|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Порівняльні характеристики БД
Бази аналітичних даних реалізуються у вигляді інформаційних сховищ. Вони зберігають дані для ефективної роботи в СППР та ІТ, дають змогу вирішувати такі основні проблеми: аналізування поточної діяльності фірми (наприклад з метою її подальшої реорганізації); прогнозування та відхилення від прогнозу (наприклад ефект від проведення рекламної кампанії); виявлення закономірностей групування клієнтів і визначення стереотипів поведінки кожної групи. Концепція сховищ даних обговорювалась спеціалістами в галузі ІС достатньо давно. Перші статті, присвячені саме сховищам даних, з’явилися в 1992 р. Білл Інмон описав дану концепцію у своїй монографії “Побудова сховищ даних” (Building the Data Warehouse). Необхідність розробки нової концепції сховищ даних обумовлена такими факторами: · для вирішення оперативних аналітичних задач недостатньо інформації, що зберігається в БД. Необхідні архівні дані, що містять результати роботи за попередні календарні періоди. Крім того, дуже часто виникає потреба в зовнішніх джерелах (дані про клієнтів, конкурентів, політичні, соціологічні, демографічні та ін.); · дуже часто на підприємстві (організації) функціонує кілька ОLТР-систем, кожна з яких має свою окрему БД. У них використовуються різні структури даних, способи кодування, одиниці вимірювання. Побудова зведеного аналітичного запиту на основі кількох БД є дуже складною проблемою, яка спочатку потребує вирішення проблеми узгодженості даних, що зберігаються в різних БД; · реалізація аналітичних звітів на основі традиційних БД, які містять оперативну інформацію, займає дуже багато часу. Це пов'язано з тим, що для аналітичних звітів переважно потрібні не первинні оперативні дані, а певним чином узагальнені, тобто агреговані, дані. Причому затрати часу, необхідні на формування аналітичних звітів, невпинно зростають по мірі зростання обсягів оперативної інформації в БД. Це призводить до затримок при реалізації аналітичних запитів; · СППР, що ґрунтуються на формуванні аналітичних запитів, почали конфліктувати з транзакційними системами оперативної обробки даних (ОLТР-системами). Одночасне вирішення оперативних та аналітичних запитів на одній БД часто призводить до нестачі ресурсів. Основні відмінності транзакційних систем від аналітичних, що створили передумови для розробки концепції сховищ даних. Перелічені вище фактори створили передумови для розробки різновиду БД, що дістала назву “сховища даних”. Сховище даних (СД) – це інтегрований накопичувач даних, які збираються з різних систем та джерел і використовуються для бізнес-аналізу та прийняття обґрунтованих стратегічних рішень. Взаємозв'язок баз даних зі сховищами даних наведено на рис. 2.13.
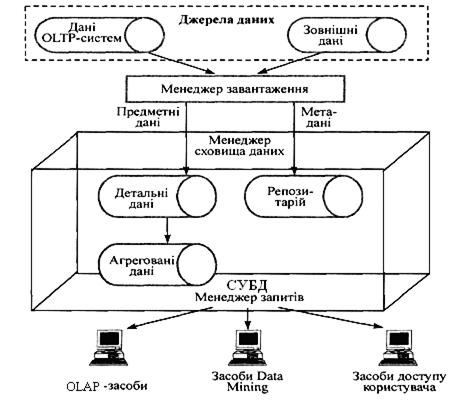
Рис. 2.13. Взаємозв'язок баз даних і сховищ даних Перш ніж завантажити дані в сховище, необхідно виконувати функції попереднього їх відбору, конвертації та очистки. Сховище даних (Data Warehouse) − це предметно-орієнтована, інтегрована, прив'язана до часу та незмінна сукупність даних, призначена для підтримки прийняття рішень. Сховища даних характеризуються предметною орієнтацією, інтегрованістю, підтримкою хронології, незмінністю і мінімальною надлишковістю. Ці основні особливості СД були визначені Біллом Інмоном. Вони незалежно від реалізації властиві всім СД і полягають у такому: Предметна орієнтація. Дані в СД організовані відповідно до основних напрямків діяльності підприємства чи фірми (замовники, продажі, склад і т. п.). Це − відмінність СД від організації оперативної БД, в якій дані організуються відповідно до процесів (відвантаження товару, виписка рахунків і т. п.). Предметна організація даних не лише спрощує проведення аналізу, але й значно прискорює виконання аналітичних розрахунків. Тобто сховища орієнтовані на бізнес-поняття, а не на бізнес-процеси. Інтегрованість. Дані у сховище надходять з різних джерел, де вони можуть мати різні імена, формати, одиниці вимірювання, іспособи кодування. Перш ніж завантажити дані до сховища, вони перевіряються, певним чином відбираються, приводяться до єдиного способу кодування, виду та формату і в необхідній мірі агрегуються (тобто обраховуються сумарні показники). З цього моменту вони представляються користувачеві у вигляді єдиного інформаційного простору, які набагато простіше аналізувати. Якщо, наприклад, у чотирьох різних БД код товару кодувався чотирма різними способами, то