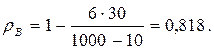|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Свойства выборочного коэффициента корреляции Спирмена.
1. Если между А и В имеется «полная прямая зависимость», то есть ранги совпадают при всех i, то ρ В = 1. Действительно, при этом di = 0, и из формулы (21.4) следует справедливость свойства 1. 2. Если между А и В имеется «противоположная зависимость», то ρ В = - 1. В этом случае, преобразуя di = (2i – 1) – n, найдем, что 3.В остальных случаях -1 < ρ B < 1, причем зависимость между А и В тем меньше, чем ближе | ρ B | к нулю. Можно использовать и другой коэффициент – коэффициент ранговой корреляции Кендалла. Рассмотрим ряд рангов у1, у2, …, уп, введенный так же, как и ранее, и зададим величины Ri следующим образом: пусть правее у1 имеется R1 рангов, больших у1; правее у2 – R2 рангов, больших у2 и т.д. Тогда, если обозначить R =R1 + R2 +…+ Rn-1, то выборочный коэффициент ранговой корреляции Кендалла определяется формулой
где п – объем выборки. Замечание. Легко убедиться, что коэффициент Кендалла обладает теми же свойствами, что и коэффициент Спирмена.
Пример 2. Десять школьников сдавали выпускной экзамен ЕГЭ по математике и вступительный экзамен по системе централизованного тестирования. Результаты обоих экзаменов оценивались по 100-балльной шкале и оказались следующими (1-я строка – оценки ЕГЭ, вторая – централизованного тестирования): 87 82 80 79 63 55 40 34 33 29 57 92 80 69 71 43 49 51 20 19 Найти выборочные коэффициенты корреляции Спирмена и Кендалла. Составим последовательности рангов по убыванию баллов на каждом экзамене: xi 1 2 3 4 5 6 7 8 9 10 yi 5 1 2 4 3 8 7 6 9 10. Вычислим di: d1 = 1 – 5 = -4; d2 = 2 – 1 = 1; d3 = 3 – 2 = 1; d4 = 4 – 4 = 0; d5 = 5 – 3 = 2; d6 = 6 – 8 = -2; d7 = 7 – 7 = 0; d8 = 8 – 6 = 2; d9 = d10 = 0. Найдем Приступим к вычислению коэффициента корреляции Кендалла. Определим, сколько рангов, больших данного, располагается справа от каждого yi: R1 = 5; R2 = 8; R3 = 7; R4 = 5; R5 = 5; R6 = 2; R7 = 2; R8 = 2; R9 = 1; R10 = 0; R = 5 + 8 + 7 + 5 + 5 + 2 + 2 + 2 + 1 = 37; Заметим, что величины выборочных коэффициентов корреляции позволяют предполагать существование связи между результатами экзаменов. Для проверки этого предположения следует проверить гипотезу о значимости соответствующего выборочного коэффициента ранговой корреляции. ◄
Вопросы для самопроверки
1. В чем состоит различие между функциональной и статистической зависимостями между случайными величинами? 2. Опишите форму корреляционной таблицы. 3. Сформулируйте две основные задачи корреляционного анализа. 4. Что такое корреляционный момент, коэффициент корреляции, регрессия? 5. Как получают эмпирическую линию регрессии? 6. Какова форма линии регрессии при линейной корреляционной зависимости? 7. В каком диапазоне могут быть значения коэффициента корреляции? 8. Что следует сказать о двух случайных величинах, если коэффициент корреляции равен нулю или же равен единице? 9. Как ставится задача определения параметров линии регрессии методом наименьших квадратов?
