
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Общая схема принятия статистических решений ⇐ ПредыдущаяСтр 5 из 5
Обстоятельства принятия статистических решений иллюстрирует схема, приведенная на рис.7.8 [33]. На этой схеме точкой q Î Q изображено то, что нам неизвестно, но необходимо определить; Q – множество всех предполагаемых возможностей относительно q. Точкой x Î X изображена выборка (протокол наблюдений) x = = (x1, ..., xN); X – множество всех возможных выборок. Тот факт, что на реализовавшееся значение выборки оказывает влияние не только искомая закономерность q, но и совокупность случайных факторов, изображен на схеме как результат совместного отображения q и некоторого случайного воздействия n в пространство X с помощью некоторого оператора
Зная x, мы должны сделать выбор относительно q, принять решение, какую из множества альтернатив Q мы примем за истинную. Чтобы не путать принимаемое решение и “истинное” состояние q, обозначим пространство, на котором производится выбор, через Г. Очевидно, что в Г входят все элементы множества Q, но могут войти и дополнительные решения (типа отказа от выбора, требования увеличить число наблюдений или провести рандомизацию и т.п.). Процедура выбора изображена как действие некоторого оператора δ над выборкой x: каждой выборке x этот оператор, называемый решающей функцией, ставит в соответствие решение γ Здесь аргумент i введен, во-первых, для того чтобы подчеркнуть, что одну и ту же выборку можно обрабатывать по-разному, получая решения различного качества, и, во-вторых, чтобы сделать акцент на том, что качество решения зависит не только от того, какой протокол обрабатывается, но и от того, какие априорные предположения вошли в структуру алгоритма. Итак, и проблема синтеза статистических процедур (построения решающих функций), и проблема анализа их качества (оценивания степени близости между γ и θ ) тесно связаны с ролью априорной информации. Определим конкретнее, что именно в статистике понимается под априорной информацией. В нее включают любые сведения, имеющиеся до того, как мы приступили к синтезу новой процедуры δ, в том числе и любую информацию о природе наблюдений (но не саму выборку x, считающуюся информацией апостериорной). Конкретнее априорные сведения характеризуют: 1) пространство ситуаций Q; 2) природу случайных факторов n; 3) оператор μ, определяющий характер взаимодействия q и n; 4) пространство наблюдений X; 5) требования потребителя к качеству решений (нумерация та же, что и на рис. 7.8). Понятие о байесовом подходе Априорная информация может быть более или менее полной и точной; в зависимости от этого по-разному ставятся и решаются статистические задачи выбора. Можно даже утверждать, что разным уровням априорной информации соответствуют различные специфические ветви математической статистики. Так как вся информация о случайном объекте содержится в его распределении вероятностей, то любая статистическая задача, по существу, может быть сведена к выбору определенного распределения из некоторого множества распределений. Априорная информация для такого выбора выражается некоторым функционалом от распределения, значение которого надо оценить. Апостериорная информация для этого содержится в выборке. Различные предположения о том, что именно известно о природе Самое полное описание случайного объекта состоит в задании распределения вероятностей на множестве возможных состояний этого объекта, поэтому наиболее подробное и полное задание априорной информации состоит в том, что считаются известными: - распределение P(q), q Î Q; - условное распределение выборочных значений F(x|q), x Î X, q Î Q; - функция потерь l(γ, q), выражающая отношение потребителя решений к расхождению между γ, т.