
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Общие методы анализа информации
К общим методам анализа информации относят наиболее общие, то есть применяемые в различных конкретных науках методы обработки данных. К ним относятся методы анализа текстов (контент-анализ), методы группировок и классификаций, включая кластерный анализ, методы обобщения измерений (расчеты средних и дисперсий), методы выявления наличия зависимостей (дисперсионный анализ), методы выявление видов зависимостей (корреляционые, регрессионные методы и методы проверки гипотез о видах и параметрах распределений случайных величин), методы выявления скрытых факторов (факторный анализ). Остановимся на некоторых наиболее часто используемых. Контент-анализ Контент-анализ (англ. content analysis )– анализ связи содержания информации с ее целевым назначением. Контент-анализ может быть применен для изучения совокупности любых текстов как письменных, так и устных. Основные процедуры контент-анализа связаны с переводом качественной информации на язык количественной информации. С этой целью выделяют два типа единиц - смысловые или качественные единицы анализа и единицы счета или количественные единицы. Единицами анализа могут быть темы, идеи, оценки, суждения, символы, термины, понятия и др. При этом смысловые единицы (единицы анализа) выделяются на основе гипотез исследования, а единицы количественной информации - с учетом характера источника и поставленных задач. В качестве единиц счета могут использоваться частота употребления тех или иных понятий, терминов, слов, темы и т.п., физическая протяженность, площадь текстов, число строк, длительность трансляции и т.п. При использовании контент-анализа обязательна проверка результатов на надежность. Для этого используется либо экспертная оценка, либо проверка с помощью других методов (опрос, интервью), либо данные сопоставляются с данными результатов других исследований.
Методы группировок и классификаций Методы группировок Любая задача многомерного анализа так или иначе сводится к нахождению группировки (группируются или объекты, или признаки). Формализация задачи (то есть ее математическая постановка) в большой степени зависит от того, в каком виде представлена исходная статистическая информация. Как правило, исходная информация для социально-экономического исследования задается или матрицей типа " объект-признак", или матрицей связи " объект-объект", причем при переходе от матрицы " объект-признак" к матрице " объект-объект" возникает вопрос о выборе меры близости объектов. При нахождении группировок в одних случаях имеются некоторые априорные сведения о существовании групп (классов) объектов или признаков, которые требуется найти в результате анализа данных, в других случаяхничего не известно ни о количестве классов, ни об их составе. Задачи многомерного анализа, или задачи группировки объектов, усложнены часто тем, что у исследователя нет четкого представления, какие признаки следует брать в качестве классифицирующих. В связи с этим на первом этапе анализа возникает вопрос или о выборе информативной системы признаков, или о нахождении факторных конструкций в системе признаков. Выбор системы информативных признаков осуществляется в режиме диалога " человек-ЭВМ" чаще всего на основе анализа корреляционной матрицы или с использованием методов факторного анализа (метода главных компонент) и для решения этой проблемы существует целый ряд методов. Кним наряду с методом главных компонент и факторным анализом следует также отнести канонический анализ, метод корреляционных плеяд, метод экстремальной группировки параметров, методы таксономии и другие. Эти методы можно разделить на две группы. Методы первой группы характеризуются уменьшением размерности признакового пространства за счет замены набора исходных признаков некоторыми их комбинациями. При использовании методов первой группы в многомерном анализе социально-экономической информации значительную сложность для исследователя представляет интерпретация формально полученных " искусственных" признаков в построенном признаковом пространстве. Методы второй группы позволяют выделить связанные группы признаков на основе их взаимосвязи. При этом в качестве представителей групп выбирают сами признаки, с помощью которых и интерпретируют полученные результаты группировки. В качестве примеров первого и второго типа приведем некоторые известные методы. Метод главных компонент является представителем первой группы методов. Пусть
где
Начальными данными метода является корреляционная или ковариационная матрица, которую строят по исходной информации. Известно, что полная дисперсия
