|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Линейная тактика — залог успеха
Первой конструкцией такого типа был автомат с линейной тактикой, предложенный М. Л. Цетлиным. На рис. 2.3 показан принцип функционирования подобного устройства. Число лепестков «ромашки»
равно числу действий, доступных автомату. На рисунке для простоты показан случай, когда число таких действий равно трем. В каждом лепестке выделено четыре устойчивых состояния, в которых может находиться автомат. В любом из состояний, образующих лепесток ромашки, устройство выдает в среду сигнал действия, приписанного этому лепестку. Смена состояний происходит с учетом сигналов оценок за действия, поступающих от внешней среды. Как уже говорилось, эти сигналы двоичные. При поступлении сигнала нештраф наступает смена состояний, показанная на рис. 2.3 сплошными стрелками. Автомат как бы переходит к внешнему краю ле- 83
пестка, а когда достигает последнего состояния в лепестке, то остается в нем. Если же на вход автомата приходит сигнал штраф, то состояния сменяются в соответствии с пунктирными стрелками на рисунке. Автомат идет в глубь лепестка, в какой-то момент под влиянием сигнала штраф переходит «а другой лепесток ромашки и происходит смена действий автомата. Смена лепестков, как видно из рисунка, происходит поочередно. Поясним теперь принцип работы устройства подобного типа. Пусть оно взаимодействует со стационарной средой, характеризуемой вектором вида Е = (0,9, 0,0001, 0,8). И пусть в начальный момент наше устройство находилось в состоянии, показанном на рис. 2.3 штриховкой. Понаблюдаем за его функционированием. Находясь в заштрихованном состоянии, устройство выполнит действие d1. За это действие среда с вероятностью 0,9 оштрафует нашу зверушку и лишь с вероятностью 0,1 поощрит ее. Тогда устройство с вероятностью 0,9 перейдет из заштрихованного состояния в состояние 1 в том же лепестке, а с вероятностью 0,1 — в состояние 3 в том же лепестке. В любом случае оно снова произведет в среде действие d1. И опять неумолимая среда с вероятностью 0,9 выдаст сигнал штраф и лишь с вероятностью 0,1 поощрит устройство. Как следует из формул теории вероятностей для независимых событий (а выработка сигналов средой на каждом шаге происходит независимо от других шагов), вероятность получения от среды двух сигналов штрафа подряд за действие d1 есть 0,9*0,9 == 0,81, вероятность получения двух поощрений подряд равна 0,1*0,1 = 0,01, а вероятность получить один штраф и одно поощрение — 0,9*0,1+0,1*0,9=0,18. Это означает, что после двух тактов взаимодействия со средой наше устройство с вероятностью 0,01 окажется в состоянии 4 группы состояний, соответствующих действию d1, с вероятностью 0,18 останется в заштрихованном состоянии и, наконец, с вероятностью 0,81 перейдет в состояние 1 той группы, которой соответствует действие d3. С ростом числа взаимодействий качественная картина не изменится. Вероятность покинуть группу состояний, в которой совершается действие d1, неуклонно возрастает, а вероятность остаться в ней — падает, 84 Что произойдет, когда устройство перейдет в состояние 1 того лепестка, который соответствует действию d3? После формирования этого действия среда с вероятностью 0,8 оштрафует устройство, и оно перейдет в состояние 1 того лепестка, которому соответствует действие d2. С вероятностью же 0,2 будет получен сигнал поощрения, который заставит наше устройство перейти в состояние 2 лепестка, соотносимого с действием d3. Но, как и в предшествующем случае, вероятность остаться в состояниях этого лепестка будет убывать с ростом числа взаимодействий, и автомат в конце-концов покинет и этот лепесток, перейдя в группу состояний, соответствующих действию d2. Здесь наблюдается иная картина. Поскольку величина вероятности штрафа за действие d2 весьма мала, то с большой вероятностью автомат заберется в последнее состояние лепестка и почти не будет покидать его. Вероятность уйти на другие лепестки ничтожно мала. По порядку величин она равна 10*E-15. А это значит, что после некоторого периода обучения автомат, имитирующий поведение зверушки, будет вести себя почти самым наилучшим образом. «Почти» связано с тем, что существует ненулевая, хотя и очень малая, вероятность ухода автомата из состояния, соответствующего действию d2. Тогда после очередного периода блуждания по лепесткам действий d1 и d3 автомат вновь вернется на благоприятный лепесток действия d2 и вновь надолго останется в нем. Однако за это «отступничество» ему придется накопить некоторый дополнительный штраф, которого не было бы, если бы всегда выполнялось действие d2. На