е. тем, что он должен использовать вместо истинного q, и действительным состоянием q. Такой уровень априорной информации соответствует байесову направлению статистики (Т. Байес – известный английский статистик). Среднее значение потерь l, связанное с конкретным алгоритмом γ обработки наблюдений x, называемое байесовым риском R, принимается за меру качества этого алгоритма. Оптимальная в этом смысле процедура γ * (также называемая байесовой) и считается наилучшим решением задачи:
Наибольшее количество споров относительно байесовых задач вызывала необходимость задавать априорное распределение P(q). Постулат Лапласа – Байеса, предлагающий при неизвестности P(q) считать его равномерным в Q, приводит к противоречиям в случае деформаций пространства Q [39, § 17]. Не помогает и предположение о том, что неизвестное P(q) принадлежит некоторому классу распределений, с тем чтобы взять в этом классе “наихудшее” распределение и для него найти байесову процедуру. Такая минимаксная процедура гарантирует, что “хуже не будет”, если только P(q) действительно входит в заданный класс. Спор между сторонниками байесова подхода и его противниками можно считать историческим недоразумением. В конце концов, было признано, что могут существовать и другие уровни априорной информации, для которых требуется создание своих методов синтеза процедур. Следующим уровнем стал отказ от необходимости знать P(q); на этом уровне в синтезе алгоритмов участвует только информация о семействе функций F(x|q). Оказалось, что если подставить в функцию плотности f(x|q) выборочные значения x1, ..., xN, и рассматривать ее зависимость от q, то такая зависимость L (q |x1, ..., xN) = f(x1, ..., xN |q) обладает замечательными свойствами, из-за которых ее и назвали функцией правдоподобия. Например, если q – неизвестный числовой параметр распределения, то В том случае, когда по выборке x1, ..., xN следует принять решение в пользу одной из конкурирующих гипотез H0 и H1, т.е. решить – это выборка из распределения с плотностью f (x|H0) или f (x|H1), лучшей процедурой является вычисление отношения правдоподобия f(x1, ..., xN|H1) / f(x1, ..., xN|H0) и выбор гипотезы H1, если это отношение превышает заданный порог, и гипотезы H0, если ниже его. В рамках этого уровня возможны и другие методы принятия статистических решений; обычно их использование вызвано соображениями простоты реализации, но по качеству получаемых с их помощью решений они не превосходят процедур, основанных на функции правдоподобия. |
Последнее изменение этой страницы: 2017-05-06; Просмотров: 484; Нарушение авторского права страницы
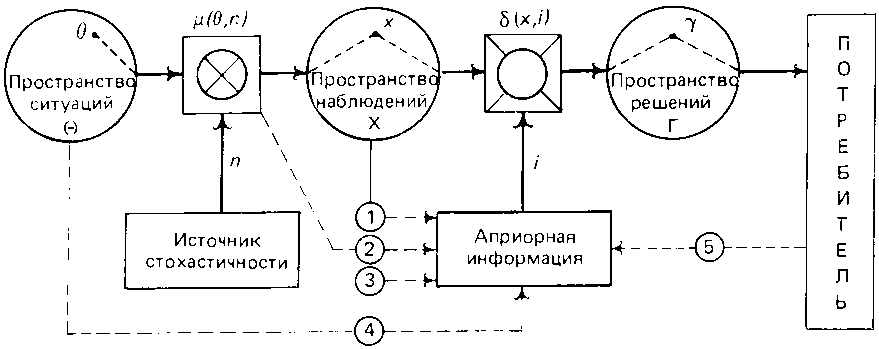 7.8 Общая схема принятия статистических решений
7.8 Общая схема принятия статистических решений
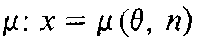 .
.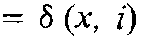 .
.  выборки, порождают различные ветви математической статистики.
выборки, порождают различные ветви математической статистики.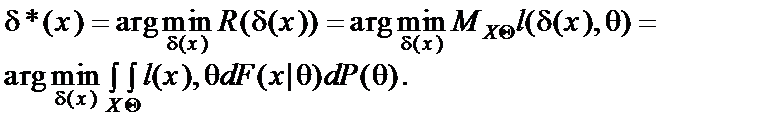
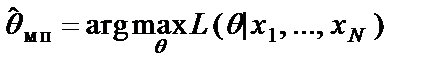 является очень хорошей оценкой рассматриваемого параметра (этот метод оценивания называется методом максимального правдоподобия).
является очень хорошей оценкой рассматриваемого параметра (этот метод оценивания называется методом максимального правдоподобия).