
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Современное состояние и перспективы распознавания образовСтр 1 из 10Следующая ⇒
Содержание Введение 3 1. Современное состояние и перспективы распознавания образов. 9 1.1 Основные понятия. 9 1.2 Признаки образов. 11 1.3 Методы распознавания образов. 12 1.4 Статистические методы распознавания образов. 14 1.4.1 Введение в статистические методы. 14 1.4.2 Проверка статистических гипотез при распознавании образов. Вероятность ошибки при проверке гипотез. 16 1.4.3 Последовательная проверка гипотез. 23 1.4.4 Линейные классификаторы. 29 1.4.5 Оценивание параметров. 38 1.5.6 Оценивание вероятности ошибки. 46 1.5 Структурные методы в распознавании образов. 59 1.5.1 Введение. 59 1.5.2 Введение в формальные языки. 61 1.5.3 Типы распознающих устройств в системах синтаксического распознавания образов. 63 1.5.4 Модификации грамматик. 70 1.5.5 Языки описания образов. 73 1.6.6 Синтаксический анализ как распознающая процедура. 78 2. Описание системы опознавания. 86 2.1 Блок-схема системы опознавания. 86 2.2 Описание оптической системы. 88 2.3 Описание матрицы фотоэлементов. 91 2.4 Описание системы предварительной обработки. 92 2.5 Описание вычислительной системы. 96 2.6 Алгоритм распознавания. 98 2.6.1 Описание подклассов. 98 2.6.2 Описание признаков подклассов. 99 Заключение. 102 Литература. 104
Введение
В настоящее время перед вооружёнными силами различных государств возникла следующая проблема: несоответствие огневых возможностей современных образцов вооружения и возможностей систем, позволяющих дать более-менее достоверный ответ на вопрос о государственной принадлежности поражаемого объекта (систем опознавания). Дальность поражения превышает дальность действия систем опознавания, поэтому при ведении боя существует вероятность того, что поражаемый объект окажется принадлежащим к группировке союзных войск. Это значительно снижает боевую эффективность вооружения танковых и мотопехотных подразделений. В качестве примера можно привести следующий факт. В ходе операции «Буря в пустыне» войска США потеряли 20 БМП «Брэдли» и 9 танков «Абрамс». Из них 17 БМП и 7 танков были уничтожены огнем американских войск. Причиной столь частого ведения огня по своим машинам стало отсутствие прицелов, имеющих большую кратность увеличения и высокую разрешающую способность, тогда как основное вооружение танков и БМП было способно поражать цели за пределами дальности опознавания. Разумеется, в этом направлении ведутся исследования, имеются некоторые образцы систем боевого опознавания. В частности, предлагается совмещать прицел боевой машины с системой прямого опознавания, работающей по принципу «запрос-ответ». Однако такие системы имеют свои недостатки, основные из которых следующие: . Необходимо найти компромисс для величины диаграммы направленности излучателя, так как широкая диаграмма направленности запросного сигнала обуславливает его приём многими ответчиками и потенциально вызывает маскировку неотвечающих целей. В свою очередь, узкая диаграмма направленности означает возможность отсутствия приёма запросного сигнала, что влечёт за собой идентификацию априорно своих объектов как «чужих». . Ограниченная пропускная способность канала передачи информации не позволяет ответчикам принимать все запросные сигналы, что также может вызвать идентификацию своих объектов как «чужих». . Необходимо предусмотреть защиту от перехвата и расшифровки противником запросных и ответных сигналов и их имитации, поскольку это может означать демаскировку своего объекта. Приведённые недостатки говорят о том, что активная запросно-ответная система опознавания не является достаточным решением проблемы, поэтому необходима разработка пассивной системы опознавания, обрабатывающей оптическую информацию, поступающую с поля боя. Такая система свободна от перечисленных недостатков, так как она не излучает никаких сигналов, а лишь обрабатывает поступающие. Задача пассивного опознавания объектов на поле боя относится к задачам распознавания образов, т.е. присвоения распознаваемому объекту однозначного понятия или классификации объектов. Классов объектов в данной задаче всего два: классы своих и чужих объектов. Основные задачи построения систем распознавания.Система распознавания - сложная динамическая система, состоящая в общем случае из коллектива подготовленных специалистов и совокупности технических средств получения и обработки информации и предназначенная для решения задач распознавания соответствующих объектов и явлений на основе специально сконструированных алгоритмов. Каждая система распознавания приспособлена для распознавания только данного вида объектов и явлений. Перечислим основные задачи, возникающие при построении и проектировании системы распознавания [2]. Задача 1.