|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Забезпечення системи обробки даних
Практично всі системи обробки даних ІС незалежно від сфери їх застосування містять однаковий набір складових (компонентів), що мають назву “види забезпечення”. Прийнято виділяти інформаційне, програмне, технічне, правове та лінгвістичне забезпечення. Хоч ІС, як і будь-яка інша система, може існувати тільки як єдине ціле, для аналізування її доцільно виділити такі її складові, як організаційне, інформаційне, математичне, лінгвістичне, апаратне, програмне та правове забезпечення тощо.
Рис. 2.5. Складові інформаційної технології Сукупність методів та засобів підвищення ефективності управління об’єктами управління на всіх стадіях їх життєвого циклу називається організаційним забезпеченням. Організаційне забезпечення ІС містить організацію якісного функціонування АІС, контроль її роботи згідно з інструкцією користувача, технічну модернізацію, правове забезпечення програм тощо. Організаційне забезпечення складається з 4-х груп компонентів: · методичні матеріали, що регламентують процес створення і функціонування системи та типові проектні рішення; · сукупність засобів ефективного проектування і функціонування ЕІС (комплекси задач керування, уніфіковані системи документів, галузеві класифікатори); · технічна документація, яку одержують в процесі обстеження, проектування і впровадження ІС (технічне завдання, технічний і робочий проекти); · організаційно-штатна структура проекту. Інформаційне забезпечення – це сукупність методів і засобів щодо розміщення й організації інформації, що містять системи класифікації і кодування, уніфіковані системи документації, раціоналізації документообігу і форм документів, методів створення внутрішньомашинної ІС. Інформаційне забезпечення дає можливість інтегрованої обробки всіх видів інформації, що циркулює в організації, вхідної, вихідної, внутрішньої, всіх документів електронного та паперового документообігу. Від якості розробленого інформаційного забезпечення значно залежать достовірність і якість управлінських рішень, що приймаються. Сукупність інформації об'єкта управління утворює його інформаційну базу. Основною функцією інформаційного забезпечення є надійне зберігання на машинних носіях усієї сукупності необхідних даних для вирішення задач користувача і зручний доступ до цих даних. Рішення щодо складу й організації необхідної інформації приймаються в поза- і внутрішньомашинній сферах. Як уже зазначалося, первинна інформація фіксується в документах позамашинної сфери і містить як нормативно-довідкову інформацію, так і облікову, оперативну інформацію, що відображає відомості про поточні процеси. Позамашиинне інформаційне забезпечення – це позамашинна інформаційна база і способи її ведення. Позамашинну інформаційну базу утворюють дані, що містяться в документах, а способи її організації і ведення призначені для забезпечення роботи з нею. Для створення практичної функціональної задачі користувача на комп'ютері і роботи з ним у деякій ПрО дані позамашинної сфери повинні бути перенесені на машинний носій, де вони утворюють внутрішньомашинну інформаційну базу. Внутрішньомашинне інформаційне забезпечення – це інформаційна база на машинному носії та способи її ведення. Варто зазначити, що інформаційна база утворює лише основу інформаційної системи, вона не враховує організацію інформації в реальних умовах та її певне функціонування в об'єкті управління. Враховуючи ці положення, в ІС необхідно чітко розрізняти два поняття: інформаційну базу і базу даних. Інформаційна база є на будь-якому об'єкті управління. Поняття БД пов'язане лише з організацією даних і використанням ЕОМ. Інформаційну базу з позицій структурних підрозділів підприємства (організації) можна поділити на інформаційну базу цеху (відділу), а з позиції функцій управління, – на інформаційну базу планування, обліку тощо. Отже, інформаційна база підприємства розпадається на ряд підсистем (ПрО). Таким чином, якщо мова йде про інформаційну базу підприємства в цілому, тоді підприємство виступає як ПрО. Аналіз інформаційної бази задач бухгалтерського обліку або фінансового стану підприємства дає змогу судити, що тут ПрО – бухгалтерський облік (фінансовий стан) підприємства. Дані в інформаційній базі зберігаються в певній послідовності, а її утворюють масиви. Масив зображає набір даних одної форми з усіма їх значеннями або групи таких наборів даних, що належать до однієї задачі підсистеми. Прикладом масиву може бути сукупність даних з обліку заробітної плати, сукупність даних з обліку надходження матеріальних цінностей на склад підприємства тощо. Масив, у свою чергу, складається з більш дрібних інформаційних одиниць – записів, записи – з полів, поля – з окремих символів. З іншого погляду, інформаційну базу підприємства (організації) можна описати і таким чином: масив – це набір даних первинних документів певної форми стосовно одної задачі; записи – рядки первинних документів з інформацією про документ (номер документа, дата його створення, місце створення); поля – окремі елементи запису. Комп'ютерна технологія обробки даних передбачає обов'язкову процедуру фіксування первинних даних на машинні носії (магнітні диски). З цього моменту користувач звертається до даних як до файлу. Файл − це місце на машинному носії, у якому зберігаються дані й яке має своє унікальне ім 'я. До складу файлу, як і масиву, входять записи, які, у свою чергу, поділяються на поля. Файли даних, об'єднані логічними зв'язками, утворюють БД, яка крім безпосередньо самих даних, містить їх описи спеціальною мовою та описи логічних зв'язків між ними. Для організації даних в ЕОМ розрізняють такі поняття, як логічна і фізична організація даних. Логічна організація даних вказує на те, які дані та в якій послідовності надаються користувачу час вирішення конкретної задачі; фізична – як дані розміщуються на машинному носії. Відмінності ці виявляються, насамперед, на рівні записів і організації їх у файлах. Для формування і ведення БД застосовується спеціальний комплекс програм – СУБД. Цей комплекс програм забезпечує створення логічної структури БД, введення та редагування бази даних, пошук і зберігання даних, доступ до окремих записів, полів тощо. База даних разом із СУБД утворює АБД. Автоматизований банк даних − система організації, ведення і зберігання даних, розташованих на машинних носіях і призначених для колективного багатоцільового використання разом зі спеціальними, технічними, мовними й організаційними засобами. Інформаційне забезпечення комп'ютерних технологій обробки даних повинно базуватися на таких основних принципах, як: підтримка методологічної єдності інформаційної бази, адекватність і повнота відображення виробничо-господарської діяльності підприємства (організації), однократність введення вхідних даних і багаторазовість їх використання, своєчасність поновлення даних та можливість розширення і вдосконалення інформаційної бази, простота і зручність доступу до даних тощо. Створення інформаційного забезпечення супроводжується проведенням складного комплексу робіт щодо впорядкування інформаційної бази, розробки єдиної системи класифікації і кодування даних, уніфікації документації, зміни діючого документообігу, пошуку ефективних cпособів і методів зберігання, накопичення, відновлення, пошуку і видачі даних. Сучасні автори часто використовують терміни “банк даних” і “база даних” як синоніми, але в загальногалузевих провідних матеріалах по створенню банків даних Державного комітету з науки і техніки, виданих в 1982 р., ці поняття розрізняються. Там приводяться наступні визначення банку даних, бази даних і СУБД. Банк даних (Б н Д) – це система спеціальним чином організованих даних – баз даних, програмних, технічних, мовних, організаційно-методичних засобів, призначених для забезпечення централізованого накопичення і колективного багатоцільового використання даних. База даних (БД) – іменована сукупність даних, що відображає стан об'єктів та їх відносин і даної наочної області. Під ПрО розуміють один або декілька об'єктів управління (або певні їх частини), інформація яких моделюється за допомогою БД і використовується для вирішення різних функціональних завдань. Система управління базами даних (СУБД) – сукупність мовних і програмних засобів, призначених для створення, ведення і сумісного використання БД багатьма користувачами. У ній можна виділити: · ядро СУБД, яке забезпечує організацію введення, обробки і зберігання даних; · компоненти, які забезпечують відладку системи, засобу тестування; · утиліти, які забезпечують виконання допоміжних функцій (наприклад, ведення журналу статистики роботи системи і т.ін.). Дуже важливим завданням СУБД є забезпечення незалежності даних. Практично одна і та ж СУБД може бути використана для ведення абсолютно різних файлів, використовуваних для вирішення різнопланових, не пов'язаних між собою завдань управління. Всі функції СУБД можна об'єднати в такі групи: 1. Управління даними. Завданнями управління даними є підготовка даних та їх контроль, внесення даних в базу, структуризація даних, забезпечення цілісності, секретності даних. 2. Доступ до даних. Пошук і селекція даних, перетворення даних у форму, зручну для подальшого використання. 