
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Последовательная проверка гипотез
Во многих задачах вся информация об объекте, подлежащем классификации, предъявляется одновременно. Для принятия решения, например, с помощью байесовского правила, используется единственный вектор наблюдений, и никаких последующих наблюдений при этом не проводится. Поэтому отсутствует возможность достаточно надёжно проконтролировать ошибку, если нельзя изменить процесс наблюдения. Однако во многих практических задачах наблюдения поступают последовательно, и в нашем распоряжении оказывается всё больше и больше информации. Можно рассмотреть, например, известную радиолокационную задачу обнаружения цели: последовательность поступивших в течение некоторого времени импульсов принадлежит одному из двух классов, соответствующих наличию или отсутствию цели. Основной метод решения задач этого типа - усреднение последовательности векторов наблюдения. Этим достигается эффект фильтрации шума и сокращение числа наблюдаемых векторов до одного вектора математического ожидания. Таким, образом, возможно, по крайней мере, теоретически, получить нулевую ошибку классификации, если векторы математического ожидания не равны между собой. Однако, поскольку невозможно получить бесконечную последовательность наблюдаемых векторов, то необходимо иметь условие или правило, позволяющее принять решение об окончании процесса наблюдения. Математическим методом решения задач этого типа является аппарат последовательной проверки гипотез [3]. Последовательный критерий Вальда. Последовательный критерий проверки гипотез Вальда можно реализовать следующим образом. Пусть x 1, x 2, … - последовательно наблюдаемые, независимые и одинаково распределённые случайные векторы. Для каждого xj можно вычислить отношение правдоподобия
являющееся случайной величиной. После k наблюдений отношение правдоподобия будет равно
С ростом k математическое ожидание и дисперсия отношения правдоподобия uk для классов C 1 и C 2 имеют вид mik = kmi, (1.18) σ 2 ik = k σ 2 i, (1.19) так как zi также являются независимыми и одинаково распределёнными случайными величинами. С ростом k mik увеличивается, если mi > 0, и уменьшается, если mi < 0. Увеличение σ ik пропорционально k 1/2 и происходит медленнее, чем возрастание mik. Кроме того, при больших k, в соответствии с центральной предельной теоремой, плотность вероятности отношения правдоподобия uk стремится к плотности нормального распределения. Если установить решающее правило следующим образом: uk ≤ a → x a < uk < b → произвести следующие наблюдения, b ≤ uk → x
то можно отнести объект x с вероятностью 1 к классу C 1 или C 2. Кроме того, при этом ошибки классификации зависят от значений a и b, т.е. при увеличении абсолютных значений a и b вероятности ошибки классификации уменьшаются, а количество наблюдений, требуемое для принятия решения, увеличивается. Соотношение между значением порога и ошибками классификации можно выразить следующим образом:
Для любых значений вероятностей ошибки ε 1 и ε 2 теоретически можно определить значения a и b из выражений (1.20) и (1.21). Простой способ нахождения пороговых значений заключается в следующем: при k-м наблюдении проверяется отношение правдоподобия
Поэтому
Левая часть выражения (1.23) содержит все векторы x, принадлежащие классу C 1, и классифицирует их правильно. Следовательно, она равна 1-ε 1. С другой стороны, правая часть выражения (1.23) содержит все векторы x, принадлежащие классу C 1, но классифицированные как принадлежащие классу C 2. Следовательно, правая часть (1.23) равна ε 2. Аналогично можно получить, что левая и правая части (1.24) соответственно будут равны ε 1 и 1 - ε 2. Тогда (1.23) и (1.24) можно переписать следующим образом:
Таким образом, для любых заданных значений вероятности ошибки ε 1 и ε 2 можно получить пороговые значения A и B из формул (1.25) и (1.26). В заключение можно сделать некоторые замечания, касающиеся свойств последовательного критерия Вальда [3]: ) Для получения выражений (1.25) и (1.26) не требуется независимости и равенства распределений случайных векторов x 1, x 2, …, xn. ) Можно доказать, что критерий Вальда сходится с вероятностью 1. ) Критерий Вальда минимизирует среднее количество наблюдений, требуемых для достижения заданных вероятностей ошибки ε 1 и ε 2. ) Критерий Вальда не зависит от априорных вероятностей P ( Ci ), хотя ошибки и зависят от P ( Ci ). Последовательный байесовский критерий. Последовательный критерий можно также применять для того, чтобы сократить количество наблюдаемых переменных, требуемых для принятия решения. Это целесообразно в случае, когда у каждого объекта отдельные признаки проверяют последовательно. Однако на пути применения такого подхода встречается много трудностей [3]. ) Наблюдаемые переменные взаимно коррелированны и имеют разные распределения. ) Значение порога должно изменяться при каждом наблюдении. На рис.5 изображён пример классификации двумерного объекта на классы C 1 и C 2. Если наблюдается случайный вектор x 1, то для отношения правдоподобия можно установить значения порогов равными A 1 и B 1. Однако если наблюдаются два случайных вектора x 1 и x 2, то A 2 должно быть равно B 2, так как нельзя откладывать принятие решения до предъявления следующей переменной. Как правило, предполагают, что по мере увеличения k значения порогов стремятся к одному и тому же значению. ) Вероятность ошибки определяется условными плотностями вероятности p ( x / C 1 ) и p ( x / C 2 ) при наблюдении всего набора из n переменных. Последовательный критерий не уменьшает вероятность ошибки, но сокращает число переменных, требуемых для принятия решения. Поэтому такая процедура может быть оправдана, если стоимость наблюдения каждой переменной является существенным фактором.