в СД буде використана єдина система кодування. Підтримка хронології. Дані в СД зберігаються у вигляді “історичних пластів”, кожен з яких характеризує певний календарний період. Це дозволяє проводити аналіз зміни показників у часі. В ОLТР-системах істинність даних гарантована тільки в момент читання, оскільки вже в наступну мить вони можуть змінитися внаслідок чергової транзакції. Важливою відмінністю сховищ від ОLТР-систем є те, що дані в них зберігають свою істинність у будь-який момент процесу читання. В ОLТР-системах інформація часто модифікується як результат виконання яких-небудь транзакцій. Часова інваріантність даних у СД досягається за рахунок введення полів, що характеризують час (день, тиждень, місяць) у ключі таблиць. У СД містяться начебто моментальні знімки даних. Кожний елемент у своєму ключі явно або непрямо зберігає часовий параметр, наприклад день, місяць, рік. Незмінність. Дані СД, що характеризують кожен “сторичний пласт”, не можуть змінюватись. Це теж є суттєвою відмінністю даних, що зберігаються у СД, від оперативних даних. Останні дані в БД постійно змінюються. З даними СД можливі лише операції їх первинного завантаження, пошуку та читання. Якщо при створенні ОLТР-систем розробники повинні враховувати такі моменти, як відкоти транзакцій після збою сервера, боротьба із взаємним блокуванням процесів, збереження цілісності даних, то для СД ці проблеми не так актуальні. Перед розробниками стоять інші задачі, пов'язані, наприклад, із забезпеченням високої швидкості доступу до даних. Мінімальна надлишковість. Незважаючи на те, що інформація до СД завантажується з БД ОLТР-систем, це не призводить до надлишковості даних. Мінімум надлишковості даних забезпечується тим, що перш ніж завантажувати дані до сховищ, вони фільтруються і певним чином очищаються від тих даних, які не потрібні та не можуть бути використаними в бізнес-аналізі. Існують різні підходи до викладення структури СД, серед яких виділяють змістовні, що відповідають наборам даних, та управлінські, що виконують спеціальні функції управління (рис. 2.14).
Рис. 2.14. Компоненти сховища даних Менеджер завантаження виконує функції диспетчеризації щодо введення нових даних до СД згідно зі встановленим порядком. Оскільки джерелом даних можуть бути різні, функції менеджера завантаження також полягають в очищенні, конвертації та приведенні даних до заданого виду їх представлення в СД. Менеджер сховища виконує операції аналізування та управління даними, а саме: аналіз узгодженості та несуперечності даних; перетворення та переміщення даних з тимчасового сховища в основні таблиці СД; створення індексів; денормалізація даних у разі її необхідності; агрегація (узагальнення) даних; резервне копіювання та архівування даних. Детальні (оперативні) дані містять усі дані визначені схемою СД, а саме: первинні дані найнижчого рівня деталізації та узагальнені до певного рівня деталізації. Агреговані дані містять дані, попередньо оброблені менеджером сховища з метою їх часткового чи глибокого узагальнення та зберігаються певним чином відсортовані та згруповані дані, необхідні для виконання запитів. Ця частина сховища є тимчасовою і змінною, оскільки вона постійно модифікується у відповідь на зміни запитів. Необхідність цієї компоненти пов'язана з підвищенням продуктивності виконання запитів. Узагальнені дані поновлюються по мірі надходження нових даних до системи. Частково узагальнені дані – це результат певного узагальнення та агрегації детальних даних. Глибоко узагальнені дані отримуються на основі узагальнення частково узагальнених даних. Репозитарій метаданих – це інформація про дані, що зберігаються в СД. Структура метаданих може відрізнятися залежно від їх призначення. Метадані використовуються для таких основних цілей: Вибірка і завантаження даних. Метадані містять інформацію про джерела даних, способи та періодичність їх вибірки і завантаження в СД. Обслуговування сховища. Метадані використовуються для автоматизації процедур узагальнення даних. Обслуговування запитів. Метадані використовуються для визначення переліку таблиць з метою виконання запитів. Менеджер запитів виконує операції, пов'язані з управлінням запитами користувачів. Ця компонента реалізується, як правило, на базі СУБД, що підтримує СД, а також СД і програм власної розробки. Користувачі спілкуються і працюють зі сховищем за допомогою спеціальних засобів. До них можуть бути віднесені ОLАР-інструменти (On-Line Analytical Processing); засоби, що