
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Оценивание вероятности ошибки
Вероятность ошибки является основным показателем качества распознавания образов, и поэтому её оценивание представляет собой очень важную задачу. Вероятность ошибки есть сложная функция, представляющая собой n-кратный интеграл от плотности вероятности при наличии сложной границы. Поэтому при её вычислении часто приходится обращаться к экспериментальным методам. При оценке вероятности ошибки рассматривают две задачи. Первая из них состоит в оценивании вероятности ошибки по имеющейся выборке в предположении, что задан классификатор [3]. Вторая задача заключается в оценке вероятности ошибки при заданных распределениях. Для этой ошибки вероятность ошибки зависит как от используемого классификатора, так и от вида распределения. Поскольку в распоряжении имеется конечное число объектов, нельзя построить оптимальный классификатор. Поэтому параметры такого классификатора представляют собой случайные величины [3]. Оценка вероятности ошибки для заданного классификатора. 1) Неизвестны априорные вероятности - случайная выборка. Предположим, что заданы распределения обоих классов и классификатор. Задача заключается в оценивании вероятности ошибки по N объектам, полученным в соответствии с этими распределениями. Когда неизвестны априорные вероятности P ( Ci ), i =1, 2, то можно случайно извлечь N объектов и проверить, даёт ли данный классификатор правильные решения для этих объектов. Такие объекты называют случайной выборкой. Пусть τ - число объектов, неправильно классифицированных в результате этого эксперимента. Величина τ есть дискретная случайная величина. Обозначим истинную вероятность ошибки через ε . Распределение значений величины τ является биномиальным:
Оценка максимального правдоподобия
т.е. оценка максимального правдоподобия равна отношению числа неправильно классифицированных объектов к общему числу объектов. Математическое ожидание и дисперсия биномиального распределения соответственно равны
Таким образом, оценка ) Известны априорные вероятности - селективная выборка. Если известны априорные вероятности классов P ( Ci ), i =1, 2, то можно извлечь N 1 = P ( C 1 ) N и N 2 = P ( C 2 ) N объектов соответственно и проверить их с помощью заданного классификатора. Такой процесс известен как селективная выборка. Пусть τ 1 и τ 2 - число неправильно классифицированных объектов соответственно из классов C 1 и C 2. Поскольку τ 1 и τ 2 взаимно независимы, то совместная плотность вероятности τ 1 и τ 2 будет равна
где ε i - истинная вероятность ошибки для класса Ci. В этом случае оценка максимального правдоподобия равна
Математическое ожидание и дисперсия оценки соответственно
Таким образом, оценка (1.69) также несмещённая. Нетрудно показать, что дисперсия (1.71) меньше, чем дисперсия (1.67). Это естественный результат, поскольку в случае селективной выборки используется априорная информация. Изложенное выше легко обобщить на случай M классов. Для этого надо лишь изменить верхние пределы у сумм и произведений в формулах (1.68) - (1.71) с 2 на M. Оценка вероятности ошибки, когда классификатор заранее не задан. Когда даны N объектов в случае отсутствия классификатора, то можно использовать эти объекты как для проектирования классификатора, так и для проверки его качества. Очевидно, оцениваемая вероятность ошибки зависит от данных распределений и используемого классификатора. Предположим, что всегда используется байесовский классификатор, минимизирующий вероятность ошибки. Тогда минимальную вероятность ошибки байесовского классификатора, которую необходимо оценить, можно рассматривать как фиксированный параметр при заданных распределениях. Кроме того, эта вероятность является минимальной для данных распределений. Как правило, вероятность ошибки есть функция двух аргументов: ε ( Θ 1, Θ 2 ), (1.72)
где Θ 1 - множество параметров распределений, используемых для синтеза байесовского классификатора, а Θ 2 - множество параметров распределений, используемых для проверки его качества. Оптимальная классификация объектов, характеризуемых распределением с параметром Θ 2, осуществляется байесовским классификатором, который построен для распределения с параметром Θ 2. Поэтому ε ( Θ 2, Θ 2 ) ≤ ε ( Θ 1, Θ 2 ). (1.73) Пусть для данной задачи Θ - вектор истинных параметров, а
