
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Из попарной независимости не следует независимость в совокупности.
Независимость событий заключается в том, что между событиями нет причинно-следственной связи. Пример показывающий, что из попарной незавимости не следует независимость в совокупности. Подбрасывается тетраэдр, на трёх гранях которого написано по одной цифре 1, 2, 3 соответственно, а на четвёртой присутствуют все 3 цифры одновременно. Рассматриваются события
Имеем
Исходя из проведённых выкладок, делаем вывод о том, что попарная независимость есть. Проверим теперь, есть ли независимость в совокупности:
2.6. Определение независимых случайных величин. Математическое ожидание произведения и дисперсия суммы независимых случайных величин. Случайные величины Случайные величины Математи́ческоеожида́ние — среднее значение случайной величины, распределение вероятностей случайной величины. Определение. Пусть задано вероятностное пространство
Свойства математического ожидания Математическое ожидание суммы независимых случайных величин равно сумме их математических ожиданий: Mx + y = Mx + My. Математическое ожидание произведения независимых случайных величин равно произведению их математических ожиданий:Mx · y = Mx · My. Диспе́рсияслуча́йной величины́ — мера разброса данной случайной величины, то есть её отклонения от математического ожидания. Обозначается Определение. Пусть Х — случайная величина, определённая на некотором вероятностном пространстве. Тогда Свойства Дисперсия любой случайной величины неотрицательна: Если дисперсия случайной величины конечна, то конечно и её математическое ожидание; Если случайная величина равна константе, то её дисперсия равна нулю: Дисперсия суммы двух случайных величин равна: , где Для дисперсии произвольной линейной комбинации нескольких случайных величин имеет место равенство: , где В частности,
2.7. Ковариа́ция (корреляционный момент, ковариационный момент) в теории вероятностей и математической статистике мера линейной зависимости двух случайных величин. Определение Пусть ,в предположении, что все математические ожидания в правой части определены. Замечания Если В гильбертовом пространстве несмещённых случайных величин с конечным вторым моментом Свойства Если НО обратное утверждение, вообще говоря, неверно: из отсутствия ковариации не следует независимость. 2.8. Коэффициент корреляции. Определение Пусть , где , Свойства Неравенство Коши — Буняковского: Коэффициент корреляции равен Где Если 2.11. Теорема Маркова.неравенствоЧебышева,правило трех .. Теорема Маркова. Если имеются зависимые случайные величины
, Применим к величине Так как по условию теоремы при
, что и требовалось доказать.
Неравенство Чебышева. Первое неравенство Чебышева. Пусть Х – неотрицательная случайная величина (т.е. Доказательство. Все слагаемые в правой части формулы (4), определяющей математическое ожидание, в рассматриваемом случае неотрицательны. Поэтому при отбрасывании некоторых слагаемых сумма не увеличивается. Оставим в сумме только те члены, для которых Для всех слагаемых в правой части (9) Из (9) и (10) следует требуемое. Второе неравенство Чебышева. Пусть Х – случайная величина. Для любого положительного числа а справедливо неравенство Для доказательства второго неравенства Чебышёва рассмотрим случайную величину У = (Х – М(Х))2. Она неотрицательна, и потому для любого положительного числа b, как следует из первого неравенства Чебышёва, справедливо неравенство Положим b = a2. Событие {Y>b} совпадает с событием {|X – M(X)|>a}, а потому ПРАВИЛО ТРЕХ СИГМ. В качестве следствия получим так называемое «правило трёх сигм», которое означает, что вероятность случайной величине отличаться от своего математического ожидания более, чем на три корня из дисперсии, мала. Мы получим верную для всех распределений с конечной дисперсией оценку сверху для вероятности случайной величине отличаться от своего математического ожидания более, чем на три корня из дисперсии.Правило трех сигм При рассмотрении нормального закона распределения выделяется важный частный случай, известный как правило трех сигм. Запишем вероятность того, что отклонение нормально распределенной случайной величины от математического ожидания меньше заданной величины D: 2.12 Абсолютно непрерывные случ величины. Случайную величину назовем непрерывной, если ее функция распределения непрерывна. Легко видеть, что случайная величина непрерывна тогда и только тогда, когда Важный класс непрерывных случайных величин -- абсолютно непрерывные случайные величины. Это случайные величины, распределение которых имеет плотность. Случайная величина