3. Організація і ведення зв'язку з користувачем. Ведення діалогу, видача діагностичних повідомлень про помилки в роботі по БД і т.д. Для обробки запитів до БД розробляють програми, які складають прикладне програмне забезпечення. Програми, за допомогою яких користувачі працюють з БД, називаються додатками. У загальному випадку з однією БД можуть працювати безліч різних додатків. Наприклад, якщо БД моделює деяке підприємство, то для роботи з нею може бути створено додаток, який обслуговує підсистему обліку кадрів; другий додаток може бути присвячений роботі підсистеми розрахунку заробітної платні співробітників; третій додаток працює як підсистема складського обліку; четвертий додаток присвячений плануванню виробничого процесу. При розгляді додатків, що працюють з однією БД, передбачається, що вони можуть працювати паралельно і незалежно один від одного, і саме СУБД покликана забезпечити роботу безлічі додатків з єдиною БД так, щоб кожне з них виконувалося коректно, але враховувало всі зміни в БД, що вносяться іншими додатками. Як будь-який програмно-організаційно-технічний комплекс, БД існує в часі та в просторі. Він має певні стадії свого розвитку: Проектування, Реалізація, Експлуатація, Модернізація, Розвиток, Повна реорганізація. На кожному етапі свого існування з БД пов'язані різні категорії користувачів. Визначимо основні категорії користувачів та їх роль у функціонуванні БД: · Кінцеві користувачі. Це основна категорія користувачів, на користь яких і створюється БнД, Залежно від особливостей створюваного БнД круг його кінцевих користувачів може істотно розрізнятися. Це можуть бути випадкові користувачі, що звертаються до БД час від часу за отриманням деякої інформації, а можуть бути регулярні користувачі. Як випадкові користувачі можуть розглядатися, наприклад, можливі клієнти вашої фірми, що проглядають каталог вашої продукції або послуг з узагальненим або докладним описом того й іншого. Регулярними користувачами можуть бути ваші співробітники, що працюють із спеціально розробленими для них програмами, які забезпечують автоматизацію їх діяльності при виконанні своїх посадових обов'язків. Наприклад, менеджер, плануючий роботу сервісного відділу комп'ютерної фірми, має в своєму розпорядженні програму, яка допомагає йому планувати і розподіляти поточні замовлення, контролювати хід їх виконання, замовляти на складі що необхідні комплектують для нових замовлень. Основний принцип полягає в тому, що від кінцевих користувачів не повинно вимагатися яких-небудь спеціальних знань у сфері обчислювальної техніки і мовних засобів. · Адміністратори банку даних. Це група користувачів, яка на початковій стадії розробки БнД відповідає за його оптимальну організацію з погляду одночасної роботи безлічі кінцевих користувачів, на стадії експлуатації відповідає за коректність роботи даного банку інформації і розрахованому на багато користувачів режимі. На стадії розвитку і реорганізації ця група користувачів відповідає за можливість коректної реорганізації банку без зміни або припинення його поточної експлуатації. · Розробники і адміністратори додатків. Це група користувачів, яка функціонує під час проектування, створення і реорганізації БнД. Адміністратори додатків координують роботу розробників при розробці конкретного додатку або групи додатків, об'єднаних у функціональну підсистему. Розробники конкретних додатків працюють з тією часткою інформації з БД, яка потрібна для конкретного додатку. Не у кожному БД можуть бути виділені всі звані користувачів. Свідомо, що при розробці ІС з використанням настільних СУБД адміністратор БД, адміністратор додатку і розробник часто існували в одній особі. Проте при побудові сучасних складних корпоративних БД, які використовуються для автоматизації всіх або більшої частини процесів бізнесу в крупній фірмі або корпорації, можуть існувати і групи адміністраторів додатків, і відділи розробників. Найбільш складні обов'язки покладені на групу адміністратора БД. У складі групи адміністратора БД повинні бути: системні аналітики; проектувальники структур даних і зовнішнього відносно до БнД інформаційного забезпечення; проектувальники технологічних процесів обробки даних; системні й прикладні програмісти; оператори і фахівці з технічного обслуговування. Якщо йдеться про комерційний БД, то важливу роль тут грають фахівці з маркетингу. Основні функції групи адміністратора БД: 1. Аналіз наочної області: опис наочної області, виявлення обмежень цілісності, визначення статусу (доступності, секретності) інформації, визначення потреб користувачів, визначення відповідності “дані – користувач”, визначення об'ємно-тимчасових характеристик обробки даних. 2. Проектування структури БД: визначення складу і структури файлів БД і зв'язків між ними; вибір методів впорядкування даних і методів доступу до інформації; опис БД мовою опису даних. 3. Завдання обмежень цілісності при описі структури БД і процедур обробки БД: · завдання декларативних обмежень цілісності, властивих наочній області; · визначення динамічних обмежень цілісності, властивих ПрО в процесі зміни інформації, що зберігається в БД; · визначення обмежень цілісності, викликаних структурою БД; · розробка процедур забезпечення цілісності БД при введенні і коригуванні даних; · визначення обмежень цілісності при паралельній роботі користувачів в розрахованому на багато користувачів режимі. 4. Первинне завантаження і ведення БД: · розробка технології первинного завантаження БД, яка відрізнятиметься від процедури модифікації й доповнення даними при штатному використанні БД; · розробка технології перевірки відповідності введених даних реальному стану наочної області. База даних моделює реальні об'єкти деякої наочної області і взаємозв'язку між ними, і на момент початку штатної експлуатації ця модель повинна повністю відповідати стану об'єктів наочної області на даний момент часу; · відповідно до розробленої технології первинного завантаження може знадобитися проектування системи первинного введення даних. 5. Захист даних: · визначення системи паролів; принципів реєстрації користувачів; створення груп користувачів, що володіють однаковими правами доступу до даних; · розробка принципів захисту конкретних даних і об'єктів проектування; · розробка спеціалізованих методів кодування інформації при її циркуляції в локальній і глобальній інформаційних мережах; · розробка засобів фіксації доступу до даних і спроб порушення системи захисту; · тестування системи захисту; · дослідження випадків порушення системи захисту і розвиток динамічних методів захисту інформації в БД.
6. Забезпечення відновлення БД: · розробка організаційних засобів архівації та принципів відновлення БД; · розробка додаткових програмних засобів і технологічних процесів відновлення БД після збоїв. 7. Аналізування звернень користувачів БД: збір статистики за характером запитів, за часом їх виконання, по необхідних вихідних документах. 8. Аналізування ефективності функціонування БД: · аналізування показників функціонування БД; · планування реструктуризації (зміна структури) БД і реорганізації БнД. 9. Робота з кінцевими користувачами: · збирання інформації про зміну ПрО; · збирання інформації про оцінку роботи БД; · навчання користувачів, консультування користувачів; · розробка необхідної методичної й навчальної документації по роботі кінцевих користувачів. 10. Підготовка і підтримка системних засобів: · аналізування існуючих на ринку програмних засобів, можливості та необхідності їх використання в рамках БД; · розробка необхідних організаційних і програмно-технічних заходів щодо розвитку БД; · перевірка працездатності покупних програмних засобів, перед підключенням їх до БД; · підключення нових програмних засобів до БД. 11. Організаційно-методична робота по проектуванню БД: · вибір (створення) методики проектування БД; · визначення цілей і напрямку розвитку системи в цілому; · забезпечення можливості комплексної відладки безлічі додатків, що взаємодіють з однією БД; · підключення нового додатку до діючої БД; · планування етапів розвитку БД; · розробка загальних словників-довідників проекту БД і концептуальної моделі; · стикування зовнішніх моделей розроблюваних додатків. Термінологія в СУБД, та і самі терміни “база даних” і “банк даних” частково запозичені з фінансової діяльності. Це запозичення — не випадково і пояснюється тим, що робота з інформацією і pa6oтa з грошовими масами багато в чому схожі, оскільки і там і там відсутня персоніфікація об'єкта обробки: дві банкноти номіналом в сто гривень однакові й взаємозамінні, як два однакових байти (природно, за винятком серійних номерів). Можна покласти гроші на деякий рахунок і надати можливість родичам або колегам використовувати їх для інших цілей. Ви можете доручити банку оплачувати ваші витрати з вашого рахунку або одержати їх готівкою про інший банк, і це будуть вже інші грошові купюри, але їх цінність буде еквівалентна тій, яку ви мали, коли клали їх на ваш рахунок. В процесі наукових досліджень, присвячених тому, як саме повинна бути влаштована СУБД, пропонувалися різні способи реалізації. Найжиттєздатнішою з них виявилася запропонована Американським комітетом із стандартизації ANSI (American National Standards Institute) трирівнева система організації БД, зображена на рис. 2.6.