Выполнив над обеими частями неравенств (1.74) и (1.75) операцию математического ожидания, получим
Если
то для вероятности ошибки байесовского классификатора имеет место двустороннее ограничение
Левое неравенство (1.79) основано на предположении (1.78) и не доказано для произвольных истинных плотностей вероятности. Однако это неравенство можно проверить многими экспериментальными способами. Из выражения (1.5) видно, что равенство (1.78) выполняется тогда, когда оценка проверяемой плотности вероятности, основанная на N наблюдениях, является несмещённой и классификатор заранее фиксирован. Следует отметить, что нижняя граница менее важна, чем верхняя. Обе границы вероятности ошибки ) ) Для реализации U-метода имеется много возможностей. Рассмотрим две типовые процедуры. . Метод разбиения выборки. Вначале имеющиеся объекты разбивают на две группы и используют одну из них для синтеза классификатора, а другую - для проверки его качества. Основной вопрос, характерный для этого метода, заключается в том, как разделить объекты. . Метод скользящего распознавания. Во втором методе попытаемся использовать имеющиеся объекты более эффективно, чем в методе разбиения выборки. Для оценки Метод разбиения выборки. Для того, чтобы разбить имеющиеся объекты на обучающую и экзаменационную выборки, изучим, как это разбиение влияет на дисперсию оценки вероятности ошибки. Вначале предположим, что имеется бесконечное число объектов для синтеза классификатора и N объектов для проверки его качества. При бесконечном числе объектов синтезируемый классификатор является классификатором для истинных распределений, и его вклад в дисперсию равен нулю. Для фиксированного классификатора организуем селективную выборку. В этом случае распределение оценки подчиняется биномиальному закону с дисперсией
где ε i - истинная вероятность ошибки для i-го класса. С другой стороны, если имеется N объектов для синтеза классификатора и бесконечное число экзаменационных объектов, то оценка вероятности ошибки выражается следующим образом:
где Γ i - область пространства признаков, соответствующая i-му классу. В этом случае подынтегральные выражения постоянны, но граница этих областей изменяется в зависимости от выборки из N объектов. Дисперсию оценки
где η i и σ 2 i определяются условными математическими ожиданиями:
Это преобразование основано на том, что для нормальных распределений с равными корреляционными матрицами байесовский классификатор - линейный, а распределение отношения правдоподобия также является нормальным распределением. Следует заметить, что даже если две истинные корреляционные матрицы равны, то оценки их различны. Однако для простоты предположим, что обе эти оценки равны и имеют вид
где Ni - число объектов x ( i ) j класса i, используемых для синтеза классификатора. Выражение для математического ожидания оценки
где d - расстояние между двумя векторами математических ожиданий, определяемое по формуле
Величина ε 0 является минимальной вероятностью ошибки байесовского классификатора. Так как ε 0 - минимальное значение оценки
при Δ ε > 0 (b ≥ 0 иc > 0). Математическое ожидание и дисперсия плотности вероятности (1.89) соответственно равны
Исключив c, получим верхнюю границу дисперсии
при b ≥ 0. Таким образом, степень влияния числа обучающих объектов на оценку вероятности ошибки ε 0 в случае нормальных распределений с равными корреляционными матрицами и равными априорными вероятностями равна
Величину s эксп следует сравнивать с величиной s теор, которая характеризует влияние числа объектов в экзаменационной выборке на оценку вероятности ошибки. Значение s теор получается подстановкой в формулу (1.80) значений P ( C 1 ) = P ( C 2 ) =0.5 и ε 1 = ε 2 = ε 0:
