|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Модельные, алгоритмические и инструментальные предложения относительно организации системы эмоциональной тональности контента
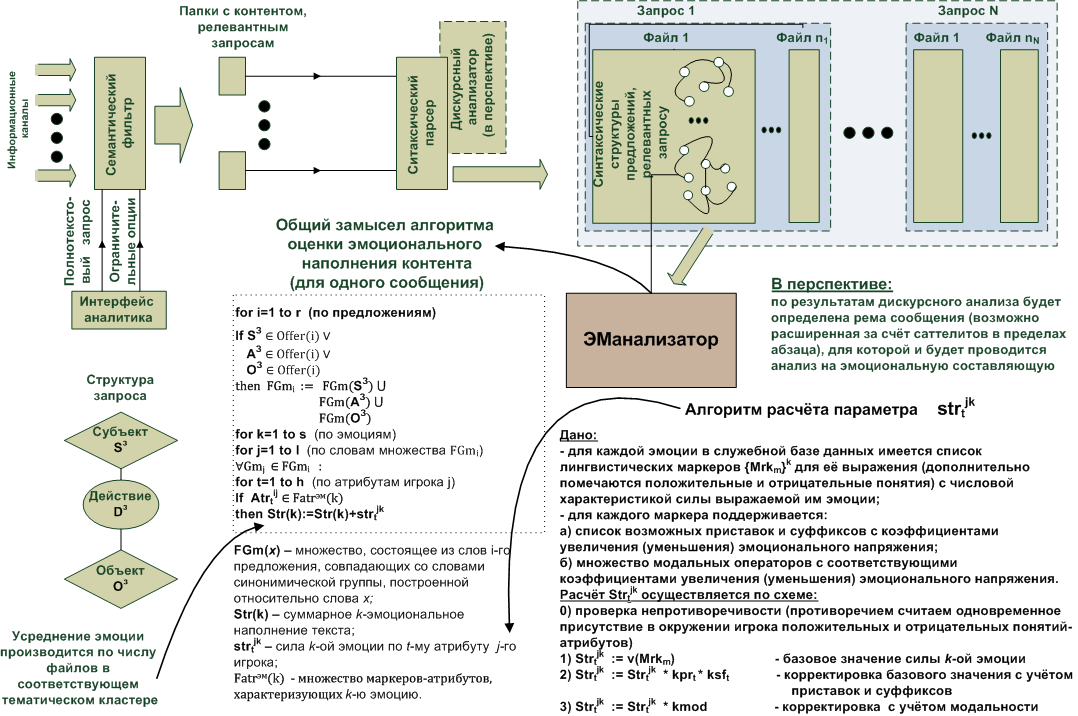
В настоящее время известны два общих подхода к решению задачи оценки тональности текстового материала. A. Инженерный подход, состоящий в применении структурных моделей, лингвистических правил и шаблонов. При этом: · правила и шаблоны пишут эксперты; · используются лингвистические ресурсы; · для записи правил применяются специальные языки и поддерживающие их программные средства – GATE, Томита-парсер, LSPL и др. B. Машинное обучение, в основе которого лежит опора на статистические (вероятностные) модели и методы. При этом необходимо использовать предварительно размеченную вручную обучающую текстовую выборку. С учётом того, что в перспективе хотелось бы довести предлагаемый проект до возможностей полноценного учёта семантики текстового контента (часто эмоциональная окраска мнения шифруется не синтаксическими, а семантическими изысками авторов), первый подход представляется более перспективным, хотя и более трудоёмким. Таким образом, выбрав первый подход, будем рассматривать формулируемые ниже предложения в порядке их соответствия установленным выше требованиям (возможностям) к функционалу. 1. Формулировка полнотекстового запроса в форме утверждения некоторого факта или тематически связной системы фактов, очерчивающего тематику исследований подразумевает возможности интерфейса системы по вводу полнотекстового запроса, который далее будет подвергаться последовательной обработке в ходе графематического, морфологического, синтаксического, первичного семантического, дискурсного (в перспективе) и семантического (в перспективе) анализа. 2. Обеспечение формирования тематического кластера текстовых материалов предполагает реализацию процедуры тематического отбора контента, предоставляемого выбранными источниками информации – информационными агентствами и (или) социальными сетями, тематически соответствующего запросу. Данная задача была успешно решена в [4] и рассматривается в данной работе как подзадача/подсистема. 3. Формирование списка функциональных ролей, или игроков (субъект действия, собственно действие, объект действия), с автоматическим определением их по структуре предложений запроса, а также списка атрибутов отобранных игроков, собственно и определяющих эмоциональное отношение автора контента именно к этим игрокам. Данная подзадача является одной из наиболее трудоёмких и декомпозируется на следующие шаги: 1) Входной контент (обработка ведётся по отдельным текстовым документам), уже отобранный по тематическим признакам, подвергается вначале морфологическому анализу. Результатом морфемного разбора является совокупность нормализованных словоформ предложений разбираемого текста с паспортами, включающими их морфологические характеристики (в том числе суффиксы, которые могут быть использованы в дальнейшем). 2) Запрос аналитика, определяющий тематическую направленность, также подвергается морфологическому, а затем и синтаксическому анализу (используется модифицированный и доработанный АОТ-парсер [2]) с целью выявления субъекта(ов) запроса, действия(ий) запроса и объекта(ов) запроса, как «игроков» некоторой очерчиваемой ими ситуации. Здесь же формируются расширенные списки, включающие помимо имён игроков также и их синонимические группы. Эти группы являются результатом выполнения очередного этапа решения описываемой подзадачи и выполняют роль «центров кристаллизации» для лингвистических маркеров, отражающих те или иные заданные эмоции. 