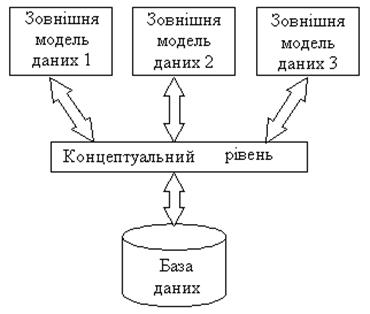
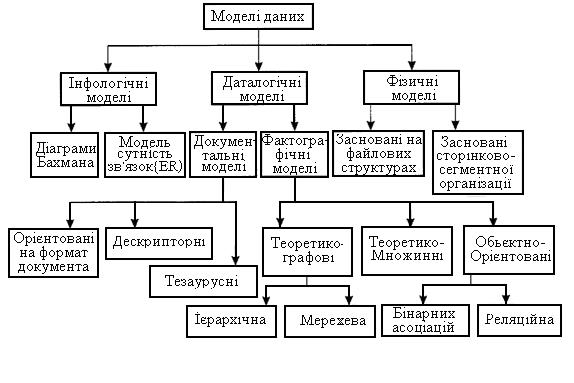
Рис. 2.6. Трирівнева модель системи управління БД, запропонована ANSI 1. Рівень зовнішніх моделей – самий верхній рівень, де кожна модель має своє “бачення” даних. Цей рівень визначає точку зору на БД окремих додатків. Кожен додаток бачить і обробляє тільки дані, необхідні саме цьому додатку. Наприклад, система розподілу робіт використовує відомості про кваліфікацію співробітника, але її не цікавлять відомості про оклад, домашню адресу і телефон співробітника; і навпаки, саме ці відомості використовуються в підсистемі відділу кадрів. 2. Концептуальний рівень – центральна ланка, яка керує; тут БД представлена в найбільш загальному вигляді, який об'єднує дані, використовувані всіма додатками, що працюють з даною БД. Фактично концептуальний рівень відображає узагальнену модель наочної сфери (об'єктів реального світу), для якої створювалася БД. Як і будь-яка модель, концептуальна модель відображає тільки істотні, з погляду обробки, особливості об'єктів реального світу. 3. Фізичний рівень – власне дані, розташовані у файлах або в сторінкових структурах, розташованих на зовнішніх носіях інформації. Ця архітектура дозволяє забезпечити логічну (між рівнями 1 і 2) і фізичну (між рівнями 2 і 3) незалежність при роботі з даними. Логічна незалежність припускає можливість зміни одного додатку без коригування інших додатків, що працюють з цією ж БД. Фізична незалежність припускає можливість перенесення інформації, що зберігається, з одних носіїв на інші при збереженні працездатності всіх додатків, що працюють з даною БД. Це саме те, чого не вистачало при використанні файлових систем. Виділення концептуального рівня дозволило розробити апарат централізованого управління БД. Банки даних (БнД) – це дуже складна система, яку можна класифікувати за цілим спектром ознак, стосовно як банку в цілому, так і окремих його компонентів. За призначенням БнД бувають: · БнД АСУ для організаційно-економічної інформації; · БнД для систем автоматизації наукових досліджень і виробничих випробувань; · БнД для систем автоматизованого проектування; · інформаційно-пошукові; · спеціалізовані по окремих областях науки і техніки. За архітектурою підтримуваного обчислювального середовища БнД бувають централізованими (інтегрованими) і розподіленими. За виглядом інформації, яка зберігається, банки діляться на БнД, банки документів і БЗ. За мовою спілкування користувача з БД розрізняють системи з базовою мовою (відкриті системи) і з власною мовою (закриті системи). У відкритих системах мовним засобом спілкування з БД одна з мов програмування, наприклад C, Pascal. У таких системах для спілкування з БД потрібен посередник, тобто програміст, який володіє вибраною мовою програмування. Закриті системи мають власну мову спілкування. Вона, як правило, набагато простіше, ніж мова програмування. Тому в таких системах не потрібен посередник-програміст для спілкування з БД. Самі користувачі, які мають відповідну підготовку, зможуть працювати з БД. Одними з основоположних в концепції БД є узагальнені категорії “дані” і “модель даних”. Поняття “дані” в концепції БД – це набір конкретних значень, параметрів, що характеризують об'єкт, умову, ситуацію або будь-які інші чинники Приклади даних: Петров Микола Степанович, кредит – $3000, і т.д. Дані не володіють певною структурою; дані стають інформацією тоді, коли користувач задає їм певну структуру, тобто усвідомлює їх смисловий зміст. Тому центральним поняттям в сфері БД є поняття моделі. Не існує однозначного визначення цього терміна, у різних авторів ця абстракція визначається з деякими відмінностями, але, проте, можна виділити щось загальне в цих визначеннях Модель даних – це деяка абстракція, яка, будучи прикладена до конкретних даних, дозволяє користувачам і розробникам трактувати їх вже як інформацію, тобто відомості, що містять не тільки дані, але і взаємозв'язок між ними. Класифікація моделей даних представлена на рис. 2.7.
Рис. 2.7. Класифікація моделей даних Відповідно до розглянутої раніше трирівневої архітектури стикаються з поняттям моделі даних відносно до кожного рівня. І дійсно, фізична модель даних оперує категоріями, стосовно організації зовнішньої пам'яті й структур зберігання, використовуваних в даному операційному середовищі. Зараз як фізичні моделі використовуються різні методи розміщення даних, засновані на файлових структурах: це організація файлів прямого і послідовного доступу; індексних і інвертованих файлів; файлів, що використовують різні методи хешування; взаємозв'язаних файлів. Крім того, сучасні СУБД широко використовують сторінкову організацію даних. Фізичні моделі даних, засновані на сторінковій організації, є найбільш перспективними. Найбільший інтерес викликають моделі даних, використовувані на концептуальному рівні. Відносно до них зовнішні моделі мають назву “підсхеми”, яківикористовують ті ж абстрактні категорії, що і концептуальні моделі даних. Окрім трьох розглянутих рівнів абстракції при проектуванні БД, існує ще один передуючий рівень, який виражає інформацію про наочну область у вигляді, незалежному від використовуваної СУБД. Ці моделі називаються інфологічними, або семантичними, і відображають в природній і зручній для розробників та інших користувачів формі інформаційно-логічний рівень абстрагування, пов'язаний з фіксацією і описом об'єктів наочної області, їх властивостей та їх взаємозв'язків. Інфологічні моделі даних використовуються на ранніх стадіях проектування для опису структур даних в процесі розробки додатку, а даталогічні моделі вже підтримуються конкретною СУБД. Документальні моделі даних відповідають уявленню про слабоструктуровану інформацію, орієнтовану в основному на вільні формати документів, текстів природною мовою. Моделі, засновані на мовах розмітки документів, пов'язані, передусім, із стандартною спільною мовою розмітки − SGML (Standard Generalized Markup Language), яка була затверджена ISO як стандарт ще в 80-х роках. Ця мова призначена для створення інших мов розмітки, вона визначає допустимий набір тегів (посилань), їх атрибути і внутрішню структуру документа. Контроль за правильністю використання тегів здійснюється за допомогою спеціального набору правил, які використовуються програмою клієнта при розборі документа. Для кожного класу документів визначається свій набір правил, що описують граматику відповідної мови розмітки. За допомогою SGML можна описувати структуровані дані, організовувати інформацію, що міститься в документах, представляти цю інформацію в стандартизованому форматі. Але зважаючи на деяку свою складність SGML використовувався в основному для опису синтаксису інших. Набагато більш проста і зручна, ніж SGML, мова HTML дозволяє визначати оформлення елементів документа і має якийсь обмежений набір інструкцій – тегів, за допомогою яких здійснюється процес розмітки. Інструкції HTML в першу чергу призначені для управління процесом виведення вмісту документа на екрані програми-клієнта і визначають тим самим спосіб представлення документа, але не його структуру. Як елемент гіпертекстової БД, що описується HTML, застосовується текстовий файл, який може легко передаватися по мережі з використанням протоколу HTTP. Ця особливість, а також те, що HTML є відкритим стандартом і величезна кількість користувачів має можливість застосовувати можливості цієї мови для оформлення своїх документів, безумовно, вплинули на зростання популярності HTML і зробили його головним механізмом представлення інформації в Internet. Проте HTML на теперішній час вже не задовольняє повною мірою вимогам, що пред'являються сучасними розробниками до мов подібного роду. І їй на зміну була запропонована нова мова гіпертекстової розмітки, могутня, гнучка і, водночас зручна мова XML. У чому ж полягають її достоїнства? XML (Extensible Markup Language) − це мова розмітки, що описує клас об'єктів даних, названих XML-документами, та використовується як засіб опису граматики інших мов і контролю правильності складання документів. Тобто сама по собі XML не містить ніяких тегів, призначених для розмітки, а просто визначає порядок їх створення. Тезаурусні моделі засновані на принципі організації словників, містять певні мовні конструкції й принципи їх взаємодії в заданій граматиці. Ці моделі ефективно застосовуються в системах-перекладачах, особливо багатомовних перекладачах. Принцип зберігання