где Тогда
где
есть полный вклад
где Факторные нагрузки Для применения методов факторного анализа к качественным данным, измеренным на ранговых и номинальных шкалах, разработан аппарат качественного факторного анализа, который основан на идее аппроксимации матрицы связи линейной комбинацией матриц определенной блочной структуры, каждая из которых интерпретируется как некоторый качественный фактор. В статистических исследованиях " проверенным" методом агрегирования исходных признаков является алгоритм экстремальной группировки параметров. По этому алгоритму формировалось, например, признаковое пространство для построения типологии демографических статусов поселений. В основу алгоритма экстремальной группировки параметров для группировки этих признаков и выделения факторов положен подход, связанный с экстремизацией некоторого функционала, зависящего как от способа группировки, так и от выбора факторов. Разбиение, экстремирующее этот функционал, и представляет экстремальную группировку признаков. В качестве примера рассмотрим один из алгоритмов экстремальной группировки параметров. Пусть коэффициент корреляции (или ковариации) двух случайных величин Х и Y есть Пусть множество параметров (признаков)
которые называются факторами. Рассматривается функционал
Алгоритм экстремальной группировки параметров решает задачу максимизации этого функционала как по разбиению параметров на множества Максимизация Если группы параметров
При фиксированном множестве параметров
где для каждого
так как в противном случае Следующий итерационный алгоритм[54], определяет одновременно группы Пусть на
В том случае, когда существуют два или более факторов и такой параметр К первой группе методов, заменяющих набор рассматриваемых признаков некоторыми их комбинациями, можно отнести и канонический анализ. Каноническая корреляция - это корреляция между линейными функциями двух множеств случайных величин, которая характеризуется максимально возможными значениями коэффициентов корреляции. В теории канонической корреляции случайные величины X 1, X 2, ..., Xs и X s+1, X s+2, …, X s+t линейно преобразуются в так называемые канонические случайные величины Y 1, Y 2, ..., Y sи Y s+1, Y s+2, …, Y s+t, такие, что: 1) все величины Y имеют нулевое математическое ожидание и единичную дисперсию; 2) внутри каждого из двух множеств величины Y некоррелированы; 3) любая величина Y из первого множества коррелирована лишь с одной величиной из второго множества; 4) ненулевые коэффициенты корреляции между величинами Y из разных множеств имеют максимальное значение. В многомерном статистическом анализе с помощью метода канонической корреляции осуществляется переход к новой системе координат, в которой корреляция между X 1, X 2, ..., Xs и X s+1, X s+2, …, X s+t проявляется наиболее отчетливо. В результате анализа канонической корреляции может оказаться, что взаимосвязь между двумя множествами полностью описывается корреляцией между несколькими каноническими случайными величинами. Каноническую корреляцию целесообразно использовать при комплексном анализе социально-экономических блоков в исследовании развития региона. Примером методов второй группы может быть метод корреляционных плеяд. Плеяда - группа признаков, в которой корреляционная связь (внутриплеядная связь) достаточно велика, а связь между признаками из разных групп (межплеядная связь) мала. Мера корреляционной связи может быть выбрана по-разному. Например, как сумма модулей коэффициентов корреляции между признаками одной группы. По корреляционной матрице строят граф, который разрыванием " малых" связей преобразуют в несколько подграфов. В каждом подграфе выбирают признаки (один или несколько), с помощью которых описывают полученные плеяды признаков. Ввиду простоты этот метод часто применяют на ранних стадиях анализа. Анализ и группировку исходных признаков как количественных, так и качественных можно также осуществить, применив метод главных кластеров к транспонированной исходной матрице " объект-признак". Выявляя группы признаков и выбирая " представителей" этих групп, решают задачу нахождения системы информативных признаков для дальнейшего исследования изучаемого явления или процесса. После выбора информативной системы признаков следующей задачей в процессе анализа социально-экономической информации является задача группировки объектов. В большинстве случаев - это задача типологизации или классификации объектов изучаемой совокупности. По способу построения группировок все методы классификации (как признаков, так и объектов) делятся на алгоритмические и вариационные. Алгоритмический метод использует некоторые эвристические соображения исследователя, на основании которых и формируются классы. Основное требование в этом подходе к формируемым классам - их компактность. Под компактной группой в некотором пространстве понимают такое множество точек этого пространства, для которого средняя внутренняя связь больше, чем средняя связь вовне (или среднее внутреннее расстояние, наоборот, меньше, чем среднее расстояние вовне). Успешное применение этих алгоритмов предполагает наличие у исследователя некоторых априорных сведений о реально существующих группах изучаемой совокупности. Эвристические алгоритмы, как правило, линейны, то есть, число операций в них пропорционально числу классифицируемых объектов. Примером эвристического алгоритма, применяемого при формировании классов объектов, служит известный алгоритм Мак Кина (или метод центров). Рассмотрим этот алгоритм. Исходной информацией служит матрица " объект-признак" или матрица связи " объект-объект". Рассмотрим случай, когда исходной является таблица " объект-признак", в которой на ( Первый шаг алгоритма - выбор в пространстве признаков точек (объектов), число которых равно числу требуемых классов. Эти объекты задаются из содержательных или из формальных соображений. Они также могут быть выбраны случайным образом. Блок " Класс" распределяет объекты - по классам так, чтобы расстояние от объекта до соответствующего ему центра было минимальным. Для количественных признаков может быть выбрано евклидово расстояние в Блок " Центр" работает после блока " Класс". Этот блок пересчитывает центры классов. Для каждого класса новые координаты его центра в пространстве признаков получаются как координаты центра тяжести каждого класса. Теперь дадим формальное описание алгоритма: 1°. Задаются 2°. Объект 3°. Пересчитываются центры классов.
где
Пункты 2° и 3° выполняются для всех Метод Мак Кина с исходной матрицей " объект-объект" заключается в следующем. Центры выбираются по исходной матрице связи " объект-объект" следующим образом. Выбирается максимальный по модулю отрицательный элемент После Процесс построения центров заканчивается, если исчерпаны все объекты с указанным свойством. Блок " Класс" в этой схеме работает следующим образом. Для каждого объекта
то есть объект относится к самому " близкому" в смысле меры связи центру. Блок " центр" в качестве нового центра
Алгоритм заканчивает работу, когда процесс стабилизируется. Для безмашинного («ручного») счета может быть использован метод вроцлавской таксономии, который был впервые применен при классификации воеводств Польши по демографическим данным. Этот метод по своей идее похож на метод корреляционных плеяд: строят граф (дерево максимальной длины), а затем его разрезают по ребрам с минимальными связями. Имеется множество алгоритмов, например, " Краб" в, в которых " разрезание" по ребрам осуществляется по критерию, представленному некоторой функцией многих переменных, сконструированной из эвристических соображений. Алгоритмы, основанные на дереве максимальной длины, применяют на стадии предварительного анализа. Вариационный подход к решению задачи конструирования группировки обычно предполагает наличие некоторого критерия качества группировки. Этот критерий, как правило, выводится формально из модели данных. Он или оценивает степень близости группировки к некоторой " идеальной", или минимизирует " погрешность" в аппроксимационных моделях данных. В первом случае учитывается не только требование компактности групп, но и представление об их количестве и их наполненности. Так как сама сконструированная группировка в этом случае в силу эквивалентности качественного признака и разбиения (группировки) есть реализация некоторого латентного признака, порожденного свойством многомерности данных, то по сути критерий качества группировки отражает степень " аппроксимации" всех признаков в совокупности одним сконструированным качественным признаком. Во втором случае критерий качества выводится из самой модели данных, в которой предполагается, что матрица связи " порождена" однимили несколькими качественными факторами. Это может быть формализовано в модели тем, что матрицу связи " объект-объект" аппроксимируют линейной комбинацией матриц связи, вид каждой из которых алгоритмически определяется свойствами качественного фактора, ей соответствующего. Достигается это тем, что при конструировании качественного фактора оценивается степень учета исходной информации, в том числе и доля разброса исходных данных, участвующих в получении решения. Примером вариационного подхода может служить группировка признаков методом экстремальной группировки параметров, а также все алгоритмы и методы в матричном подходе к анализу данных. Наиболее хорошо зарекомендовавшим себя подходом в решении задач многомерной группировки является вариационный, исходной информацией для которого служит матрица связи " объект-объект", а сама группировка осуществляется в терминах связей между объектами. В качестве примера формализованной в рамках этого подхода задачи нахождения группировки может быть приведена следующая постановка задачи. Пусть а =
суммы внутренних связей в При этом считают, что диагональные элементы а) сумма внутренних связей
в каждом классе б) суммарная связь
между любыми двумя классами Схема алгоритмов локальной оптимизации включает в себя три части и начинается с тривиального разбиения множества объектов на Полученное разбиение улучшается с помощью алгоритма " Перемещение", после чего проводится проверка: удовлетворяет ли полученное разбиение необходимым условиям оптимальности а) и б). После проверки те классы, которые не удовлетворяют условию а), рассыпаются на одноэлементные подклассы, после чего опять применяется объединение с последующим перемещением - и так до тех пор, пока условия а) и б) не окажутся выполненными. Количество классов разбиения определяется только величиной порога, который часто из содержательных педставлений о конкретной задаче легче задать интуитивно, чем более формальную величину числа классов. В связи с работой в итеративном режиме " человек-ЭВМ" при построении классификации появились и сформулированы требования к методам, с помощью которых они осуществляются: универсальность, интерпретируемость результатов, адаптируемость.
Кластерный анализ КЛАСТЕР (англ. Cluster (группа)) в прикладной статистике– группа объектов такая, что средний квадрат внутригруппового расстояния в какой-либо метрике до центра группы меньше среднего квадрата расстояния до общего центра в исходной совокупности. КЛАСТЕРНЫЙ АНАЛИЗ (англ. Cluster analysis )– реализация математических методов, предназначенных для формирования относительно «отдаленных» друг от друга групп «близких» между собой объектов во введенных мерах близости между ними. По смыслу аналогичен терминам: автоматическая классификация, таксономия, распознавание образов без учителя. Используется для анализа структуры совокупностей социально-экон. показателей по заданной матрице коэффициентов корреляции между ними, социально-экон. объектов (предприятий, регионов, социологических анкет), описанных многими априорно равноправными признаками, и т. п. Алгоритмические процедуры К. а. обычно включают параметры, задаваемые исследователем (число классов, порог значимости и т. п.), что позволяет получать несколько решений, из к-рых исследователь выбирает наилучшее с точки зрения интерпретации в терминах теоретических представлений о конкретном изучаемом явлении. В современной статистике для построения многомерных группировок обычно используют один из подходов: факторный анализ или кластер-анализ. Как известно, факторный анализ состоит в переходе к малому числу латентных (скрытых) переменных — факторов и проведении классификации объектов по этим факторам. Это один из самых распространенных методов анализа многомерной информации. Так, в региональных социально-экономических и демографических исследованиях городов и населенных пунктов обычно использованы методы факторного анализа. Что касается кластер-анализа, то он позволяет анализировать одновременно много признаков, но обычные методы и программы кластер-анализа имеют ряд недостатков: - много априорных параметров (число классов, порог существенности связей и т.д.); - непосредственным результатом кластер-анализа является состав классов (групп), а все характеристики этих классов, необходимые для интерпретации, носят внешний характер по отношению к рассматриваемой модели. Таким образом, и эти наиболее часто используемые модели анализа данных не лишены недостатков, которые можно считать уже традиционными — это недостаточное соответствие между математической формализацией (моделью) и той реальностью, которую эта модель призвана отражать. Можно выделить причины этого несоответствия: 1) зачастую используются методы, разработанные для нужд других наук, в то время как методы, весьма полезные в социально-экономических исследованиях, остаются неизвестными исследователям; 2) при использовании математико-статистических методов часто не учитывается, что каждый математический