
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
ВЫБОРКА. ОСНОВНЫЕ ХАРАКТЕРИСТИКИ.Стр 1 из 8Следующая ⇒
ГЛАВА ІІ =========== ОСНОВНЫЕ МЕТОДЫ МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ ВЫБОРКА. ОСНОВНЫЕ ХАРАКТЕРИСТИКИ. СТАТИСТИЧЕСКОЕ ОЦЕНИВАНИЕ Изучение статистических закономерностей начинается с фиксации (протоколирования) результатов обследования. Затем эти данные представляются в удобной для обозрения и изучения форме — в виде рядов, многоугольников, гистограмм распределений. Методика получения рядов распределений и их графического изображения — многоугольников и гистограмм — является важным в данной теме. Математическая статистика занимается установлением закономерностей, которым подчинены массовые случайные явления, на основе обработки статистических данных, полученных в результате наблюдений. Двумя основными задачами математической статистики являются: 1. определение способов сбора и группировки этих статистических данных; 2. разработка методов анализа полученных данных в зависимости от целей исследования. К данным методам относятся: а) оценка неизвестной вероятности события; оценка неизвестной функции распределения; оценка параметров распределения, вид которого известен; оценка зависимости от других случайных величин и т.д.; б) проверка статистических гипотез о виде неизвестного распределения или о значениях параметров известного распределения. Для решения этих задач необходимо выбрать из большой совокупности однородных объектов ограниченное количество объектов, по результатам изучения которых можно сделать прогноз относительно исследуемого признака этих объектов. Определим основные понятия математической статистики. Генеральная совокупность – это множество {аi} всех однородных (однотипных) элементов (объектов) аi, подлежащих изучению в данном исследовании. При этом каждому элементу аi соответствует некоторое числовое значение Xi рассматриваемого признака Х. Примером генеральной совокупности может служить работающее население региона или страны, а признаком Х, например, годовой доход работника. Возможно сплошное обследование, когда изучается по рассматриваемому признаку каждый элемент генеральной совокупности без исключения, и выборочное обследование, когда изучению подвергается только некоторая часть элементов (подмножество) генеральной совокупности. Выборка (выборочная совокупность) – это совокупность случайно отобранных по отдельным правилам объектов, составляющих лишь часть генеральной совокупности. Выборка называется репрезентативной (представительной), если она правильно отражает свойства генеральной совокупности (закон и числовые характеристики признака как случайной величины). Учитывая закон больших чисел, можно утверждать, что это условие выполняется, если каждый объект выбран случайно, причем для любого объекта вероятность попасть в выборку одинакова. Объем генеральной совокупности N и объем выборки n – число объектов в рассматриваемой совокупности. Виды выборки: повторная – каждый отобранный объект перед выбором следующего возвращается в генеральную совокупность; бесповторная– отобранный объект в генеральную совокупность не возвращается. Способы первичной обработки выборки Пусть интересующая нас случайная величина Х принимает в выборке значение х1 п1 раз, х2 – п2 раз, …, хк – пк раз, причем
Вариационный ряд, заданный в таком виде, называют дискретным Пример. При проведении 20 серий из 10 бросков игральной кости число выпадений шести очков оказалось равным 1, 1, 4, 0, 1, 2, 1, 2, 2, 0, 5, 3, 3, 1, 0, 2, 2, 3, 4, 1.Составим вариационный ряд: 0, 1, 2, 3, 4, 5. Размах выборки равен 5. Статистический ряд для абсолютных и относительных частот имеет вид:
◄ Пример. Дана выборка, состоящая из чисел: 3.2, 4.1, 8.1, 8.1, 6.7, 4.4, 4.4, 3.2, 5.0, 6.7, 6.7, 7.5, 3.2, 4.4, 6.7, 6.7, 5.0, 5.0, 4.4, 8.1. Составить статистический ряд распределения абсолютных и относительных частот. Объем выборки п = 20. Перепишем варианты в порядке возрастания: 3.2, 3.2, 3.2, 4.4, 4.4, 4.4, 4.4, 4.4, 5.0, 5.0, 5.0, 6.7, 6.7, 6.7, 6.7, 6.7, 7.5, 8.1, 8.1, 8.1. Составлен так называемый вариационный ряд, который показывает, что выборка состоит из шести вариант (3, 4, 5, 6, 7, 8). Составим статистический ряд:
(относительная частота Если исследуется некоторый непрерывный признак, то вариационный ряд может состоять из очень большого количества чисел. В этом случае удобнее использовать группированную выборку. Для ее получения интервал, в котором заключены все наблюдаемые значения признака, разбивают на несколько равных частичных интервалов длиной h,
От интервального ряда можно перейти к дискретному статистическому ряду, взяв на каждом интервале (хi, xi+1) за отдельное значение хi* величину
являющуюся серединой этого интервала.
