
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Типы распознающих устройств в системах синтаксического распознавания образов
Автоматные языки и конечные автоматы. Конечный (детерминированный) автомат - пятёрка A =( Σ , Q, δ , q 0, F ), где Σ - конечное множество входных символов (алфавит), Q - конечное множество состояний, δ - функция, определяющая следующее состояние, т.е. отображение Q × Σ в Q, q 0 δ (q, λ ) = q, δ (q, xa) = δ ( δ (q, x), a), x
Таким образом, δ ( q, λ ) = q ’ понимается так: находясь в состоянии q, автомат A просматривает цепочку x на входной ленте и переходит в состояние q ’, а считывающее устройство смещается вперёд с той части входного потока, которая содержит x. Говорят, что цепочка, или предложение x, допускается автоматом A, если δ ( q, λ ) = p для некоторого p
Множество цепочек, допускаемых A, определяется как T ( A ) = { x | δ ( q 0, x )
Недетерминированный конечный автомат есть пятёрка A = ( Σ , Q, δ , q 0, F ), где Σ - конечное множество входных символов (алфавит), Q - конечное множество состояний, δ - отображение Q × Σ во множество подмножеств множества Q, q 0 - начальное состояние и F - множество заключительных состояний. Единственная разница между детерминированным и недетерминированным вариантами автомата состоит в том, что δ ( q, a ) обозначает множество состояний (возможно, пустое), а не обязательно единственное состояние. Отображение δ ( q, a ) = ( q 1, q 2, …, ql ) интерпретируется следующим образом: автомат в состоянии q, читая на входе символ a, выбирает в качестве следующего любое из состояний q 1, q 2, …, ql, и сдвигает считывающее устройство на один символ вперёд. Как и в случае детерминированного автомата, отображение δ можно распространить с одного входного символа на цепочку, определив δ (q, λ ) = q, δ (q, xa) =
Далее можно определить δ ( { q 1, q 2, …, ql }, x ) = Цепочка x допускается недетерминированным автоматом A, если найдётся такое состояние p, что p
Множество цепочек, допускаемых автоматом A, определяется как T (A) = {x| p
Доказано, что если имеется недетерминированный конечный автомат A, который допускает множество цепочек L, то существует детерминированный конечный автомат A ’, который допускает L. Поэтому в дальнейшем, если в этом не будет необходимости, и те и другие автоматы будут называться просто конечными автоматами [4]. Бесконтекстные языки и магазинные автоматы. Магазинный автомат определяется как семёрка M = (Σ, Q, Γ , δ, q 0, Z 0, F ), где Σ - конечное множество входных символов, Q - конечное множество состояний, Γ - конечное множество магазинных символов, q 0 Устройство магазинного автомата близко к устройству конечного автомата, но он снабжён дополнительной магазинной памятью. Магазинная память организована по стековому принципу, т.е. символы можно вводить или считывать только на вершину и с вершины магазинной памяти [4]. Отображение δ ( q, aZ ) = {( q 1, γ 1 ), , …, ( qm, γ m )}, q 1, …, qm интерпретируется следующим образом: магазинный автомат, находясь в состоянии q, считывает входной символ a и верхний символ магазина Z, переходит в состояние qi, заменяя в магазине памяти символ Z на символ γ i, 1≤ i ≤ m, и продвигает устройство считывания на один символ. Запись δ ( q, λ , Z ) = {( q 1, γ 1 ), ( q 2, γ 2 ), …, ( qm, γ m )} (2.12)
означает, что магазинный автомат в состоянии qi при верхнем символе в магазине Z независимо от считываемого входного символа перейдёт в состояние qi и заменит Z на γ i, 1 ≤ i ≤ m. В этом случае считывающее устройство не работает. Такая операция используется для изменения содержания магазина и обычно называется λ -движением. Для описания “ситуации” магазинного автомата используется упорядоченная пара ( q, γ ), q a ( q, Zγ )