метод имеет свою область эффективности и предполагает определенную модель явления, которая, как правило, отражает лишь какую-то сторону реальности. В исследованиях социально-экономического развития регионов предлагается использовать две модели, которые в какой-то степени преодолевают указанные недостатки. Первая модель — метод главных кластеров основана на линейной модели агрегирования данных и в качестве решения содержит, кроме состава классов, ряд параметров самой модели. Рассмотрим идею этого метода, алгоритмическую реализацию его, а также возможности предлагаемой модели для статистического анализа полученных в результате работы алгоритма группировок многомерных объектов и их содержательной интерпретации. Исходная информация в методе главных кластеров предполагается заданной в виде матрицы " объект-признак" и порождается суммами " вкладов" отдельных кластеров. Модель является линейной, и соотношения модели аналогичны соотношениям модели главных компонент. Полученные в результате работы алгоритма группировки описываются параметрами, заложенными в самой модели: оценивается вклад каждого кластера в дисперсию исходных данных и на этой основе оценивается сравнительная значимость кластеров, указываются эталонные значения признаков для каждого кластера, а также веса признаков в каждом кластере. Применяемый метод позволяет не фиксировать число кластеров заранее, а определить в процессе решения на основе анализа соответствующей доли дисперсии до исчерпания всех объектов множества. Итак, модель имеет следующий вид. Пусть Y = где
Обозначим через
и где В этих терминах модель имеет следующий вид:
где Заметим, что матрица Y может быть стандартизована (хотя это и не обязательно). Необходимо найти векторы f t, a t (
При реализации этого метода используется принцип последовательного исчерпания данных, аналогичный тому, который используется в методе главных компонент. Метод главных кластеров основан на той же модели агрегирования, что и метод главных компонент, но
где |
Последнее изменение этой страницы: 2017-03-15; Просмотров: 4043; Нарушение авторского права страницы
 - число объектов,
- число объектов, 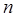 - число признаков, тогда нормированное значение
- число признаков, тогда нормированное значение  -ro признака, полученное из исходной информации типа " объект-признак", необходимо представить в виде
-ro признака, полученное из исходной информации типа " объект-признак", необходимо представить в виде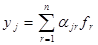
 -
- 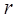 -я главная компонента;
-я главная компонента;  - вес
- вес 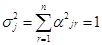
 - доля полной дисперсии
- доля полной дисперсии  ).
).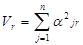 ,
,  );
);  ),
),  ,
,  - число " весомых" главных компонент (
- число " весомых" главных компонент (  ).
).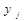 .
.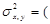 X, Y
X, Y  . Дисперсия случайной величины Х
. Дисперсия случайной величины Х  X, X
X, X  X 2.
X 2. разбито на непересекающиеся группы
разбито на непересекающиеся группы  и заданы случайные величины
и заданы случайные величины 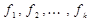 , такие, что
, такие, что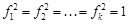 ,
, 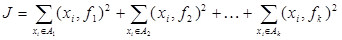 .
.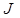 соответствует требованию такого разбиения параметров, когда в одну группу попадают наиболее " близкие" между собой параметры. Действительно, при максимизации функционала для каждого фиксированного набора случайных величин
соответствует требованию такого разбиения параметров, когда в одну группу попадают наиболее " близкие" между собой параметры. Действительно, при максимизации функционала для каждого фиксированного набора случайных величин  -ю группу будут попадать такие параметры, которые наиболее " близки" к
-ю группу будут попадать такие параметры, которые наиболее " близки" к  ; в то же время среди всех возможных наборов случайных величин
; в то же время среди всех возможных наборов случайных величин 
 фактор
фактор  , (1)
, (1) - компоненты собственного вектора матрицы R l = {(
- компоненты собственного вектора матрицы R l = {(  )},
)},  , соответствующего ее наибольшему собственному числу. С другой стороны, если величины
, соответствующего ее наибольшему собственному числу. С другой стороны, если величины 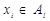
 ,
, 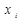 из группы
из группы  , для которой это соотношение неверно.