Исключение задания класса для объектов экзаменационной выборки. Для того, чтобы оценить вероятность ошибки как при обучении, так и на экзамене, требуются выборки объектов, в которых известно, какой объект к какому конкретному классу принадлежит. Однако в некоторых случаях получение такой информации связано с большими затратами. Рассмотрим метод оценки вероятности ошибки, не требующий информации о принадлежности объектов экзаменационной выборки к конкретному классу. Применение этого метода наиболее эффективно в случае, когда при оптимальном разбиении выборки на обучающую и экзаменационную число объектов в экзаменационной выборке больше, чем в обучающей. Введём критическую область для задач классификации M классов:
где P ( x ) - плотность вероятности смеси, t - критический уровень, 0 ≤ t ≤ 1. Условие (1.94) устанавливает, что если для данного объекта x значения P ( C 1 ) p ( x / C 1 ), вычисленные для каждого класса Mi, не превышают величины (1- t ) p ( x ), то объект х не классифицируют вообще; в противном случае объект x классифицируют и относят его к i-му классу. Таким образом, вся область значений x делится на критическую область Γ r ( t ) и допустимую область Γ a ( t ), причём размеры обеих областей являются функциями критического уровня t. При таком решающем правиле вероятность ошибки ε ( t ), коэффициент отклонения r ( t ) и коэффициент правильного распознавания c ( t ) будут равны
ε ( t ) = 1 - c ( t ) - r ( t ). (1.97)
Предположим, что область отклонения увеличивается на Γ r ( t ) за счёт замены значения t на t -Δ t. Тогда те x, которые раньше классифицировались правильно, теперь отклоняются:
при x (1 - t ) Δ r ( t ) ≤ - Δ c ( t ) < (1 - t + Δ t ) Δ r ( t ), (1.99)
где Δ r ( t ) и Δ c ( t ) - приращения r ( t ) и c ( t ), вызванные изменениями t. Из формулы (1.97) следует, что неравенство (1.99) можно переписать следующим образом: tΔ r ( t ) ≤ Δ ε ( t ) < - Σ ( t - Δ t ) Δ r ( t ). (1.100)
Полагая Δ t→ 0, получаем интеграл Стилтьеса
Уравнение (1.101) показывает, что вероятность ошибки ε ( t ) может быть вычислена после того, как установлена зависимость между значениями t и r ( t ). Из решающего правила (1.94) следует, что при t = 1-1/ M область отклонения отсутствует, так что байесовская ошибка ε 0 = ε (1-1/ M ). Кроме того, из формулы (1.101) можно установить взаимосвязь между вероятностью ошибки и коэффициентом отклонения, так как изменение вероятности ошибки можно вычислить как функцию от изменения коэффициента отклонения. Воспользуемся выражением (1.94) для исключения задания класса объектов экзаменационной выборки. Для этого поступим следующим образом. 1. Для определения Δ Γ r ( kt 0 ) при t = kt 0, k = 0, 1, …, m = (1-1/ M ) t 0, где t 0 - дискретный шаг переменной t, будем использовать относительно дорогостоящие классифицируемые объекты. 2. Подсчитаем число неклассифицированных объектов экзаменационной выборки, которые попали в область Δ Γ r ( kt 0 ), разделим это число на общее число объектов и обозначим полученное соотношение через Δ r ( kt 0 ). . Тогда из выражения (1.94) следует, что оценка вероятности ошибки
В описанной процедуре использовалось то, что коэффициент отклонения является функцией от плотности вероятности смеси, а не от плотностей вероятности отдельных классов. Поэтому после того, как по классифицированным объектам найдены расширенные области отклонения, в дальнейшем для оценивания Δ r ( t ) и вероятности ошибки ε ( t ) нет необходимости использовать классифицированные объекты.
|
Последнее изменение этой страницы: 2020-02-16; Просмотров: 354; Нарушение авторского права страницы
 . (1.64)
. (1.64) из уравнения (1.56) равна
из уравнения (1.56) равна , (1.65)
, (1.65) , (1.66)
, (1.66) . (1.67)
. (1.67) , (1.68)
, (1.68) . (1.69)
. (1.69) , (1.70)
, (1.70) . (1.71)
. (1.71) - его оценка. Таким образом, оценка
- его оценка. Таким образом, оценка  является случайным вектором и ε 0 =ε (Θ, Θ ). Для любого конкретного значения
является случайным вектором и ε 0 =ε (Θ, Θ ). Для любого конкретного значения  оценки
оценки  , (1.74)
, (1.74) . (1.75)
. (1.75)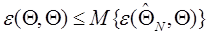 , (1.76)
, (1.76) . (1.77)
. (1.77) , (1.78)
, (1.78) . (1.79)
. (1.79) можно интерпретировать следующим образом:
можно интерпретировать следующим образом: 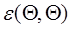 : одни и те же N объектов используются и для синтеза байесовского классификатора, и для последующей классификации. Этот случай назовём C-методом. Из (1.79) следует, что C-метод даёт, вообще говоря, заниженную оценку вероятности ошибки.
