|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Обоснование актуальности разработки системы анализа эмоциональной тональности текстовых материалов
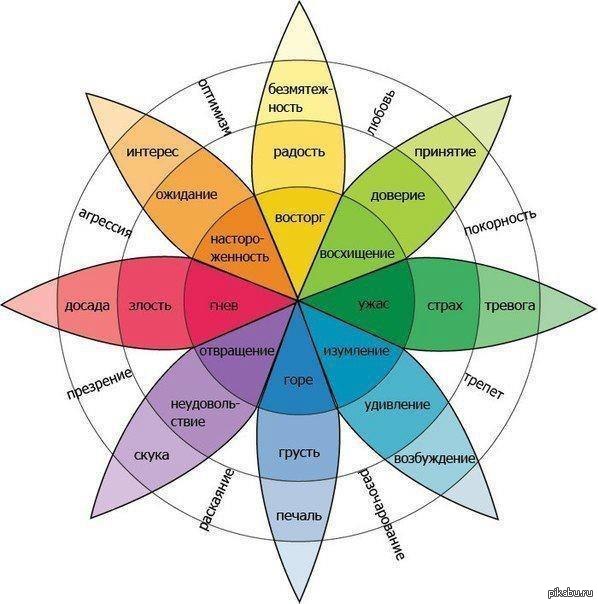
Под тональностью понимается эмоциональная оценка, выраженная в тексте по отношению к некоторой сущности в целом или её частям/свойствам/характеристикам. В качестве видов оценок тональности принято использовать двоичную (+/-), троичную (+/-/0), а также оценку по некоторой шкале. Применяется оценка тональности для анализа отзывов/мнений о персонах, политических партиях, товарах, компаниях и др. Раскрытие данной коммуникационной характеристики (эмоционального отношения автора к предмету высказываний) предполагает некоторое предварительное рассуждение. Дело в том, что мир эмоций чрезвычайно разнообразен и прежде, чем судить об эмоциональном отношении автора к описываемым им же событиям, необходимо это разнообразие определить и систематизировать. Лучшим результатом в данной области, по нашему мнению, является «колесо эмоций» Плутчека (рис.1) [5].
Рисунок 1. Колесо эмоций Плутчека
Очевидно, каждый лепесток систематизирует один класс эмоций, упорядочивая членов класса по степени силы вкладываемой в них энергии. Возможно сопоставить каждому такому классу некоторую совокупность лингвистических маркеров, синтаксических и семантических характеристик, указывающих на проявление соответствующей эмоции. На базе такого сопоставления можно построить процедуры обработки контента, например, для следующей прикладной задачи. Проводится исследование определённого источника или группы источников информации. Фиксируется конкретная тематика исследуемого контента. По результатам анализа информационного фона в контентах этого (этих) источника строится трёхмерный график в осях: время (горизонтальная ось), наименование эмоции (дискретно по перспективе) и сила эмоции (вертикальная ось). Соответствующие процедуры обеспечат визуализацию динамики в проявлении типов эмоций и их силы в интервале, например, один месяц (или год, или иное), что позволит соответствующим аналитикам сделать выводы о смене настроений в отношении той или иной тематики среди авторов рассматриваемого источника (источников) контента. К выявлению эмоционального фона ЕЯ-текстов в зависимости от конкретных потребностей аналитических служб могут предъявляться различные требования: · оценка текстового контента в целом; · оценка текстового контента в отношении предмета (предметов) интереса аналитических служб; · оценка тональности не одного текстового сообщения, а потока таковых, исходящего от конкретного (конкретных) лица, организации, сообщества и т.д.; · предыдущий вариант, реализованный с учётом возможности выбора тематической направленности контента; · любое из перечисленного относительно определённого временного периода для анализа тенденций; · любое из перечисленного с графическим отображением динамики изменения силы эмоций. Очевидно, интеграция последних четырёх вариантов требований в контексте проведения измерений в шкале отношений является наиболее точным и, следовательно, предпочтительным пожеланием к автоматизаторам. Таким образом, возможно сформулировать постановку задачи оценки тональности, как представляется, наиболее значимую в современных условиях, которая выглядит следующим образом: создать методную, алгоритмическую и инструментальную поддержку деятельности аналитика, специализирующегося на исследовании медиа-контента и социальных сетей, позволяющую: 1) формулировать полнотекстовый запрос в форме утверждения некоторого факта или тематически связной системы фактов, очерчивающий тематику исследований; 2) обеспечивать формирование тематического кластера текстовых материалов; 3) формировать список функциональных ролей, или игроков (субъект действия, собственно действие, объект действия), автоматически определяя их по структуре предложений запроса, а также список атрибутов отобранных игроков, собственно и определяющих эмоциональное отношение автора контента именно к этим игрокам; 4) выбирать список требуемых эмоций, информация о наличии которых представляет интерес; 5) измерять величину отобранных эмоций по поводу игроков, входящих в сформированный ранее список, в шкале отношений, суммируя их по всем текстовым материалам требуемого тематического кластера; 6) отображать полученные результаты в удобной для аналитика форме с широким спектром возможностей настройки: по периоду времени, по отображаемым эмоциям и др. Такая поддержка позволила бы получать оперативную информацию, например, об отношении соответствующих информационных агентств или социальных групп (слоёв) к различным событиям, ситуациям, мнениям и т.п. В настоящее время крупные компании, к примеру, ООО «ЭР СИ О» (RCO), ABBYY и другие вплотную занимаются программными продуктами, главная задача которых – лингвистическая обработка неструктурированной информации. Рассмотрим краткие описания популярных систем анализа тональности текста. A. SentiStrengh Система, разработана M. Thelwall, K. Buckley, G. Paltoglou и D. Cai. Первоначально, данная система была разработана для анализа коротких неструктурированных неформальных текстов на английском языке. Однако она может быть сконфигурирована для работы с текстами на ряде других языков, в том числе и для текстов на русском языке. Результат выдается в виде двух оценок – оценка позитивной составляющей текста (по шкале от +1 до +5) и оценка негативной составляющей (по шкале от -1 до -5). Кроме того, существует возможность предоставления оценок в другом виде: · бинарная оценка (позитивный/негативный текст); · тернальная оценка (позитивный/негативный/нейтральный); · оценка по единой шкале от -4 до +4. Алгоритм основан на поиске максимального значения тональности в тексте для каждой шкалы (т.е. поиск слова с максимальной негативной оценкой и слова с максимальной позитивной оценкой). При работе алгоритма учитывается простейшее взаимодействие слов (например, слова-усилители повышают значение тональности для слова, на которое они действуют – «очень злой» будет иметь более негативную оценку, нежели просто «злой») и идиоматические выражения. Недостатки системы: хотя система может быть сконфигурирована для русского языка, реализованные в ней алгоритмы не учитывают его специфику, в том числе русскую морфологию, что приводит к ряду проблем. Например, для полноценной работы системы с русским языком необходимо в банке данных иметь все словоформы для каждого слова. Кроме того, система считает лишь общую тональность текста, не выделяя субъекты и объекты тональности. |
Последнее изменение этой страницы: 2019-06-09; Просмотров: 370; Нарушение авторского права страницы