
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
ПРОВЕРКА ПАРАМЕТРИЧЕСКИХ СТАТИСТИЧЕСКИХ ГИПОТЕЗ
Цель работы: ознакомиться с методикой проведения проверки параметрических гипотез. Задание : По выборке из лабораторной работы № 1 и заданному значению математического ожидания провести проверку гипотезы Н0 о равенстве математического ожидания заданному значению против предложенного вида альтернативной гипотезы На: Н0: На:
В данном случае критерием для проверки нулевой гипотезы является случайная величина
Доказано, что если гипотеза Н0 верна, то с.в. t имеет распределение Стьюдента с ν = n – 1 степенями свободы. Алгоритм проверки гипотезы Н0 следующий:
• по формуле (2.1) вычисляется значение критерия t;
• в таблице (Приложение А) по заданному уровню значимости α и числу степеней свободы ν = n – 1 находят критическую точку
• если
–
то считается, что нет оснований для отклонения гипотезы Н0.
Если же
t ≤ –
то нулевая гипотеза отклоняется в пользу альтернативной. Пример выполнения лабораторной работы
При проведении экспериментов фиксировались значения случайной величины X, характеризующей стоимость строительно-монтажных работ на участке, у.е.. В результате расчетов в Лабораторной работе № 1 подсчитано, что выборочное среднее значение равно Можно ли на основании имеющихся данных утверждать, что стоимость строительно-монтажных работ на участке, у.е в среднем составляет
Решение. Требуется на заданном уровне значимости α проверить гипотезу Н0 при альтернативе На:
Н0: На:
Вычислим значение критерия t по формуле (3.1)
В таблице Г.3 найдем критическую точку То есть можно считать, что стоимость строительно-монтажных работ на участке в среднем составляет 127 у.е. Задание на выполнение работы
Решить задачу по варианту. Решение должно быть выполнено по алгоритму: • сформулировать случайную величину (величины), которая будет исследоваться в задаче; • указать, подчиняется ли исследуемая случайная величина (величины) нормальному закону распределения; • записать (найти) оценки параметров исследуемой случайной величины (величин); • сформулировать нулевую и альтернативную гипотезы; • записать формулу для вычисления статистического критерия, который будет использоваться для проверки выдвинутой нулевой гипотезы; • выполнить необходимые вычисления и сделать вывод о принятии или отклонении нулевой гипотезы; • ответить на вопрос, сформулированный в задаче. Распределение вариантов заданий
Порядок выполнения работы 1 Изучить теоретические сведения. 2 Записать на диск выборку случайной величины, которую требуется исследовать. 3 По этой выборке и заданному значению математического ожидания провести проверку гипотезы о равенстве математического ожидания заданному значению против предложенного вида альтернативной гипотезы: – вручную рассчитать значение выборочной статистики и сравнить его с критическим значением; – с помощь процедуры «One-Sample Analysis» пакета Statgrafics. 5 Сделать выводы. Контрольные вопросы 1 Что называется статистической гипотезой? 2 Дайте определение параметрической и непараметрической статистических гипотез. 3 Что такое нулевая и альтернативная гипотезы? 4 Что называется статистическим критерием? 5 Что называется уровнем значимости статистического критерия? 6 Что называется областью допустимых значений статистического критерия? 7 Сформулируйте правило принятия решения на основании выборочного значения статистического критерия. РЕГРЕССИОННЫЙ АНАЛИЗ 4.1 Задачи регрессии. Общий вид уравнения регрессии
Определение 4.1 Функциональной называется однозначная зависимость между переменными величинами, когда определенному значению одной (независимой) переменной х, называемой аргументом, соответствует определенное значение другой (зависимой) переменной у, называемой функцией. (Пример: зависимость скорости химической реакции от температуры; зависимость силы притяжения от масс притягивающихся тел и расстояния между ними). Определение 4.2 Корреляционной называется зависимость между переменными, имеющими статистистический характер, когда определенному значению одного признака (рассматриваемого в качестве независимой переменной) соответствует целый ряд числовых значений другого признака. (Пример: связь между прибылью организации и материальными затратами, урожаем и количеством осадков; между расходом топлива и весом автомобиля и т.д.). Определение 4.3 Поле корреляции представляет собой множество точек, координаты которых равны полученным на опыте парам значений переменных х и у. Корреляционный анализ рассматривает две задачи. Первая задача теории корреляции – установить форму корреляционной связи, то есть вид функции регрессии (линейная, квадратичная и так далее). Вторая задача теории корреляции – оценить силу (тесноту) корреляционной связи. Теснота корреляционной связи (зависимости) Y на Х оценивается по величине рассеивания значений Y вокруг условного среднего. Большое рассеивание свидетельствует о слабой зависимости Y от Х, малое рассеивание указывает на наличие сильной зависимости. По виду корреляционного поля можно судить о наличии или отсутствии связи и ее типе. Визуальный анализ диаграммы рассеяния и предметная постановка задачи (физический смысл рассматриваемых величин) позволяет сделать предположение о виде уравнения регрессии. Связь называется положительной, если при увеличении одной переменной увеличивается другая переменная. Связь называется отрицательной, если при увеличении одной переменной уменьшается другая переменная.