Задача состоит в подробном и тщательном изучении объектов, для распознавания которых предназначена проектируемая система. Её цель - уяснить особенности изучаемых объектов и определить, что роднит и отличает их друг от друга. Задача 2.Эта задача заключается в проведении классификации распознаваемых объектов и явлений. Основное в данной задаче - выбор надлежащего принципа классификации. Этот принцип определяется требованиями, предъявляемыми к системе распознавания, которые, в свою очередь, зависят от того, какие решения могут приниматься по результатам распознавания системой неизвестных объектов и явлений. Задача 3.Эта задача состоит в составлении словаря признаков, используемого как для априорного описания классов, так и для апостериорного описания каждого неизвестного объекта или явления, поступающего на вход системы и подлежащего распознаванию. При разработке словаря признаков сталкиваются с рядом ограничений: ) В словарь могут быть включены только те признаки, относительно которых может быть получена априорная информация, достаточная для описания классов на языке этих признаков. Составленный из этих признаков словарь будем называть априорным. Другие признаки, которые либо совсем бесполезны, либо малополезны для разделения по классам, включать в словарь нецелесообразно. ) Наличие или возможность создания технических средств наблюдений, обеспечивающих на основе проведения экспериментов определение предварительно отобранных признаков. Эти ограничения часто превращают разработку словаря признаков в сложную задачу. При проектировании системы распознавания сначала на языке признаков априорного словаря производится описание классов и после выбора алгоритмов распознавания оценивается информативность каждого признака. В результате из рассмотрения исключаются наименее полезные признаки. Затем вновь формируется модель системы распознавания, и анализируются качества оставшейся части признаков. После этого, учитывая ограничения, накладываемые на создание технических средств получения апостериорной информации, окончательно решается вопрос о создании рабочего словаря признаков системы распознавания. Задача 4.Задача заключается в описании классов объектов на языке признаков. Она не имеет однозначного решения, и в зависимости от объёма априорной информации для её решения могут быть использованы методы непосредственной обработки исходных данных, обучения или самообучения. Рассмотрим суть данной задачи. Пусть в словаре содержится упорядоченный набор параметров объектов или явлений - признаки x 1, x 2, …, xN. Величины x 1, x 2, …, xN можно рассматривать как составляющие вектора x ={ x 1, x 2, …, xN }, характеризующего пространство признаков. Множество векторов x образует пространство признаков размерности N, а точки этого пространства представляют собой распознаваемые объекты. Пусть произведено разбиение объектов на классы C 1, C 2, , …, Cm. Требуется выделить в пространстве признаков области Di, i =1, 2, …, m, эквивалентные классам, т. е. характеризуемые следующей зависимостью: если объект характеризуется набором признаков x ={ x 1, x 2, …, xN } и относится к классу Ci, то представляющая его в пространстве признаков точка принадлежит области Di. Помимо геометрической, существует и алгебраическая трактовка задачи, которая состоит в следующем. Требуется построить разделяющие функции Fi ( x 1, x 2, …, xN ), i =1, 2, …, m, обладающие следующим свойством: если объект, имеющий признаки xo = { x 1 0, x 2 0, …, x 3 0 }, относится к классу Ci, то величина Fi ( x 1 0, x 2 0, …, xN 0 ) должна быть наибольшей. Она должна быть наибольшей и для всех других значений признаков объектов, относящихся к классу Ci.Если через xq обозначить вектор признаков объекта, относящегося к классу Cq, то для всех значений вектора xq Fq ( xq ) > Fp ( xp ), q, p = 1, 2, …, m, q ≠ p Таким образом, в признаковом пространстве системы распознавания граница разбиений, называемая решающей границей между областями Di, выражается уравнением Fq ( x ) - Fp ( x ) = 0
