
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Доверительные интервалы для оценки среднего квадратического
отклонения нормального распределения. Будем искать для среднего квадратического отклонения нормально распределенной случайной величины доверительный интервал вида (s – δ, s +δ ), где s – исправленное выборочное среднее квадратическое отклонение, а для δ выполняется условие: p ( |σ – s| < δ ) = γ. Запишем это неравенство в виде:
Рассмотрим случайную величину χ, определяемую по формуле
которая распределена по закону «хи-квадрат» с п-1 степенями свободы. Плотность ее распределения
не зависит от оцениваемого параметра σ, а зависит только от объема выборки п. Преобразуем неравенство (4) так, чтобы оно приняло вид χ 1 < χ < χ 2. Вероятность выполнения этого неравенства равна доверительной вероятности γ, следовательно,
или, после умножения на Замечание. Если q > 1, то с учетом условия σ > 0 доверительный интервал для σ будет иметь границы
Итак, для оценки генерального среднего квадратического отклонения σ при заданной надежности γ можно построить доверительный интервал вида
где s – исправленное выборочное среднее квадратическое отклонение, а q = q (n, γ ) – значение, определяемое из таблиц. Пример. Пусть п = 20, s = 1, 3. Найдем доверительный интервал для σ при заданной надежности γ = 0, 95. Из соответствующей таблицы находим q (n = 20, γ = 0, 95 ) = 0, 37. Следовательно, границы доверительного интервала: 1, 3(1-0, 37) = 0, 819 и 1, 3(1+0, 37) = 1, 781. Итак, 0, 819 < σ < 1, 781 с вероятностью 0, 95. ◄ Пример. Дана выборка значений нормально распределенной случайной величины: 2, 3, 3, 4, 2, 5, 5, 5, 6, 3, 6, 3, 4, 4, 4, 6, 5, 7, 3, 5. Найти с доверительной вероятностью γ = 0, 95 границы доверительных интервалов для математического ожидания и дисперсии. Объем выборки п = 20. Найдем
доверительный интервал для математического ожидания;
доверительный интервал для дисперсии. ◄
Вопросы для самопроверки
1. В чем сущность задачи по определению параметров генеральной совокупности? В чем особенности этой задачи? 2. Как вычисляется средняя арифметическая выборки при малом и больших объемах ее? 3. Как вычисляется дисперсия выборки в случаях малого и большого объема ее? 4. Какая величина принимается за среднюю генеральной совокупности, а какая — за дисперсию? 5 Что понимается под доверительным интервалом и доверительной вероятностью? 6. Как вычисляется среднее квадратическое отклонение средней выборки? 7. Назовите выборочные числовые характеристики. 8. Что такое статистики и для чего они служат? 9. Какими свойствами должны обладать оценки? 10. Какова вероятность попадания генеральной средней в интервал размером ±2(+3) средних квадратических отклонений средней выборки при нормальном распределении. 11. Что называется доверительным интервалом и доверительной вероятностью? Дайте общую схему построения доверительного интервала. 12. Как изменяется доверительный интервал с увеличением надежности? С увеличением объема выборки? 13. Как изменяется доверительный интервал в зависимости от того, известны ли другие параметры точно или нет? 14. Если доверительная вероятность будет увеличена, то как изменится доверительный интервал при других равных условиях. 15. Что надо сделать с объемом выборки, чтобы уменьшить доверительный интервал при том же значении доверительной вероятности?
ЭЛЕМЕНТЫ ТЕОРИИ КОРРЕЛЯЦИИ Расчеты коэффициентов корреляции, регрессии достаточно трудоемки. Это объясняется тем, что приходится обрабатывать большое количество исходных данных; ведь одно наблюдение дает сразу две величины. Однако нужно иметь в виду, что если объем выборки невелик, то расчеты этих коэффициентов несложны. При малых выборках общую корреляционную таблицу не составляют, а результат наблюдений оставляют в том виде, каким он получается непосредственно в опыте, т. е. в виде так называемой простой корреляционной таблицы. В такой таблице каждому номеру наблюдений соответствует пара наблюдавшихся значений случайных величин. Конечно, вычисленный по малому числу наблюдений коэффициент в целом имеет меньшую надежность. В тех случаях, когда известен общий вид зависимости между средней одной величины и значениями другой, параметры этой зависимости могут быть найдены методом наименьших квадратов. Линейная корреляция Рассмотрим выборку двумерной случайной величины (Х, Y). Примем в качестве оценок условных математических ожиданий компонент их условные средние значения, а именно: условным средним M (Y / x) = f (x), M ( X / y ) = φ (y). Условные средние - выборочное уравнение регрессии Y на Х, - выборочное уравнение регрессии Х на Y. Соответственно функции f*(x) и φ *(у) называются выборочной регрессией Y на Х и Х на Y, а их графики – выборочными линиями регрессии. Выясним, как определять параметры выборочных уравнений регрессии, если этих уравнений известен. Пусть изучается двумерная случайная величина (Х, Y), и получена выборка из п пар чисел (х1, у1), (х2, у2), …, (хп, уп). Будем искать параметры прямой линии среднеквадратической регрессии Y на Х вида Y = ρ yxx + b, (3) Подбирая параметры ρ ух и b так, чтобы точки на плоскости с координатами (х1, у1), (х2, у2), …, (хп, уп) лежали как можно ближе к прямой (3). Используем для этого метод наименьших квадратов и найдем минимум функции
Приравняем нулю соответствующие частные производные:
В результате получим систему двух линейных уравнений относительно ρ и b:
Ее решение позволяет найти искомые параметры в виде:
При этом предполагалось, что все значения Х и Y наблюдались по одному разу. Теперь рассмотрим случай, когда имеется достаточно большая выборка (не менее 50 значений), и данные сгруппированы в виде корреляционной таблицы:
Здесь nij – число появлений в выборке пары чисел (xi, yj). Поскольку
Можно решить эту систему и найти параметры ρ ух и b, определяющие выборочное уравнение прямой линии регрессии:
Но чаще уравнение регрессии записывают в ином виде, вводя выборочный коэффициент корреляции. Выразим b из второго уравнения системы (7):
Подставим это выражение в уравнение регрессии:
где
и умножим равенство (8) на
Коэффициент корреляции – безразмерная величина, которая служит для оценки степени линейной зависимости между Х и Y: эта связь тем сильнее, чем ближе |r| к единице. Для качественной оценки тесноты корреляционной связи между X и Y можно воспользоваться таблицей Чеддока (табл.1): Таблица 1
Итак, если для выборки двумерной случайной величины (X, Y): {(xi, yi), i = 1, 2,..., n} вычислены выборочные средние
и получить линейные уравнения, описывающие связь между Х и Y, которые называются выборочным уравнением прямой линии регрессии Y на Х:
и выборочным уравнением прямой линии регрессии Х на Y :
Пример. Для выборки двумерной случайной величины
вычислить выборочные средние, выборочные средние квадратические отклонения, выборочный коэффициент корреляции и составить выборочное уравнение прямой линии регрессии Y на Х.
Пример. По заданной корреляционной таблице найти выборочные средние
Вычислим выборочные средние и среднеквадратические отклонения для X, Y
Выборочный коэффициент корреляции между Х и У отыскивается по формуле
Согласно таблице откуда
Выборочное линейное уравнение регрессии У на Х имеет вид
или, с учётом вычисленных значений,
Условное среднее при x = xi вычисляется по формуле
где
Значения условных средних
Отклонения значений,
будут d1 = 0-0.45=-0.45; d2 = 2.6- 1.96 = 0.65; d3 = -0.51, d4 = 0.55; d5 = -0.05; d6 = 0.05. Наибольшее по абсолютной величине отклонение равно 0.65. ◄ Пример. Выборочно обследовано 100 снабженческо-сбытовых предприятий некоторого региона по количеству работников X и объёмам складской реализации Y (д.е.). Результаты представлены в корреляционной таблице;
По данным исследования требуется: 1) в прямоугольной системе координат построить эмпирические ломаные регрессии Y на X и X на Y, сделать предположение в виде корреляционной связи; 2) оценить тесноту линейной корреляционной связи; 3) проверить гипотезу о значимости выборочного коэффициента корреляции, при уровне значимости α =0, 05; 4) составить линейные уравнения регрессии У на X и X на У, построить их графики в одной системе координат; 5) используя полученные уравнения регрессии, оценить ожидаемое среднее значение признака Y при х=40 чел.; дать экономическую интерпретацию полученных результатов. 1. Для построения эмпирических ломаных регрессии вычислим условные средние 2.
то условное среднее При х=15 признак Y имеет распределение
тогда
Аналогично вычисляются все
Таблица 2
Таблица 3
В прямоугольной системе координат построим точки Аi(хi,