Функция Следствие Если Наглядный смысл плотности можно проиллюстрировать следующим рисунком. Замечание Если плотность Следствие 3.2 Если
Примеры абсолютно непрерывных распределений 1) Равномерное распределение в отрезке
2) Показательное распределение с параметром
Показательное распределение называют также экспоненциальным. 3) Нормальное (или гауссовское) распределение
Стандартное нормальное распределение -- :
2.13 Равномерное распределение Р. р. на отрезке числовой прямой (прямоугольное распределение). Р. р. на каком-либо отрезке [ а, b], а<b, - это распределений вероятностей, имеющее плотность Понятие Р. р. на [ а, b] соответствует представлению о случайном выборе точки на этом отрезке "наудачу". Математич. ожидание и дисперсия Р. р. равны, соответственно, (b+a)/2 и (b-а)2/12. Функция распределения задается формулой График дифференциальной функции равномерного распределения вероятностей представлен на рис. Интегральную функцию равномерного распределения аналитически можно записать так:
Математическое ожидание равномерного распределения: M(X) = (a + b)/2 Дисперсия равномерного распределения: D(X) = (b - a)2/12 Среднее квадратичное отклонение равномерного распределения: σ(X) = (b - a)/(2√3) 2.15 Нормальное распределение. Нормальное распределение, также называемое гауссовым распределением, гауссианой или распределением Гаусса — распределение вероятностей, которое задается функцией плотности распределения:
Плотность вероятности Функция распределения График плотности распределения для нормально распределённой случайной величины имеет вид, отдалённо напоминающий колокол:
Функция нормального распределения имеет вид
Заметим, что нормальная кривая (рис.9.11 ) симметрична относительно прямой Вычислим математическое ожидание для нормального закона СМЫСЛ ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ Кривая распределения по нормальному закону имеет симметричный холмообразный вид (рис. 6.1.1). Максимальная ордината кривой, равная
Выясним смысл численных параметров
Применяя замену переменной
Нетрудно убедиться, что первый из двух интервалов в формуле (6.1.2) равен нулю; второй представляет собой известный интеграл Эйлера-Пуассона:
Вычислим дисперсию величины X: Применив снова замену переменной Интегрируя по частям, получим: Первое слагаемое в фигурных скобках равно нулю (так как Следовательно, параметр Выясним смысл параметров Размерность центра рассеивания – та же, что размерность случайной величины X. Параметр
Размерность параметра В некоторых курсах теории вероятностей в качестве характеристики рассеивания для нормального закона вместо среднего квадратического отклонения применяется так называемая мера точности. Мерой точности называется величина, обратно пропорциональная среднему квадратическому отклонению
3.1 Определение. Множество Итак, с одной стороны, выборка - это конкретный набор значений случайной величины. Однако, если мы повторим серию из Таким образом, в математической модели, выборка - совокупность независимых и одинаково распределенных случайных величин |
Последнее изменение этой страницы: 2019-05-08; Просмотров: 1492; Нарушение авторского права страницы
 {тетраэдр упадёт на грань, на которой присутствует цифра i},
{тетраэдр упадёт на грань, на которой присутствует цифра i}, 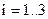 . Показать, что события
. Показать, что события  попарно независимы, но не являются независимыми в совокупности.
попарно независимы, но не являются независимыми в совокупности.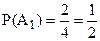