означает, что по правилам перехода данного автомата M входной символ a может вызвать переход M из ситуации ( q, Zγ ) в ситуацию ( q ’, β γ ). Если для символов a 1, a 2, …, an, ai a: (qi, γ i )
то пишется a1a2…an: (q1, γ 1 )) Допускаемые магазинными автоматами языки определяются двумя способами. Для магазинного автомата M язык T ( M ), допускаемый при помощи заключительного состояния, определяется как T ( M ) = { x | x: ( q 0, Z 0 )
С другой стороны, язык N ( M ), допускаемый M при пустом магазине, определяется как N ( M ) = { x | x: ( q 0, Z 0 )
Если язык допускается автоматом при пустом магазине, то множество заключительных состояний автомата M не используется. В этом случае обычно принимается F = Ø . Языки, допускаемые магазинными автоматами при пустом магазине, являются бесконтекстными [4]. Машины Тьюринга. Машина Тьюринга - шестёрка T = ( Σ , Q, Γ , δ , q 0, F ), где Q - конечное множество состояний, Γ - конечное множество символов на входе, один из которых - пустой символ B. В начале работы n крайних левых полей на входе машины содержат символы входной цепочки (n - конечное число). Оставшееся бесконечное число полей заполнено специальным символом B - символом «пустое место», который не является входным. Подмножество Σ Разница между машиной Тьюринга и конечным автоматом состоит в том, что машина Тьюринга может изменять содержимое полей на входе при помощи своей читающей-пишущей головки. Ситуация машины Тьюринга задаётся тройкой ( q, α , i ), где q (q, A1A2…An, i)
Это означает, что машина Тьюринга записывает в i-ю клетку символ X и сдвигает головку на одно поле вправо. Если же δ (q, Ai) = (p, X, L), 2≤ i≤ n, то (q, A1A2…An, i)
В этом случае машина Тьюринга записывает символ X в i-ю клетку и сдвигает головку на одно поле влево, но не левее левого конца ленты. Если i = n +1, то машина считывает пустой символ B. Если δ ( q, B ) = ( p, X, R ), то (q, A1A2…An, n+1)
Если же, наоборот, δ ( q, B ) = ( p, X, L ), то (q, A1A2…An, n+1)
В случае, когда две ситуации машины Тьюринга связаны между собой некоторым конечным числом элементарных действий, будет использоваться обозначение Язык, допускаемый машиной Тьюринга, определяется как множество { x | x
Считается, что машина T, допускающая язык L, останавливается на каждом допустимом входе (т.е., допустив цепочку, машина прекращает работу). С другой стороны, возможно, что машина T не остановится, если входная цепочка не принадлежит языку L. Недетерминированная машина Тьюринга - это такая машина, у которой δ - отображение Q × Γ во множество подмножеств множества Q × (Γ -{ B })× { L, R }. Можно показать, что если язык L допускается недетерминированной машиной Тьюринга T 1, то L допускается и некоторой недетерминированной машиной Тьюринга T 2. Линейно ограниченный автомат. Линейно ограниченным автоматом M называется шестёрка M = ( Σ , Q, Γ , δ , q 0, F ), где Q - конечное множество состояний, Γ - конечное множество входных символов, Σ Из определения следует, что линейный ограниченный автомат есть, в сущности, недетерминированная машина Тьюринга, которая никогда не сдвигается с той части входной ленты, на которой задан вход [4]. Ситуация линейно ограниченного автомата и связь между двумя ситуациями { x | x для некоторых q
Если для любого q Линейно ограниченные автоматы допускают языки непосредственно составляющих, и только их.