підтримують технологію Data Mining, та різні засоби доступу кінцевого користувача: створення звітів і запитів та ін. Розрізняють такі види СД: корпоративні і кіоски, або вітрини, даних. Корпоративні сховища даних (enterprise data werehouses) вміщують інтегровану інформацію, зібрану з певної безлічі оперативних БД, яка характеризує всю корпорацію і необхідна для виконання консолідованого аналізування діяльності корпорації в цілому. Такі сховища охоплюють усі численні напрямки діяльності корпорації та використовуються для прийняття як тактичних, так і стратегічних рішень. Розробка корпоративного СД дуже трудомісткий процес, який може тривати від одного до кількох років, а місткість сховища може досягати від 50 Гбайт до кількох терабайт. Кіоски, або вітрини (data marts) – це певна підмножина корпоративних даних, які характеризують конкретний аспект діяльності корпорації, наприклад роботу конкретного підрозділу. Кіоск може вміщувати як агреговані, так і первинні дані певної ПрО. Кіоск може отримувати дані з корпоративного СД (залежний кіоск) чи бути незалежним, і тоді джерелом поповнення його даними будуть оперативні БД. Розробка кіоску даних потребує значно менше часу і в середньому займає приблизно три – чотири місяці. Самостійно вітрини даних часто з’являються в організації історично і зустрічаються у великих організаціях з численністю незалежних підрозділів, які вирішують власні аналітичні задачі. Перевагами такого підходу є: · багаторазове зберігання даних у різних вітринах даних, що призводить до збільшення витрат на їх зберігання і до потенційних проблем, пов’язаних з необхідністю підтримки незаперечливих даних; · відсутність консолідованості даних на рівні ПрО, а відповідно − відсутність єдиної картини. Недоліками автономних вітрин даних є: · проектування вітрин даних для відповіді на певне коло питань; · спрощення процедур заповнення вітрин даних і підвищення їх потужності за рахунок обліку потреб певного кола користувачів; · швидке впровадження автономних вітрин даних і отримання віддачі. Корпоративні СД і кіоски будуються за подібними принципами і використовують практично одинакові технології. Останнім часом з'явилось поняття глобального сховища даних, в якому СД розглядається як єдине джерело інтегрованих даних для всіх вітрин даних. Моделі сховищ даних та їх особливості Багатовимірна модель СД MOLAP (Multidimensional OLAP) представляє собою багатовимірний куб даних, у комірках якого зберігаються показники, які аналізуються, а вимірювання характеризують якість ознаки цих показників. До елементів багатовимірної моделі (рис. 2.15) належать: 1) показник, або міра − це поле, значення якого однозначно визначаються фіксованими набором вимірів, що характеризують певний факт;
Рис. 2.15. Представлення даних у вигляді багатовимірного куба 2) показники, або міра, складають, як правило, основний вміст СД і можуть бути представленими: · числовими характеристиками факту чи події, що відбувалися на об'єкті управління, для якого створюється сховище (наприклад, обсяги чи дохід від продажів); · формулами, що, як правило, являють собою прості функції агрегування показників (змінних) для отримання узагальнених даних (наприклад, сума, яка консолідує значення змінної за кілька календарних періодів в одне підсумкове значення). Вимір − це послідовність значень одного з аналізованих параметрів. Наприклад, для параметра “час” – це послідовність календарних днів; для параметра “регіон” – це може бути список міст. Колективні виміри – це виміри, які можуть використовуватись одночасно в декількох кубах. Колективними вимірами можуть бути якісь ознаки, які застосовуються при бізнес-аналізі різних ПрО. Приватні виміри – це виміри, які належать конкретному кубу і створюються разом з ним. Інакше кажучи, це специфічні ознаки, що характеризують лише певну конкретну ПрО. Сукупність вимірів визначають параметри простору, в якому можна буде виконувати бізнес-аналіз. Таким чином, багатовимірну модель даних можна представити як гіперкуб. Гіперкубічна модель – це модель, показники якої визначаються однаковими наборами вимірювань. Над гіперкубом можна виконувати наступні операції: Зріз ( Slice ) − формування підмножини багатовимірного масиву даних, відповідаючому єдиному значенню одного або декількох елементів виміру, які не входять в цю підмножину. Наприклад, при виборі елементу “Факт” виміру “Сценарій” зріз даних представляє собою підкуб, у який входять всі решта вимірів (рис. 2.16).