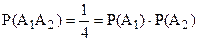
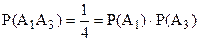

 => независимости в совокупности нет. Этот пример подтверждает изложенный выше факт, что из попарной независимости не следует независимость в совокупности.
=> независимости в совокупности нет. Этот пример подтверждает изложенный выше факт, что из попарной независимости не следует независимость в совокупности. называют независимыми (в совокупности), если для любого набора борелевских множеств
называют независимыми (в совокупности), если для любого набора борелевских множеств  ,...,
,...,  имеет место равенство:
имеет место равенство: 
 и определённая на нём случайная величина
и определённая на нём случайная величина  . То есть, по определению,
. То есть, по определению,  — измеримая функция. Если существует интеграл Лебега от X по пространству
— измеримая функция. Если существует интеграл Лебега от X по пространству  , то он называется математическим ожиданием, или средним (ожидаемым) значением и обозначается
, то он называется математическим ожиданием, или средним (ожидаемым) значением и обозначается  или
или  .
.

 , где символ М обозначает математическое ожидание.
, где символ М обозначает математическое ожидание.
 Верно и обратное: если
Верно и обратное: если 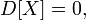 то
то  почти всюду;
почти всюду;
 — их ковариация;
— их ковариация;
 ;
; для любых независимых или некоррелированных случайных величин, так как их ковариации равны нулю;
для любых независимых или некоррелированных случайных величин, так как их ковариации равны нулю;


 — две случайные величины, определённые на одном и том же вероятностном пространстве. Тогда их ковариация определяется следующим образом:
— две случайные величины, определённые на одном и том же вероятностном пространстве. Тогда их ковариация определяется следующим образом: 
 , то есть имеют конечный второй момент, то ковариация определена и конечна.
, то есть имеют конечный второй момент, то ковариация определена и конечна. ковариация имеет вид
ковариация имеет вид  и играет роль скалярного произведения.
и играет роль скалярного произведения.
 — две случайные величины, определённые на одном вероятностном пространстве. Тогда их коэффициент корреляции задаётся формулой:
— две случайные величины, определённые на одном вероятностном пространстве. Тогда их коэффициент корреляции задаётся формулой: 
 обозначает ковариацию, а
обозначает ковариацию, а  —дисперсию, или, что то же самое,
—дисперсию, или, что то же самое, где символ
где символ  обозначает математическое ожидание.
обозначает математическое ожидание.
 тогда и только тогда, когда
тогда и только тогда, когда  и
и  линейно зависимы:
линейно зависимы: 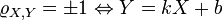
 . Более того в этом случае знаки
. Более того в этом случае знаки  иК совпадают:
иК совпадают: . Обратное, вообще говоря, неверно.
. Обратное, вообще говоря, неверно. и если при
и если при 
 то среднее арифметическое наблюденных значений случайных величин
то среднее арифметическое наблюденных значений случайных величин 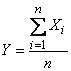 Очевидно,
Очевидно, 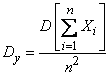

 , то при достаточно большом
, то при достаточно большом 
 или, переходя к противоположному событию,
или, переходя к противоположному событию, 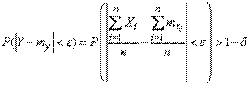
 для любого
для любого  ). Тогда для любого положительного числа а справедливо неравенство
). Тогда для любого положительного числа а справедливо неравенство 
 . Получим, что
. Получим, что  . (9)
. (9) . (10)
. (10)

 что и требовалось доказать.
что и требовалось доказать. Если принять D = 3s, то получаем с использованием таблиц значений функции Лапласа:
Если принять D = 3s, то получаем с использованием таблиц значений функции Лапласа:  Т.е. вероятность того, что случайная величина отклонится от своего математического ожидание на величину, большую чем утроенное среднее. На практике считается, что если для какой – либо случайной величины выполняется правило трех сигм, то эта случайная величина имеет нормальное распределение.
Т.е. вероятность того, что случайная величина отклонится от своего математического ожидание на величину, большую чем утроенное среднее. На практике считается, что если для какой – либо случайной величины выполняется правило трех сигм, то эта случайная величина имеет нормальное распределение. при всех
при всех  .
.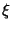 называется абсолютно непрерывной, если существует функция
называется абсолютно непрерывной, если существует функция 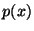 такая, что
такая, что  ,
,  ,
,  , имеет место равенство:
, имеет место равенство: 

 , обладающая вышеперечисленными свойствами, называется плотностью распределения случайной величины
, обладающая вышеперечисленными свойствами, называется плотностью распределения случайной величины 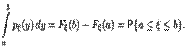