Выработка сведений о распознаваемых объектах и априорное описание классов - весьма трудоёмкая часть в решении классификационных задач, требующая глубокого изучения свойств этих объектов. Задача 5.Задача состоит в разработке алгоритмов распознавания, обеспечивающих отнесение рассматриваемых объектов к тому или иному классу. Алгоритмы распознавания основываются на сравнении той или другой меры близости (сходства) распознаваемого объекта с каждым классом. При этом, если выбранная мера близости L данного объекта ω с каким - либо классом Cp, p =1, 2, , , m, превышает меру его близости с другими классами, то принимается решение о принадлежности этого объекта классу Cp, т. е. ω L (ω, Cp) = max {L (ω, Ci)}, i = 1, 2, …, m Задача 6.Задача заключается в разработке специальных алгоритмов управления работой системы. Их назначение состоит в том, чтобы процесс функционирования системы распознавания был в определенном смысле оптимальным и выбранный критерий качества этого процесса достигал экстремального значения. В качестве подобного критерия может использоваться, например, вероятность правильного решения задачи распознавания, среднее время её решения, расходы, связанные с реализацией процесса распознавания и т. д. Достижение экстремальной величины названных критериев должно сопровождаться соблюдением некоторых ограничивающих условий. Например, минимизация среднего времени решения задачи должна осуществляться при условии достижения заданной вероятности правильного распознавания. Задача 7.Задача состоит в выборе показателей эффективности системы распознавания и оценке их значений. В качестве показателей эффективности могут рассматриваться вероятность правильного решения задачи распознавания, среднее время, затрачиваемое на её решение, расходы, связанные с реализацией процесса распознавания и т.д. Оценка значений выбранной совокупности показателей эффективности, как правило, проводится на основе экспериментальных исследований либо реальной системы распознавания, либо с помощью её физической или математической модели.
Основные понятия
В распознавании образов можно выделить 2 направления [1]: ) в узком смысле - автоматическое распознавание таких образов, которые могут распознаваться при помощи органов чувств. Это направление будем называть распознаванием на основе данных, воспринимаемых органами чувств (sense-data pattern recognition); ) в широком смысле - автоматическое распознавание всевозможных регулярностей, встречающихся, например, в данных научных исследований; распознавание этих регулярностей достигается в результате использования методов распознавания образов. При такой интерпретации образу соответствуют все типы регулярностей (порядок, структура), встречающихся в сложных данных. Это направление распознавания будем называть распознаванием на основе данных произвольного характера (general-data pattern recognition). Под образом (объектом) в системе распознавания понимается совокупность данных на входе системы. Данные могут быть представлены различным образом: это может видеоизображение, последовательность звуков, набор числовых характеристик и т.д. Каждый образ характеризуется набором признаков - величин, на основании которых система принимает решение о принадлежности объекта определённому классу. Класс в данном случае - группа образов, обладающих определённым признаком или значением признака, который (которое) отличает данную группу образов от других образов. Результат распознавания - классификация некоторого определенного объекта. Под классификацией в данном случае понимается присвоение рассматриваемому объекту надлежащего и однозначного понятия, т.е. сопоставление данному объекту одного из известных системе классов. Человеку в процессе классификации совсем не обязательно явным образом определять характерные признаки объекта, имеет значение только окончательный результат процесса наблюдения, восприятия и распознавания. Автоматические системы должны осуществлять такую же классификацию, как и человек, но они должны явным образом использовать характерные признаки объекта. Классы, возникающие в результате реализации процесса распознавания, могут быть дискретными (объект либо является, либо не является элементом класса), либо нечеткими (объектам ставятся в соответствие функции принадлежности классу). В случае нечетких классов некоторый объект может характеризоваться принадлежностью к одному или нескольким классам, значение которой может задаваться в пределах (0, 1). Подходы, основанные на нечетких понятиях, могут оказаться полезными для решения задач распознавания, если классы имеют нечеткий характер. Они могут также играть роль промежуточных средств при решении задач распознавания таких объектов, которые характеризуются принадлежностью к дискретным классам. В большинстве задач распознавания классы являются дискретными. Поэтому целесообразно изложить некоторые особенности распознавания образов применительно к такому случаю. Входная информация отличается определенной степенью сложности и вырабатывается некоторым реальным источником. Выходная информация сравнительно проста - она сводится к указанию класса. Существенным является то обстоятельство, что множество различных входных данных, поступающих от различных источников si 1, si 2, …, но несущих информацию об одном и том же образе ω , должны быть отображены в один и тот же класс Ci. Следовательно, распознавание образов представляет собой однозначное отображение. Это означает, что все входные данные, поступающие от si 1, si 2, …и подлежащие отображению в один и тот же класс, эквивалентны (хотя и различны) относительно соответствующего образа. На языке теории множеств это означает, что на множестве Si ={ si 1, si 2, …} должно существовать некоторое отношение эквивалентности « Si » .