
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
СТАТИСТИЧЕСКИЕ МЕТОДЫ ОБЕСПЕЧЕНИЯ КАЧЕСТВА
ОСНОВНЫЕ ПОНЯТИЯ МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ Одной из главных задач обеспечения и постоянного повышения характеристик качества продукции и процессов является использование методов и средств теории вероятностей и математической статистики. Мощным инструментом регулирования и управления качеством служит набор методов, входящих в понятие FMEA ( Failure Mode and Effects Analysis) – анализ видов отказов и их воздействий. Все эти методы невозможно применять без начальных знаний основ математической статистики. Поэтому в данном разделе приводятся необходимые начальные сведения по математической статистике (Л.2,4). Теория вероятности выводит свойства реального физического процесса из математической модели, т.е., определяет какой процент интересующих наблюдений, находится в выборке. Теория математической статистики устанавливает свойства математической модели на основании данных наблюдения, т.е. распространяет данные выборки на всю генеральную совокупность. Статистика позволяет оценить случайность или закономерность проведенных измерений за счет описания массива экспериментальных данных, оценивания характеристик (моментов или статистик) массива данных и принятия решений на основе определенных статистик. В теории математической статистики одним из основополагающих понятий является выборка, характеризующаяся объемом, функцией распределения членов выборки и правилами создания. Обычно стараются создавать репрезентативную (представительную) выборку, т.е. такую, когда любая комбинация из равного числа элементов генеральной совокупности имеет равную вероятность образовать выборку. Обычно, отдельное значение случайной переменной обозначается через x, а ее реализацию через X . С этих позиций, генеральная совокупность представляет собой множество всех возможных реализаций случайной переменной, а выборка представляет n- мерную реализацию, состоящую из n- исходов. Каждая переменная x с определенной вероятностью может принять какое либо значение, тогда накопленное распределение вероятностей F ( x ), чаще всего называемое функцией распределения может быть записано в виде: F ( x ) = P ( X В случае дискретной случайной переменной ( количество дефектных деталей, количество обслуженных посетителей и т.п.) соответствие между xi и вероятностью (относительной частотой ) f ( xi ) представляется в виде полигона частот или гистограммы. Ломаная линия, соединяющая середины верхней части прямоугольников гистограммы, площадь под которой примерно равна единице, называется функцией вероятности или частотной функцией. Выражение для функции распределения может быть записано в виде: .
На рисунке 14 дана иллюстрация гистограммы и полигона частот
Рис.14. Иллюстрация гистограммы и полигона частот Для непрерывной случайной переменной функция распределения запишется в виде: где f ( t ) плотность вероятности. В том случае, когда необходимо рассмотреть изменение случайной переменной в интервале от а до b выражение (6) примет вид: P ( a ≤ X ≤ b ) = F ( b ) – F ( a ) = т.е. вероятность события на этом интервале равна площади под кривой функции распределения в заданных пределах. Чаще всего, функция распределения, определяемая в пределах, носит название закона распределения. Подробнее о законах распределения следует читать в специальной литературе по математической статистике или в ППП «Статистика» или в главе МАТЛАБ по статистике. Подводя итог сказанному, следует запомнить, что любая случайная переменная полностью определяется функцией или законом распределения! Однако при проведении эксперимента или оценке характеристик качества, когда получена начальная выборка, состоящая из какого-то числа данных, нельзя судить о возможном распределении. Поэтому, на основе полученной выборки следует оценить числовые характеристики (статистики) распределения вероятностей, называемые моментами E порядка k , которые представляют собой математическое ожидание М вида: E = M ( X - x ) k , k = 1,2,3,… 8 Следует иметь в виду, что для обозначения характеристик - генеральной - ГС и выборочной совокупностей - ВС, применяются различные символы, которые представлены в таблице 5. В соответствии с этими символами будут приводиться все дальнейшие обозначения.
Таблица 5. Обозначения, применяемые для статистик ГС и ВС
В таблице 6 приведены основные статистики (моменты), для начальной оценки экспериментальных данных. Таблица 6. Определение четырех моментов распределения
В задачах оценки качества чаще всего применяются четыре непрерывных законов распределения: Муавра - Лапласа - Гаусса (нормальное или N -распределение, Стьюдента (Госсета)(t - распределение), Пирсона - Хельмерта ( Нормальное распределение зависит от математического ожидания и стандартного отклонения, остальные три от числа степеней свободы - ЧСС, обозначаемой где m- число определяемых статистик. Чем меньше Таблица 7. Применимость различных распределений
При увеличении номера момента, число статистик возрастает, так при определении дисперсии таких статистик одна - среднее значение, и В последней графе таблицы 7 приведены аналитические выражения для статистик. Статистические критерии. Статистическая надежность. Статистика, определяемая по выборке, является только средней оценкой искомого параметра ГС, которая должна быть дополнена интервальной оценкой, называемой доверительным интервалом. Его величина зависит от соответствующего коэффициента и позволяет судить насколько надежно высказывание о том, что интервал содержит параметр ГС. Вероятность попадания в интервал называется статистической надежностью S . Значение 1- S называется уровнем значимости Таблица 8. значения интервала для N-распределения
Примечание: 1. В последней строке таблицы приведены знаменитые 2. Не путать диапазон Вероятность не превышения уровня ошибки определится из выражения:
где: |
Последнее изменение этой страницы: 2019-04-19; Просмотров: 260; Нарушение авторского права страницы
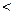 x ). 4
x ). 4 5
5 
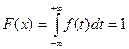 6
6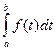 7
7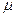
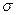