Хотя проверка обычного последовательного байесовского критерия очень сложна, этот критерий используют для последовательной проверки признаков объекта. Байесовский риск можно представить следующим образом:
где rj - стоимость наблюдений x 1, x 2, …, xj; L ( Ci, dj ( x 1 , x 2 , …, xj )) - математическое ожидание потерь для случая, когда ( x 1, x 2, …, xj ) Линейные классификаторы
Выше было сказано, что байесовский классификатор отношения правдоподобия оптимален в том смысле, что он минимизирует риск или вероятность ошибки. Однако для получения отношения правдоподобия необходимо располагать для каждого класса условными плотностями вероятности. В большинстве приложений оценка этих плотностей осуществляется по конечному числу выборочных векторов наблюдений. Процедуры оценивания плотностей вероятности известны, но они являются либо очень сложными, либо требуют для получения точных результатов большого числа векторов наблюдений. В связи с этим имеет смысл рассмотреть более простые методы разработки классификаторов. Тем не менее, надо понимать, что байесовский классификатор во всех случаях является наилучшим, и никакой линейный классификатор не превосходит по качеству работы классификатор, полученный по критерию отношения правдоподобия. Наиболее простым и общим видом является линейный или кусочно-линейный классификатор. Байесовский линейный классификатор. Для двух нормально распределённых случайных величин байесовское решающее правило можно представить в виде квадратичной функции относительно вектора наблюдений x следующим образом:
где Σ i - корреляционные матрицы случайных величин, Mi - математические ожидания соответственно. Если корреляционная матрица равна единичной, то можно считать, что вектор x представляет собой наблюдение, искажённое белым шумом. Компоненты вектора x при этом некоррелированы и имеют единичную дисперсию, а байесовское решающее правило принимает вид
Произведение MT ix представляет собой коэффициент корреляции между векторами Mi и x. Легко видеть, что для принятия решения рассматриваемый классификатор сравнивает разность коэффициентов корреляции векторов x и М1 и x и M 2 с выбранным порогом. Следовательно, его можно назвать корреляционным классификатором [3]. Если умножить (1.29) на 2, а затем прибавить и вычесть xTx из левой части, то можно получить решающее правило
или
Полученному решающему правилу можно дать следующую интерпретацию: сравниваются расстояния между вектором x и векторами M 1 и M 2 с порогом. В общем случае, когда корреляционные матрицы не равны единичной, наблюдаемый шум коррелирован, и его часто называют «окрашенным». В этом случае байесовский классификатор так легко не интерпретируется. Однако по-прежнему целесообразно рассматривать в качестве решающего правила корреляционный классификатор или классификатор, основанный на вычислении расстояния. Для этого можно ввести декоррелирующее преобразование y = A x , которое переводит коррелированный («окрашенный») шум в белый: AΣ A T = I. (1.32)