інформації в цих системах і підкоряється тезаурусним моделям. Дескрипторні моделі – найпростіші з документальних моделей, вони широко використовувалися на ранніх стадіях використання документальних БД. У цих моделях кожному документу відповідав дескриптор - описувач. Цей дескриптор мав жорстку структуру і описував документ відповідно до характеристик, потрібних для роботи з документами, розроблювальними в документальній БД. Наприклад, для БД, що містить опис патентів, дескриптор містив назву області, до якої відносився патент, номер патенту, дату видачі патенту і ще ряд ключових параметрів, які заповнювалися для кожного патенту. Обробка інформації в таких БД велася виключно по дескрипторах, тобто по тих параметрах, які характеризували патент, а не по самому тексту патенту. Математичне забезпечення (МЗ) − це сукупність математичних моделей і алгоритмів для вирішення питань обробки інформації з застосуванням вибраної ІТ, а також комплекс засобів і методів, що дозволяють будувати економіко-математичні моделі задач керування. Ступінь розвитку математичного забезпечення значною мірою визначає ефективність використання певної ІТ. У теперішній час спостерігається тенденція до зростання частки витрат на розроблення математичного апарата в загальних витратах на проект ІС. Останнє десятиліття характеризується значним розвитком математичних дисциплін, методи яких використовуються для вирішення задач в ІС. Мережні методи знаходять найширше застосування в проектуванні. Вони дозволяють визначати параметри мережних моделей і аналізувати хід робіт з реалізації виробничих планів. У рамках мережного моделювання можлива одно- чи багатокритеріальна оптимізація, у тому числі за часом і за ресурсами. Евристичні методи дозволяють вирішувати слабоструктуровані задачі, які неможливо вирішити повним перебором варіантів, приміром задачі календарного планування. Сутність евристичного методу в тому, щоб запланувати роботи в найкоротші терміни, але так, щоб не перевищити заданий верхній рівень ресурсів. Як правило, використання евристичних методів передбачає наявність діалогу з користувачем, під час якого на комп’ютер покладаються обчислення і видача проміжних результатів, включаючи різні графіки і діаграми. Користувач залежно від отриманих даних визначає подальший напрямок розрахунків. Методи комбінаторики, математичної логіки, інформаційної алгебри застосовуються для рішення інформаційно-логічних задач. Це групування та впорядкування даних, об'єднання масивів даних і коригування інформації, введення, декомпозиція й обмін даними між електронними сховищами в межах однієї або кількох ЕОМ. Математичне програмування поєднує лінійне, нелінійне, динамічне і стохастичне програмування. З використанням лінійного програмування вирішуються і аналізуються такі питання, як розроблення та складання прогнозів планів розвитку галузей, оптимального розподілу ресурсів. Нелінійне математичне програмування застосовується рідше за лінійне, причому найчастіше нелінійні задачі вирішуються також способами лінійного програмування, для чого криволінійні залежності апроксимуються прямими (лінеаризація). Суть динамічного програмування полягає у тому, що з двох шляхів досягнення результату довший шлях відкидається, щоб зменшити обсяг обчислень на ЕОМ. Стохастичне програмування характеризується введенням у задачі ймовірнісних значень параметрів, що відображають ризик і невизначеність. Методи теорії ігор дозволяють формалізувати та вирішувати задачі, що зазвичай вирішуються емпірично, без використання кількісних вимірників. До таких задач належить, приміром, дослідження конфліктних ситуацій в умовах невизначеності інформації про дії учасників. Методи теорії ігор широко застосовуються при аналізуванні організаційних, економічних, воєнних і політичних ситуацій. Теорія черг або масового обслуговування вивчає ймовірнісні моделі поведінки систем. Базою для вирішення задач масового обслуговування є теорія ймовірностей. Математична статистика, що є одним з розділів теорії ймовірності, дозволяє дати оцінку певній сукупності даних. Метод статистичних іспитів також призначений для вивчення ймовірнісних систем, застосовується при моделюванні найрізноманітніших ситуацій. Цим методом вдається, зокрема, одержати характеристики системи без проведення натурних експериментів. Метод теорії розкладів дозволяє знайти оптимальну послідовність побудови об'єктів за якимось критерієм. Приміром, критерієм може служити “найменший термін будівництва”, “мінімум простоїв виконавців на об'єктах”, “максимальна щільність робіт на об'єктах” тощо. Методи теорії множин дозволяють значно компактніше описувати задачі керування, знаходити ефективні шляхи їхнього рішення. Програмне забезпечення − сукупність програмних засобів для створення й експлуатації системи обробки даних засобами обчислювальної техніки. До складу програмного забезпечення входять базові (загально-системні) і прикладні (спеціальні) програмні продукти. Базові програмні засоби служать для автоматизації взаємодії людини і комп'ютера, організації типових процедур обробки даних, контролю і діагностики функціонування технічних засобів систем обробки даних. Комп’ютерна програма – це алгоритм вирішення певної задачі мовою, зрозумілою комп’ютеру. Програмне забезпечення складається з операційної системи, мов програмування та застосовних програм. Операційна система (ОС) − це комплекс спеціальних програмних засобів, призначених для керування завантаженням, запуском і виконанням прикладних програм, вводом-виводом даних, а також для планування та управління обчислювальними ресурсами комп'ютера. Та частина ОС, що взаємодіє з апаратними засобами безпосередньо і тому постійно зберігається в комп'ютері, має називу ядро ОС. Програмне забезпечення, що входить до складу ядра ОС, відповідає за перевірку працездатності компонентів комп'ютера і виконання елементарних операцій, пов'язаних з роботою дисплея, клавіатури, магнітних накопичувачів і т.п. При вмиканні комп'ютера ОС автоматично завантажується в оперативну пам'ять. Крім ядра, ОС містить сервісні програми: для тестування обладнання, зміни параметрів його функціонування, форматування магнітних дисків тощо. Кожна прикладна програма пов'язана з якою-небудь ОС і може експлуатуватися тільки на тих комп'ютерах, де є відповідна ОС. За кількістю задач, що можуть виконуватися одночасно, ОС поділяють на ті, що виконують одну задачу (MSX), та ті, що здатні виконувати одночасно багато задач (OS/2, UNIX, Windows ), а за кількістю користувачів, що працюють одночасно, − на ОС, що взаємодіють з одним користувачем та ті, що взаємодіють з багатьма користувачами (UNIX, Windows NT, 7,10). Файлова система забезпечує взаємодію програм і фізичних пристроїв вводу-виводу. Її основні функції можна поділити на дві групи: для роботи з файлами (створення, видалення, зміна атрибутів), для роботи з даними, що зберігаються у файлах (читання, запис, пошук тощо). Основний атрибут файлу − його ім'я. Мови програмування – це інструментальні засоби, призначені для створення програмного забезпечення. Програма розробляється зрозумілою людині формалізованою мовою, а потім за допомогою транслятора перетворюється в машинні коди. Існує два типи трансляторів: інтерпретатори, що обробляють команди безпосередньо в процесі виконання програми, та компілятори, що переробляють програму в машинні коди до її виконання. Програми, що інтерпретуються, працюють повільніше за програми, що компілюються. Компілятори зберігають результати обробки в окремих файлах, які можна використовувати на інших комп’ютерах. Прикладне програмне забезпечення – це програми, призначені для вирішення конкретних задач (класів задач) у певній ПрО. Прикладні програми призначені для вирішення конкретних задач, поставлених перед користувачами, як спеціалізованих, так і загальновживаних. Прикладне програмне забезпечення − це сукупність програмних продуктів, призначених для автоматизації рішення функціональних задач ІС. Вони можуть бути розроблені як універсальні засоби (офісні програми, СУБД) і як спеціалізовані, що реалізують функціональні підсистеми (бізнес-процеси) об'єктів (економічних, інженерних, технічнічних тощо). Мовні засоби СУБД необхідні для опису даних, організації спілкування і виконання процедур пошуку і різних перетворень даних. Класифікація мовних засобів БнД, показана на рис. 2.8, розроблена Американським комітетом CODASYL з проектування і створення БД.