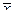
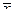 )2
Корень квадратный из дисперсии
R = x max - xmin
)2
Корень квадратный из дисперсии
R = x max - xmin
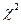 - распределение), Фишера (F- распределение). Применимость этих распределений представлена в таблице 7.
- распределение), Фишера (F- распределение). Применимость этих распределений представлена в таблице 7.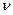 или r . ЧСС статистически определяется числом независимых (свободных) наблюдений и равно объему выборки минус число статистик, оцениваемых по данной выборке, тогда
или r . ЧСС статистически определяется числом независимых (свободных) наблюдений и равно объему выборки минус число статистик, оцениваемых по данной выборке, тогда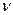 = n - m , 9
= n - m , 9 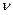 , тем сильнее отклонение от нормального распределения и хвосты распределений больше.
, тем сильнее отклонение от нормального распределения и хвосты распределений больше.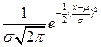
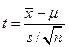

 50
50
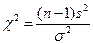
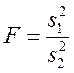
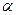 или вероятностью ошибки или превышения уровня.
или вероятностью ошибки или превышения уровня.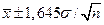

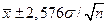
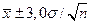
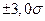 , перекрывающие 99,73% наблюдаемого числового ряда. Следует понять и запомнить, что ширина интервала тем больше, чем выше статистическая надежность!
, перекрывающие 99,73% наблюдаемого числового ряда. Следует понять и запомнить, что ширина интервала тем больше, чем выше статистическая надежность!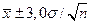 или шесть сигма, с широко применимым ныне в теории обеспечения качества методом шести сигм - МШС! В МШС на самом деле идет речь о диапазоне 12 сигма и это будет более подробно рассмотрено ниже.
или шесть сигма, с широко применимым ныне в теории обеспечения качества методом шести сигм - МШС! В МШС на самом деле идет речь о диапазоне 12 сигма и это будет более подробно рассмотрено ниже. , 10
, 10 , приводя нормальное распределение к стандартному, с нулевым средним значением и стандартным отклонением равным единице. Следует запомнить простое правило: если n раз высказывается утверждение, что неизвестный параметр лежит в доверительном интервале, то в среднем следует ожидать
, приводя нормальное распределение к стандартному, с нулевым средним значением и стандартным отклонением равным единице. Следует запомнить простое правило: если n раз высказывается утверждение, что неизвестный параметр лежит в доверительном интервале, то в среднем следует ожидать 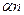 ошибок! В таблице 8 приведены значения доверительного интервала для четырех наиболее часто применяемых значений статистической надежности для стандартного нормального распределения.
ошибок! В таблице 8 приведены значения доверительного интервала для четырех наиболее часто применяемых значений статистической надежности для стандартного нормального распределения.