а) Связь между величинами прямая б) Связь между величинами обратная
в) Связь между величинами квадратичная г) Связи между величинами нет
Вычисление регрессии - это метод измерения связи между одной или несколькими причинами и следствием. Он решает следующие задачи: - форма связи численно выражается соответствующей функцией, которая характеризует главное в связи, так как она показывает действие одной или нескольких основных причин, причем влияние второстепенных причин исключается; - определяется величина следствия, зависящая от величины причины. В частности устанавливается, как изменяется следствие, если причина изменяется на единицу; - предполагаемую величину следствия можно определить, выйдя за пределы имеющейся вариации (экстраполяции) или внутри пределов вариации для ненаблюдавшихся причин (интерполяция). При этом следует учитывать, что причины в комплексе их могут изменять свое значение и что поэтому прогноз будет тем менее точным, чем больше мы выходим за пределы наблюдавшейся вариации. Отклонения между связью, определяемой только влиянием основных причин, и действительно существующей связью дают сведения об изменчивости следствия. Разработано множество методов изучения связей, выбор которых зависит от целей исследования и от поставленных задач. Вместе с тем следует учитывать, что полную характеристику каждому типу явлений можно дать при использовании системы признаков. Признак - это основная отличительная черта, особенность изучаемого явления или процесса. Количественное представление признака называется показателем. Для экономических явлений характерны корреляционные связи: конкретной величине причины противостоят различные, но находящиеся в определенных пределах величины следствия, так как на действительную связь влияют второстепенные причины. Влияние второстепенных причин исключают, приводя корреляционную связь к функциональной, на которую влияют только основные причины. Функциональная связь выражается уравнением. Оно характеризует связь в среднем, исключая рассеивание. Регрессионный анализ – это раздел статистического анализа данных, в рамках которого осуществляется построение и исследование регрессионных зависимостей между величинами. Целью регрессионного анализа является оценка функциональной зависимости условного среднего значения результативного признака (У) от факторных (
Определение 4.5 Регрессионная модель - запись выявленной связи между результативным показателем и факторами в виде уравнения в постановке, когда реализация резулыир\10щего показателя имеет случайную составляющую, а факторы - детерминированные. Теоретической линией регрессии называется та линия, вокруг которой группируются точки корреляционного поля и которая указывает основное направление, основную тенденцию связи. Регрессионный анализ часто ограничивается простой связью между одной причиной и одним следствием. Связь можно исследовать комплексно при помощи множественной регрессии, как связь между следствием и двумя или многими причинами. Там, где это целесообразно, следует ограничиваться простой регрессией. Так, например, между расходами на товары и коммунальные услуги и доходом семей очень трудно установить законномерную связь. Она становится видимой, если привлечь сюда еще данные о величине семей. В таких случаях следует прибегать к множественной регрессии. Но ее нужно, однако, обязательно ограничивать необходимым числом причин; так, в приведенном примере следует отказаться от данных о числе лиц, получающих доход. Таким образом, одной из проблем построения уравнения регрессии является ее размерность, т.е. определение числа факторных признаков, включаемых в модель. Их число должно быть оптимальным. Сокращение размерности за счет исключения второстепенных, несущественных факторов позволяет получить модель, реализуемую быстрее и качественнее. В то же время построение модели малой размерности может привести к тому, что она будет недостаточно точно описывать исследуемое явление или процесс. Практика выработала определенный критерий, позволяющий установить оптимальное соотношение между числом факторных признаков, включаемых в модель, и объемом исследуемой совокупности. Согласно данному критерию число факторных признаков должно быть в 5-6 раз меньше объема изучаемой совокупности. Регрессионный анализ включает следующие этапы: 1) определение типа функции; 2) определение и проверку коэффициентов регрессии; 3) расчет значений функции для отдельных значений аргумента; 4) исследование рассеивания по отклонениям расчетных значений от эмпирических данных. Решающим этапом регрессионного анализа является определение типа функции, так как от этого зависит, правильно ли алгебраическое уравнение отражает сущность связи между явлениями. Чтобы можно было правильно определить тип функции, нужно из эмпирических данные получить ответ на следующие вопросы вопросы: 1)каково направление связи; 2) изменяется ли направление связи в исследуемой совокупности, т.