Заметим, что пока корреляционная матрица Σ является положительно определённой, матрица A существует и невырождена. Поэтому декоррелирующее преобразование обратимо, и наблюдения вектора y можно классифицировать также эффективно, как и наблюдения вектора x [3]. Линейная разделяющая функция, минимизирующая вероятность ошибки решения. Линейные классификаторы представляют собой простейшие классификаторы, поскольку их реализация непосредственно связана со многими известными методами классификации, такими, как корреляционные методы или методы, основанные на вычислении евклидовых расстояний. Однако линейные классификаторы оптимальны в байесовском смысле только для нормальных распределений с равными корреляционными матрицами. Для некоторых приложений, таких, как выделение полезного сигнала в системах связи, равенство корреляционных матриц является приемлемым предположением, так как при изменении сигнала свойства шума существенно не изменяются. Однако во многих других приложениях распознавания образов предположение о равенстве ковариаций не оправдано. Предпринимались различные попытки разработки линейных классификаторов для нормальных распределений с неравными корреляционными матрицами и для распределений, отличных от нормального. Разумеется, эти классификаторы не являются оптимальными, однако во многих случаях их простота служит достаточной компенсацией ухудшения качества классификации. Рассмотрим методы создания линейных классификаторов для этих более сложных случаев. Так как оговорено, что независимо то вида распределений используется линейный классификатор, то решающее правило должно иметь вид
Выражение h ( x ) есть линейная разделяющая функция относительно x. Задача синтеза классификатора заключается в том, чтобы для заданных распределений определить коэффициенты VT =[ v 1, v 2, …, vn ] и значение порога v 0, оптимальные по различным критериям. Если случайная величина h ( x ) распределена по нормальному или близкому к нему закону, то для вычисления вероятности ошибки можно использовать её математическое ожидание и дисперсию для классов C 1 и C 2, а затем выбрать параметры V и v 0 так, чтобы минимизировать ошибку решения. Так как h ( x ) является суммой, состоящей из n слагаемых xi, приходим к выводу [3]: 1) если векторы x имеют нормальное распределение, то величина h ( x ) также имеет нормальное распределение; 2) даже если векторы x распределены не по нормальному закону, но при большом n выполнены условия центральной предельной теоремы, то распределение величины h ( x ) может быть близко к нормальному. Математические ожидания и дисперсии величины h ( x ) в классах C 1 и C 2 равны Mi = VTmi + v0, (1.34) σ 2 i = VT Σ i V. (1.35)
Поэтому вероятность ошибки можно записать следующим образом:
Если требуется минимизировать риск R, то вместо вероятностей P ( C 1 ) и P ( C 2 ) в формуле (1.36) должны быть использованы величины r 12 P ( C 1 ) и r 21 P ( C 2 ). При такой замене предполагается, что r 11 = r 22 = 0. Продифференцировав выражение (1.36) по параметрам V и v 0, получим, что
при этом h =0 и M 2 - M 1 = [( m 2 / σ 2 2 ) Σ 2 -( m 1 / σ 2 1 ) Σ 1 ]. Кусочно-линейные разделяющие функции. Линейные разделяющие функции находят широкое применение в задачах распознавания образов для случая двух классов, хотя при этом неизбежна некоторая потеря качества распознавания. Однако при трёх или более классах качество распознавания с использованием линейной разделяющей функции часто оказывается неприемлемым. Если в этих случаях воспользоваться совокупностью линейных разделяющих функций, т.е. воспользоваться кусочно-линейной разделяющей функцией, то появляются дополнительные возможности улучшения качества распознавания [3]. На рис. 6 изображён пример задачи распознавания для случая четырёх классов.