Построенные эмпирические ломаные регрессии Y на X и X на Y свидетельствуют о том, что между количеством работающих (X) и объёмом складских реализаций (Y) существует линейная зависимость. Из графика видно, что с увеличением X величина 2. Оценим тесноту связи. Вычислим выборочный коэффициент корреляции, предварительно вычислив характеристики по формулам
Это значение rB говорит о том, что линейная связь между количеством работников и объемом складских реализаций высокая. Этот вывод подтверждает первоначальное предположение, сделанное исходя из графика. 3. Запишем теоретические уравнения линейной регрессии:
Подставляя в эти уравнения найденные величины, получаем искомые уравнения регрессии: 1) уравнение регрессии Y на X:
2) уравнение регрессии X на Y:
Контроль: точка пересечения прямых линий регрессии имеет координаты 4. Найдём среднее значение Y при х=40 чел., используя уравнение регрессии Y на X. Подставим в это уравнение х=40, получим
Ожидаемое в генеральной совокупности среднее значение объёма складских реализаций при заданном количестве работников (х=40) составляет 137, 51 д.е. Замечание 1. Если в корреляционной таблице даны интервальные распределения, то за значения вариант надо брать середины частичных интервалов. Замечание 2. Если данные наблюдений над признаками X и Y заданы в виде корреляционной таблицы с равноотстоящими вариантами, то целесообразно перейти к условным вариантам:
где h1 – шаг, т.е. разность между двумя соседними вариантами xi; С1 – «ложный нуль» вариант xi (в качестве «ложного нуля» удобно принять варианту, которая расположена примерно в середине ряда); h2 – шаг вариант Y; С2 – «ложный нуль» вариант Y. В этом случае выборочный коэффициент корреляции
где
Зная эти величины, находят
Найденные величины подставляем в уравнения (10). Так в данном примере С1 =25, h1=10, С2=136, h2=2; Корреляционная таблица в условных вариантах имеет вид
По этой таблице и приведённым выше формулам находим характеристики:
В результате получаем те же уравнения линейной регрессии:
|
Последнее изменение этой страницы: 2017-05-11; Просмотров: 4408; Нарушение авторского права страницы
 или, обозначив
или, обозначив  ,
,  . (4)
. (4) ,
, 
 Предположим, что q < 1, тогда неравенство (4) можно записать так:
Предположим, что q < 1, тогда неравенство (4) можно записать так:  ,
,  ,
,  . Следовательно,
. Следовательно, 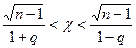 . Тогда
. Тогда 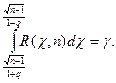 Существуют таблицы для распределения «хи-квадрат», из которых можно найти q по заданным п и γ, не решая этого уравнения. Таким образом, вычислив по выборке значение s и определив по таблице значение q, можно найти доверительный интервал (4), в который значение σ попадает с заданной вероятностью γ.
Существуют таблицы для распределения «хи-квадрат», из которых можно найти q по заданным п и γ, не решая этого уравнения. Таким образом, вычислив по выборке значение s и определив по таблице значение q, можно найти доверительный интервал (4), в который значение σ попадает с заданной вероятностью γ. . (5)
. (5)
 = 4, 25, s = 1, 37. По таблицам ([1], табл. 3 и 4) определим t (0, 95; 20) = 2, 093; q (0, 95; 20) = 0, 37. Тогда
= 4, 25, s = 1, 37. По таблицам ([1], табл. 3 и 4) определим t (0, 95; 20) = 2, 093; q (0, 95; 20) = 0, 37. Тогда