Рис. 2.16. Операція зрізу даних Обертання (Rotate) − зміна розташування вимірювань, представлених в звіті або на відображуваній сторінці. Наприклад, операція обертання може полягати в перестановці місцями рядків і стовпців таблиці або переміщенні вимірювань, що цікавлять, в стовпці або рядки створюваного звіту, що дозволяє задавати йому бажаний вигляд. Крім того, обертанням куба даних є переміщення нетабличнх вимірювань на місце вимірювань, представлених на відображуваній сторінці і навпаки. Як приклад першого випадку може служити звіт, для якого елементи вимірювання “Час” розташовуються впоперек екрану (є заголовками стовпців таблиці), а елементи вимірювання “Продукція” − вздовж екрану (заголовки рядків таблиці).
Рис. 2.17. Операція обертання Консолідація (Drill Up) і деталізація (Drill Down) (рис. 2.18) − операції, які визначають перехід вгору по напрямку від детального (down) представлення даних до агрегованого (up), і навпаки відповідно. Напрямок деталізації (узагальнення) може бути заданий як за ієрархією окремих вимірювань, так і згідно з іншими відношеннями, встановленими в рамках вимірювань або між вимірюваннями. Наприклад, якщо при аналізуванні даних про обсяги продажів в Північній Америці виконати операцію Drill Down для вимірювання “Регіон”, то на екрані будуть відображені такі його елементи, як “Канада”, “Східні Штати Америки” і “Західні Штати Америки”. В результаті подальшої деталізації елементу “Канада” будуть відображені елементи “Торонто”, “Ванкувер”, “Монреаль” і т.д.
Рис. 2.18. Операції консолідації і деталізації Реляційна модель сховища даних (ROLAP) передбачає зберігання і детальних, і агрегованих даних у реляційних БД, але агреговані дані розміщуються у спеціально створених службових таблицях. ROLAP-сервери використовують реляційні БД. На думку Кодда, “реляційні БД були, є і будуть самою відповідною технологією для зберігання даних. Необхідність існує не в новій технології БД, а швидше в засобах аналізу, доповнюючих функції існуючих СУБД і достатньо гнучких, щоб передбачити і автоматизувати різні види інтелектуального аналізу, властиві OLAP”. У даний час поширено дві основні схеми реалізації багатовимірного представлення даних за допомогою реляційних таблиць: схема “зірка” (рис. 2.19) і схема “сніжинка” (рис. 2.20).