Отношением эквивалентности называется всякое отношение, обладающее свойствами рефлексивности, симметричности и транзитивности. Рефлексивность означает, что sii принадлежит к тому же классу, что и sii. Симметричность указывает, что если sii принадлежит к тому же классу, что и sij, то sij принадлежит к тому же классу, что и sii. Транзитивность означает, что если sii принадлежит к тому же классу, что и sij, а sij принадлежит тому же классу, что и sik, то sii и sik также принадлежат к одному и тому же классу. При распознавании образов можно ввести в систему механизм обучения, который сводится к следующему. Проектировщик системы для каждого из отличающихся друг от друга образов i задаёт примеры si 1, si 2, …, sin, причем каждому образу ставится в соответствие метка, указывающая класс Ci, к которому он принадлежит. Множество таких примеров называют обучающим множеством. В процессе обучения система должна научиться отображать входную информацию в «правильные» классы. Обучающее множество должно быть репрезентативно относительно всех возможных входных данных. Результат распознавания зависит также от размера обучающего множества. Признаки образов Двумя существенными проблемами в распознавании образов являются следующие: какие входные данные можно считать уместными и какая предварительная обработка исходных данных (обычно отличающихся чрезвычайной избыточностью) приводит к получению свойств или признаков, действительно позволяющих проводить классификацию. Так или иначе, при определении признаков используются априорные знания, интуиция, метод проб и ошибок, опыт. В зависимости от специфики задачи используется множество типов признаков. Некоторые признаки хорошо поддаются определению и легко интерпретируются на объектах (например, линейные размеры). Более сложные признаки основаны на форме, текстуре, статистических связях, разложении в ряд исходных данных. Когда признаки тем или иным образом выбраны, к ним можно применить формальную схему, которая заключается в использовании следующих двух отображений [1]: ) r 1: Si → Fi, обеспечивающее получение значений признаков Fi = { fi 1, fi 2, … } ) r 2: Fi → С i - процесс классификации, посредством которого входным данным ставятся в соответствие классы. Основная проблема распознавания - изменчивость образов. Входные данные, которые должны быть классифицированы как объекты одного класса, могут отличаться довольно сильно. Причин такой изменчивости множество [1]: 1) изменчивость, связанная с процессом измерения (шумы в датчиках); 2) изменчивость, связанная с каналами связи; ) изменчивость, свойственная собственно образам (объекты одного класса могут очень сильно отличаться друг от друга).
Линейные классификаторы
Выше было сказано, что байесовский классификатор отношения правдоподобия оптимален в том смысле, что он минимизирует риск или вероятность ошибки. Однако для получения отношения правдоподобия необходимо располагать для каждого класса условными плотностями вероятности. В большинстве приложений оценка этих плотностей осуществляется по конечному числу выборочных векторов наблюдений. Процедуры оценивания плотностей вероятности известны, но они являются либо очень сложными, либо требуют для получения точных результатов большого числа векторов наблюдений. В связи с этим имеет смысл рассмотреть более простые методы разработки классификаторов. Тем не менее, надо понимать, что байесовский классификатор во всех случаях является наилучшим, и никакой линейный классификатор не превосходит по качеству работы классификатор, полученный по критерию отношения правдоподобия. Наиболее простым и общим видом является линейный или кусочно-линейный классификатор. Байесовский линейный классификатор. Для двух нормально распределённых случайных величин байесовское решающее правило можно представить в виде квадратичной функции относительно вектора наблюдений x следующим образом:
где Σ i - корреляционные матрицы случайных величин, Mi - математические ожидания соответственно. Если корреляционная матрица равна единичной, то можно считать, что вектор x представляет собой наблюдение, искажённое белым шумом. Компоненты вектора x при этом некоррелированы и имеют единичную дисперсию, а байесовское решающее правило принимает вид