 назовем среднее арифметическое наблюдавшихся значений Y, соответствующих Х = х. Аналогично условное среднее
назовем среднее арифметическое наблюдавшихся значений Y, соответствующих Х = х. Аналогично условное среднее 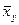 - среднее арифметическое наблюдавшихся значений Х, соответствующих Y = y. Введем уравнения регрессии Y на Х и Х на Y:
- среднее арифметическое наблюдавшихся значений Х, соответствующих Y = y. Введем уравнения регрессии Y на Х и Х на Y: 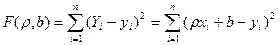 . (4)
. (4) .
. . (5)
. (5) . (6)
. (6)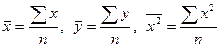 , заменим в системе (5)
, заменим в системе (5) 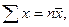
 , где пху – число появлений пары чисел (х, у). Тогда система (5) примет вид:
, где пху – число появлений пары чисел (х, у). Тогда система (5) примет вид: 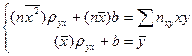 . (7)
. (7)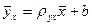 .
.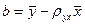 .
.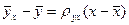 . Из (7)
. Из (7)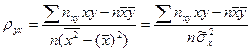 , (8)
, (8)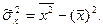 Введем понятие выборочного коэффициента корреляции
Введем понятие выборочного коэффициента корреляции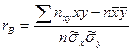
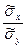 :
:  , откуда
, откуда 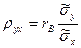 . Используя это соотношение, получим выборочное уравнение прямой линии регрессии Y на Х вида
. Используя это соотношение, получим выборочное уравнение прямой линии регрессии Y на Х вида . (9)
. (9)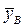 и выборочные средние квадратические отклонения σ х и σ у, то по этим данным можно вычислить выборочный коэффициент корреляции
и выборочные средние квадратические отклонения σ х и σ у, то по этим данным можно вычислить выборочный коэффициент корреляции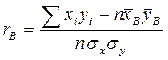

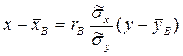 .
.