Распределения В этой теме необходимо усвоить методику оценки неизвестных средней и дисперсии генеральной совокупности по данным обследования выборки для случая, когда наблюдаемая случайная величина распределена нормально. Наряду с материалом пособия следует запомнить, что интервал
Пусть требуется изучить количественный признак генеральной совокупности. Располагая лишь выборочными значениями признака, можно оценить, а не определить точно значения параметров закона или числовых характеристик признака; эти оценки будут случайными и меняться от выборки к выборке. Поэтому важно не только знать оценки неизвестных величин, полученные на основе выборочных данных, но и понимать меры их надежности. Цель любого оценивания – получить как можно более точное значение неизвестной характеристики признака генеральной совокупности по данным выборочного наблюдения. Статистической оценкой неизвестной величины (неизвестного параметра теоретического закона распределения или неизвестной числовой характеристики признака генеральной совокупности) называют функцию от наблюдаемых значений признака как независимых случайных величин. Точечной называют статистическую оценку, которая характеризуется одним числом. Интервальной называют оценку, которая задаётся двумя числами – концами интервала, покрывающего неизвестную величину, внутри которого может находиться оцениваемый параметр генеральной совокупности. Генеральная совокупность характеризуется двумя сторонами: 1) видом распределения (например, равномерное, нормальное, Пуассоновское и т.д.); 2) параметрами распределения (например, математическое ожидание, среднее квадратическое отклонение и т.п.). В связи с этим существует два класса оценок: оценки вида распределения и оценки параметров распределения. К статистической оценке предъявляется ряд естественных требований (несмещённость, состоятельность, эффективность), которые обеспечивают в некотором смысле её «доброкачественность». Определения несмещённой, состоятельной, эффективной оценок смотри в п.3.
1. Точечные оценки параметров распределения. Несмещённой и состоятельной оценкой генеральной средней (математического ожидания признака Х генеральной совокупности) является выборочная средняя 1. Выборочным среднимназывается среднее арифметическое значений случайной величины, принимаемых в выборке:
где xi – варианты, ni - частоты. Замечание. Выборочное среднее служит для оценки математического ожидания исследуемой случайной величины. Выборочной дисперсией называется
Выборочным средним квадратическим отклонением–
Так же справедлива следующая формула для вычисления выборочной дисперсии:
Исправленная выборочная дисперсия
Исправленное выборочное среднее квадратическое отклонение -
Пример. Найдем числовые характеристики выборки, заданной статистическим рядом
■ ▬ ▬ ▬ ►
2. Другими характеристиками вариационного ряда являются: - мода М0 – варианта, имеющая наибольшую частоту (в предыдущем примере М0 = 5). - медиана т е - варианта, которая делит вариационный ряд на две части, равные по числу вариант. Если число вариант нечетно ( n = 2k + 1 ), то me = xk+1, а при четном n =2k Оценки начальных и центральных моментов (так называемые эмпирические моменты) определяются аналогично соответствующим теоретическим моментам: - начальным эмпирическим моментом порядка k называется
В частности, - центральным эмпирическим моментом порядка k называется