, для которой это соотношение неверно. -м шаге итерации построено разбиение
-м шаге итерации построено разбиение  . Для каждой группы параметров строят факторы
. Для каждой группы параметров строят факторы  по формуле (1) и новое,
по формуле (1) и новое,  -е разбиение
-е разбиение  по правилу:
по правилу:  , если
, если . (2)
. (2)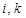 )-м месте записано значение
)-м месте записано значение  -го признака, соответствующее
-го признака, соответствующее  -му объекту, -
-му объекту, -  . Объект изучаемой совокупности представляется в таблице в виде строки значений признаков на этом объекте или в виде точки в
. Объект изучаемой совокупности представляется в таблице в виде строки значений признаков на этом объекте или в виде точки в  .
. точек
точек 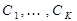
 в пространстве признаков, которые объявляются центрами классов.
в пространстве признаков, которые объявляются центрами классов. относится к
относится к 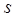 -му классу,
-му классу, 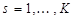 , если при
, если при  достигает минимума
достигает минимума  - расстояние между объектом
- расстояние между объектом 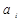 и центром
и центром  -й итерации.
-й итерации.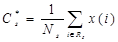 ,
, 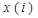 - вектор значений признаков на
- вектор значений признаков на 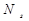 - мощность (число объектов) класса
- мощность (число объектов) класса 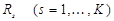 .
. . Если массив объектов исчерпан, а последовательность центров не стабилизировалась, то описанный процесс повторяется с самого начала, причем в качестве исходных центров выбираются центры, подучившиеся на последней итерации.
. Если массив объектов исчерпан, а последовательность центров не стабилизировалась, то описанный процесс повторяется с самого начала, причем в качестве исходных центров выбираются центры, подучившиеся на последней итерации. . Объекты с номерами
. Объекты с номерами  | максимальна, причем
| максимальна, причем  .
. шагов будем иметь
шагов будем иметь  . В качестве центра
. В качестве центра 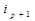 берется объект с таким номером
берется объект с таким номером 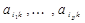 отрицательны, а |
отрицательны, а |  | максимальна по всем таким
| максимальна по всем таким  с каждым из центров
с каждым из центров  . Объект
. Объект  , если
, если ,
,  -го класса выбирает объект этого класса, такой, что
-го класса выбирает объект этого класса, такой, что .
. - матрица связей между объектами. Найти разбиение
- матрица связей между объектами. Найти разбиение 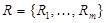 множества элементов на заранее не заданное число
множества элементов на заранее не заданное число  . которое максимизирует величину вида
. которое максимизирует величину вида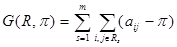
 за вычетом определенного порогового значения
за вычетом определенного порогового значения 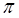 .
. . Оказывается, что если
. Оказывается, что если  , то:
, то: 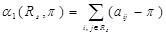

 неположительна.
неположительна. максимальны до тех пор, пока все величины
максимальны до тех пор, пока все величины  - матрица данных " объект-признак",
- матрица данных " объект-признак",  );
);  );
);  - значение
- значение  искомые кластеры (группы), численности которых равны
искомые кластеры (группы), численности которых равны  соответственно. Количество самих кластеров, а также число объектов в каждой из групп заранее не определены. Каждому кластеру сопоставим два нижеследующих вектора:
соответственно. Количество самих кластеров, а также число объектов в каждой из групп заранее не определены. Каждому кластеру сопоставим два нижеследующих вектора:  , где
, где 
 ,
, 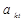 - " эталонное" значение признака
- " эталонное" значение признака 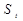 (
( 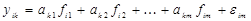 ,
,  - " невязки" соотношений модели агрегирования, (
- " невязки" соотношений модели агрегирования, (  ) исходя из требования минимизации суммарной квадратичной невязки
) исходя из требования минимизации суммарной квадратичной невязки .
. принимает " нуль-единичные" значения, а не произвольные, как в методе главных компонент. Согласно указанному принципу, кластеры
принимает " нуль-единичные" значения, а не произвольные, как в методе главных компонент. Согласно указанному принципу, кластеры 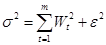 , (3)
, (3) - суммарная дисперсия исходных данных;
- суммарная дисперсия исходных данных;