Рис. 2.8. Схема класифікації мовних засобів БнД Схема має загальний характер і орієнтована на різні СУБД. Проте не кожна СУБД, яка зараз використовується на практиці та поширена на ринку програмних продуктів, має весь набір вказаних мовних засобів. Мова опису даних (DDL − Data Definition Language) призначений для опису даних на різних рівнях абстракції: зовнішньому, логічному, внутрішньому. Виходячи з пропозицій CODASYL, мови опису даних на логічному (концептуальному) і внутрішньому рівнях незалежні й різні. Проте в більшості промислових СУБД мови не діляться на дві окремі мови опису логічної і фізичної організації даних, а існує єдина мова, яка ще має назву “мова опису схем” та призначена для представлення даних на логічному і фізичному рівнях. Ця мова має свій синтаксис: наприклад, ім'я файлу не повинне перевищувати восьми символів, а ім'я поля − десяти; при цьому кожне ім'я може починатися з букви. Поля календарної дати позначаються символом D (DATA), символьні поля − С (CHARACTER); числові − N (NUMERIC), логічні − L (LOGICAL), приміток − М (MEMO). Опис всіх імен, типів і розмірів полів зберігається в пам'яті разом з даними; ці структури у разі потреби можна переглянути і виправити. Якщо логічний і фізичний рівні видокремлені, то до складу СУБД може входити мова опису зберігання даних. У деяких СУБД використовується ще мова опису підсхем, яка потрібна для опису частини БД, що відображає інформаційні потреби окремого користувача або прикладної програми. Мова опису даних на зовнішньому рівні використовується для опису вимог користувачів і прикладних програм та створення інфологічної моделі БД. Ця мова не має нічого спільного з мовами програмування. Так, мовним засобом, використовуваним для інфологічного моделювання, є звичайна природна мова або його підмножина, а також мова графів і матриць. Мова маніпулювання даними (DML − Data Manipulation Language) використовується для обробки даних, їх перетворень і написання програм. DML може бути базовим або автономним. Базова мова DML – це одна з традиційних мов програмування (BASIC, C++ й ін.). Системи, які використовують базову мову, називають “відкритими”. Використання базових мов як мов опису даних звужує коло, тобто можуть безпосередньо звертатися до БД осіб, оскільки для цього потрібно знати мову програмування. У таких випадках для спрощення спілкування кінцевих користувачів з БД передбачається мова ведення діалогу, який значно простіше для оволодіння, чим мова програмування. Автономна мова DML – це власна мова СУБД, яка дає можливість виконувати різні операції з даними. Системи з власною мовою називають “закритими”. У сучасних СУБД для спрощення процедур пошуку даних в БД передбачена мова запитів. Найбільш поширеними мовами запитів є SQL і QBE. Мова запитів SQL (Structured Query Language − структурована мова запитів) була створена фірмою IBM в рамках роботи над проектом побудови СУБД на початку 70-х років XX ст. Американський національний інститут стандартів (ANSI) поклав цю мову в основу стандарту мов реляційних БД, прийнятого Міжнародною організацією стандартів (ISO). Окрім стандарту SQL, існує комерційний стандарт мови SQL, розроблений Консорціумом виробників БД SQL Access Group. Ця група створила варіант мови, використовуваної більшістю систем і дає можливість їм “розуміти” одна одну. Був розроблений стандартний інтерфейс мови CLI (Common Language Interface) для всіх основних варіантів мови SQL. Цей інтерфейс, формалізований фірмою Microsoft, одержав назву ODBC (Open DataBase Connectivity – відкритий доступ до даних). ODBC – це інтерфейс доступу до даних, які зберігаються під керування у різних СУБД. ODBC має цілий набір драйверів, допомогою яких одна СУБД може працювати з даними інших систем. Архітектура ODBC зображена на рис. 2.9.
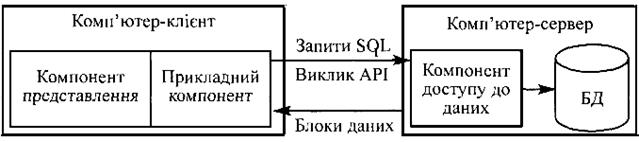
Рис. 2.9. Архітектура ODBC Мова запитів QBE (Query By Example) – це реалізація запитів за зразком у вигляді таблиць. Для визначення запиту до БД користувач повинен заповнити надану системою таблицю QBE і визначити в ній критерії пошуку і вибору даних. Технічне забезпечення − це комплекс технічних засобів, застосовуваних для функціонування системи обробки даних. Цей комплекс містить пристрої, що реалізують типові операції обробки даних як поза ЕОМ (периферійні технічні засоби збору, реєстрації, первинної обробки інформації, оргтехніка різного призначення, засоби телекомунікації та зв'язку), так і на ЕОМ різних класів. Апаратне забезпечення − це технічні засоби, що забезпечують передачу й обробку інформації. Обчислювальна машина − це технічний пристрій, призначений для вводу, зберігання, обробки і виводу інформації. Термін “архітектура ЕОМ” використовується для опису найбільш загальних принципів дії, конфігурації основних логічних вузлів ЕОМ, а також взаємодії між ними. Архітектура обчислювальної системи описує принципи її роботи на функціональному рівні безвідносно до фізичної реалізації. З погляду архітектури становлять інтерес лише найбільш загальні зв'язки і принципи, властиві багатьом конкретним реалізаціям обчислювальних машин. Часто визначають навіть сімейства ЕОМ, тобто групи моделей, сумісних між собою. У межах одного сімейства основні принципи функціонування машин однакові, хоча окремі моделі можуть істотно різнитися за продуктивністю, вартістю та іншими параметрами. Створення архітектури “клієнт-сервер” знаменувало новий етап розвитку мережних ІТ. Це стало можливим завдяки збільшенню ємностей внутрішньої та зовнішньої пам'яті, підвищенню швидкодії ЕОМ, зростанню швидкості передачі даних. Концепція “клієнт-сервер” пов'язана з комп'ютерами спільного користування (серверами), які керують спільними ресурсами, що надають доступ до цих ресурсів як сервісу своїм клієнтам. Обчислювальні мережі, побудовані на основі концепції “клієнт-сервер”, дають змогу: реалізувати кооперативне керування ресурсами; виробити розподіл доступу до даних і процесів їх оброблення між безліччю робочих станцій та сервером; організувати програмне забезпечення на основі концепції відкритих систем. Сервер − одно- або багатопроцесорна персональна чи віртуальна ЕОМ з розподіленою пам'яттю, розподіленим обробленням даних, розподіленими комунікаційними засобами та засобами керування периферійним обладнанням. Як сервер застосовують потужні ЕОМ, що мають великий дисковий простір і швидкодійні процесори. Основна роль сервера полягає в керуванні клієнтами, які спільно користуються ресурсами системи в заданий момент часу: принтерами, БД, зовнішньою пам'яттю, програмами та ін. За функціями розрізняють файл-сервер, обчислювальний сервер, принт-сервер, комунікаційний сервер тощо. Залежно від конфігурації технічних і програмних засобів використовують різні концепції мережного оброблення даних (“файл-сервер”, “клієнт-сервер”). Концепція “файл-сервер” передбачає наявність комп'ютера, виділеного під файловий сервер, в якому знаходяться ядро мережної ОС і файли, які централізовано зберігаються. Для цієї архітектури характерний колективний доступ до спільної БД на файловому сервері. Від конкретного клієнта на сервер надходить запит, оброблення якого зумовлює передачу по мережі всієї інформації запитуваного файлу. Вибір записів, що задовольняють умовам запиту, буде здійснений на самому комп’ютері клієнта засобами СУБД. Це приводить до того, що в момент передачі по мережі інформації файлу доступ до нього інших користувачів блокується. Одночасний доступ багатьох користувачів до інтегрованої БД реалізується в концепції “клієнт-сервер”, згідно з якою серверу належить більш активна роль. Запит на оброблення даних посилається клієнтом по мережі на сервер БД. На сервері здійснюються пошук даних та їх оброблення засобами СУБД. Оброблені дані передаються по мережі від сервера до клієнта. Специфікою архітектури “клієнт-сервер” є використання мови структурованих запитів SQL до БД, що забезпечує роботу зі спільними даними з різнотипних додатків у мережі. Мережний сервер підтримує реалізацію функцій мережної ОС, термінальний − функцій з багатьма користувачами системи. Кожний сервер БД може працювати з певним комп'ютером і мережною ОС. Відносно серверів решта ЕОМ, які запрошують інформацію, є клієнтами. Клієнт − робоча станція, що взаємодіє з користувачем, здатна виконувати потрібні обчислення і забезпечує приєднання до обчислювальних ресурсів та БД засобів їх оброблення, а також засобів організації інтерфейсів. Як ЕОМ клієнта може бути використана будь-яка ЕОМ. Концепція “клієнт-сервер” означає, що кожна технологічна процедура потребує наявності трьох елементів: клієнта, який запрошує інформацію; сервера, що цю інформацію надає; власне мережі. Сервер можна розглядати: як елемент апаратури, який забезпечує спільно використовуваний сервіс у мережному середовищі; як програмний компонент, що надає спільний функціональний сервіс іншим програмним компонентам; як поєднання ЕОМ і програми. Клієнта можна розглядати: як ЕОМ; як додаток, що формує і спрямовує запит до сервера. Він відповідає за оброблення, виведення інформації та передачу запитів серверу. Програма-сервер приймає запит, обробляє його і відправляє результат клієнту. Користувач взаємодіє тільки з програмою-клієнтом. При цьому в концепції “клієнт-сервер” програми клієнта та його запити зберігаються окремо від СУБД. Основна ідея концепції “клієнт-сервер” полягає в тому, щоб сервери розмістити на потужних ЕОМ, а додатки клієнтів − на менш потужних. Завдяки цьому будуть задіяні ресурси більш потужного сервера і менш потужних ЕОМ клієнтів. Введення-виведення до бази ґрунтується не на фізичному дробленні даних, а на логічному, тобто сервер відправляє клієнтам не повну копію бази, а тільки логічно необхідні порції. Завдяки цьому скорочується трафік мережі − потік повідомлень. Сервер обробляє запити клієнтів, вибирає потрібні дані з БД, посилає їх клієнтам по мережі, поновлює інформацію, забезпечує цілісність і зберігання даних. Концепція “клієнт-сервер”, будучи більш потужною, замінила концепцію “файл-сервер”. Вона дозволила поєднати позитивні якості систем з одним користувачем (високий рівень діалогової підтримки, дружній інтерфейс, низька ціна) з перевагами великих комп'ютерних систем (підтримка цілісності, захист даних, багатозадачність). Завдяки архітектурі “клієнт-сервер” реалізується механізм доступу великої кількості користувачів до інформації на сервері. З другого боку, вплив концепції “клієнт-сервер” проявився у тому, що вона вперше реалізувала адаптивну обчислювальну машину (ОМ) з можливістю нарощування її ресурсів. Ця ОМ здатна плавно адаптувати свою потужність до кількості користувачів, які працюють у ній. Конфігурація ОМ, забезпечуючи вимоги користувачів, не перевантажується і не вичерпується. При цьому сервери, що додаються, розташовуються ближче до користувача. Моделі архітектури “клієнт-сервер” існують у двох варіантах: дворівнева (RDA – і DBS – моделі) і трирівнева (AS-модель). Модель доступу до віддалених даних (RDA − Remote Data Access). RDA-модель істотно відрізняється як від систем із централізованою архітектурою (мейнфреймів). Доступ до інформації підтримується або операторами спеціальної мови (наприклад SQL), або викликами функцій спеціальної бібліотеки. У цьому разі використовується відповідний інтерфейс прикладного програмування (АРІ − Аррlication Program Interface) (рис. 2.10), який дає змогу абстрагуватися від обладнання і низькорівневих протоколів.
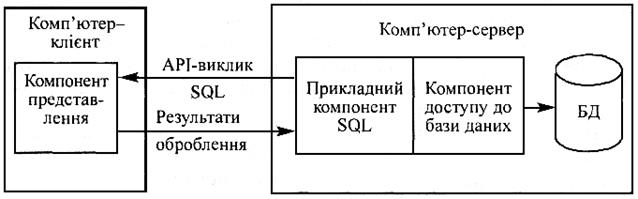
Рис. 2.10. Модель доступу до віддалених даних (RDA) Клієнт посилає запити по мережі до віддаленого сервера для отримання відповідної інформації. На сервері функціонує ядро СУБД, яке обробляє запити, виконуючи прописані в запиті дії, і повертає клієнтові результат, оформлений як блок даних. При цьому ініціатором маніпулювання з даними є прикладна програма, виконана на комп'ютері клієнта. Ядру СУБД відводиться роль обслуговування запитів та їх опрацювання. Виконання компонента представлення і прикладного компонента на комп'ютері клієнта, на відміну від централізованої архітектури, істотно розвантажує сервер БД, мінімізуючи загальну кількість процесів в ОС сервера. Сервер БД звільняється від не властивих йому функцій і цілковито завантажується операціями оброблення даних, запитів і транзакцій. Це стає можливим завдяки відмові від терміналів і оснащенню робочих місць ПК, які володіють власними локальними обчислювальними ресурсами, що цілковито використовуються програмами переднього плану. Основна перевага RDA-моделі − це уніфікація інтерфейсу “клієнт-сервер” з допомогою мови SQL. Взаємодія прикладного компонента з ядром СУБД неможлива без стандартного засобу спілкування. Запити, що їх посилає прикладна програма до ядра СУБД, мають бути зрозумілі обом сторонам (прикладній програмі та ядру СУБД). Для цього їх потрібно сформулювати спеціальною мовою. Такою мовою може бути SQL, яка вже існує в ядрі СУБД і яку доцільно використовувати не лише як засіб доступу до даних, а і як засіб стандарту спілкування клієнта й сервера. Крім позитивних сторін, RDA-модель має низку недоліків. По-перше, взаємодія клієнта й сервера за допомогою SQL-запитів істотно завантажує мережу. Тільки-но кількість клієнтів зростає, мережа перетворюється на “вузьке горло”, гальмуючи швидкість роботи всієї ІС. По-друге, поєднання в одній програмі різних за своєю природою функцій (функцій представлення і прикладних), виконаних на комп'ютері клієнта, не дозволяє ефективно проводити централізоване адміністрування додатків у RDA-моделі. Модель сервера бази даних. Поряд з RDA-моделлю дедалі популярнішою стає перспективна DBS-модель наведена на рис. 2.11. Її основою є механізм процедур, що зберігаються на сервері, своєрідний засіб програмування SQL-сервера. Процедури зберігаються в словнику БД і можуть розподілятися між кількома клієнтами та виконуватися на тому комп'ютері, де функціонує SQL-сервер. Мова, якою розробляються процедури, що зберігаються, являє собою процедуру розширення мови запитів SQL і є унікальною для кожної конкретної СУБД. Рис. 2.11. Модель сервера бази даних (DBS) У DBS-моделі компонент представлення (інтерфейс) функціонує на комп'ютері клієнта, у той час як прикладний компонент, оформлений як набір процедур, що зберігаються, функціонує на сервері БД. Там само знаходиться компонент доступу до даних, тобто ядро СУБД. Окрім переваг, притаманних RDA-моделі, DBS-модель має низку додаткових переваг: · можливість централізованого адміністрування прикладних функцій за рахунок перенесення їх на сервер; · додаткове зниження завантаження локальної мережі завдяки тому, що по мережі передаються не SQL-запити, а виклики процедур, які зберігаються на сервері; · можливість розподілу процедур між кількома додатками, що дає змогу організувати завдання підтримки цілісності даних незалежно від прикладних програм, що використовують ці дані; · економія ресурсів комп'ютера завдяки використанню створеного плану виконання процедури. DBS-модель найпоширеніша у відомих реляційних СУБД, таких як Огасle, Іnformix, Sybase т.ін. Недоліки DBS-моделі такі: по-перше, додаткові витрати коштів, необхідних для написання процедур, що зберігаються на сервері; по-друге, використання різноманітних процедурних розширень мови доволі вузькоорієнтованої SQL для написання збережених процедур не можна навіть порівняти з мовами третього покоління, такими як С, С++, Рascal: SQL значно поступається їхнім образотворчим і функціональним можливостям; їх вбудовано в конкретні СУБД і сфера їх використання обмежена цими СУБД. У більшості з них немає можливостей налагодження і тестування розроблених процедур; по-третє, DBS-модель не забезпечує необхідної ефективності використання обчислювальних ресурсів через обмеження в ядрі СУБД, які не дозволяють змоги організувати в його межах ефективний баланс завантаження, міграцію процедур на інші сервери БД та реалізувати інші корисні функції; по-четверте, децентралізація додатків у сучасних корпоративних інформаційних системах потребує істотної різноманітності варіантів взаємодії клієнта й сервера. Під час реалізації прикладної системи можуть знадобитися такі механізми взаємодії, як збереження черги, асинхронні виклики і т.п., що в DBS-моделі не підтримуються. Модель прикладного сервера (А S – Арр lication Server). Ця модель набула популярності в середині 90-х років минулого століття. У ній реалізовано трирівневу систему розподілу функцій (рис. 2.12).
