
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
А. Первичная обработка исходной статистики
В соответствии с физическим определением плотности вероятности F ( t ) ее опытное значение F * в любой точке T = t 1 рассчитывается по формуле F ( t = t 1 ) где На этапе первичной обработки исходной статистики, исходя из формулы (11), необходимо определить: — минимальное ( tmin ) и максимальное (tmax) значения из статистического ряда полученных величин Т= ti; — длину частных интервалов группирования — значения величин — статистические значения элементов вероятности отказов для каждого интервала — опытные статистические значения F *; — заполнить таблицу результатов первичной обработки статистики. Значения tmin , tmax берутся непосредственно из полученного статистического ряда величин ti Длина всего интервала R = tmax - tmin дает первое представление о том, что наиболее вероятное значение случайной величины Т может быть заключено между tmin , tmax, т. е. неизвестная плотность вероятности F ( t ) распределена примерно в этом отрезке значений случайной величины Т. Длина интервала At может быть ориентировочно выбрана с использованием эмпирической формулы: где k — число частных интервалов Значение числа k сначала ориентировочно оценивается по формуле k Подсчет количества реализаций Δt ≈ (200 -1) /( 1+3,3 lg 100) ≈ 26 ч (принимаем Δt =20 ч) K ≈ 1+ 3,3 lg 100 ≈ ( tmax – tmin )/ Δt ≈ (200-1)/20 ≈ 10. Таблица 10 Экспериментальные данные примера
В каждой колонке приводится значение середины интервала t 1= tj ( tj = 10; 30; 50; 70; 90; 110; 130; 150; 170; 190) либо крайние правые границы интервалов tj + После того, как все n = 100 чисел T = ti рассортированы по колонкам таблицы, производится подсчет чисел Пусть значения опытных чисел
После того, как определены величины В нашем примере целесообразно последние три интервала объединить в один, длиной Теперь рассчитываются опытные значения элементов вероятности |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Последнее изменение этой страницы: 2019-04-19; Просмотров: 251; Нарушение авторского права страницы
 11
11 — число отказов, приходящихся на j -й интервал длиною
— число отказов, приходящихся на j -й интервал длиною  на оси возможных значений случайной величины Т (интервал
на оси возможных значений случайной величины Т (интервал  накрывает точку tj ). Обычно точка tj выбирается в середине
накрывает точку tj ). Обычно точка tj выбирается в середине 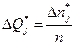 12
12  , 13
, 13 .
. 1 +3,3 lg n и обычно выбирается в пределах k =10
1 +3,3 lg n и обычно выбирается в пределах k =10  30.
30. по интервалам группирования
по интервалам группирования 


 получены такие, как в табл. 10 (
получены такие, как в табл. 10 (  =31,
=31, 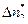 = 22,
= 22,  =13,
=13,  =13, затем 7, 5, 4, 2, 2 и 1). Разумеется, должно выполняться условие:
=13, затем 7, 5, 4, 2, 2 и 1). Разумеется, должно выполняться условие:
 , необходимо проверить, нет ли слишком малых значений
, необходимо проверить, нет ли слишком малых значений 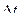 .
. ' = 3
' = 3  — 5. Окончательно имеем всего k = 8 интервалов, семь первых длиной по 20 ч и один последний длиной 60 ч.
— 5. Окончательно имеем всего k = 8 интервалов, семь первых длиной по 20 ч и один последний длиной 60 ч. и
и  для всех интервалов, и результаты первичной обработки статистики заносятся в табл.10.
для всех интервалов, и результаты первичной обработки статистики заносятся в табл.10.