В частности, ◄ ▬ ▬ ▬ ■ Для непрерывного распределения применяются те же формулы, но за значения 3. Получив статистические оценки параметров распределения (выборочное среднее, выборочную дисперсию и т.д.), нужно убедиться, что они в достаточной степени служат приближением соответствующих характеристик генеральной совокупности. Определим требования, которые должны при этом выполняться. Пусть Θ * - статистическая оценка неизвестного параметра Θ теоретического распределения. Извлечем из генеральной совокупности несколько выборок одного и того же объема п и вычислим для каждой из них оценку параметра Θ: Статистическая оценка Θ * называется несмещенно й, если ее математичес-кое ожидание равно оцениваемому параметруΘ при любом объеме выборки: М(Θ *) = Θ. Смещенной называют оценку, математическое ожидание которой не равно оцениваемому параметру. Однако несмещенность не является достаточным условием хорошего приближения к истинному значению оцениваемого параметра. Если при этом возможные значения Θ * могут значительно отклоняться от среднего значения, то есть дисперсия Θ * велика, то значение, найденное по данным одной выборки, может значительно отличаться от оцениваемого параметра. Следовательно, требуется наложить ограничения на дисперсию. Статистическая оценка называется эффективной, если она при заданном объеме выборки п имеет наименьшую возможную дисперсию. При рассмотрении выборок большого объема к статистическим оценкам предъявляется еще и требование состоятельности. Состоятельной называется статистическая оценка, которая при п→ ∞ стремится по вероятности к оцениваемому параметру (если эта оценка несмещенная, то она будет состоятельной, если при п→ ∞ ее дисперсия стремится к 0). Заданная таким образом оценка математического ожидания является несмещенной, то есть математическое ожидание выборочного среднего равно оцениваемому параметру (математическому ожиданию исследуемой случай-ной величины). Выборочная дисперсия, напротив, смещенная оценка генеральной дисперсии, и
Соответственно число Пример. Найти выборочное среднее, исправленную выборочную дисперсию и исправленное среднее выборочное отклонение для выборок, заданных в примерах 1 и 2. 1)
2) В выборке из примера 2 будем считать вариантами середины частичных интервалов, то есть определим точечные оценки для выборки
Тогда
Пример. При изучении производительности труда Х на одного работника было обследовано 10 предприятий и получены следующие значения (тыс. руб.): 4, 2; 4, 8; 4, 7; 5, 0; 4, 9; 4, 3; 3, 9; 4, 1; 4, 3; 4, 8. Определить выборочную среднюю, выборочную дисперсию, исправленное среднее квадратическое отклонение. По данной выборке объёма n=10 составим статистический ряд:
По формуле (1) найдется выборочная средняя:
По формуле (2) найдем выборочную дисперсию. Для этого вычислим
Тогда DB=20, 382–20, 25=0, 132. Согласно (4а) S≈ 0, 383. Смысл полученных результатов заключается в следующем. Средняя производительность труда на одного работника для изученных предприятий составила
2. Интервальные оценки параметров распределения. При выборке малого объема точечная оценка может значительно отличаться от оцениваемого параметра, что приводит к грубым ошибкам. Поэтому в таком случае лучше пользоваться интервальными оценками, то есть указывать интервал, в который с заданной вероятностью попадает истинное значение оцениваемого параметра. Разумеется, чем меньше длина этого интервала, тем точнее оценка параметра. Поэтому, если для оценки Θ * некоторого параметра Θ справедливо неравенство | Θ * - Θ | < δ, число δ > 0 характеризует точность оценки(предельность ошибки)( чем меньше δ, тем точнее оценка). Но статистические методы позволяют говорить только о том, что это неравенство выполняется с некоторой вероятностью. Надежностью (доверительной вероятностью)оценки Θ * параметра Θ называется вероятность γ того, что выполняется неравенство | Θ * - Θ | < δ. Если заменить это неравенство двойным неравенством – δ < Θ * - Θ < δ, то получим: p ( Θ * - δ < Θ < Θ * + δ ) = γ. Таким образом, γ есть вероятность того, что Θ попадает в интервал ( Θ *- δ, Θ *+ δ ). Доверительнымназывается интервал, в который попадает неизвестный параметр с заданной надежностью γ; он является симметричной интервальной оценкой неизвестной величины Q. ЭЛЕМЕНТЫ ТЕОРИИ КОРРЕЛЯЦИИ Расчеты коэффициентов корреляции, регрессии достаточно трудоемки. Это объясняется тем, что приходится обрабатывать большое количество исходных данных; ведь одно наблюдение дает сразу две величины. Однако нужно иметь в виду, что если объем выборки невелик, то расчеты этих коэффициентов несложны. При малых выборках общую корреляционную таблицу не составляют, а результат наблюдений оставляют в том виде, каким он получается непосредственно в опыте, т. е. в виде так называемой простой корреляционной таблицы. В такой таблице каждому номеру наблюдений соответствует пара наблюдавшихся значений случайных величин. Конечно, вычисленный по малому числу наблюдений коэффициент в целом имеет меньшую надежность. В тех случаях, когда известен общий вид зависимости между средней одной величины и значениями другой, параметры этой зависимости могут быть найдены методом наименьших квадратов. Линейная корреляция Рассмотрим выборку двумерной случайной величины (Х, Y). Примем в качестве оценок условных математических ожиданий компонент их условные средние значения, а именно: условным средним M (Y / x) = f (x), M ( X / y ) = φ (y). Условные средние - выборочное уравнение регрессии Y на Х, - выборочное уравнение регрессии Х на Y. Соответственно функции f*(x) и φ *(у) называются выборочной регрессией Y на Х и Х на Y, а их графики – выборочными линиями регрессии. Выясним, как определять параметры выборочных уравнений регрессии, если этих уравнений известен. Пусть изучается двумерная случайная величина (Х, Y), и получена выборка из п пар чисел (х1, у1), (х2, у2), …, (хп, уп). Будем искать параметры прямой линии среднеквадратической регрессии Y на Х вида Y = ρ yxx + b, (3) Подбирая параметры ρ ух и b так, чтобы точки на плоскости с координатами (х1, у1), (х2, у2), …, (хп, уп) лежали как можно ближе к прямой (3). Используем для этого метод наименьших квадратов и найдем минимум функции
Приравняем нулю соответствующие частные производные:
В результате получим систему двух линейных уравнений относительно ρ и b:
Ее решение позволяет найти искомые параметры в виде:
При этом предполагалось, что все значения Х и Y наблюдались по одному разу. Теперь рассмотрим случай, когда имеется достаточно большая выборка (не менее 50 значений), и данные сгруппированы в виде корреляционной таблицы:
Здесь nij – число появлений в выборке пары чисел (xi, yj). Поскольку
Можно решить эту систему и найти параметры ρ ух и b, определяющие выборочное уравнение прямой линии регрессии:
Но чаще уравнение регрессии записывают в ином виде, вводя выборочный коэффициент корреляции. Выразим b из второго уравнения системы (7):
Подставим это выражение в уравнение регрессии:
где
и умножим равенство (8) на
Коэффициент корреляции – безразмерная величина, которая служит для оценки степени линейной зависимости между Х и Y: эта связь тем сильнее, чем ближе |r| к единице. Для качественной оценки тесноты корреляционной связи между X и Y можно воспользоваться таблицей Чеддока (табл.1): Таблица 1
Итак, если для выборки двумерной случайной величины (X, Y): {(xi, yi), i = 1, 2,..., n} вычислены выборочные средние
и получить линейные уравнения, описывающие связь между Х и Y, которые называются выборочным уравнением прямой линии регрессии Y на Х:
и выборочным уравнением прямой линии регрессии Х на Y :
Пример. Для выборки двумерной случайной величины
вычислить выборочные средние, выборочные средние квадратические отклонения, выборочный коэффициент корреляции и составить выборочное уравнение прямой линии регрессии Y на Х.