е. является ли зависимость монотонной; 3) вытекает ли форма связи из равномерно ускоряющихся или замедляющихся изменений, т.е. имеет связь линейный или нелинейный характер. Необходимые для определения типа функции сведения получают из эмпирического материала. Представление о направлении и форме связи (аналитическому выражению) получают путем параллельного сравнения рядов и из графика. По направлению связи различают: а) прямую регрессию, возникающую при условии, если с увеличением или уменьшением независимой величины х значения зависимой величины Y также соответственно увеличиваются б) обратную регрессию: появляющуюся при условии, что с увеличением или уменьшением независимой величины х зависимая величина У, соответственно, уменьшается или увеличивается. Для определения формы связи рекомендуется сравнить разности между следующими друг за другом величинами признака. Если признаки возрастают одинаково, примерно в арифметической прогрессии, то это свидетельствует о том, что связь между ними линейная. Если тенденция изменения Y в зависимости от изменения х отсутствует, то это свидетельствует о сильной вариации Y или о невозможности установить наличие действительной связи. Все приведенные выше рассуждения относительно х и У относились к парной регрессии, характеризующей связь между двумя признаками: результативным и факторным. Для характеристики связей экономических явлений используют, прежде всего, следующие типы функций: линейную, гиперболическую, показательную, параболическую, степенную, логарифмическою. Две (или несколько) случайных величин могут быть связаны либо функциональной, либо статистической зависимостью. Строгая функциональная зависимость реализуется редко, так как случайные величины подвержены действию случайных факторов, причем среди них могут быть и общие для двух или нескольких величин. В этом случае возникает статистическая зависимость. Статистической называют зависимость, при которой изменение одной из величин влечет изменение распределения другой. В частности, статистическая зависимость проявляется в том, что при изменении одной из величин изменяется среднее значение другой – в этом случае статистическая зависимость называется корреляционной. Метод наименьших квадратов Наилучшие (несмещенные, состоятельные и эффективные) оценки неизвестных параметров линейной регрессии b0 и b1 могут быть получены методом наименьших квадратов, смысл которого заключается в следующем. Рассмотрим функцию S, равную сумме квадратов отклонений выборочных значений yi случайной величины Y от значения
Фактически эти отклонения в каждой точке xi равны ei, т. е. той ошибке, которая обусловлена упрощением вида зависимости Y от X (без учёта дополнительных влияющих факторов), а также возможной ошибкой в выборе формы регрессии (в действительности она может описываться другим уравнением). Оценки
Рисунок 4.2 – Отклонения результатов
Из курса математического анализа известно, что для нахождения минимума функции S(
Система линейных уравнений (1) имеет единственное решение, если определитель матрицы ее коэффициентов не равен нулю. Полученные значения
Þ Þ
Уравнения (4.2) называются нормальными уравнениями. Для предполагаемой линейной регрессионной зависимости (1) оценки минимизируют ошибку, возникающую при аппроксимации выборки прямой, и вычисляются по формулам:
В результате оценка уравнения линейной регрессии (эмпирическое уравнение линейной регрессии, прямая МНК) будет иметь вид: В таблице 4.1 приведены системы уравнений для нахождения оценок параметров некоторых регрессионных моделей. Таблица 4.1 – Системы уравнений для нахождения оценок параметров
Корреляционный анализ
Помимо предположения о форме регрессионной зависимости между случайными величинами и нахождения его параметров исследователю требуется оценить насколько удачно выбранное уравнение регрессии объясняет существующую зависимость между исследуемыми с. в. Коэффициент корреляции. Основной числовой характеристикой, определяющей тесноту линейной регрессионной зависимости (*) между двумя случайными величинами, является коэффициент корреляции
где M(XY) – математическое ожидание произведения с. в. X и Y. Коэффициент корреляции является безразмерной величиной и может принимать значения из интервала: –1 £ r £ 1. Для линейно независимых случайных величин Х и Y коэффициент корреляции равен нулю. Экстремальные значения 1 или –1 коэффициента корреляции соответствуют линейной функциональной зависимости между двумя с. в. (положительной и отрицательной соответственно). Таким образом, можно говорить, что коэффициент корреляции характеризует степень линейной регрессионной зависимости между двумя с. в., близость ее к линейной функциональной зависимости. По заданной двумерной выборке, оценку коэффициента корреляции
При большом числе независимых наблюдений, подчиняющихся одному и тому же распределению, близкому к нормальному, оценка Качественная оценка тесноты связи между величинами выявляется по шкале Чеддока (таблица 4.1).
