумя значениями: наклоном b и сдвигом а. Наклон указывает на крутизну подъема, если b положителен, или снижения, если b отрицателен. Если сместиться по горизонтали на 1 единицу измерения x, то линия поднимется или снизится по вертикали на b единиц измерения y. Сдвиг – это просто значение y при x = 0. В случаях, когда нулевое значение лишено смысла, сдвиг следует рассматривать как техническую характеристику. Нельзя рассчитывать на то, что все точки попадут на линию. Фактические данные можно представить как линию с добавлением случайности. Для каждой точки можно определить остаток, который указывает, на сколько эта точка оказывается выше или ниже линии. Остатки позволяют вносить коррективы, сравнивая фактические значения с теми значениями, которые можно ожидать для соответствующих значений х. Формула остатка имеет вид:
Поскольку на изучаемый результативный признак влияет не один факторный признак, а множество, то возникает задача изолированного измерения тесноты связи результативного признака с каждым из признаков-факторов при элиминировании других признаков-факторов, а также задача измерения тесноты связи между результативными признаками и всеми признаками-факторами, включенными в анализ. Основой решения этих задач служит матрица коэффициентов парной корреляции.
На основе коэффициентов парной корреляции рассчитываются коэффициенты частной детерминации. Коэффициент частной детерминации переменной xk — это доля дисперсии у, дополнительно объясняемой при включении переменной xk, в величине дисперсии у, не объясненной ранее включенными в анализ переменными. Коэффициент частной детерминации обозначается как
Наиболее ясно суть коэффициентов частной детерминации выражает формула их расчета через коэффициенты множественной детерминации. Коэффициент множественной детерминации показывает, какая часть дисперсии результативной переменной у объясняется за счет учтенных в анализе факторных признаков. Этот показатель обозначается R2yx1…xk и изменяется в интервале [0, 1]:
где Извлекая корень квадратный из R2, получаем коэффициент множественной (или совокупной) корреляции у со всеми учтенными переменными х1... xk. Главное назначение коэффициентов частной детерминации — определить, имеет ли смысл введение в уравнение регрессии дополнительной объясняющей переменной или нет. Назначение коэффициента множественной корреляции (или множественной детерминации) состоит в оценке качества уровня множественной регрессии: чем больше значение R, чем ближе оно к единице, тем лучше уравнение регрессии, тем надежнее результаты анализа или прогноза на его основе. В случае влияния двух факторов для расчета совокупного коэффициента множественной детерминации можно воспользоваться формулой:
Математически корреляционная зависимость результативной переменной от нескольких факторных (объясняющих) переменных описывается уравнением множественной регрессии. Уравнение множественной регрессии характеризует среднее изменение у сизменением признаков-факторов. При построении уравнения множественной рецессии нужно решить две задачи: - выбрать признаки-факторы, включенные в регрессию; - выбрать тип уравнения регрессии. Решение первой задачи основывается, прежде всего, на рассмотрении матрицы коэффициентов корреляции и выделении тех переменных, для которых Не рекомендуется включать совместно признаки, представленные как абсолютные и средние или относительные величины. Нельзя включать в регрессию признаки, функционально связанные с зависимой переменной у, например, те, которые являются составной частью у. Принимаются во внимание частные коэффициенты детерминации для каждого признака-фактора. Их значения свидетельствуют об объясняющей способности каждого из признаков-факторов — возможности уменьшить остаточную переменную результативной переменной в счет включения в регрессию того или иного факторного признака. Решение второй задачи основывается на соотношениях простоты и интерпретируемости результатов многофакторного регрессионного анализа: чем проще тип уравнения множественной регрессии, тем очевиднее интерпретация его параметров, тем лучше для использования регрессии с целью анализа и прогноза. Исходя из этого, чаще всего используют линейное уравнение множественной регрессии:
где j – номер фактора; k – число факторов, включенных в уравнение множественной регрессии. При записи линейного уравнения множественной регрессии для коэффициентов регрессии введены подстрочные значки, подчеркивающие, что каждый из коэффициентов регрессии является «чистой» мерой влияния изменения хj на у в отличие от коэффициента регрессии в уравнении парной регрессии, где влияние изменений прочих переменных-факторов не устраняется. Интерпретация коэффициентов регрессии линейного уравнения множественной регрессии очевидна: они показывают, на сколько единиц в среднем изменяется у при изменении хj на свою единицу измерения при закреплении прочих введенных в уравнение объясняющих переменных на среднем уровне. Так как все включенные переменныеимеют свою размерность, то сравнивать bj нельзя; по величине bj нельзя сделать вывод, что одна переменная влияет сильнее на у, а другая — слабее. Очевидный смысл коэффициентов регрессии — это основное преимущество линейного уравнения. Вторая причина, по которой предпочтение отдается линейной форме, — ограниченность вариации переменных. Поскольку коэффициенты регрессии — это средние величины, они надежны и устойчивы, если исходные данные однородны. Однородность данных предполагает их варьирование в определенных пределах, так что нелинейность связей, даже если она существует, может не проявиться. Наконец, третья причина предпочтения линейной формы регрессии состоит в том, что социальная и экономическая информация, как правило, содержит разного рода погрешности, неточности. Эффект уточнения, который может дать применение нелинейной регрессии в этих условиях, ничтожен. Параметры линейного уравнения множественной регрессии оцениваются методом наименьших квадратов (МНК). Условие МНК:
Берем частные производные первого порядка данной функции и приравниваем их к нулю (условие экстремума функции). Отсюда получаем систему нормальных уравнений, решение которой даст значения параметров уравнения множественной регрессии. При записи системы уравнений для нахождения параметров уравнения множественной регрессии можно руководствоваться следующим простым правилом: первое уравнение получается как сумма n уравнений регрессии; второе и последующие — как сумма п уравнений регрессии, все члены которой умножены на x1, затем на х2 и т. д.
… … ...
Свободный член уравнения а рассчитывается по формуле:
В отличие от коэффициентов регрессии в натуральном масштабе bj, которые нельзя сравнивать, стандартизованные коэффициенты регрессии
Они определяют, на какую часть своего среднеквадратического отклонения изменится у при изменении хj на одно среднее квадратическое отклонение. Такую же возможность дают и коэффициенты эластичности Эj, которые показывают на сколько процентов изменится у при изменении хj на 1 %.
Кроме значения совокупного коэффициента детерминации, важно знать вклад каждой объясняющей переменной. Он измеряется коэффициентами раздельной детерминации. Формула коэффициента раздельной детерминации основана на следующем представлении коэффициента совокупной детерминации:
т. е. R2 — сумма произведений парных коэффициентов корреляции и стандартизованных коэффициентов регрессии. Отсюда коэффициент раздельной детерминации равен:
Оценка результатов регрессионного анализа начинается с оценки суммарной значимости результатов регрессионной связи с помощью F-теста. Целью этого теста является выяснить, объясняют ли х-переменные значимую часть вариации у. Если этот тест значим, следовательно, связь существует и можно приступать к исследованию и объяснению. Выполнить F-тест проще всего, отыскав в результатах компьютерной программы подходящее р-значение (значение доверительной вероятности, это вероятность того, что данные соответствуют нулевой гипотезе, малые значения свидетельствуют об удивительности этого события и приводят к тому, что нулевая гипотеза отвергается) и интерпретировав результирующий уровень значимости. Нулевая гипотеза для F-теста утверждает, что в генеральной совокупности между х и у прогнозирующая взаимосвязь отсутствует. Если р-значение больше, чем 0, 05, то полученный результат является незначимым. Если же р-значение меньше, чем 0, 05, то результат является значимым, если меньше 0, 01, то результат – высоко значим. Еще один вариант основан на оценке R2. Если R2 меньше, чем критическое значение по таблице R2, то соответствующая модель не является значимой, и наоборот. Критическое значение R2 определяется при заданном уровне значимости, например, 5 %, и индексирована по n и k. Традиционный способ выполнения F-теста основан на сравнении F-статистики с критическим значением из F-таблицы для соответствующего уровня тестирования. При этом используется два разных числа степеней свободы: число степеней свободы числителя k и число степеней свободы знаменателя n-k-1 (мера случайности остатков после оценивания k+1 коэффициентов а, в1, в2. …). Результаты выполнения этого теста всегда такие же, как и теста R2. Статистический смысл термина значимый состоит в том, что когда вы находите значимую модель регрессии, то знаете, что взаимосвязь сильнее, чем можно было бы ожидать от простой случайности. После того, как оценена в целом значимость регрессионной модели, можно говорить о том, что значимы хотя бы один или все коэффициенты регрессии. Оценка значимости коэффициентов регрессии производится с помощью t-статистики и р-значений. Данные корреляционно-регрессионного анализа, проведенного с помощью компьютерных программ, предоставляют также результаты дисперсионного анализа. В таблице дисперсионного анализа указываются источники вариации: объясненная сумма квадратов отклонений значений, рассчитанных по уравнению регрессии, от среднего значения Doбъясн. при числе степеней свободы df=k; остаточная — отклонения фактических значений от расчетных Doстат. при числе степеней свободы df=n-k-1; общая — Dобщ. при числе степеней свободы df=n-1. Затем приводится средний квадрат отклонений S21 = Doбъясн.: df, S22 = Doстат.: dfостат. Далее указано их отношение, равное F-критерию: F = S21: S22. Наконец, указывается вероятность ошибочного решения, т.е. нулевого R2.