нашем рисунке в каждом лепестке ромашки по четыре состояния. Выбор этого числа состояний произволен. Каждый лепесток может содержать не четыре, а большее или меньшее число состояний. Обозначим это число через q. Оно называется глубиной памяти автомата. Смысл этого параметра заключается в следующем. Чем больше q, тем более инерционен автомат, ибо тем большая последовательность штрафов вынуждает его к смене действий. Интуитивно ясно, что, чем больше инерционность автомата, тем ближе он к тому, чтобы, выбрав наилучшее в данной среде действие, продолжать выполнять только его. 85 Читателю должно быть ясно, что с ростом глубины памяти растет при функционировании в стационарных средах и целесообразность поведения автомата. И, наоборот, при малом значении q функционирование автомата подвержено воздействию сигналов штрафа, часто выводящих автомат на лепестки с невыгодными действиями. Конструкция автомата, рассмотренная нами, была названа М. Л. Цетлиным автоматом с линейной тактикой. И эта весьма простая в технической реализации система (набор сдвигающих регистров, соотносимых с лепестками и тривиальная логическая схема для организации сдвига единички в этих регистрах и перехода с регистра на регистр) решает сложную задачу о целесообразном поведении в любой заранее не фиксированной стационарной среде. Факт этот вызывает глубокое изумление. Сколь же просты оказываются конструкции, способные выполнять процедуры адаптации, представляющиеся на первый взгляд весьма сложными. Но оказывается, что целесообразное поведение это еще не все. Можно показать (и М. Л. Цетлин сделал это), что если minP, не превосходит 0,5, то при росте величины q мы получим последовательность автоматов с линейной тактикой со все увеличивающейся глубиной памяти, которая является асимптотически оптимальной. Это означает, что при q -->бесконечность имеет место M(q,E) —>М, где М—минимальный суммарный штраф, который можно получить в данной стационарной случайной среде. Таким образом, во многих таких средах конструкция, предложенная М. Л. Цетлиным, обеспечивает при достаточно больших значениях q поведение, сколь угодно близкое к наилучшему. А это уже совсем фантастично. После автоматов с линейной тактикой было найдено еще много конструкций зверушек, которые могли вести себя целесообразно, а зачастую асимптотически оптимально в любых стационарных случайных средах. О них мы расскажем ниже. § 2.4. «Личные» качества автоматов Автомат с линейной тактикой аккуратен и педантичен. Неторопливо движется он по состояниям лепестков, отсчитывая число поступивших на его вход 36
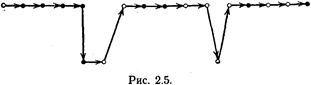
наказаний и поощрений. Но возможны и другие автоматы. Вот один из них, предложенный В. И. Кринским. Он похож на автомат с линейной тактикой и действует при поступлении сигнала штраф аналогично автомату с линейной тактикой. Но при сигнале поощрение его поведение резко отлично от педантизма автомата с линейной тактикой. В каком бы состоянии лепестка в этот момент не был автомат В. И. Кринского, он тут же меняет его на самое глубокое для данного лепестка состояние. Соответствующая картина показана на рис. 2.4 (пока не следует обращать внимание на штрихпунктирные линии). Такой автомат можно назвать «доверчивым». Он всегда «верит» в хорошее. И всякий положительный сигнал от среды приводит его в состояние «эйфории». Казалось бы, подобный способ поведения ничего кроме неприятностей автомату не сулит. Но мир автоматов оригинален и странен. Строго доказано, что доверчивые автоматы В. И. Кринского ведут себя 37 целесообразно в любых стационарных случайных средах, а последовательность подобных автоматов с ростом их глубины памяти q образует асимптотически оптимальную последовательность. Оказывается, что и автоматы, предложенные Г. Роббинсом, которые отличаются от доверчивых автоматов тем, что при переходе с лепестка на лепесток они переходят не в начальное состояние лепестка, а в конечное его состояние (на рис. 2.4 эти переходы показаны штрихпунктирными стрелками), также ведут себя целесообразно в любой стационарной случайной среде и при росте глубины памяти q образуют асимптотически оптимальную последовательность автоматов. Создается такое впечатление, что любые меры по повышению инерционности автомата, задержке его в группе состояний, принадлежащих одному лепестку, улучшат качество его функционирования в среде. Пояснить это можно следующим примером. Заядлый рыболов, обнаружив однажды место, где был хороший клев, может ходить сюда довольно долго, хотя результаты могут быть нулевыми. И часто при достаточном терпении он бывает вознагражден