Модификации грамматик Известно, что бесконтекстные грамматики не являются достаточно мощным средством для описания естественных языков или языков программирования. С другой стороны, языки непосредственно составляющих (но не бесконтекстные) требуют весьма сложного синтаксического анализа. Компромисс достигается путём введения различных обобщений бесконтекстных грамматик. Такими обобщениями являются программные и индексные грамматики [4]. Программные грамматики. Программные грамматики отличаются тем, что после применения правила подстановки к некоторой промежуточной цепочке выбор следующего правила подстановки ограничен. Каждое правило подстановки состоит из метки, ядра и двух связанных с ядром списков перехода. Если правило можно применить к цепочке, полученной в процессе вывода, то следующее правило выбирается из первого списка (списка переходов при успехе). В противном случае следующее правило выбирается из второго списка (списка переходов при неудаче). Программной грамматикой Gp называется пятёрка ( VN, VT, J, P, S ), где VN, VT и P - конечные множества вспомогательных символов, основных символов и правил вывода соответственно, S - начальный символ, S Правило вывода из P имеет вид ( r ) α → β S ( U ) F ( W ). (2.24)
Правило подстановки α → β называется ядром. Здесь α Программная грамматика действует следующим образом. Сначала применяется правило с меткой (1). Если делается попытка применить правило ( r ), чтобы заменить подцепочку α , и выведенная перед этим цепочка содержит α, то применяется правило ( r ) α → β , и следующее правило выбирается из правил, метки которых содержатся в списке переходов при успехе U. Если выведенная цепочка не содержит α , то правило ( r ) не используется, а следующее правило выбирается из тех, метки которых содержатся в списке переходов при неудаче W. В случае, когда ядра всех выводов имеют бесконтекстную форму (т.е. A → β ), грамматика называется бесконтекстной программной. Аналогично, когда ядра правил имеют регулярный вид или вид правил непосредственно составляющих, грамматика называется регулярной программной или программной грамматикой непосредственно составляющих. Показано, что язык, порождённый бесконтекстной программной грамматикой, может быть языком непосредственно составляющих. Более того, показано, что класс языков, порождённых бесконтекстными программными грамматиками, включает все бесконтекстные языки. Индексные грамматики. Это обобщение получается при введении в грамматику нового конечного множества - множества индексов. Грубо говоря, за вспомогательным символом в цепочке могут следовать произвольные списки индексов. Если вспомогательный символ со следующими за ним индексами заменяется одним или несколькими вспомогательными символами, индексы будут следовать за всеми вновь порождёнными вспомогательными символами. Если вспомогательный символ заменяется основным, индексы пропадают. Индексной грамматикой называется пятёрка Gi = ( VN, VT, F, P, S ), где VN, VT, F и P - конечные множества вспомогательных символов, основных символов, индексов и правил подстановки соответственно, S Определим отношение . Если α A θ β - цепочка, в которой α и β
α A θ β
Здесь φ i = λ , если Xi . Если α Af θ β - цепочка, в которой α и β α Af θ β
где φ i = λ , если Xi Показано, что класс индексных языков содержит все бесконтекстные языки как подкласс и является подклассом класса языков непосредственно составляющих. Более того, индексные грамматики достаточно мощны, чтобы обеспечить целый ряд не бесконтекстных свойств в алгоритмических языках. Языки описания образов Выбор непроизводных элементов. Выше было сказано, что первый этап построения синтаксической модели образов состоит в определении множества непроизводных элементов, при помощи которых можно описать эти образы. Выбор непроизводных элементов существенно зависит от природы образов, специфики области применения и от характера доступных технологических средств. Обычно при этом выборе стараются выполнить следующие требования [4]: 1. Непроизводные элементы должны служить основными элементами образов и обеспечивать адекватное и сжатое описание исходных данных в терминах заданных структурных отношений. 2. Поскольку структурная информация в непроизводных элементах не важна, и они считаются простыми и компактными образами, их выделение и распознавание должны легко осуществляться существующими несинтаксическими методами. Второе требование часто вступает в противоречие с первым, поскольку выбранные непроизводные элементы не всегда легко распознать при помощи несинтаксических методов. С другой стороны, в соответствии с этим требованием можно выбирать довольно сложные непроизводные элементы, лишь бы они были доступны распознаванию. Чем сложнее непроизводные элементы, тем проще могут быть структурные описания, т.е. они могут укладываться в рамки простых грамматик. При реализации распознающей системы достижение компромисса между указанными требованиями может стать весьма важной задачей. Методы выделения непроизводных элементов можно разделить на две группы. В одной из них упор делается на границы, а во второй - на области изображения. Выделение непроизводных элементов на границах и остовах. Множество непроизводных элементов, которые обычно используют для описания границ и остовов, получают по схеме цепного кодирования. На двумерное изображение накладывают прямоугольную сетку, и узлы сетки, которые наиболее близки к точкам изображения, соединяют отрезками прямых. Каждому такому отрезку в соответствии с его наклоном присваивают восьмеричное число. Таким образом, изображение представляется цепью (последовательностью) или цепями восьмеричных чисел. Эта дескриптивная схема обладает рядом полезных свойств. Например, поворот изображения на угол, кратный 45º, сводится к прибавлению восьмеричного числа (сложение по модулю 8) к каждому числу цепочки. Конечно, при этом изображение может исказиться. Только поворот на угол, кратный 90º, никогда не приводит к искажению изображения. Легко выполняются и некоторые другие простые манипуляции с изображением, такие, как растяжение, изменение длины кривой, определение самопересечений. Изменяя шаг сетки, накладываемой на изображение, можно получить любое желаемое разрешение [4]. Этот метод не ограничен изображениями с односвязными замкнутыми изображениями. Его можно применять для описания произвольных двумерных фигур, составленных из прямых и кривых линий и отрезков. На рис.10 показано множество непроизводных элементов и кодовая цепочка 66767011221222, которая описывает кривую.
