
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Дедупликация передаваемых данных .
Дедупликация – это метод устранения избыточности информации, за счет исключения дублирующих копий повторяющихся блоков данных [6]. Рассмотрим механизм дедупликации. В процессе дедупликации выделяют следующие этапы [8]: · предварительная обработка входных данных; · фрагментация данных на блоки; · вычисление хэш-кодов; · аутентификация дубликатов; · формирование словаря; · процесс формирования выходной последовательности. При необходимости, данные предварительно обрабатываются. Возможны следующие виды предварительной обработки – анализ, нормализация, структурирование данных и другие виды подготовки данных к последующей обработке. На следующем этапе производится фрагментация данных на блоки. Это один из важных этапов дедупликации, так как число повторяющихся блоков данных меняется в зависимости от размера каждого блока. Необходимо, на основе предварительной обработки, выбрать такой размер блока данных, чтобы полученные блоки имели наибольшее количество дубликатов. Это позволяет максимально устранить избыточность данных. Эффективность дедупликации оценивают с помощью коэффициента дедупликации
где Существуют следующие методы деления данных на блоки [8]: · фрагментация с фиксированным размером – данные разбиваются на блоки равных размеров; · фрагментация с переменным размером – данные разбиваются на блоки переменной длины, размер которых зависит от определенных параметров или структуры данных (например, строка, предложение, абзац и другие); · динамическая фрагментация – процесс фрагментации выполняется динамически, данные считываются и обрабатываются без фиксируемых заранее параметров фрагментации, данные делятся на блоки случайных размеров; · объектовая фрагментация – весь объект (например, файл) рассматривается как единый блок для дальнейшей обработки. Данный вид фрагментации используется при кэшировании файлов. В общем случае количество создаваемых блоков
После фрагментации идет этап вычисления хэш-кодов. На данном этапе каждый созданный блок данных обрабатывается хэш-функцией, в результате которой вычисляется соответствующий хэш-код. Особенностью хэш-функции
Причем у одинаковых блоков данных значения хэш-кодов равны, но если в блоке данных изменить хотя бы один бит, то весь шестнадцатеричный хэш-код полностью изменится. Пусть
Это позволяет использовать вычисленные хэш-коды для эффективной аутентификации дублированных блоков данных среди множества всех принятых блоков. Эффективность в данном случае повышается за счет того, что длина хэш-кода меньше длины блока данных. В разных случаях используются различные хеш-функции. В табл. 1 показаны основные хэш-функции, используемые при дедупликации [8].
Таблица 1 Основные хэш-функции, используемые при дедупликации
Четвертый этап дедупликации – это аутентификация дубликатов. Вычисленные хэш-коды проверяются в словаре. Если хэш-код есть в словаре, то блок данных считается дубликатом, в противном случае уникальным, и в словарь заносится блок данных и его хэш-код. Наконец, из уникальных блоков данных и хэш-кодов, соответствующих дубликатам, формируется выходная последовательность. На приемной стороне аналогичным образом формируется словарь. При приеме информационного блока вычисляется его хэш-код, и они помещаются в словарь. При приеме хэш-кода информационный блок извлекается из словаря. Дублирующие блоки данных заменяют соответствующие хэш-коды и объединяются с уникальными блоками, вместе формируя исходные данные. Обобщенная схема работы процедур дедупликации сетевого потока показана на рис. 4.
Источник сообщения Канал связи Приемник сообщения
Рисунок 4. Обобщенная схема работы процедур дедупликации сетевого трафика
Эффект использования дедупликации зависит от характера передаваемых данных. Чем больше повторяющихся блоков данных, тем выше эффективность механизма уменьшения передаваемого объема данных. Максимальная эффективность дедупликации проявляется при передаче почти одинаковых данных разным пользователям. Примером таких данных может быть удаленное обновление программного обеспечения. Следует отметить, что изначально дедупликация применялась для хранения данных в больших хранилищах. Методы дедупликации для систем хранения и систем передачи данных по сети схожи, но имеют определенные отличия. Как и метод сжатия, дедупликация уменьшает фактический размер передаваемых по сети данных и, соответственно, требуемую ширину канала связи, при этом повышая общий объем неоптимизированного трафика. Кэширование файлов. Часто в процессе работы сетевых приложений передаются одни и те же версии файлов (обновление программ, резервное копирование).Использование кэширования позволяет эффективно сокращать объем сетевого трафика. Устройства кэширования размещаются как можно ближе к пользователю. При запросе файла пользователем, сначала проверяется его наличие в памяти устройства кэширования. Если файл есть, то он передается получателю без обращения к удаленному серверу. Файл передается по каналу связи, только если его нет в кэш-памяти. Таким образом, объем данных, передаваемых по наиболее узким каналам связи (WAN), уменьшается. Кэширование файлов является частным случаем дедупликации в случае файловой фрагментации данных. Схема работы устройств кэширования показана на рис. 5.