Рис. 2.19. Приклад схеми “зірка”
Рис. 2.20. Приклад схеми “сніжинка”
Основними складовими схеми “зірка” (Star Schema) є денормалізована таблиця фактів (Fact Table) і безліч таблиць вимірювань (Dimension Tables). Таблиця фактів, як правило, містить відомості про об'єкти або події, сукупність яких надалі аналізуватиметься. Звичайно визначають чотири типи фактів, що найчастіше зустрічаються, тобто факти пов’язані з: транзакціями (Transaction facts). Вони засновані на окремих подіях (типовими прикладами яких є телефонний дзвінок або зняття грошей з рахунку за допомогою банкомату); “моментальними знімками” (Snapshot facts). Вони засновані на стані об'єкту (наприклад, банківського рахунку) в певні моменти часу (наприклад, на кінець дня або місяця). Типовими прикладами таких фактів є обсяг продажів за день або денна виручка; елементами документа (Line-item facts). Вони засновані на тому або іншому документі (наприклад, рахунку за товар або послуги) і містять докладну інформацію про елементи цього документа (наприклад, про кількість, ціну, відсоток знижки); подіями або станом об'єкта (Event or state facts). Вони представляють виникнення події без подробиць про неї (наприклад, просто факт продажу або факт відсутності такої без інших подробиць). Таблиця фактів, як правило, містить унікальний складовий ключ, об'єднуючий первинні ключі таблиць вимірювань. При цьому як ключові, так і деякі не ключові поля повинні відповідати вимірюванням гіперкуба. Крім того, таблиця фактів містить одне або декілька числових полів, на підставі яких надалі будуть одержані агреговані дані. Таблиці вимірювань містять незмінні або рідко змінні дані. Здебільшого цими даними є по одному запису для кожного члена нижнього рівня ієрархії у вимірюванні. Таблиці вимірювань також містять, як мінімум, одне описове поле (звично з ім'ям члена вимірювання) і, як правило, цілочисельне ключове поле (звичайно це сурогатний ключ) для однозначної ідентифікації члена вимірювання. Якщо вимірювання відповідає таблиці, містить ієрархію, то така таблиця також може містити поля, вказуючі на “батька” даного члена в цій ієрархії. Кожна таблиця вимірювань повинна знаходитися у відношенні “один до багатьох” з таблицею фактів. Швидкість зростання таблиць вимірювань повинна бути незначної в порівнянні з швидкістю росту таблиці фактів. Наприклад, новий запис в таблицю вимірювань, що характеризує товари, додається тільки при появі нового товару, що не продавався раніше. У складних задачах з ієрархічними вимірюваннями має сенс звернутися до розширеної схеми “сніжинка” (Snowfiake Schema). В цих випадках окремі таблиці фактів створюються для можливих поєднань рівнів узагальнення різних вимірювань. Це дозволяє добитися кращої продуктивності, але часто призводить до надмірності даних і значних ускладнень в структурі БД, в якій опиняється величезна кількість таблиць фактів. Збільшення числа таблиць фактів в БД визначається не тільки множинністю рівнів різних вимірювань, але і тією обставиною, що в загальному випадку факти мають різну множину вимірювань. При абстрагуванні від окремих вимірювань користувач повинен одержувати проекцію максимально повного гіперкуба, причому далеко не завжди значення показників в ній повинні бути результатом елементарного підсумовування. Таким чином, при великому числі незалежних вимірювань необхідно підтримувати множину таблиць фактів, відповідних кожному можливому поєднанню вибраних в запиті вимірювань, що також призводить до неекономного використовування зовнішньої пам'яті, збільшення часу завантаження даних в БД схеми “зірка” із зовнішніх джерел і складнощів адміністрування. Використовування реляційних БД в OLAP-системах має наступні переваги: здебільшого корпоративні СД реалізуються засобами реляційних СУБД; інструменти ROLAP дозволяють проводити аналіз безпосередньо над ними. При цьому розмір сховища не є таким критичним параметром, як у разі MOLAP; у разі змінної розмірності задачі, коли зміни в структуру вимірювань доводиться вносити достатньо часто, ROLAP-системи з динамічним представленням розмірності є оптимальним рішенням, оскільки в них такі модифікації не вимагають фізичної реорганізації БД; реляційні СУБД забезпечують значно вищий рівень захисту даних і хороші можливості розмежування прав доступу. Основний недолік ROLAP в порівнянні з багатовимірними СУБД − менша продуктивність. Для забезпечення продуктивності, порівнянної з MOLAP, реляційні системи вимагають ретельного опрацьовування схеми БД і налаштування індексів, тобто великих зусиль з боку адміністраторів БД. Тільки при використовуванні схем типу “зірка” продуктивність добре набудованих реляційних систем може бути наближена до продуктивності систем на основі багатовимірних БД. Кращий ефект при багатовимірному аналізуванні великих обсягів даних забезпечує гібридна HOLAP- модель. HOLAP-модель використовує гібридну архітектуру, яка об'єднує технології ROLAP і MOLAP. На відміну від MOLAP, яка працює краще, коли дані більш-менш щільні, сервери ROLAP показують кращі параметри в тих випадках, коли дані сильно розріджені. Модель HOLAP застосовує підхід ROLAP для розріджених областей багатовимірного простору і підхід MOLAP для щільних областей. Модель HOLAP розділяє запит на декілька підзапитів, спрямовують їх до відповідних фрагментів даних, комбінують результати, а потім надають результат користувачу. |
Последнее изменение этой страницы: 2019-04-11; Просмотров: 267; Нарушение авторского права страницы