Непроизводные элементы из областей. Второй способ выделения непроизводных элементов - кодирование геометрических образов, которые строятся из областей. Основными непроизводными элементами служат полупространства образов (поля наблюдения). Можно показать, что любая фигура аппроксимируется произвольным многоугольником, который, в свою очередь, можно представить как объединение конечного числа выпуклых многоугольников. Каждый выпуклый многоугольник можно представить в виде пересечения конечного числа полуплоскостей. Если подходящим образом задать последовательность выпуклых многоугольников, составляющих произвольный многоугольник, то можно однозначно определить минимальное множество в некотором смысле множеств, объединение которых даст исходную фигуру. По аналогии с лингвистикой фигура - это «предложение», составляющие её выпуклые многоугольники - «слова», а полуплоскости - «буквы» [4]. Следующий после выделения непроизводных элементов этап состоит в построении грамматики (грамматик), порождающей язык (языки) для описания исследуемых образов. В лучшем случае было бы хорошо иметь систему восстановления грамматики, которая способна строить грамматику по множеству цепочек, описывающих эти образы. К сожалению, такую систему можно построить для некоторых весьма специальных случаев. В большинстве случаев проектировщик при построении грамматики основывается на доступных априорных знаниях и своём опыте. Использование семантической информации. Для выделения непроизводного элемента требуется некоторое множество признаков. Непроизводные элементы с разными величинами могут быть описаны величинами признаков. Это множество признаков можно рассматривать как семантическую информацию о непроизводных элементах. Каждый признак можно выразить набором чисел или логических предикатов. Начальное описание T ( x ) образа x можно определить выражением T ( x ) = ( Ts ( x ), Tv ( x )), (2.27)
где Ts ( x ) - задание непроизводных элементов образа x и их взаимных отношений, а Tv ( x ) - значение признаков для каждого элемента. Структурная информация об образе x задаётся синтаксическим или иерархическим описанием H ( x ) = ( Hs ( x ), Hv ( x )), (2.28)
где Hs ( x ) - синтаксическая компонента, состоящая из множества необходимых для порождения Ts ( x ) правил подстановки, а Hv ( x ) - выполнимость интерпретационного правила, соответствующего каждому правилу подстановки грамматики G, которое используется при грамматическом разборе выражения Ts (α ). Таким образом, полное описание образа x определено выражением (T(x), H(x)) = ((Ts(x), Tv(x)), (Hs(x), Hv(x))). (2.29)
Класс образов может быть описан ассоциативной семантической информацией и грамматикой G, такой, что для любого образа x из этого класса Ts ( x ) Все признаки разделяются на две группы: унаследованные и синтезированные [4]. Унаследованные признаки касаются тех аспектов смысла, которые определяются контекстом фразы, а синтезированные связаны с самой фразой. Принципиально для определения смысла цепочки в бесконтекстном языке достаточно одних синтезированных признаков. Однако включение унаследованных признаков часто приводит к существенным упрощениям в оценке признаков. Семантические правила добавляются к бесконтекстной грамматике следующим образом. Каждому символу X Xk 0 → Xk 1, Xk 2, …, Xknk, (2.30)
где Xk 0 Приписывание семантики цепочкам бесконтекстного языка при помощи семантических правил осуществляется следующим образом. Для любой основной цепочки x нужно обычным образом построить дерево её вывода из начального символа S. Корнем этого дерева является символ S, а вершина, соответствующая применению k-го правила подстановки, является либо основным, либо вспомогательным символом xk 0. Пусть X - символ какой-либо вершины этого дерева, а α f kjα : D α 1 × D α 2 × …× D α t → D α (2.31)
все признаки имеют величины v 1, …, vt для соответствующих вершин, помеченных символами Xkl 1, …, Xklt, и v = f kjα ( v 1, …, vt ). Этот процесс оценки признаков нужно проводить по всему дереву до тех пор, пока он не закончится естественным образом [4]. Полученные на этой стадии оценки признаков и являются «смыслом», соответствующим данному выводу.