Контрольные вопросы 1. В чем состоит отличие между корреляционной и функциональной связями? 2. Приведите примеры статистической и корреляционной связей. 3. Какие методы целесообразно использовать для выявления возможной связи между факторным и результативным признаками при небольшом объеме фактических данных? 4. Перечислите условия применения корреляционно-регрессионного анализа. 5. В чем смысл коэффициента парной корреляции, каковы границы его значений? 6. Какие еще показатели тесноты связи существуют между двумя признаками? 7. Как измерить долю общей вариации результативного признака, которая объясняется влиянием вариации признака-фактора? 8. Какие показатели используют для измерения степени тесноты связи между качественными признаками? 9. В каком случае достаточно использовать уравнение парной регрессии? 10. Что характеризует коэффициент регрессии? 11. Какая связь существует между линейным коэффициентом корреляции и коэффициентом регрессии? 12. Поясните смысл коэффициентов частной и множественной корреляции. 13. Каковы условия построения уравнения множественной регрессии? 14. Каковы направления анализа на основе уравнения регрессии? 15. Как использовать уравнение регрессии для прогноза? 16. Что означает величина коэффициента эластичности 0, 63?
Задачи 8.1. Изучается зависимость рентабельности продукции от объема продукции на основе следующей аналитической группировки предприятий:
1. Оцените в целом по совокупности показатель силы связи. 2. С помощью эмпирического корреляционного отношения и коэффициента детерминации оцените тесноту связи между признаками. 3. Постройте эмпирическую линию регрессии. Сделайте выводы. 8.2. По семи однородным семьям имеются следующие данные о доходах и потреблении молока за месяц (на одного члена семьи):
Найдите уравнение корреляционной связи между доходом и потреблением молока (связь линейная). Проанализируйте параметры уравнения регрессии. Рассчитайте парный линейный коэффициент корреляции. Изобразите графически данную зависимость. Сделайте выводы. 8.3. По 8 рабочим механического цеха завода имеются следующие данные:
Найдите уравнение корреляционной связи между стажем работы и выработкой (связь линейная). Проанализируйте параметры уравнения регрессии. Рассчитайте парный линейный коэффициент корреляции. Изобразите корреляционную связь графически. Сделайте выводы. 8.4. По 15 однородным предприятиям имеются следующие данные:
Найдите уравнение корреляционной связи между выпуском продукции и себестоимостью изделия (связь в виде параболы второго порядка). Изобразите графически корреляционную связь. 8.5. По 10 магазинам области имеются данные:
Найдите уравнение корреляционной связи между товарооборотом и товарными запасами (связь в виде гиперболы). Изобразите графически корреляционную связь. 8.6. Имеются следующие данные по 12 предприятиям:
Для определения зависимости себестоимости единицы изделия от выпуска продукции вычислите и проанализируйте параметры степенной функции, постройте теоретическую линию регрессии, изобразите графически корреляционную связь. 8.7. По данным приложения 1 произведите аналитическую группировку результата Y, разбив совокупность на четыре группы. Каждую группу охарактеризуйте числом единиц в подгруппе и средними показателями Вычислите парные коэффициенты корреляции и постройте матрицу парных коэффициентов корреляции. Сделайте выводы о тесноте связи между признаками. Найдите линейное уравнение связи 8.8. Выполните условие задачи 8.7 по данным приложения 2. 8.9. Выполните условие задачи 8.7 по данным приложения 3. 8.10. Выполните условие задачи 8.7 по данным приложения 4. 8.11. Выполните условие задачи 8.7 по данным приложения 5. 8.12. Выполните условие задачи 8.7 по данным приложения 6. 8.13. Выполните условие задачи 8.7 по данным приложения 7. 8.14. Выполните условие задачи 8.7 по данным приложения 8. 8.15. Выполните условие задачи 8.7 по данным приложения 9. 8.16. Выполните условие задачи 8.7 по данным приложения 10.