Рис. 2.12. Модель прикладного сервера (АS) Перший рівень − це комп'ютер, на якому розміщені користувацький інтерфейс (графічний і об'єктно-орієнтований), функції локального редагування, логіка для перевірки даних, а також система взаємодії з мережею. Тобто на комп'ютері виконуються функції першої групи, які відповідають за інтерфейс з користувачем. Звертаючись до прикладного компонента, розміщеного на окремому сервері, комп'ютер першого рівня виконує роль клієнта додатка (прикладного клієнта). Другий рівень − це прикладний сервер, який є відмітною ознакою трирівневої архітектури “клієнт-сервер”. Основне його призначення − зберігання і виконання бізнес-правил. Він релізований як група процедур, що виконують прикладні функції, і мають назву “прикладний сервер”. Третій рівень − це сервер БД. Він забезпечує зберігання й підтримку даних, включаючи їх узгоджене перетворення, побігання несанкціонованому або некоректному коригуванню і створення резервних копій тощо, тобто осмислення інформації, що зберігається в БД. Лінгвістичне забезпечення − це сукупність мовних засобів, використовуваних на різних стадіях створення й експлуатації системи обробки даних для підвищення ефективності розробки і забезпечення спілкування людини та ЕОМ. Організаційне забезпечення ІС. Людський чинник (персонал) відіграє велику роль у забезпеченні ефективного функціонування ІС. Саме цим зумовлено виділення організаційних компонентів у самостійний напрям. Упровадження нової ІТ передбачає, як правило, упорядкування і вдосконалення організаційної структури об'єкта. Головна проблема при цьому полягає у виявленні ступеня відповідності існуючим функціям управління й організаційній структурі, що реалізує ці функції й стратегію розвитку фірми, підприємства. Під організаційними компонентами ІС розуміється сукупність методів і засобів, що дозволяють удосконалювати організаційну структуру об'єктів, управлінські функції, виконувані структурними підрозділами; визначати штатний розпис і чисельний склад кожного структурного підрозділу; розробляти посадові інструкції персоналу управління в умовах функціонування СОД. Впровадження нових ІС сприяє вдосконаленню організаційних структур, оскільки передбачає визначення науково обґрунтованої чисельності апарату управління за структурними підрозділами, обумовлення чітких службових обов'язків кожного працівника, визначення нормального завантаження працівника протягом дня і на календарний період, розробку посадових інструкцій персоналу в умовах функціонування СОД, зокрема в умовах аварійних ситуацій. Правове забезпечення. Виникнення самого терміна “інтелектуальна власність” припадає на кінець XVIII ст. Він уперше з’явився у французькому законодавстві. Авторське та патентне права виникли у Франції на ґрунті теорії природного права, яке одержало свій найбільш послідовний розвиток саме в працях французьких філософів-просвітителів (Вольтер, Дідро, Руссо). Право власності на інформацію − це врегульовані законом суспільні відносини щодо володіння, користування і розпорядження інформації. Інформація є об'єктом права власності громадян, організацій (юридичних осіб) і держави. Інформація може бути об'єктом права власності як у повному обсязі, так і об'єктом лише володіння, користування чи розпорядження. Власник інформації щодо об'єктів своєї власності має право здійснювати будь-які законні дії. Право інтелектуальної власності – це право володіння, користування і розпорядження результатами інтелектуальної діяльності. Інформаційна продукція та інформаційні послуги громадян та юридичних осіб, які займаються інформаційною діяльністю, можуть бути об'єктами товарних відносин, що регулюються чинним цивільним та іншим законодавством. Ціни і ціноутворення на інформаційну продукцію та інформаційні послуги встановлюються договорами, за винятком випадків, передбачених чинним законодавством. Діяльність програмістів та інших фахівців, що працюють у сфері ІС, усе частіше виступає як об'єкт правового регулювання. Деякі дії при цьому можуть бути кваліфіковані як правопорушення (злочини). Правова свідомість у цілому, а в ІТ особливо, у нашому суспільстві, перебуває на досить низькому рівні. Головне призначення правового регулювання в галузі ІТ − юридичне визначення понять, пов'язаних з авторством і поширенням комп'ютерних програм і БД, а також установлення прав, що виникають при створенні програм і БД − авторських, майнових, на передачу, захист, реєстрацію, недоторканість. Правове забезпечення ІС – це сукупність правових норм, що реалізують створення та функціонування ІС. Правове забезпечення функціонування ІС містить умови надання юридичної сили документам, отриманим з використанням обчислювальної техніки, права, обов’язки персоналу, правила користування інформацією, порядок вирішення конфліктів з приводу її достовірності. Для сучасного стану правового регулювання сфери, пов'язаної з інформатикою, в Україні на теперішній час актуальними є питання, пов'язані з порушенням авторських прав та використанням неліцензованої продукції ІТ. Велика частина ПЗ, що використовується окремими програмістами, користувачами і організаціями, придбана в результаті незаконного копіювання, розкрадання. Зараз назріла потреба узаконення способів боротьби з цією практикою, оскільки вона заважає, насамперед, розвитку індустрії ІТ. Правове регулювання в галузі ІТ базується на Конституції України, Законах України “Про інформацію”, “Про захист інформації в автоматизованих системах” тощо. Порушення цих законів призводить до дисциплінарної, цивільно-правової, адміністративної або кримінальної відповідальності згідно із чинним законодавством України. Національне законодавство про охорону права інтелектуальної власності має чинність тільки в межах тієї держави, яка його прийняла. За межами держави правова охорона результатам інтелектуальної діяльності не надається. Це призводить до можливості використання інформації без дозволу її власника чи володільця. Для вирішення цієї проблеми вже з кінця минулого століття починають укладатися різноманітні міжнародні угоди, якими передбачається охорона прав на результати творчої діяльності. Хоч такі угоди не завжди досягали поставленої мети, проте дозволили визначити напрямки, в яких варто їх розвивати та удосконалювати. Так склалася міжнародна система охорони інтелектуальної власності. На теперішній час найбільш авторитетною організацієюз охорони авторських прав є Всесвітня організація інтелектуальної власності (ВОІВ), яка фактично була заснована ще в 1883 − 1886 рр. внаслідок прийняття Паризької конвенції про охорону промислової власності і Бернської конвенції про охорону літературних і художніх творів. У липні 1967 р. в Стокгольмі була підписана Конвенція щодо утворення Всесвітньої організації інтелектуальної власності, яка набула чинності в 1970 р. У грудні 1974 р. ВОІВ набула статусу спеціалізованої установи Організації Об'єднаних Націй. Сприяючи охороні інтелектуальної власності в усьому світі, ВОІВ заохочує укладання нових міжнародних договорів і сприяє удосконаленню національних законодавств. У сфері адміністративного співробітництва ВОІВ централізує адміністративне управління союзами в Міжнародному бюро в Женеві, яке є секретаріатом ВОІВ, а також здійснює контроль такого управління через свої органи. ВОІВ несе відповідальність за розвиток інтелектуальної діяльності і сприяє передачі технологій стосовно промислової власності країнам, що розвиваються, з метою прискорення їх економічного, соціального і культурного розвитку. При виконанні своїх функцій ВОІВ керується завданнями міжнародного співробітництва з метою розвитку повною мірою використовуючи досягнення інтелектуальної діяльності, сприяє більш широкому використанню інтелектуальної власності для заохочення національної творчої діяльності. Основними компонентами ІТ є організаційне, інформаційне, математичне, апаратне, програмне та правове забезпечення. Інформаційна продукція та інформаційні послуги громадян та юридичних осіб, які займаються інформаційною діяльністю, можуть бути об'єктами товарних відносин, що регулюються чинним цивільним та іншим законодавством. 