Таблица 4.2 - Шкала Чеддока
Коэффициент детерминации. Для характеристики тесноты связи между случайными величинами, описываемой нелинейной функцией регрессии, используется коэффициент детерминации. Данный коэффициент характеризует качество описания зависимости между двумя с. в. выбранным уравнением регрессии. Очевидно, чем теснее наблюдения примыкают к линии регрессии, тем лучше регрессия описывает соответствующую зависимость и потому с большей надежностью может быть применена для практических расчетов. Коэффициент детерминации рассчитывается по формуле (4.7) и может принимать значения в интервале от нуля до единицы (0 £ R2 £ 1):
где Анализ (4.7) показывает, что коэффициент детерминации характеризует насколько хорошо уравнение регрессии предсказывает значения зависимой с. в. Y, т. е. объясняет ее рассеяние в общей величине рассеяния (дисперсии) зависимой с. в. Таким образом, коэффициент детерминации рассматривается как мера качества описания зависимости между с. в. с помощью уравнения регрессии, т. е. характеризует насколько удачно выбранная модель (уравнение) регрессии описывает действительную зависимость между с. в. Равенство коэффициента детерминации нулю указывает на то, что выбранное уравнение регрессии (модель зависимости) никак не объясняет действительную зависимость между с. в. Равенство же коэффициента детерминации единице указывает на то, что зависимость между случайными величинами является функциональной, описываемой уравнением регрессии, т. е. выбранное уравнение регрессии полностью (однозначно) определяет зависимость между с. в. Если значение коэффициента детерминации больше 0, 7, то считают, что выбранное уравнение регрессии хорошо описывает зависимость, существующую между случайными величинами. Если же коэффициент детерминации меньше 0, 3, то уравнение регрессии незначительно описывает зависимость между случайными величинами, если таковая существует.
|
Последнее изменение этой страницы: 2017-05-05; Просмотров: 684; Нарушение авторского права страницы
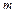 =
= 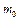 ;
; 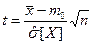 (2.1)
(2.1)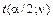 распределения Стьюдента;
распределения Стьюдента; 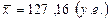 , а выборочное среднее квадратическое отклонение этого параметра
, а выборочное среднее квадратическое отклонение этого параметра  .
. ?
? 
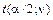 распределения Стьюдента при уровне значимости α = 0, 05 и числе степеней свободы
распределения Стьюдента при уровне значимости α = 0, 05 и числе степеней свободы 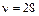 , t(0, 025; 49) = 2, 0095. Поскольку выполняется неравенство
, t(0, 025; 49) = 2, 0095. Поскольку выполняется неравенство  , т.е.
, т.е.  , то имеющиеся статистические данные не дают основания для отклонения нулевой гипотезы.
, то имеющиеся статистические данные не дают основания для отклонения нулевой гипотезы.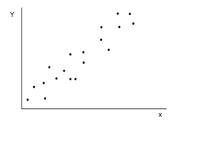



 , выражаемой в виде уравнения регрессии
, выражаемой в виде уравнения регрессии .
.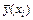 , предсказанного уравнением регрессии в точке X = xi (рисунок 4.1).
, предсказанного уравнением регрессии в точке X = xi (рисунок 4.1).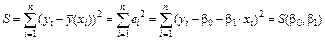 (4.1)
(4.1) и
и  параметров регрессии
параметров регрессии 
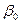 ,
,  (4.1)
(4.1) и
и  , являющиеся решением системы (1), называются оценками параметров регрессии.
, являющиеся решением системы (1), называются оценками параметров регрессии.
 Þ Разделим обе части уравнений на (-2)
Þ Разделим обе части уравнений на (-2)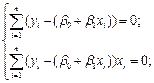 Þ
Þ  Þ
Þ  (4.2)
(4.2)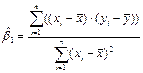 ,
,  , (4.3)
, (4.3) ,
,  . (4.4)
. (4.4) .
.


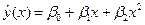


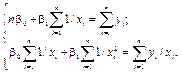


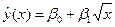

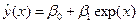

 , (4.5)
, (4.5) можно найти по формуле
можно найти по формуле . (4.6)
. (4.6) , (4.7)
, (4.7)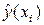 – значение функции в каждой точке после нахождения коэффициентов,
– значение функции в каждой точке после нахождения коэффициентов,  – значения результативного признака выборки,
– значения результативного признака выборки, 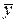 – среднее значение результативного признака выборки. Чем ближе полученный коэффициент к 1 тем теснее нелинейная связь между величинами, если же он = 0, то можно говорить о том, что зависимость выбрана неверно или связи нет.
– среднее значение результативного признака выборки. Чем ближе полученный коэффициент к 1 тем теснее нелинейная связь между величинами, если же он = 0, то можно говорить о том, что зависимость выбрана неверно или связи нет.