Рисунок 5. Схема работы устройств кэширования Оптимизация работы протокола TCP . Протокол TCP является протоколом транспортного уровня, основной задачей которого является передача данных между любой парой прикладных процессов, работающих в вычислительной сети. В настоящее время TCP является самым популярным протоколом транспортного уровня [9]. Протокол TCP имеет ряд особенностей. При организации связи он предварительно устанавливает соединение, в случае потери пакета данных осуществляет его повторный запрос, при получении двух копий одного пакета устраняет дублирование. Это позволяет гарантировать целостность передаваемых данных и уведомление отправителя о результатах передачи. В тоже время скорость передачи информации в протоколе TCP зависит от размера окна (поле данных в заголовке протокола TCP). При установлении соединения размер окна имеет минимальный размер, затем происходит постепенное увеличение размера окна, т.е. растет скорость передачи полезной нагрузки (информации). При потере пакетов данных протокол TCP вдвое уменьшает размер окна, что приводит к резкому падению скорости передачи информации. Если потерь пакетов нет, снова постепенно увеличивается размер окна, затем при потере пакета он вновь уменьшается вдвое. Данная особенность приводит к тому, что при наличии сравнительно небольшого количества потерь пакетов происходит значительное снижение скорости передачи информации. В этом случае доступная полоса пропускания используется неэффективно, т.е. канал связи всегда загружен частично. Для решения проблемы максимального заполнения полосы пропускания канала связи разработаны модификации протокола TCP. Модификация High- SpeedTCP [5] значительно быстрее увеличивает скорость передачи информации, а при потере пакета данных размер окна уменьшается незначительно. Также существуют модификации TCP Vegas, TCP-Jersey, FastTCP и другие. На рис. 6 показано заполнение доступной полосы пропускания канала различными версиями протокола TCP.
Рисунок 6. Сравнение заполнения доступной полосы протоколом ТСР и его модификацией High- SpeedTCP Кроме того, размер стандартного заголовка TCP/IP составляет 40 байтов, а в ходе каждого устанавливаемого соединения значительная часть полей заголовка остается постоянной [3]. Длина кадров TCP/IP ограничена размером 65535 байтов, но часто, в целях уменьшения влияния ошибок на пропускную способность, сетевое оборудование использует пакеты длиной до 576 байтов. Таким образом, размер заголовка оказывает значительное влияние при передаче данных по низкоскоростным линиям связи. Был предложен метод сжатия заголовков TCP/IP, который описан в спецификацииRFC 1144. Данный метод сжимает заголовки TCP/IP-пакетов до 4-5 байт. На передающей и приемной стороне запоминаются фиксированные значения полей заголовков и передаются только их изменения. Схема сжатия заголовков протоколов TCP/IP показана на рис. 7.
Рисунок 7. Сжатие заголовков протоколов TCP/IP
Оптимизация протокола TCP/IP уменьшает объем передаваемой служебной информации, т.е. фактически позволяет увеличить эффективную пропускную способность канала связи. |
Последнее изменение этой страницы: 2019-06-09; Просмотров: 403; Нарушение авторского права страницы
 (1).
(1). , (1)
, (1) – размер данных до дедупликации,
– размер данных до дедупликации,  – размер данных после дедупликации.
– размер данных после дедупликации. (2) зависит от размера блока
(2) зависит от размера блока  и общего размера входных данных до дедупликации
и общего размера входных данных до дедупликации  . (2)
. (2)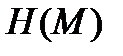 является вычисление фиксированного по длине уникального шестнадцатеричного хэш-кода h (3) для произвольного входного значения M
является вычисление фиксированного по длине уникального шестнадцатеричного хэш-кода h (3) для произвольного входного значения M . (3)
. (3) и
и  , тогда
, тогда , если
, если  и
и , если
, если 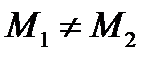 .
.