2.6. CASE - технології − інструментарій підтримки життєвого циклу сучасних інформаційних систем На теперішній час використання САSЕ-технологій охоплює не лише автоматизацію розроблення програмного забезпечення, а й поширюється на процеси створення складних ІС в цілому. САSЕ (Computer-Aided Software / System Engineering) являє собою сукупність методологій аналізування, проектування, розробки і супроводження складних програмних систем, підтриманну комплексом взаємопов’язаних засобів автоматизації. САSЕ − це інструментарій для системних аналітиків, розробників і програмістів, що замінює їм папір і олівець комп’ютером для автоматизації процесу проектування і розробки програмного забезпечення. Основна мета САSЕ полягає в тому, щоб видокремити початкові етапи (аналізування і проектування) від подальших етапів розробки, а також не обтяжувати розробників усіма деталями середовища розробки і функціонування системи. Чим більший обсяг робіт буде винесений на етапи аналізування й проектування, тим краще. Під час використання САSЕ трансформуються всі етапи життєвого циклу ІС, при цьому найбільші зміни стосуються етапів аналізування і проектування. Крім автоматизації методологій і, як наслідок, можливості застосування сучасних методів системної й програмної інженерії, САSЕ мають такі основні переваги: 1) поліпшують якість створюваної системи за допомогою засобів автоматичного контролю (передусім, контролю проекту); 2) дозволяють за короткий час створювати прототип майбутньої системи, що дає змогу на ранніх етапах оцінити очікуваний результат; 3) прискорюють процес проектування і розробки; 4) звільняють розробника від рутинної роботи, дозволяючи йому цілком зосередитися на творчій частині розробки; 5) підтримують розвиток і супровід розробки; 6) підтримують технології повторного використання компонентів розробки. Сучасні САSЕ-засоби характеризуються такими властивостями: · автоматична кодогенерація, призначена для одержання виконуваних машинних кодів із специфікацій ПЗ; · використання комп'ютерного сховища, або репозитарію, − БД САSЕ, в якій зберігається вся проектна інформація; · гнучкість, яка забезпечує здатність до адаптації у разі зміни вимог і цілей проекту; · застосування базових програмних засобів різного призначення (БД і СУБД, компілятори, налагоджувачі, документатори, текстові редактори, оболонки експертних систем і БЗ, мови четвертого покоління та ін.); · застосування потужної графіки для представлення та документування систем ПЗ, а також для покращання інтерфейсу з користувачем; · інтеграція інформації та інструментальних засобів, що дозволяє керувати всім процесом проектування та розроблення ПЗ, використовуючи засоби планування проекту; · обмеження складності з метою одержання керованих компонентів системи з простою структурою і доступних для огляду та розуміння. Зараз існує два покоління САSЕ. Засоби першого покоління призначені для аналізування вимог, проектування специфікацій і структури системи і є першою технологією, адресованою безпосередньо системним аналітикам і проектувальникам. Вони включають засоби для підтримки графічних моделей, проектування специфікацій, редагування словників даних і концентрують увагу на початкових кроках проекту − системному аналізуванні, визначенні вимог, системному проектуванні, логічному проектуванні БД. Засоби другого покоління призначені для підтримки повного життєвого циклу розробки. В них, насамперед, використовуються засоби підтримки автоматичної кодогенерації, а також забезпечується повна функціональна підтримка для створення графічних системних вимог і специфікацій проектування; контролю, аналізування і зв’язування системної інформації, а також інформації щодо управління проектуванням; побудови прототипів і моделей системи; тестування, верифікації і аналізування згенерованих програм; генерації документів з проекту; контролю на відповідність стандартам по всіх етапах життєвого циклу (ЖЦ). Стисла характеристика основних функціональних можливостей САSЕ-засобів: · Автоматична кодогенерація. Кодогенерація здійснюється на основі репозитарію і дозволяє автоматично побудувати близько 80-90% об’єктних кодів або текстів програм мовами високого рівня. При цьому різними САSЕ-пакетами підтримуються практично всі відомі мови програмування. · Верифікація проекту. САSЕ забезпечує автоматичну верифікацію і контроль проекту на повноту і спроможність на ранніх етапах розробки, що впливає на успіх розробки в цілому. · Генерація документації. Вся документація з проекту генерується автоматично на базі репозитарію (як правило, на базі вимог відповідних стандартів). Безперечна перевага САSЕ полягає в тому, що документація завжди відповідає поточному стану справ, оскільки будь-які зміни в проекті автоматично відбиваються в репозитарії. Відомо, що за традиційних підходів до розробки АІСУП документація щонайбільше запізнюється, а ряд модифікацій взагалі не знаходить у ній відображення. · Загальна БД проекту. Основа САSЕ – це використання БД-проекту (репозитарію) для зберігання всієї інформації про проект, яка може розподілятися між розробниками відповідно до їхніх прав доступу. Зміст репозитарію включає не тільки об’єкти різних типів, але і відносини між їх компонентами, а також правила використання або опрацювання цих компонентів. Репозитарій може зберігати понад 100 типів об’єктів, прикладами яких є діаграми, визначення екранів і меню, проекти звітів, описи даних, логіка опрацювання, моделі даних, моделі підприємства, моделі опрацювання, початкові коди, елементи даних і т. ін. · Інтеграція засобів. На основі репозитарію здійснюються інтеграція САSЕ-засобів і розподіл системної інформації між розробниками. При цьому можливості репозитарію забезпечують кілька рівнів інтеграції: загальний інтерфейс користувача по всіх засобах, передачу даних між засобами, інтеграцію етапів розробки через єдину систему подань фаз ЖЦ, передачу даних і засобів між апаратними платформами. · Підтримка колективної розробки й управління проектом. САSЕ підтримує групову роботу над проектом за допомогою засобів роботи в мережі, експорту-імпорту будь-яких фрагментів проекту для розвитку і/або модифікації, а також планування, контролю, управління, взаємодії, тобто функцій, необхідних для розробки і супроводження проектів. Ці функції також реалізуються на основі репозитарію. Зокрема, через репозитарій може здійснюватися контроль безпеки (обмеження доступу, привілеї доступу), контроль версій, контроль змін тощо. · Прототипування. Важливу роль в автоматизації ранніх етапів ЖЦ відіграють можливості підтримки прототипування. САSЕ дозволяє будувати швидкі прототипи системи, що дає змогу на ранніх етапах розробки оцінити, наскільки майбутня система влаштовує замовника і наскільки “дружня” вона майбутньому користувачеві. · Спільна графічна мова. САSЕ забезпечує всіх учасників проекту (в тому числі й замовників) спільною мовою, наочною, строгою та інтуїтивно зрозумілою. Це дозволяє залучати замовника до процесу розробки, спілкуватися з експертами ПрО, захищати проект перед керівництвом, поділяти діяльність системних аналітиків, проектувальників і програмістів, а також забезпечувати легкість супроводження і внесення змін у цільову систему. Графічна орієнтація САSЕ полягає в тому, що програми є двовимірними схемами, набагато простішими у використанні, аніж описи на кілька сторінок. · Супроводження і реінжиніринг. Супроводження системи в межах САSЕ характеризується тим, що супроводжується проект, а не програмні коди. Засоби реінжинірингу і реверсного інжинірингу дозволяють продукувати схеми системи з її кодів та інтегрувати отримання схеми в проект, автоматично оновлювати документацію під час заміни кодів, автоматично змінювати специфікації при редагуванні кодів і т. ін. Сховища даних Інформація є ключовим корпоративним ресурсом. Технологія сховищ даних дає змогу одержати точну інформацію, постійний доступ до якої є перевагою цієї технології. Якщо мережа є нервовою системою корпорації, то БД − її пам'ять. БД − водночас інструментальні засоби й інформація, з якою ці засоби працюють. Якщо клієнти, сервери, мережі, великі універсальні ЕОМ купуються корпорацією як компоненти, то БД − як технологія. БД, процеси та додатки проектуються в корпорації для здобуття повної системи “клієнт-сервер”. В корпоративних системах обробки даних інформація поділяється між різними БД (операційними й аналітичним) залежно від часу. Фундаментальна відмінність у філософії природи реального часу транзакційних систем і природи часу СППР привела до поділу БД на операційні й аналітичні, порівняльні характеристики яких наведено в табл. 2.3. Таблиця 2.3 |
Последнее изменение этой страницы: 2019-04-11; Просмотров: 1047; Нарушение авторского права страницы