|
Последнее изменение этой страницы: 2020-02-16; Просмотров: 188; Нарушение авторского права страницы
 Q - начальное состояние и F
Q - начальное состояние и F  Q - множество заключительных состояний. Функция δ ( q, a ) интерпретируется следующим образом: автомат A в состоянии q читает входной символ a, переходит в состояние q ’ и сдвигает устройство считывания на один символ вперёд. Отображение δ можно распространить с одного входного символа на цепочку, если определить
Q - множество заключительных состояний. Функция δ ( q, a ) интерпретируется следующим образом: автомат A в состоянии q читает входной символ a, переходит в состояние q ’ и сдвигает устройство считывания на один символ вперёд. Отображение δ можно распространить с одного входного символа на цепочку, если определить Σ *, a
Σ *, a 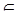 F }. (2.7)
F }. (2.7) δ (qi, a), x
δ (qi, a), x  Σ *, a
Σ *, a  δ ( qi, x ). (2.9)
δ ( qi, x ). (2.9) Q - множество заключительных состояний, δ - отображение Q × (Σ U{ λ })× Γ во множество конечных подмножеств Q × Γ *.
Q - множество заключительных состояний, δ - отображение Q × (Σ U{ λ })× Γ во множество конечных подмножеств Q × Γ *.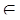 Q 0 и γ
Q 0 и γ  ( Σ U { λ }), γ, β
( Σ U { λ }), γ, β  Γ и Z
Γ и Z  ( q ’, β γ ) (2.13)
( q ’, β γ ) (2.13)  (qi+1, γ i+1 ), 1 ≤ i ≤ n, (2.14)
(qi+1, γ i+1 ), 1 ≤ i ≤ n, (2.14)  (qi+1, γ i+1 ). (2.15)
(qi+1, γ i+1 ). (2.15) ( q, γ ) для некоторых γ
( q, γ ) для некоторых γ  Γ , не содержащее B, составляет множество входных символов, δ - отображение Q × Γ в Q × (Γ -{ B })× { L, R } (оно может быть не определено для некоторых аргументов), q 0
Γ , не содержащее B, составляет множество входных символов, δ - отображение Q × Γ в Q × (Γ -{ B })× { L, R } (оно может быть не определено для некоторых аргументов), q 0 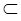 Q - множество заключительных состояний.
Q - множество заключительных состояний. (p, A1A2...Ai-1XAi+1…An, i+1). (2.18)
(p, A1A2...Ai-1XAi+1…An, i+1). (2.18)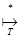 .
. Σ * и ( q 0, x, 1)
Σ * и ( q 0, x, 1) 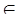 F, α
F, α  Σ * и i } (2.22)
Σ * и i } (2.22)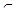 ( Σ -{Ø, $}) * и ( q 0 Ø x $, 1)
( Σ -{Ø, $}) * и ( q 0 Ø x $, 1) 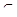 VN, J - множество меток правил подстановки.
VN, J - множество меток правил подстановки. V * VNV и β
V * VNV и β  J.
J. на цепочках множества ( VNF *UVT )* следующим образом:
на цепочках множества ( VNF *UVT )* следующим образом:  F *, а A → X 1 ψ 1 X 2 ψ 2 … Xm ψ m - правило подстановки из P, в котором Xi
F *, а A → X 1 ψ 1 X 2 ψ 2 … Xm ψ m - правило подстановки из P, в котором Xi  F *, для всех i, то считаем, что
F *, для всех i, то считаем, что VT, и φ i = ψ i θ , если Xi
VT, и φ i = ψ i θ , если Xi 
 L ( G ). «Смысл» образа выражен как начальным, так и синтаксическим описанием.
L ( G ). «Смысл» образа выражен как начальным, так и синтаксическим описанием. VT. Каждый признак α
VT. Каждый признак α  A ( X ) имеет множество возможных значений D α , из которого при появлении символа X в дереве синтаксического анализа может быть выбрано одно значение. Пусть множество P состоит из m правил подстановки, и пусть k-е правило имеет вид
A ( X ) имеет множество возможных значений D α , из которого при появлении символа X в дереве синтаксического анализа может быть выбрано одно значение. Пусть множество P состоит из m правил подстановки, и пусть k-е правило имеет вид A 0 ( Xkj ) при j = 0 и α
A 0 ( Xkj ) при j = 0 и α