Пример. По заданной корреляционной таблице найти выборочные средние
Вычислим выборочные средние и среднеквадратические отклонения для X, Y
Выборочный коэффициент корреляции между Х и У отыскивается по формуле
Согласно таблице откуда
Выборочное линейное уравнение регрессии У на Х имеет вид
или, с учётом вычисленных значений,
Условное среднее при x = xi вычисляется по формуле
где
Значения условных средних
Отклонения значений,
будут d1 = 0-0.45=-0.45; d2 = 2.6- 1.96 = 0.65; d3 = -0.51, d4 = 0.55; d5 = -0.05; d6 = 0.05. Наибольшее по абсолютной величине отклонение равно 0.65. ◄ Пример. Выборочно обследовано 100 снабженческо-сбытовых предприятий некоторого региона по количеству работников X и объёмам складской реализации Y (д.е.). Результаты представлены в корреляционной таблице;
По данным исследования требуется: 1) в прямоугольной системе координат построить эмпирические ломаные регрессии Y на X и X на Y, сделать предположение в виде корреляционной связи; 2) оценить тесноту линейной корреляционной связи; 3) проверить гипотезу о значимости выборочного коэффициента корреляции, при уровне значимости α =0, 05; 4) составить линейные уравнения регрессии У на X и X на У, построить их графики в одной системе координат; 5) используя полученные уравнения регрессии, оценить ожидаемое среднее значение признака Y при х=40 чел.; дать экономическую интерпретацию полученных результатов. 1. Для построения эмпирических ломаных регрессии вычислим условные средние 2.
то условное среднее При х=15 признак Y имеет распределение
тогда
Аналогично вычисляются все
Таблица 2
Таблица 3
В прямоугольной системе координат построим точки Аi(хi,

Построенные эмпирические ломаные регрессии Y на X и X на Y свидетельствуют о том, что между количеством работающих (X) и объёмом складских реализаций (Y) существует линейная зависимость. Из графика видно, что с увеличением X величина 2. Оценим тесноту связи. Вычислим выборочный коэффициент корреляции, предварительно вычислив характеристики по формулам
|
Последнее изменение этой страницы: 2017-05-11; Просмотров: 2915; Нарушение авторского права страницы
 где п – объем выборки. Тогда наблюдаемые значения случайной величины х1, х2, …, хк называют вариантами, а п1, п2, …, пк – частотами. Если разделить каждую частоту на объем выборки, то получим относительные частоты
где п – объем выборки. Тогда наблюдаемые значения случайной величины х1, х2, …, хк называют вариантами, а п1, п2, …, пк – частотами. Если разделить каждую частоту на объем выборки, то получим относительные частоты 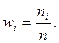 Разность между максимальным и минимальным элементами выборки называетсяразмахом выборки. Последовательность вариант, записанных в порядке возрастания, называют вариационным рядом, а перечень вариант и соответствующих им частот или относительных частот – статистическим рядом:
Разность между максимальным и минимальным элементами выборки называетсяразмахом выборки. Последовательность вариант, записанных в порядке возрастания, называют вариационным рядом, а перечень вариант и соответствующих им частот или относительных частот – статистическим рядом: 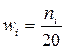 ). ◄
). ◄  , (
, ( 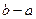 размах выборки), а затем находят для каждого частичного интервала ni – сумму частот вариант, попавших в i-й интервал. В зависимости от объема выборки число интервалов группировки
размах выборки), а затем находят для каждого частичного интервала ni – сумму частот вариант, попавших в i-й интервал. В зависимости от объема выборки число интервалов группировки 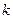 берется от 6 до 20. Составленная по этим результатам таблица называется группированным статистическим рядом:
берется от 6 до 20. Составленная по этим результатам таблица называется группированным статистическим рядом: 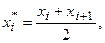
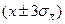 накрывают неизвестную генеральную среднюю с вероятностью 0, 9973; интервал
накрывают неизвестную генеральную среднюю с вероятностью 0, 9973; интервал  с вероятностью 0, 9545. Здесь
с вероятностью 0, 9545. Здесь 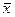 — средняя выборки;
— средняя выборки; 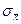 -среднее квадратическое отклонение средней выборки. При такой оценке доверительного интервала, если объем выборки не мал (не менее 25единиц), точное значение генеральной дисперсии
-среднее квадратическое отклонение средней выборки. При такой оценке доверительного интервала, если объем выборки не мал (не менее 25единиц), точное значение генеральной дисперсии  можно заменять приближенным
можно заменять приближенным  , соответствующим данной выборке.