|
Последнее изменение этой страницы: 2017-03-15; Просмотров: 601; Нарушение авторского права страницы
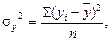
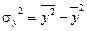 .
.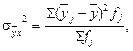
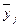 — среднее значение признака у в j-й группе;
— среднее значение признака у в j-й группе; 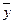 — среднее значение признака у в совокупности;
— среднее значение признака у в совокупности; 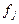 — число единиц в j-й группе.
— число единиц в j-й группе.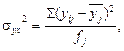
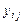 — значение признака у для i-й единицы в j-й группе.
— значение признака у для i-й единицы в j-й группе.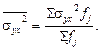
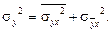
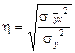 .
.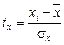 ,
, 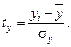
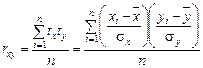 ,
, 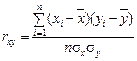 ,
, 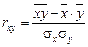 .
.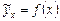 .
.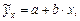
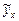 – среднее значение результативного признака при определенном значении факторного признака; а – свободный член уравнения регрессии; b – коэффициент регрессии, который показывает, на сколько единиц в среднем изменится результативный признак при изменении факторного признака на единицу его измерения, является показателем силы связи.
– среднее значение результативного признака при определенном значении факторного признака; а – свободный член уравнения регрессии; b – коэффициент регрессии, который показывает, на сколько единиц в среднем изменится результативный признак при изменении факторного признака на единицу его измерения, является показателем силы связи.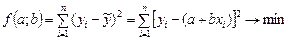 .
.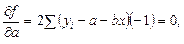
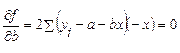
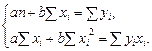
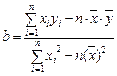
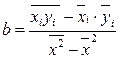 ,
, 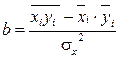 ,
, 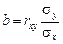 .
.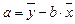 .
.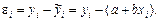
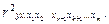
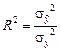 ,
, 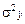 — дисперсия переменной у, объясненная факторными переменными, включенными в анализ;
— дисперсия переменной у, объясненная факторными переменными, включенными в анализ; 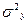 — общая дисперсия переменной у.
— общая дисперсия переменной у.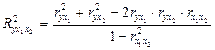 .
.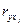 >
> 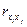 (i≠ j). Кроме того, не рекомендуется совместно включать во множественную регрессию объясняющие переменные, тесно связанные между собой: при
(i≠ j). Кроме того, не рекомендуется совместно включать во множественную регрессию объясняющие переменные, тесно связанные между собой: при 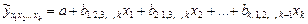 ,
, 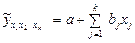 ,
, 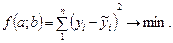
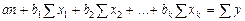 ,
, 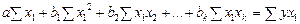 ,
,  ,
, 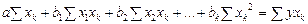 .
.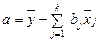 .
.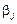 можно сравнивать, а также можно делать вывод, влияние какого фактора на у значительнее. Они рассчитываются по формуле:
можно сравнивать, а также можно делать вывод, влияние какого фактора на у значительнее. Они рассчитываются по формуле: 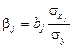 .
.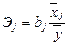 .
.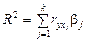 ,
, 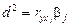 .
.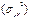
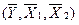 . Сделайте анализ результатов группировки.
. Сделайте анализ результатов группировки.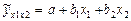 , совокупный коэффициент корреляции и детерминации, b-коэффициенты, коэффициенты эластичности. Сделайте подробные выводы.
, совокупный коэффициент корреляции и детерминации, b-коэффициенты, коэффициенты эластичности. Сделайте подробные выводы.