Произведение MT ix представляет собой коэффициент корреляции между векторами Mi и x. Легко видеть, что для принятия решения рассматриваемый классификатор сравнивает разность коэффициентов корреляции векторов x и М1 и x и M 2 с выбранным порогом. Следовательно, его можно назвать корреляционным классификатором [3]. Если умножить (1.29) на 2, а затем прибавить и вычесть xTx из левой части, то можно получить решающее правило
или
Полученному решающему правилу можно дать следующую интерпретацию: сравниваются расстояния между вектором x и векторами M 1 и M 2 с порогом. В общем случае, когда корреляционные матрицы не равны единичной, наблюдаемый шум коррелирован, и его часто называют «окрашенным». В этом случае байесовский классификатор так легко не интерпретируется. Однако по-прежнему целесообразно рассматривать в качестве решающего правила корреляционный классификатор или классификатор, основанный на вычислении расстояния. Для этого можно ввести декоррелирующее преобразование y = A x , которое переводит коррелированный («окрашенный») шум в белый: AΣ A T = I. (1.32)
Заметим, что пока корреляционная матрица Σ является положительно определённой, матрица A существует и невырождена. Поэтому декоррелирующее преобразование обратимо, и наблюдения вектора y можно классифицировать также эффективно, как и наблюдения вектора x [3]. Линейная разделяющая функция, минимизирующая вероятность ошибки решения. Линейные классификаторы представляют собой простейшие классификаторы, поскольку их реализация непосредственно связана со многими известными методами классификации, такими, как корреляционные методы или методы, основанные на вычислении евклидовых расстояний. Однако линейные классификаторы оптимальны в байесовском смысле только для нормальных распределений с равными корреляционными матрицами. Для некоторых приложений, таких, как выделение полезного сигнала в системах связи, равенство корреляционных матриц является приемлемым предположением, так как при изменении сигнала свойства шума существенно не изменяются. Однако во многих других приложениях распознавания образов предположение о равенстве ковариаций не оправдано. Предпринимались различные попытки разработки линейных классификаторов для нормальных распределений с неравными корреляционными матрицами и для распределений, отличных от нормального. Разумеется, эти классификаторы не являются оптимальными, однако во многих случаях их простота служит достаточной компенсацией ухудшения качества классификации. Рассмотрим методы создания линейных классификаторов для этих более сложных случаев. Так как оговорено, что независимо то вида распределений используется линейный классификатор, то решающее правило должно иметь вид
Выражение h ( x ) есть линейная разделяющая функция относительно x. Задача синтеза классификатора заключается в том, чтобы для заданных распределений определить коэффициенты VT =[ v 1, v 2, …, vn ] и значение порога v 0, оптимальные по различным критериям. Если случайная величина h ( x ) распределена по нормальному или близкому к нему закону, то для вычисления вероятности ошибки можно использовать её математическое ожидание и дисперсию для классов C 1 и C 2, а затем выбрать параметры V и v 0 так, чтобы минимизировать ошибку решения. Так как h ( x ) является суммой, состоящей из n слагаемых xi, приходим к выводу [3]: 1) если векторы x имеют нормальное распределение, то величина h ( x ) также имеет нормальное распределение; 2) даже если векторы x распределены не по нормальному закону, но при большом n выполнены условия центральной предельной теоремы, то распределение величины h ( x ) может быть близко к нормальному. Математические ожидания и дисперсии величины h ( x ) в классах C 1 и C 2 равны Mi = VTmi + v0, (1.34) σ 2 i = VT Σ i V. (1.35)
Поэтому вероятность ошибки можно записать следующим образом:
Если требуется минимизировать риск R, то вместо вероятностей P ( C 1 ) и P ( C 2 ) в формуле (1.36) должны быть использованы величины r 12 P ( C 1 ) и r 21 P ( C 2 ). При такой замене предполагается, что r 11 = r 22 = 0. Продифференцировав выражение (1.36) по параметрам V и v 0, получим, что
при этом h =0 и M 2 - M 1 = [( m 2 / σ 2 2 ) Σ 2 -( m 1 / σ 2 1 ) Σ 1 ]. Кусочно-линейные разделяющие функции. Линейные разделяющие функции находят широкое применение в задачах распознавания образов для случая двух классов, хотя при этом неизбежна некоторая потеря качества распознавания. Однако при трёх или более классах качество распознавания с использованием линейной разделяющей функции часто оказывается неприемлемым. Если в этих случаях воспользоваться совокупностью линейных разделяющих функций, т.е. воспользоваться кусочно-линейной разделяющей функцией, то появляются дополнительные возможности улучшения качества распознавания [3]. На рис. 6 изображён пример задачи распознавания для случая четырёх классов.