 Для определения выборочного коэффициента корреляции вычислим предварительно
Для определения выборочного коэффициента корреляции вычислим предварительно  Тогда
Тогда Выборочное уравнение прямой линии регрессии Y на Х имеет вид:
Выборочное уравнение прямой линии регрессии Y на Х имеет вид: 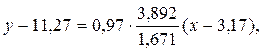 или
или 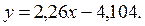 ◄
◄ 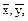 среднеквадратические отклонения sΧ , sΥ , коэффициент корреляции ρ Χ Υ и уравнение линейной регрессии Y на X. Вычислить условные средние
среднеквадратические отклонения sΧ , sΥ , коэффициент корреляции ρ Χ Υ и уравнение линейной регрессии Y на X. Вычислить условные средние  по дан-ным таблицы и найти наибольшее их отклонение от значений, вычисляемых из уравнения регрессии.
по дан-ным таблицы и найти наибольшее их отклонение от значений, вычисляемых из уравнения регрессии.

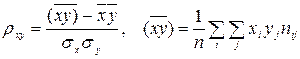

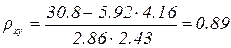
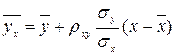
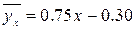
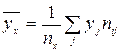
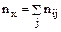 - число выборочных значений yj , наблюдавшихся при данном xi . Согласно данным из таблицы находим
- число выборочных значений yj , наблюдавшихся при данном xi . Согласно данным из таблицы находим
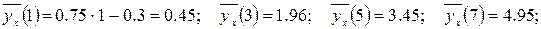
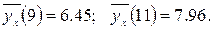

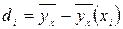
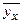 и
и  Вычисляем
Вычисляем 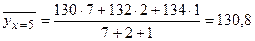 .
.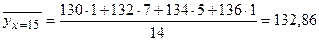 .
. и
и 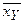 .Получим таблицы, выражающие корреляционную зависимость Y от X (табл.2) и X от Y (табл.3).
.Получим таблицы, выражающие корреляционную зависимость Y от X (табл.2) и X от Y (табл.3).
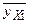 ), соединив их отрезками, получим эмпирическую линию регрессии Y на X. Аналогично строятся точки В j(
), соединив их отрезками, получим эмпирическую линию регрессии Y на X. Аналогично строятся точки В j( 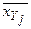 , yj) и эмпирическая линия регрессии X на Y (см. рис.).
, yj) и эмпирическая линия регрессии X на Y (см. рис.).
 также увеличивается, поэтому можно выдвинуть гипотезу о прямой линейной корреляционной зависимости между количеством работающих и объёмом складских реализаций.
также увеличивается, поэтому можно выдвинуть гипотезу о прямой линейной корреляционной зависимости между количеством работающих и объёмом складских реализаций.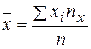 ,
,  ,
, 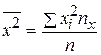 ,
,  ,
, 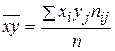 ,
,  ,
,  :
:  ;
;  ;
;  ;
; 
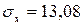 ;
; 

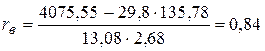 .
. ,
, 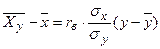 .
. , или
, или  ;
;  , или
, или  .
. Построим графики найденных уравнений регрессии. Зададим координаты двух точек, удовлетворяющих уравнению
Построим графики найденных уравнений регрессии. Зададим координаты двух точек, удовлетворяющих уравнению 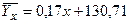 . Пусть х = 10, тогда
. Пусть х = 10, тогда  , А1(10; 132, 41), Если х = 40, тогда
, А1(10; 132, 41), Если х = 40, тогда  , А2(40; 137, 51). Аналогично находим точки, удовлетворяющие уравнению
, А2(40; 137, 51). Аналогично находим точки, удовлетворяющие уравнению  , В1(10, 2; 131), В2(43; 139). Графики прямых линий регрессии изображены ниже на рисунке.
, В1(10, 2; 131), В2(43; 139). Графики прямых линий регрессии изображены ниже на рисунке.
 . В нашем примере: С(29, 8; 135, 78).
. В нашем примере: С(29, 8; 135, 78). .
. ,
,  ,
,  ,
,  ,
,  ,
, 
 ,
, 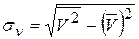 .
.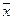 ,
,  , σ х, σ у по формулам
, σ х, σ у по формулам ,
,  ,
,  ,
,  .
. ,
,  .
. ;
;  ;
;  ;
;  ;
; 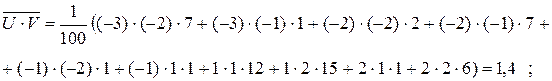
 ;
;  ;
;  ;
;  ;
;  ;
;  ;
;  .
.