В задачах со многими классами критерии проверки многих гипотез дают наилучшее в байесовском смысле решающее правило, обеспечивающее минимум риска или вероятности ошибки. В соответствии с критерием проверки гипотез плотность вероятности или её логарифм следует сравнивать с плотностями вероятности других классов, как следует из (1.11). На рис. 6, а изображены полученные таким образом границы. Если оценивание плотностей вероятности является слишком сложной задачей или границы, определяемые в соответствии с критерием проверки гипотез, слишком “вычурные”, то можно заменить эти сложные границы множеством простых линейных границ. Такая замена, конечно, приводит к некоторому ухудшению качества распознавания. Однако использование линейных границ особенно эффективно для задач распознавания многих классов, т.е. в тех случаях, когда сложность границ быстро возрастает с увеличением числа классов, и является желательным некоторое упрощение процедуры синтеза классификатора [3]. На рис. 6, б показана замена байесовских границ кусочно-линейными границами. Множество линейных функций, соответствующее кусочно-линейной разделяющей функции, определяется следующим образом: hij(x) = VTijx + vi0, i, j = 1, 2, …, M, i ≠ j, (1.38)
где M - число классов. Знаки Vij выбираются так, чтобы распределение класса i находилось в области положительных значений линейной функции hij ( x ), а распределение класса j - в области отрицательных значений. Из этого требования следует, что hij ( x ) = hji ( x ). (1.39)
Предположим, что для каждого класса соответствующая область является выпуклой, как изображено на рис. 6, б, тогда область класса i может быть просто определена следующим образом: hi1(x) > 0, hi2(x) > 0, …, hiM(x) > 0 → x
(функция hii ( x ) исключена из рассмотрения). Наличие тёмной области на рисунке 6, б показывает, что M областей, определяемые условиями (390), не обязательно покрывают всё пространство. Если объект попадает в эту область, то кусочно-линейный классификатор не может принять решение о его принадлежности к определённому классу; эту область называют областью отказов. Решающее правило состоит из M -1 линейных разделяющих функций и логического элемента AND с M -1 входами, которые принимают значения sign { hij ( x )}. Соответствующая блок-схема изображена на рис. 7. Поскольку каждая из параллельных цепей состоит из двух последовательно соединённых элементов, то такой кусочно-линейный классификатор иногда называют двухслойной машиной. Если предположение о выпуклости областей не выполняется, то необходимо определить взаимные пересечения M -1 гиперплоскостей и строить решающее правило в соответствии с этими пересечениями. Однако при этом классификатор становится весьма сложным для решения практических задач.
Вероятность ошибки решения для каждого класса ε i можно выразить через ( M -1)-мерную функцию распределения вероятности:
(функция hii исключена из рассмотрения.). Тогда общая ошибка решения
Задача теперь состоит в том, чтобы определить значения V и v 0 для данного множества M распределений при наличии информации о структуре кусочно-линейного классификатора. Вследствие сложности этой задачи её решение не является таким наглядным, как для линейного классификатора. Кратко отметим несколько приближённых методов решения задачи [3]. 1) Можно подстраивать коэффициенты V и v 0 так, чтобы минимизировать вероятность ошибки решения ε , определяемую формулой (1.41). 2) Линейная разделяющая функция между парой классов строится с помощью одного из методов, рассмотренных ранее для случая распознавания двух классов. Вычисляются M ( M -1)/2 разделяющих функций. Эти функции без дальнейшей коррекции используются в качестве кусочно-линейной разделяющей функции. Если распределения являются нормальными с равными корреляционными матрицами, то описанная процедура эквивалентна применению байесовского решающего правила. Если распределения существенно отличаются между собой, то дальнейшая коррекция решающего правила может привести к уменьшению ошибки. Однако часто оказывается, что уменьшение ошибки за счёт подстройки параметров V и v 0 относительно невелико. Обобщенные линейные разделяющие функции. До сих пор были рассмотрены линейные разделяющие функции. Одна из причин этого заключается в том, что при высокой размерности наблюдаемых векторов только линейные или кусочно-линейные разделяющие функции дают приемлемый компромисс между качеством распознавания и простотой реализации. Другая важная причина состоит в том, что даже нелинейная разделяющая функция может быть интерпретирована в функциональном пространстве как линейная, т.е. выражение
