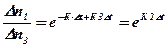|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Контроль надежности ПО в процессе отладки и эксплуатации. Математическая модель надежности ПО
Отладка проводится по выбранным вариантам функционирования ПО. При назначении критерия отбора вариантов на отладку имеется некоторая свобода выбора – некоторый волюнтаризм: что накрывать маршруты, дуги или узлы. Накрывать узлы очевидно, что плохо. А вот накрытие ребер применяется часто, так как число вариантов отладки с накрытием маршрутов на графе максимально и максимальна трудоемкость отладки. Для практики крайне желательно иметь математическую модель прогнозирования надежности ПО в том числе при отладке, по которой можно было снимать эту неопределенность и неуверенность в качестве отладки и оценивать, например, необходимость продолжения отладки, планировать точку останова этого процесса каким -то другим методом. Число свободных параметров подобной модели желательно иметь небольшим, а число экспериментальных данных наоборот большим. Это на первый взгляд является противоречием и должно составить проблему: ведь по законам алгебры число уравнений должно равняться числу переменных, которые необходимо найти. Однако, опасаться того, что число переменных может стать меньше числа уравнений для их определения, не надо. Метод наименьших квадратов (МНК), которым мы будем пользоваться, не только аппроксимирует случайные экспериментальные данные, но и позволяет получать решение «переопределенной» в алгебраическом смысле системы уравнений. Оставим на время дискретную модель надежности ПО и запишем выражение, вытекающее из гипотезы Джелинского Моранды, в виде дифференциального уравнения, понимая что интенсивность отказов по определению – это скорость изменения числа обнаруженных ошибок
. Здесь N0 – начальное число ошибок, n –число обнаруженных ошибок, К – коэффициент пропорциональности
Решение приведенного выше дифференциального уравнения первого порядка n = N0 ( 1 – е-кt ) и
Можно показать, что данные выражения справедливы для математических ожиданий
Мы получили дискретную и непрерывную модели надежности ПО, относительно одних и тех же параметров N0 и К. Дискретная модель определяет ВБР за время t, непрерывная число проявившихся ошибок на момент времени t. При экспериментальных наблюдениях за проявлением ошибок в ПО мы наблюдаем именно число проявившихся ошибок, поэтому рассмотрим подробнее непрерывную модель. При этом удобнее не рассматривать общее количество проявившихся ошибок с нарастающим итогом, а рассматривать количество ошибок, проявившихся на фиксированных интервалах времени. Запишем выражение для количества ошибок, проявившихся на интервале Dti, полагая равномерным шаг наблюдений за проявлениями ошибок Dt.
Здесь Dni - приращение количества обнаруженных ошибок на интервале Dt. Пусть шаг Dt можно выбрать так, чтобы произведение КDt < 1. Тогда, разлагая exp функцию в ряд и пренебрегая членами выше 1-ой степени К·Dt, как малыми, имеем: еxp(x)=1+х/1! +х2 / 2! +…..=1+ К·Dt
1) В данном уравнении два неизвестных N0 и К. Для их определения достаточно рассмотреть два различных интервала Dt - будет два уравнения с двумя неизвестными.
Обозначим измеренное значение количества проявившихся ошибок на интервалах Dti как Dni и рассмотрим, например, моменты времени t1 и t3. Для этих моментов
Разделим первое уравнение на второе ( при Dn3 ¹ 0 )
Отсюда, разлагая ехр в ряд и пренебрегая членами второго порядка малости, имеем
Определим из первого уравнения N0, подставляя в него полученное выражение для К. Полученное решение не соответствует всей совокупности экспериментальных данных и в этом смысле неверно. Очевидно, что также неверный результат мы получили, если бы рассмотрели моменты времени Dt1 и Dt2. Таким образом подход, связанный с выбором 2 наблюдений, приводит к неправильному результату. Однако, возникает вопрос какую пару интервалов из r имеющихся интервалов наблюдений выбрать для определения N0 и К, так как каждой паре интервалов соответствует в общем случае свое решение относительно N0 и К. Полученное по каждой паре случайно «пляшущих» данных решение не соответствует всей совокупности экспериментальных данных и в этом смысле не имеет особого смысла. Нужно использовать всю совокупность наблюдений. Однако, это на первый взгляд приведет к получению переопределенной системы уравнений (число уравнений, больше числа неизвестных).
|
Последнее изменение этой страницы: 2017-04-12; Просмотров: 440; Нарушение авторского права страницы
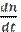 = K× (N0 – n)
= K× (N0 – n) N0 е-кt К> 0
N0 е-кt К> 0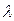 , n, Nо, если рассматривать процесс проявления ошибок в ПО, как случайный.
, n, Nо, если рассматривать процесс проявления ошибок в ПО, как случайный.