СТАТИСТИЧЕСКАЯ ПРОВЕРКА ГИПОТЕЗ Основные понятия. В исследованиях часто возникает необходимость знать закон распределения изучаемого признака генеральной совокупности. С этой целью производят наблюдения и получают опытное (или эмпирическое) распределение случайной величины в виде вариационного ряда. Поставленная задача сводится к оценке закона распределения признака в генеральной совокупности на основе выборочных данных. Распределение признака в выборке называется эмпирическим распределением. Распределение признака в генеральной совокупности называется теоретическим распределением. Статистической гипотезой называют гипотезу о виде неизвестного распределения генеральной совокупности или о параметрах известных распределений. Нулевой (основной) называют выдвинутую гипотезу Н0. Конкурирующей (альтернативной)называют гипотезу Н1, которая противоречит нулевой. Пример. Пусть Н0 заключается в том, что математическое ожидание генеральной совокупности а = 3. Тогда возможные варианты Н1: а) а ≠ 3; б) а > 3; в) а < 3. ◄ Простой называют гипотезу, содержащую только одно предположение, сложной – гипотезу, состоящую из конечного или бесконечного числа простых гипотез. Пример. Для показательного распределения гипотеза Н0: λ = 2 – простая, Н0: λ > 2 – сложная, состоящая из бесконечного числа простых ( вида λ = с, где с – любое число, большее 2). ◄ В результате проверки правильности выдвинутой нулевой гипотезы ( такая проверка называется статистической, так как производится с применением методов математической статистики) возможны ошибки двух видов: ошибка первого рода, состоящая в том, что будет отвергнута правильная нулевая гипотеза, и ошибка второго рода, заключающаяся в том, что будет принята неверная гипотеза. Замечание. Какая из ошибок является на практике более опасной, зависит от конкретной задачи. Например, если проверяется правильность выбора метода лечения больного, то ошибка первого рода означает отказ от правильной методики, что может замедлить лечение, а ошибка второго рода (применение неправильной методики) чревата ухудшением состояния больного и является более опасной. Вероятность ошибки первого рода называется уровнем значимости α. Основной прием проверки статистических гипотез заключается в том, что по имеющейся выборке вычисляется значение некоторой случайной величины, имеющей известный закон распределения. Статистическим критерием называется случайная величина К с известным законом распределения, служащая для проверки нулевой гипотезы. Критической областью называют область значений критерия, при которых нулевую гипотезу отвергают, областью принятия гипотезы – область значений критерия, при которых гипотезу принимают. Итак, процесс проверки гипотезы состоит из следующих этапов: 1) выбирается статистический критерий К; 2) вычисляется его наблюдаемое значение Кнабл по имеющейся выборке; 3) поскольку закон распределения К известен, определяется (по известному уровню значимости α ) критическое значениеkкр, разделяющее критическую область и область принятия гипотезы (например, если р(К > kкр) = α, то справа от kкр располагается критическая область, а слева – область принятия гипотезы); 4) если вычисленное значение Кнабл попадает в область принятия гипотезы, то нулевая гипотеза принимается, если в критическую область – нулевая гипотеза отвергается. Различают разные виды критических областей: - правостороннююкритическую область, определяемую неравенством K > kкр ( kкр > 0); - левостороннюю критическую область, определяемую неравенством K < kкр ( kкр < 0); - двустороннюю критическую область, определяемую неравенствами K < k1, K > k2 (k2 > k1). Мощностью критерия называют вероятность попадания критерия в критическую область при условии, что верна конкурирующая гипотеза. Если обозначить вероятность ошибки второго рода (принятия неправильной нулевой гипотезы) β, то мощность критерия равна 1 – β. Следовательно, чем больше мощность критерия, тем меньше вероятность совершить ошибку второго рода. Поэтому после выбора уровня значимости следует строить критическую область так, чтобы мощность критерия была максимальной.
■ ▬ ▬ ► |
Последнее изменение этой страницы: 2017-05-11; Просмотров: 636; Нарушение авторского права страницы
 , тогда
, тогда 
 (6)
(6) Тогда выборочный коэффициент ранговой корреляции Спирмена
Тогда выборочный коэффициент ранговой корреляции Спирмена