представляет собой в функциональном пространстве линейную разделяющую функцию, где r переменных gi ( x ) заменяют n переменных x в исходном пространстве. Другим важным случаем является использование квадратичных поверхностей, где r переменных gi ( x ) задают так, что первыми n переменными являются x 2 i, i =1, 2, …, n, следующими n ( n -1)/2 - все пары xixj , i, j =1, 2, …, n, i ≠ j, а последние n переменных представляют собой x i, i =1, 2, …, n. Относительно этого преобразования можно сказать, что для каждой квадратичной разделяющей функции в пространстве x существует соответствующая линейная разделяющая функция в пространстве функций gj ( x ). Переменные gi ( x ) являются признаками. Выбор эффективной системы признаков представляет собой самостоятельный раздел теории распознавания образов. Оценивание параметров Как говорилось выше, если известны плотности вероятности классов, то для классификации объектов можно определить граничную поверхность, разделяющую пространство признаков на области. Следующий вопрос заключается в том, как по имеющейся выборке объектов оценить эти плотности вероятности? Эта задача является очень сложной, если нельзя сделать предположение о структуре многомерной плотности вероятности. Однако если можно задать вид этой функции, то задача сводится к определению конечного числа параметров. Для этого можно использовать известные статистические методы оценки параметров. Оценивание параметров плотностей вероятности известного вида и классификацию объектов на основе этих плотностей называют параметрическим методом классификации [3]. Первая задача, которая здесь возникает, заключается в оценке основных параметров плотностей вероятности, таких, как вектор математического ожидания, корреляционная матрица и т.д., в предположении, что эти параметры не являются случайными величинами. Далее следует рассмотреть случай, когда эти параметры - случайные величины. Такие задачи называют точечным оцениванием [3]. Другой важный вопрос в распознавании образов - оценка вероятности ошибок решения и отношения правдоподобия. Поскольку вероятности ошибок и отношение правдоподобия представляют собой сложные функции относительно параметров, непосредственное применение для них стандартных методов оценивания не даёт приемлемых результатов. Поэтому имеет смысл рассмотреть методы оценивания этих величин по имеющимся выборочным данным. Оценивание неслучайных параметров. Пусть Θ и
где Оценка
Оценка
Оценка
Оценка
Таким образом, наилучшая оценка из тех, которые можно найти, должна быть несмещённой, состоятельной, эффективной и достаточной. Оценки моментов. Основными параметрами, характеризующими плотность вероятности, являются моменты. В качестве их оценок используют выборочные моменты. Общий выборочный момент порядка i 1 + i 2 +…+ in определяется как среднее от моментов порядка i 1 + i 2 +…+ in отдельных случайных выборочных объектов
где Математическое ожидание оценки (1.49) вычислить нетрудно, оно равно истинному значению искомого момента распределения, а дисперсия (1.49) равна
где Таким образом, выборочный момент представляет собой несмещённую состоятельную оценку. В большинстве приложений внимание сосредоточено на моментах первого и второго порядка - выборочном векторе средних значений и выборочной автокорреляционной матрице, которые определяются соответственно следующим образом:
Формулы (1.51) и (1.52) - частные случаи формулы (1.49), поэтому оценки математического ожидания и автокорреляционной матрицы являются несмещёнными и состоятельными. Ситуация несколько меняется, когда рассматривают центральные моменты, такие, как дисперсии и корреляционные матрицы. Определим оценку корреляционной матрицы следующим образом:
Математическое ожидание оценки
Нижнюю границу дисперсии любой несмещённой оценки
(в предположении, что обе производные существуют и абсолютно интегрируемы). Любая несмещённая оценка, при которой в (1.55) имеет место равенство, является эффективной оценкой. Оценка максимального правдоподобия. Более общим методом точечного оценивания является выбор при наблюдаемой величине Z такой оценки
или
Эти уравнения называют уравнениями правдоподобия. Можно показать, что если существует эффективная оценка (т.е. выполняется условие (1.55)), то она будет оценкой максимального правдоподобия. Оценивание случайных параметров. Когда оценивание параметры представляют собой случайные величины, делается попытка минимизировать математическое ожидание функции ошибки между случайными параметрами и их оценками. Байесовская оценка. Пусть Θ и
где r (•) - функция штрафа, зависящая от случайного параметра Θ и его оценки Хотя байесовская оценка является весьма общей и обладает свойством оптимальности в смысле минимума среднего риска, получить её в явном виде, как правило, нелегко. Поэтому такие оценки получены для некоторых функций штрафа. ) Оценка, минимизирующая среднеквадратичную ошибку В качестве функции штрафа можно использовать величину
При этом байесовский риск (1.57) превращается в среднеквадратичную ошибку оценки
Таким образом, оценка минимизирующая среднеквадратичную ошибку, представляет собой вектор математического ожидания апостериорной плотности вероятности. Вообще говоря, выражение (1.59) справедливо для всех функций штрафа, обладающих свойствами симметричности и выпуклости, если апостериорная плотность вероятности является симметричной функцией относительно условного математического ожидания, т.е.
