
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Распознавание статистических гипотез
При попарном сравнении двух образцов продукции или двух объектов экспертизы, полученных разными способами или на разных производствах, всегда встает вопрос, какой из них лучше. Сравнивать только средние значения нерационально, так как хвосты распределений могут наложиться друг на друга. При этом, решение принимается на основе статистических предположений (гипотез) о ГС с учетом разброса данных. Выбор правильного решения из двух противоположных предположений о ГС называется статистической проверкой гипотез. Информация при этом носит альтернативный характер, поэтому количественные оценки надо находить с помощью статистического оценивания. Гипотеза о том, что две совокупности, с точки зрения одного или нескольких критериев, одинаковы, называется нуль - гипотезой - H 0. Поскольку критерии устанавливают только отличие совокупностей, H 0 выдвигается для проверки основания ее отбрасывания и принятия альтернативной гипотезы НА, указывающей, что расхождение между проверяемыми совокупностями есть. При проверке гипотез могут возникнуть два ошибочных решения: отклонение верной гипотезы с вероятностью Таблица 9. Возможные исходы распознавания гипотез
Вероятности, соответствующие, обеим исходам в литературе носят различные названия при сохранении начального смысла: - Вероятность отклонения правильной H 0 гипотезы - ошибка первого рода - Вероятность неправильного принятия НА гипотезы - ошибка второго рода, риск II, риск потребителя или заказчика, риск незамеченной разладки технологического процесса и т.д. Ошибки первого и второго рода уменьшаются при увеличении объема выборки и равны нулю при проверке ГС в целом. Ошибка первого рода принимается в пределах от 1 % до 10 %, ошибка второго рода от 10% и больше. Приведем алгоритм распознавания гипотез на примере N- распределения, в случае проверки гипотез для других распределений алгоритм не меняется, а в нем используются статистики рассматриваемого распределения (см. таблицу 8). 1. Принимаем нулевую гипотезу H 0 : 2. Формируем альтернативную гипотезу HA : 3. Используем статистику N распределения 4. Принимаем уровень значимости 5. Сравниваем статистическое и табличное значения статистик если если Пример Пусть взята первая выборка с параметрами Н0 : НА: Пополним первую выборку до 49 членов, параметры выборки примут вид В теории математической статистики рассматриваются разные виды критериев: - критерии значимости ( принять или отклонить), - параметрические критерии, когда проверяется численное значение параметра - критерии согласия, проверяющие согласуется ли экспериментальное распределение с гипотетическим распределением. |
|||||||||||||||||
Последнее изменение этой страницы: 2019-04-19; Просмотров: 274; Нарушение авторского права страницы
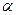 и принятие неверной гипотезы с вероятностью
и принятие неверной гипотезы с вероятностью  . Подобный алгоритм представлен в таблице 9.
. Подобный алгоритм представлен в таблице 9. (
( 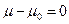 ),
), (
(  ),
), или статистику любого другого проверяемого закона распределения
или статистику любого другого проверяемого закона распределения .
.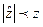 , то Н0 не отвергается,
, то Н0 не отвергается, , то Н0 отвергается на принятом уровне значимости
, то Н0 отвергается на принятом уровне значимости 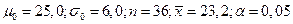

 ,
, , следовательно Н0 подтверждается на принятом уровне значимости.
, следовательно Н0 подтверждается на принятом уровне значимости.

 , следовательно Н0 отвергается на принятом уровне значимости.
, следовательно Н0 отвергается на принятом уровне значимости.