В задачах со многими классами критерии проверки многих гипотез дают наилучшее в байесовском смысле решающее правило, обеспечивающее минимум риска или вероятности ошибки. В соответствии с критерием проверки гипотез плотность вероятности или её логарифм следует сравнивать с плотностями вероятности других классов, как следует из (1.11). На рис. 6, а изображены полученные таким образом границы. Если оценивание плотностей вероятности является слишком сложной задачей или границы, определяемые в соответствии с критерием проверки гипотез, слишком “вычурные”, то можно заменить эти сложные границы множеством простых линейных границ. Такая замена, конечно, приводит к некоторому ухудшению качества распознавания. Однако использование линейных границ особенно эффективно для задач распознавания многих классов, т.е. в тех случаях, когда сложность границ быстро возрастает с увеличением числа классов, и является желательным некоторое упрощение процедуры синтеза классификатора [3]. На рис. 6, б показана замена байесовских границ кусочно-линейными границами. Множество линейных функций, соответствующее кусочно-линейной разделяющей функции, определяется следующим образом: hij(x) = VTijx + vi0, i, j = 1, 2, …, M, i ≠ j, (1.38)
где M - число классов. Знаки Vij выбираются так, чтобы распределение класса i находилось в области положительных значений линейной функции hij ( x ), а распределение класса j - в области отрицательных значений. Из этого требования следует, что hij ( x ) = hji ( x ). (1.39)
Предположим, что для каждого класса соответствующая область является выпуклой, как изображено на рис. 6, б, тогда область класса i может быть просто определена следующим образом: hi1(x) > 0, hi2(x) > 0, …, hiM(x) > 0 → x
(функция hii ( x ) исключена из рассмотрения). Наличие тёмной области на рисунке 6, б показывает, что M областей, определяемые условиями (390), не обязательно покрывают всё пространство. Если объект попадает в эту область, то кусочно-линейный классификатор не может принять решение о его принадлежности к определённому классу; эту область называют областью отказов. Решающее правило состоит из M -1 линейных разделяющих функций и логического элемента AND с M -1 входами, которые принимают значения sign { hij ( x )}. Соответствующая блок-схема изображена на рис. 7. Поскольку каждая из параллельных цепей состоит из двух последовательно соединённых элементов, то такой кусочно-линейный классификатор иногда называют двухслойной машиной. Если предположение о выпуклости областей не выполняется, то необходимо определить взаимные пересечения M -1 гиперплоскостей и строить решающее правило в соответствии с этими пересечениями. Однако при этом классификатор становится весьма сложным для решения практических задач.
Вероятность ошибки решения для каждого класса ε i можно выразить через ( M -1)-мерную функцию распределения вероятности:
(функция hii исключена из рассмотрения.). Тогда общая ошибка решения
Задача теперь состоит в том, чтобы определить значения V и v 0 для данного множества M распределений при наличии информации о структуре кусочно-линейного классификатора. Вследствие сложности этой задачи её решение не является таким наглядным, как для линейного классификатора. Кратко отметим несколько приближённых методов решения задачи [3]. 1) Можно подстраивать коэффициенты V и v 0 так, чтобы минимизировать вероятность ошибки решения ε , определяемую формулой (1.41). 2) Линейная разделяющая функция между парой классов строится с помощью одного из методов, рассмотренных ранее для случая распознавания двух классов. Вычисляются M ( M -1)/2 разделяющих функций. Эти функции без дальнейшей коррекции используются в качестве кусочно-линейной разделяющей функции. Если распределения являются нормальными с равными корреляционными матрицами, то описанная процедура эквивалентна применению байесовского решающего правила. Если распределения существенно отличаются между собой, то дальнейшая коррекция решающего правила может привести к уменьшению ошибки. Однако часто оказывается, что уменьшение ошибки за счёт подстройки параметров V и v 0 относительно невелико. Обобщенные линейные разделяющие функции. До сих пор были рассмотрены линейные разделяющие функции. Одна из причин этого заключается в том, что при высокой размерности наблюдаемых векторов только линейные или кусочно-линейные разделяющие функции дают приемлемый компромисс между качеством распознавания и простотой реализации. Другая важная причина состоит в том, что даже нелинейная разделяющая функция может быть интерпретирована в функциональном пространстве как линейная, т.е. выражение