, соответствующим данной выборке.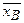 .
. , (1)
, (1)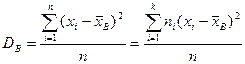 . (2)
. (2)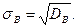 (3)
(3) . (4)
. (4) (4а)
(4а)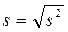 .
.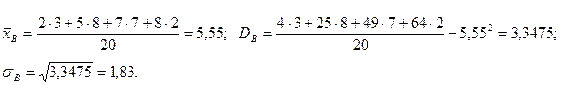
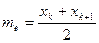 . В частности, в предыдущем примере
. В частности, в предыдущем примере 
 . (5)
. (5) , то есть начальный эмпирический момент первого порядка равен выборочному среднему.
, то есть начальный эмпирический момент первого порядка равен выборочному среднему.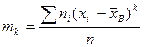 . (6)
. (6) , то есть центральный эмпирический момент второго порядка равен выборочной дисперсии.
, то есть центральный эмпирический момент второго порядка равен выборочной дисперсии.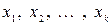 в этих формулах берутся, как правило середины вариант-интервалов. Таким образом, интервальный вариационный ряд заменяется дискретным рядом.
в этих формулах берутся, как правило середины вариант-интервалов. Таким образом, интервальный вариационный ряд заменяется дискретным рядом. Тогда оценку Θ * можно рассматривать как случайную величину, принимающую возможные значения
Тогда оценку Θ * можно рассматривать как случайную величину, принимающую возможные значения 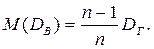 Поэтому и вводится несмещенная оценка генеральной дисперсии – исправленная выборочная дисперсия
Поэтому и вводится несмещенная оценка генеральной дисперсии – исправленная выборочная дисперсия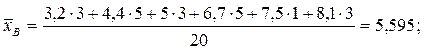


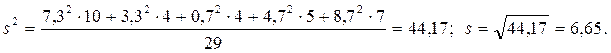 ◄
◄  (тыс. руб.).
(тыс. руб.).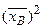 и
и  по формуле (4):
по формуле (4): 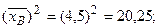

 =4, 5 тыс. руб. Исправленное среднее квадратическое отклонение S описывает абсолютный разброс значений показателя Х и в данном случае составляет S=0, 383 тыс. руб.◄
=4, 5 тыс. руб. Исправленное среднее квадратическое отклонение S описывает абсолютный разброс значений показателя Х и в данном случае составляет S=0, 383 тыс. руб.◄  назовем среднее арифметическое наблюдавшихся значений Y, соответствующих Х = х. Аналогично условное среднее
назовем среднее арифметическое наблюдавшихся значений Y, соответствующих Х = х. Аналогично условное среднее 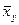 - среднее арифметическое наблюдавшихся значений Х, соответствующих Y = y. Введем уравнения регрессии Y на Х и Х на Y:
- среднее арифметическое наблюдавшихся значений Х, соответствующих Y = y. Введем уравнения регрессии Y на Х и Х на Y: 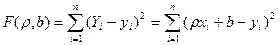 . (4)
. (4) .
. . (5)
. (5) . (6)
. (6)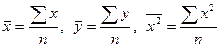 , заменим в системе (5)
, заменим в системе (5) 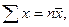
 , где пху – число появлений пары чисел (х, у). Тогда система (5) примет вид:
, где пху – число появлений пары чисел (х, у). Тогда система (5) примет вид: 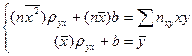 . (7)
. (7)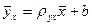 .