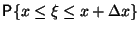 =
= 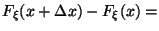








 ,
,  ,
,  :
:

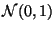
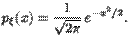

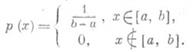
 а характеристич. функция - формулой
а характеристич. функция - формулой 
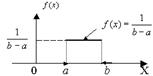
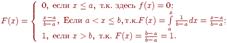 График интегральной функции равномерного распределения вероятностей представлен на рис.
График интегральной функции равномерного распределения вероятностей представлен на рис. 
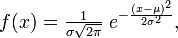 где параметр μ — среднее значение (математическое ожидание) случайной величины и указывает координату максимума кривой плотности распределения, а σ² — дисперсия.
где параметр μ — среднее значение (математическое ожидание) случайной величины и указывает координату максимума кривой плотности распределения, а σ² — дисперсия.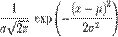

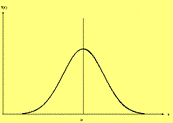
 График нормальной функции распределения
График нормальной функции распределения (22)
(22) и асимптотически приближается к оси ОХ при
и асимптотически приближается к оси ОХ при  .
.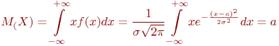
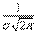 , соответствует точке
, соответствует точке  ; по мере удаления от точки
; по мере удаления от точки  плотность распределения падает, и при
плотность распределения падает, и при  кривая асимптотически приближается к оси абсцисс.
кривая асимптотически приближается к оси абсцисс. 
 , входящих в выражение нормального закона (6.1.1); докажем, что величина
, входящих в выражение нормального закона (6.1.1); докажем, что величина 
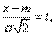 имеем:
имеем: 
 Следовательно,
Следовательно,  т.е. параметрm представляет собой математическое ожидание величиныX . Этот параметр, особенно в задачах стрельбы, часто называют центром рассеивания (сокращенно – ц. р.).
т.е. параметрm представляет собой математическое ожидание величиныX . Этот параметр, особенно в задачах стрельбы, часто называют центром рассеивания (сокращенно – ц. р.).
 имеем:
имеем: 

 при
при  убывает быстрее, чем возрастает любая степень
убывает быстрее, чем возрастает любая степень  ), второе слагаемое по формуле (6.1.3) равно
), второе слагаемое по формуле (6.1.3) равно  , откуда
, откуда 
 на обратный выражение (6.1.1) не меняется. Если изменять центр рассеивания , кривая распределения будет смещаться вдоль оси абсцисс, не изменяя своей формы (рис. 6.1.2). Центр рассеивания характеризует положение распределения на оси абсцисс.
на обратный выражение (6.1.1) не меняется. Если изменять центр рассеивания , кривая распределения будет смещаться вдоль оси абсцисс, не изменяя своей формы (рис. 6.1.2). Центр рассеивания характеризует положение распределения на оси абсцисс. 
 ; из них кривая I соответствует самому большому, а кривая III – самому малому значению
; из них кривая I соответствует самому большому, а кривая III – самому малому значению 
 Размерность меры точности обратная размерности случайной величины.Термин «мера точности» заимствован из теории ошибок измерений: чем точнее измерение, тем больше мера точности. Пользуясь мерой точности , можно записать нормальный закон в виде:
Размерность меры точности обратная размерности случайной величины.Термин «мера точности» заимствован из теории ошибок измерений: чем точнее измерение, тем больше мера точности. Пользуясь мерой точности , можно записать нормальный закон в виде: 
 отдельных значений случайной величины
отдельных значений случайной величины 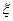 , полученных в серии из
, полученных в серии из  независимых экспериментов (наблюдений), называется выборочной совокупностью или выборкой объема
независимых экспериментов (наблюдений), называется выборочной совокупностью или выборкой объема 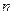 экспериментов, мы получим другой набор значений случайной величины
экспериментов, мы получим другой набор значений случайной величины  , т.е. любое выборочное значение
, т.е. любое выборочное значение  само является случайной величиной, очевидно распределенной по тому же закону
само является случайной величиной, очевидно распределенной по тому же закону  .
.