где Θ ’ =Θ - M { Θ / Z }. ) Оценка, максимизирующая апостериорную вероятность. Пусть функция штрафа имеет следующий вид:
где параметр δ и область Δ Φ выбраны достаточно малыми так, чтобы условную плотность вероятности p (Θ / Z ) можно было считать постоянной в данной области. Пусть Δ V - объём области Δ Φ . Тогда выражение (1.57) можно переписать в виде
Подынтегральное выражение в (1.62) является неотрицательным. Поэтому риск R можно минимизировать, если оценку
или
Такую оценку называют оценкой, максимизирующей апостериорную вероятность.
|
Последнее изменение этой страницы: 2020-02-16; Просмотров: 197; Нарушение авторского права страницы
 , (1.16)
, (1.16) .(1.17)
.(1.17)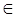 C 1,
C 1,  C 2,
C 2,  , (1.20)
, (1.20)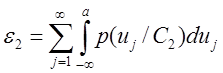 . (1.21)
. (1.21) . (1.22)
. (1.22)

 , (1.23),
, (1.23), 
 . (1.24)
. (1.24)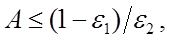 (1.25)
(1.25) (1.26)
(1.26)

 , (1.27)
, (1.27) Ci и использовано решающее правило dj ( x 1 , x 2 , …, xj ); Δ i - область пространства X, для которой последовательность испытаний заканчивается при j-м наблюдении. В случае байесовского критерия необходимо отыскать решающие правила dj ( x 1 , x 2 , …, xj ), j =1, 2, …, n, минимизирующие риск R для заданного множества стоимостей наблюдений.
Ci и использовано решающее правило dj ( x 1 , x 2 , …, xj ); Δ i - область пространства X, для которой последовательность испытаний заканчивается при j-м наблюдении. В случае байесовского критерия необходимо отыскать решающие правила dj ( x 1 , x 2 , …, xj ), j =1, 2, …, n, минимизирующие риск R для заданного множества стоимостей наблюдений.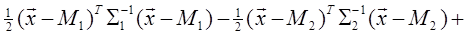
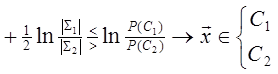 , (1.28)
, (1.28)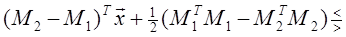
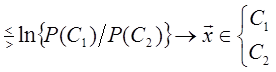 . (1.29)
. (1.29)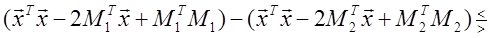
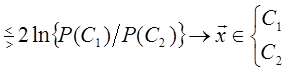 , (1.30)
, (1.30)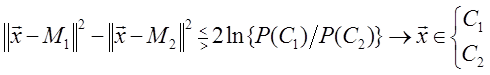 . (1.31)
. (1.31)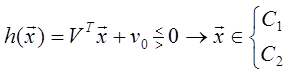 . (1.33)
. (1.33)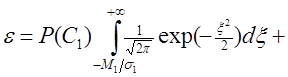
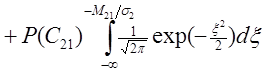 . (1.36)
. (1.36)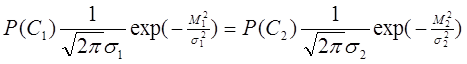 , (1.37)
, (1.37)
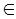 C1 (1.40)
C1 (1.40)
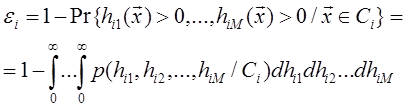 (1.41)
(1.41)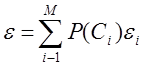 . (1.42)
. (1.42)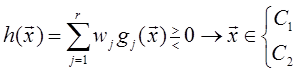 (1.43)
(1.43)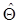 - соответственно истинный вектор параметров и его оценка. Значение
- соответственно истинный вектор параметров и его оценка. Значение 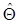 есть функция от наблюдаемых случайных векторов x 1, x 2, …, xN, т.е.
есть функция от наблюдаемых случайных векторов x 1, x 2, …, xN, т.е.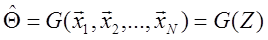 , (1.44)
, (1.44)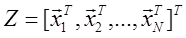 .
.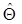 называется несмещённой оценкой параметра Θ , если её математическое ожидание равно истинному значению параметра, т.е.
называется несмещённой оценкой параметра Θ , если её математическое ожидание равно истинному значению параметра, т.е. . (1.45)
. (1.45) сходится по вероятности к Θ , т.е.
сходится по вероятности к Θ , т.е. . (1.46)
. (1.46) называется эффективной оценкой параметра Θ, если для всех возможных оценок
называется эффективной оценкой параметра Θ, если для всех возможных оценок 
 . (1.47)
. (1.47)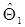 называется достаточной оценкой параметра Θ , если она содержит всю информацию о Θ , содержащуюся в наблюдаемых объектах, т.е.