сторицей за предшествующие неудачи. А, сменив место ловли и не поймав ни одной рыбешки, такой рыболов не отчаивается и еще много раз приходит сюда, чтобы попытать счастья. И окончательно разочаруется в облюбованном месте лишь тогда, когда довольно много раз уйдет отсюда без какой-либо добычи. И, как показывает жизненный опыт многих поколений любителей рыбной ловли, средний улов такого рыболова всегда выше, чем у его коллеги, придерживающегося тактики менять место ловли, как только при первой же рыбалке его улов оказывается незначительным. Опишем еще одну конструкцию автомата, обеспечивающего целесообразное поведение в любой стационарной среде и дающего возможность построить асимптотически оптимальную последовательность автоматов, позволяющую получать минимальный возможный штраф в данной среде с любой наперед заданной точностью. В отличие от ранее рассмотренных конструкций этот автомат будет не детерминированным, а вероятностным. Устроен он подобно автомату с линейной тактикой. При поступлении сигнала нештраф смена состояний в нем происходит так, как показано на рис. 2.3. Но при сигнале штраф та- 38 кой автомат не спешит менять состояние. Сначала он «подбрасывает монетку» и по результату подбрасывания либо переходит в состояние по пунктирной стрелке, показанной на рис. 2.3, либо сохраняет то состояние, в котором автомат получил сигнал штраф. Эта конструкция, предложенная В. Ю. Крыловым, может быть названа «осторожным» автоматом. Интересен вопрос о том, насколько модели зверушек, построенные в рамках теории коллективного поведения, идентичны тем моделям, которые лежат в основе поведенческих актов, наблюдавшихся в опытах Торндайка, или в ситуациях альтернативного выбора, характерных для человека. М. А. Алексеев, М. С. Залкинд и В. М. Кушнарев провели серию экспериментов с людьми. Они проводили опыты в изолированной комнате, где ничего нет, кроме пульта с двумя кнопками, перед которым стоит стул. Испытуемый садится на него и надевает наушники. Если нажать ту или иную кнопку, то с некоторой фиксированной вероятностью, неизвестной испытуемым, в наушниках раздастся щелчок. Это сигнал поощрения. Отсутствие щелчка — аналог сигнала штраф. Цель испытуемого максимизировать сигналы нештрафа путем правильного выбора нажимаемых кнопок. Внешне все выглядит так же, как в опытах Торндайка, т. е. альтернативный выбор из двух возможностей и неизвестные заранее значения вероятностей поощрения и наказания. Как же ведут себя люди в этой экспериментальной ситуации? В простейших случаях, когда вероятность щелчка при нажатии одной из кнопок была равна единице, а при нажатии второй имелась ненулевая вероятность штрафа, люди быстро постигали ситуацию и нажимали лишь ту кнопку, которая гарантировала им стопроцентную удачу. Однако в более сложных случаях поведение испытуемых не было столь простым, как можно было бы предполагать. Если стационарная среда задавалась, например, вектором Е == (0,2, 0,8), то, вместо того чтобы после некоторого периода обучения нажимать всегда первую кнопку (здесь вероятность щелчка есть 0,8, так как вероятность штрафа для первой кнопки задана равной 0,2), человек нажимал то одну кнопку, то другую. На рис. 2.5 показан фрагмент действий испытуемого. Верхняя цепь кружочков соответствует 39
нажатию первой кнопки, а нижняя — второй кнопки. Зачерненные кружки соответствуют нажатию, при котором испытуемый услышал щелчок, светлые — исходу испытания со штрафом. Как видно из рисунка, испытуемый правильно считает, что надо нажимать на первую кнопку, но время от времени он пробует нажимать и на вторую. Появление штрафа при этом переходе с кнопки на кнопку (с лепестка на лепесток) приводит к возвращению к первой кнопке. Сравнивая поведение людей с функционированием автоматов с линейной тактикой, авторы эксперимента при шли к выводу, что людей можно уподобить таким автоматам с небольшой глубиной памяти (q = 1, 2, 3). Это приводит к тому, что люди решают задачу альтернативного выбора (особенно при близких значениях вероятностей Pi друг к другу) хуже, чем автоматы с линейной тактикой. И, конечно, хуже остальных рассмотренных нами автоматов. Интересно, что И. Б. Мучник и О. Я. Кобринская показали, что крысы в условиях опыта Торндайка действуют с гораздо большей глубиной памяти и превосходят в этом отношении человека. Но в средах с близкими значениями вероятности штрафов за действия пальма первенства остается не за биологическими организмами, а за не знающими эмоций простейшими автоматными устройствами. |
Последнее изменение этой страницы: 2019-05-06; Просмотров: 279; Нарушение авторского права страницы