представляет собой в функциональном пространстве линейную разделяющую функцию, где r переменных gi ( x ) заменяют n переменных x в исходном пространстве. Другим важным случаем является использование квадратичных поверхностей, где r переменных gi ( x ) задают так, что первыми n переменными являются x 2 i, i =1, 2, …, n, следующими n ( n -1)/2 - все пары xixj , i, j =1, 2, …, n, i ≠ j, а последние n переменных представляют собой x i, i =1, 2, …, n. Относительно этого преобразования можно сказать, что для каждой квадратичной разделяющей функции в пространстве x существует соответствующая линейная разделяющая функция в пространстве функций gj ( x ). Переменные gi ( x ) являются признаками. Выбор эффективной системы признаков представляет собой самостоятельный раздел теории распознавания образов. Оценивание параметров Как говорилось выше, если известны плотности вероятности классов, то для классификации объектов можно определить граничную поверхность, разделяющую пространство признаков на области. Следующий вопрос заключается в том, как по имеющейся выборке объектов оценить эти плотности вероятности? Эта задача является очень сложной, если нельзя сделать предположение о структуре многомерной плотности вероятности. Однако если можно задать вид этой функции, то задача сводится к определению конечного числа параметров. Для этого можно использовать известные статистические методы оценки параметров. Оценивание параметров плотностей вероятности известного вида и классификацию объектов на основе этих плотностей называют параметрическим методом классификации [3]. Первая задача, которая здесь возникает, заключается в оценке основных параметров плотностей вероятности, таких, как вектор математического ожидания, корреляционная матрица и т.д., в предположении, что эти параметры не являются случайными величинами. Далее следует рассмотреть случай, когда эти параметры - случайные величины. Такие задачи называют точечным оцениванием [3]. Другой важный вопрос в распознавании образов - оценка вероятности ошибок решения и отношения правдоподобия. Поскольку вероятности ошибок и отношение правдоподобия представляют собой сложные функции относительно параметров, непосредственное применение для них стандартных методов оценивания не даёт приемлемых результатов. Поэтому имеет смысл рассмотреть методы оценивания этих величин по имеющимся выборочным данным. Оценивание неслучайных параметров. Пусть Θ и
где Оценка |
Последнее изменение этой страницы: 2020-02-16; Просмотров: 263; Нарушение авторского права страницы
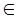 Cp, если
Cp, если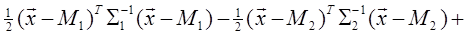
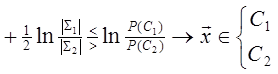 , (1.28)
, (1.28)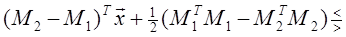
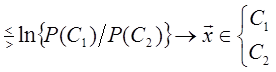 . (1.29)
. (1.29)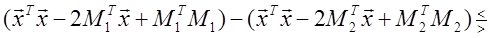
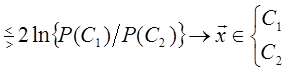 , (1.30)
, (1.30)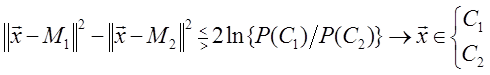 . (1.31)
. (1.31)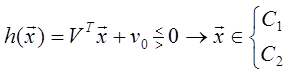 . (1.33)
. (1.33)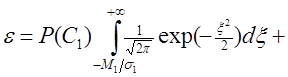
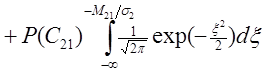 . (1.36)
. (1.36)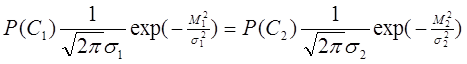 , (1.37)
, (1.37)
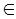 C1 (1.40)
C1 (1.40)
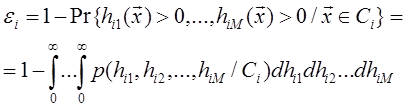 (1.41)
(1.41)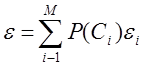 . (1.42)
. (1.42)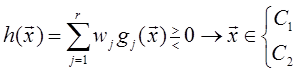 (1.43)
(1.43)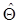 - соответственно истинный вектор параметров и его оценка. Значение
- соответственно истинный вектор параметров и его оценка. Значение 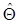 есть функция от наблюдаемых случайных векторов x 1, x 2, …, xN, т.е.
есть функция от наблюдаемых случайных векторов x 1, x 2, …, xN, т.е.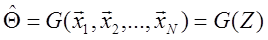 , (1.44)
, (1.44)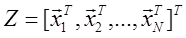 .
.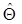 называется несмещённой оценкой параметра Θ , если её математическое ожидание равно и
называется несмещённой оценкой параметра Θ , если её математическое ожидание равно и