называется достаточной оценкой параметра Θ , если она содержит всю информацию о Θ , содержащуюся в наблюдаемых объектах, т.е.  - достаточная оценка тогда и только тогда, когда для любых других оценок
- достаточная оценка тогда и только тогда, когда для любых других оценок  (для которых якобиан соответствующего преобразования не равен нулю) условная плотность вероятности оценок
(для которых якобиан соответствующего преобразования не равен нулю) условная плотность вероятности оценок  при фиксированной оценке
при фиксированной оценке 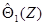 не зависит от параметра Θ :
не зависит от параметра Θ : 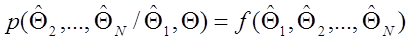 . (1.48)
. (1.48) , (1.49)
, (1.49)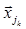 - k-я компонента j-го объекта.
- k-я компонента j-го объекта. , (1.50)
, (1.50) - дисперсия отдельного случайного объекта (в предположении, что наблюдаемые объекты независимы и одинаково распределены).
- дисперсия отдельного случайного объекта (в предположении, что наблюдаемые объекты независимы и одинаково распределены). , (1.51)
, (1.51)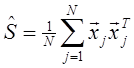 . (1.52)
. (1.52) . (1.53)
. (1.53) равно
равно  , отсюда видно, что такая оценка корреляционной матрицы является смещённой. Это смещение можно устранить с помощью следующей модифицированной оценки корреляционной матрицы:
, отсюда видно, что такая оценка корреляционной матрицы является смещённой. Это смещение можно устранить с помощью следующей модифицированной оценки корреляционной матрицы:  . (1.54)
. (1.54) можно определить с помощью следующего неравенства, называемого границей Крамера - Рао:
можно определить с помощью следующего неравенства, называемого границей Крамера - Рао: 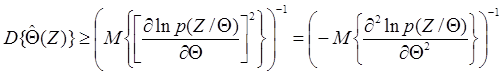 (1.55)
(1.55)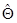 , которая максимизирует условную плотность вероятности p ( Z /Θ ), или ln p ( Z /Θ ). Иначе говоря, выбирается значение параметра Θ , при котором Z является наиболее правдоподобным результатом. Ясно, что эта оценка есть функция вектора Z. Логарифмическая функция рассматривается для удобства вычислений и, будучи монотонной, не изменяет точки максимума. Эту оценку называют оценкой максимального правдоподобия. Она представляет собой решение следующих эквивалентных уравнений:
, которая максимизирует условную плотность вероятности p ( Z /Θ ), или ln p ( Z /Θ ). Иначе говоря, выбирается значение параметра Θ , при котором Z является наиболее правдоподобным результатом. Ясно, что эта оценка есть функция вектора Z. Логарифмическая функция рассматривается для удобства вычислений и, будучи монотонной, не изменяет точки максимума. Эту оценку называют оценкой максимального правдоподобия. Она представляет собой решение следующих эквивалентных уравнений:  ,
, 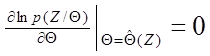 (1.56)
(1.56)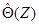 - соответственно оцениваемый параметр и случайная оценка, основанная на наблюдениях
- соответственно оцениваемый параметр и случайная оценка, основанная на наблюдениях 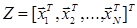 . Тогда можно ввести функцию штрафа так, чтобы средний риск оценки выражался следующим образом:
. Тогда можно ввести функцию штрафа так, чтобы средний риск оценки выражался следующим образом:  , (1.57)
, (1.57) . Величину R называют байесовским риском, а оценку, минимизирующую байесовский риск - байесовской оценкой.
. Величину R называют байесовским риском, а оценку, минимизирующую байесовский риск - байесовской оценкой. . (1.58)
. (1.58) . Минимизируя выражение (1.57) при условии (1.58) и при фиксированном векторе наблюдений Z, получим
. Минимизируя выражение (1.57) при условии (1.58) и при фиксированном векторе наблюдений Z, получим . (1.59)
. (1.59)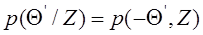 , (1.60)
, (1.60) (1.61)
(1.61)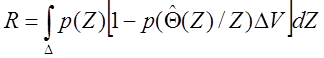 . (1.62)
. (1.62) выбрать равной значению параметра Θ , которое максимизирует апостериорную плотность вероятности p (Θ / Z ). Другими словами, эта оценка есть решение уравнения
выбрать равной значению параметра Θ , которое максимизирует апостериорную плотность вероятности p (Θ / Z ). Другими словами, эта оценка есть решение уравнения
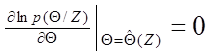 . (1.63)
. (1.63)