3) Результаты двух предыдущих шагов используются для отбора тех предложений входного контента, которые включают соответствующие «центры кристаллизации». Таким образом, по окончании третьего этапа подзадача будет иметь ограниченный относительно входного контент, включающий только предложения, содержащие слова созданных в соответствие с запросом аналитика синонимических групп. 4) Отобранные предложения подвергаются синтаксическому анализу. Для этого используется уже упомянутый парсер, расширенный дополнительными грамматическими правилами разбора предложений русского языка и снабжённый дополнительными же средствами первичного семантического анализа, позволяющими выделять функциональные роли лингвистических объектов (субъект действия, собственно действие, объект действия), а также их атрибутов (обычно дополнений места, времени и т.д.), относительно которых далее и будет даваться характеристика эмоциональной тональности. Включение в подзадачу таких процедур вызвано необходимостью целенаправленного вскрытия эмоциональных характеристик относительно требуемых игроков, а не относительно всего текстового материала. Результатом этапа являются иерархические синтаксические структуры отобранных предложений с подсвеченными атрибутами игроков. 4. Выбор списка требуемых эмоций, информация о наличии которых представляет интерес, настраивает проект на поиск именно заданных эмоциональных характеристик. Такие характеристики формируются при совпадении выявленных атрибутов игроков с соответствующими лингвистическими маркерами, хранящимися в специальной базе данных. 5. Измерение величины отобранных эмоций относительно игроков, входящих в сформированный ранее список, в шкале отношений, осуществляется посредством суммирования соответствующих эмоциональных характеристик по всем текстовым материалам требуемого тематического кластера. Математический аппарат, используемый для такого суммирования, представлен на рисунке 3. 6. Отображение полученных результатов в удобной для аналитика форме с широким спектром возможностей настройки: по периоду времени, по отображаемым эмоциям и др. осуществляется с помощью дружественного графического интерфейса, позволяющего: 1) вводить запрос аналитика, обеспечивающий как тематический отбор контента, так и фиксацию группы игроков для оценки его эмоционального фона; 2) формировать список источников информации, подвергаемых тональностному исследованию; 3) устанавливать временные рамки выхода в свет соответствующих информационных материалов; 4) задавать список эмоций для анализа отобранных материалов; 5) выводить на экран монитора результаты анализа в форме разноцветных (в соответствие со вскрываемыми эмоциями) графических отображений (с привязкой к временной шкале и с учётом силы соответствующих эмоций); 6) выводить на экран монитора графические образы синтаксически разобранных предложений; и т.д. В целом описание предлагаемого подхода можно проиллюстрировать общей структурной схемой (рис.2), общие модельные и алгоритмические решения для которой изображены на рис. 3.