: одни и те же N объектов используются и для синтеза байесовского классификатора, и для последующей классификации. Этот случай назовём C-методом. Из (1.79) следует, что C-метод даёт, вообще говоря, заниженную оценку вероятности ошибки. : для синтеза байесовского классификатора используются N объектов, а классифицируются объекты из истинных распределений. Эту процедуру называют U-методом. U-метод также даёт смещённую оценку вероятности ошибки ε 0. Это смещение таково, что его математическое ожидание является верхней границей вероятности ошибки. Объекты из истинного распределения могут быть заменены объектами, которые не были использованы для синтеза классификатора и независимы от объектов, по которым классификатор был синтезирован. Когда число классифицируемых объектов увеличивается, их распределение стремится к истинному распределению.
: для синтеза байесовского классификатора используются N объектов, а классифицируются объекты из истинных распределений. Эту процедуру называют U-методом. U-метод также даёт смещённую оценку вероятности ошибки ε 0. Это смещение таково, что его математическое ожидание является верхней границей вероятности ошибки. Объекты из истинного распределения могут быть заменены объектами, которые не были использованы для синтеза классификатора и независимы от объектов, по которым классификатор был синтезирован. Когда число классифицируемых объектов увеличивается, их распределение стремится к истинному распределению. необходимо, вообще говоря, извлечь много выборок объектов и синтезировать большое количество классификаторов, проверить качество каждого классификатора с помощью неиспользованных объектов и определить среднее значение показателя качества. Подобная процедура может быть выполнена путём использования только имеющихся N объектов следующим образом. Исключая один объект, синтезируется классификатор по имеющимся N -1 объектам, и классифицируется неиспользованный объект. Затем эту процедуру повторяют N раз и подсчитывают число неправильно классифицированных объектов. Этот метод позволяет более эффективно использовать имеющиеся объекты и оценивать
необходимо, вообще говоря, извлечь много выборок объектов и синтезировать большое количество классификаторов, проверить качество каждого классификатора с помощью неиспользованных объектов и определить среднее значение показателя качества. Подобная процедура может быть выполнена путём использования только имеющихся N объектов следующим образом. Исключая один объект, синтезируется классификатор по имеющимся N -1 объектам, и классифицируется неиспользованный объект. Затем эту процедуру повторяют N раз и подсчитывают число неправильно классифицированных объектов. Этот метод позволяет более эффективно использовать имеющиеся объекты и оценивать  . Один из недостатков этого метода заключается в том, что приходится синтезировать N классификаторов.
. Один из недостатков этого метода заключается в том, что приходится синтезировать N классификаторов. , (1.80)
, (1.80) , (1.81)
, (1.81) вычислить сложно. Однако в случае нормальных распределений с равными корреляционными матрицами интегралы в (1.81) можно привести к одномерным интегралам
вычислить сложно. Однако в случае нормальных распределений с равными корреляционными матрицами интегралы в (1.81) можно привести к одномерным интегралам , (1.81)
, (1.81) , (1.82)
, (1.82) , (1.83)
, (1.83)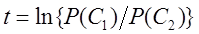 . (1.84)
. (1.84) , (1.85)
, (1.85) достаточно громоздкое, здесь приводится простейший случай, когда P ( C 1 )= P ( C 2 ) и N 1 = N 2:
достаточно громоздкое, здесь приводится простейший случай, когда P ( C 1 )= P ( C 2 ) и N 1 = N 2:  , (1.86)
, (1.86)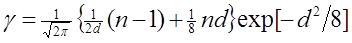 , (1.87)
, (1.87) . (1.88)
. (1.88) является причинным. Поэтому можно определить оценку дисперсии величины
является причинным. Поэтому можно определить оценку дисперсии величины  (1.89)
(1.89) , (1.90)
, (1.90) . (1.91)
. (1.91) (1.91)
(1.91) . (1.92)
. (1.92) . (1.93)
. (1.93)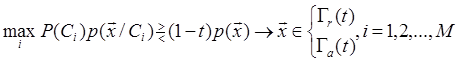 , (1.94)
, (1.94) , (1.95)
, (1.95) , (1.96)
, (1.96) (1.98)
(1.98)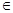 Δ Γ r ( t ). Интегрируя (1.98) в пределах области Δ Γ r ( t ), получим
Δ Γ r ( t ). Интегрируя (1.98) в пределах области Δ Γ r ( t ), получим . (1.101)
. (1.101) . (1.102)
. (1.102)