.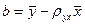 .
.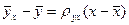 . Из (7)
. Из (7)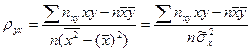 , (8)
, (8)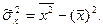 Введем понятие выборочного коэффициента корреляции
Введем понятие выборочного коэффициента корреляции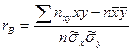
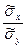 :
:  , откуда
, откуда 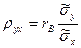 . Используя это соотношение, получим выборочное уравнение прямой линии регрессии Y на Х вида
. Используя это соотношение, получим выборочное уравнение прямой линии регрессии Y на Х вида . (9)
. (9) и
и 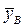 и выборочные средние квадратические отклонения σ х и σ у, то по этим данным можно вычислить выборочный коэффициент корреляции
и выборочные средние квадратические отклонения σ х и σ у, то по этим данным можно вычислить выборочный коэффициент корреляции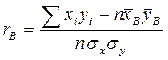

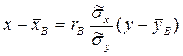 .
.

 Для определения выборочного коэффициента корреляции вычислим предварительно
Для определения выборочного коэффициента корреляции вычислим предварительно  Тогда
Тогда Выборочное уравнение прямой линии регрессии Y на Х имеет вид:
Выборочное уравнение прямой линии регрессии Y на Х имеет вид: 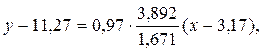 или
или 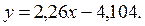 ◄
◄ 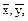 среднеквадратические отклонения sΧ , sΥ , коэффициент корреляции ρ Χ Υ и уравнение линейной регрессии Y на X. Вычислить условные средние
среднеквадратические отклонения sΧ , sΥ , коэффициент корреляции ρ Χ Υ и уравнение линейной регрессии Y на X. Вычислить условные средние  по дан-ным таблицы и найти наибольшее их отклонение от значений, вычисляемых из уравнения регрессии.
по дан-ным таблицы и найти наибольшее их отклонение от значений, вычисляемых из уравнения регрессии.

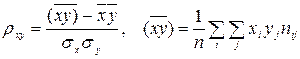

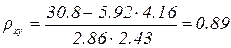
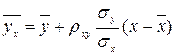
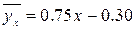
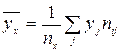
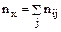 - число выборочных значений yj , наблюдавшихся при данном xi . Согласно данным из таблицы находим
- число выборочных значений yj , наблюдавшихся при данном xi . Согласно данным из таблицы находим
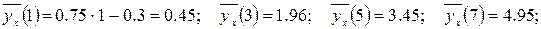
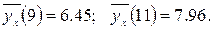

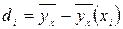
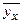 и
и  Вычисляем
Вычисляем 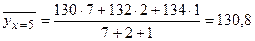 .
.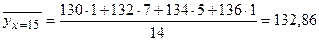 .
. и
и 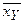 .Получим таблицы, выражающие корреляционную зависимость Y от X (табл.2) и X от Y (табл.3).
.Получим таблицы, выражающие корреляционную зависимость Y от X (табл.2) и X от Y (табл.3).
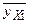 ), соединив их отрезками, получим эмпирическую линию регрессии Y на X. Аналогично строятся точки В j(
), соединив их отрезками, получим эмпирическую линию регрессии Y на X. Аналогично строятся точки В j( 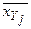 , yj) и эмпирическая линия регрессии X на Y (см. рис.).
, yj) и эмпирическая линия регрессии X на Y (см. рис.).
 также увеличивается, поэтому можно выдвинуть гипотезу о прямой линейной корреляционной зависимости между количеством работающих и объёмом складских реализаций.
также увеличивается, поэтому можно выдвинуть гипотезу о прямой линейной корреляционной зависимости между количеством работающих и объёмом складских реализаций.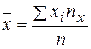 ,
,  ,
, 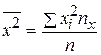 ,
,  ,
, 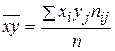 ,
,