Рисунок 2. Структурная схема системы автоматизированного анализа эмоциональной тональности
Очевидно, узким местом модели является способ определения количественных характеристик эмоционального насыщения контента. Параметр Str ( k ), отражающий силу k-ой эмоции, как представляется должен рассчитываться через числовые величины v ( Mrkm ), kprt , ksftи kmod ,подбираемые экспериментально экспертами-лингвистами и экспертами-психологами. Описанный в работе подход к автоматизации анализа эмоциональной тональности был реализован программно. Полученные экспериментальные результаты показали его применимость и результативность.
Рисунок 3. Модельные и алгоритмические решения в интересах построения автоматизированной системы анализа эмоциональной тональности
Перспективным направлением дальнейших исследований, как представляется, должно стать расширение функционала, позволяющее осуществлять вскрытие эмоционального фона контента не только через анализ морфолого-синтаксических характеристик, но и с учётом семантики и прагматики текстов. Здесь имеется в виду классическое определение этих разделов семиотики. Так, вскрытие семантических характеристик текстов предполагает выявление значений и смыслов, используемых в контенте символических конструкций, что, несомненно, потребует первичного и глубинного семантического анализа текстов с включением в систему таких дополнительных инструментов как модули анализа корреференций, структуры дискурса, далее семантической интерпретации с использованием лингвистической онтологии [3]. Полученные семантические характеристики могут лечь в основу прагматического анализа, вскрывающего намерения активной стороны коммуникации, а также возможные цели и соответствующие им процессы, активируемые пассивной стороной. Очевидно, между вскрываемой эмоциональной тональностью, семантическим и прагматическим наполнением должно присутствовать гармоническое единство, которое и будет являться главным доказательством правильности всех упомянутых результатов.
Литература 1. Апресян В.Ю. Русский и английские эмоциональные концепты // Труды международной конференции по компьютерной лингвистике и интеллектуальным технологиям / Диалог 2008, Протвино, 2008. С. 216–222. 2. ГрязнухинаТ. А., ДарчукН. П., Критская В. И., Маловица Н. П. и др. Синтаксический анализ научного текста на ЭВМ. Киев: Научная мысль, 1999. 3. Мительков Д.В., Новиков А.Ю., Сатин Б.Б. Способ и система семантической обработки текстовых документов. Заявка на изобретение.Российская Федерация: МПК G06F 17/27 - № 2016133365: заявл. 12.08.2016; опубл. 20.12.2016. Бюл. № 35. 4. Новиков А.Ю., Павленко А.В. Нейросетевой классификатор текстовых сообщений. Свидетельство о государственной регистрации программы для ЭВМ № 2016612566 от 2.03.2016г. 5. Плутчик К.К. Теория эмоций. Монография. М.: Наука, 1962.
References 1. Apresyan V.Y. Russian and English emotional concepts// Works of the International Conference on Computer Linguistics and Intellectual Technologies/ Dialog’ 2008, Protvino, 2008? с. 216–222. 2. Gryaznuhina T.A., Darchuk N.P., Kritsraya V.I.,Malovitsa N.P. and others. Syntactic analysis of a scientific text on a computer.- Kiev: Scientific thought, 1999. 3. Mitel`kov D.V., Novikov A.Iu., Satin B.B. Method and system of semantic processing of text documents. Application for an invention. Russian Federation. MPK G06F 17/27 - № 2016133365: 12.08.2016; published 20.12.2016, byul. № 35. 4. Novikov A.Iu., Pavlenko A.V. Neural network classifier of text messages. Sertificateof state registration of the program of a computer program № 2016612566 2.03.2016. 5. Plutchek K.K. Theory of emotions. Monograph. – M.: The Science, 1962.
|
Последнее изменение этой страницы: 2019-06-09; Просмотров: 339; Нарушение авторского права страницы