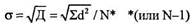|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Общее представление о вторичной обработке
Вторичная обработка завершает анализ данных и подготавливает их к синтезированию знаний на стадиях объяснения и выводов. Даже если эти последние этапы по каким-либо причинам не могут быть выполнены, исследование может считаться состоявшимся, поскольку завершилось получением результатов. В основном вторичная обработка заключается в статистическом анализе итогов первичной обработки. Как специфический вид вторичной обработки, по нашему мнению, выступает шкалирование, совмещающее математический, логический и эмпирический анализы данных, но в этом параграфе остановимся лишь на статистической обработке данных. Уже табулирование и построение графиков, строго говоря, тоже есть статистическая обработка, которая в совокупности с вычислением мер центральной тенденции и разброса включается в один из разделов статистики, а именно в описательную статистику. Другой раздел статистики – индуктивная статистика – осуществляет проверку соответствия данных выборки всей популяции, т. е. решает проблему репрезентативности результатов и возможности перехода от частного знания к общему [44, 158, 179, 187]. Третий большой раздел – корреляционная статистика – выявляет связи между явлениями. Статистика имеет мощный и подчас труднодоступный для неподготовленного исследователя аппарат. Поэтому надо сделать два замечания. Первое – статистическая обработка является неотъемлемой частью современного психологического исследования. Избежать ее практически невозможно (особенно в эмпирических исследованиях). Отсюда вытекает необходимость специалисту-психологу хорошо знать основы математики и статистики и важнейшие методы математико-статистического анализа психологической информации. Неизбежность статистики в психологии обусловлена массовостью психологического материала, поскольку все время приходится один и тот же эффект регистрировать по многу раз. Причина же необходимости многократных замеров кроется в самой природе психических явлений, устойчивость которых относительна, а изменчивость абсолютна. Классическим примером тому может служить непрерывная флуктуация сенсорных порогов, породившая знаменитую «пороговую проблему». Поэтому вероятностный подход – неизбежный путь к познанию психического. А статистические методы – способ реализации этого подхода. Кстати, надо заметить, что формирующаяся с начала XX столетия новая картина мира, постепенно вытесняющая ньютонов-ско-картезианскую модель мироздания, одним из своих важнейших компонентов имеет как раз представление о преобладании статистико-вероятностных закономерностей над причинно-следственными. По крайней мере, это достаточно убедительно продемонстрировано для микроскопического (субатомного) и мегаскопического (космического) уровней организации мира [43, 101, 233, 260, 302, 409]. Логично предположить, что это в какой-то степени справедливо и для среднего (макроскопического) уровня, в границах которого и возможно, по-видимому, говорить о психике, личности и тому подобных категориях. Надо полагать, что именно в этом ключе следует понимать замечание Б. Г. Ананьева о вероятностном характере психической деятельности и о необходимости единства детерминистического и вероятностного подходов к исследованию психических явлений [10, с. 283]. В связи с этим вызывает, по меньшей мере, недоумение бытующее в психологических кругах мнение, что соединение психологической проблематики с ее математическим анализом – это «брак по принуждению или недоразумению», где психология – «невеста без приданого». Вынуждена же психология вступить в этот «брак» якобы потому, что «не смогла пока еще доказать, что строится на принципиально иных основах», нежели точные науки [344, с. 5–6]. Эти же «принципиально иные основы» вроде бы обусловлены тем, что предмет исследования психологии несопоставим по своей сложности с предметами других наук. Нам кажется, что подобный снобизм не только не уместен с точки зрения научной этики, но и не имеет оснований. Мир – един в своем бесконечном многообразии. А наука лишь попытка человечества репрезентировать этот мир в моделях (в том числе в образах), доступных пониманию человека. Причем эти модели отражают лишь отдельные фрагменты мира. Но любой из этих фрагментов так же сложен, как и мир в целом. Так что математические формулы, статистические выкладки, описания натуралиста или психологические представления – все суть более или менее адекватные формы отражения одной и той же реальности. И математика в психологии – это не инородное вкрапление, которое психологи вынуждены терпеть за отсутствием собственных точных формальных (а по возможности и «объективных») способов описания и репрезентации психологической реальности. Это – естественный код организации мира и, соответственно, естественный язык описания этой организации. Надежды некоторых психологов на временный характер зависимости психологии от математики – утопия. Психология использует математику не потому, что «за неимением гербовой пишет на простой», т. е. «пока» не имеет своих точных и объективных приемов анализа и объяснения психических феноменов, а потому, что математический язык – это общенаучный язык отражения реальности. И в этом смысле математику действительно можно признать «царицей наук». Психологии этот язык присущ так же, как любой другой отрасли научного знания. Вопрос лишь в том, насколько психология этот язык освоила. Таким образом, психологии вовсе не требуется доказывать, что она «может существовать независимо от математики» и эмансипироваться вплоть до «развода» с нею. Симптоматично в этом отношении формирование в последние годы новой психологической дисциплины – математической психологии [363]. Итак, утверждения о временном мезальянсе психологии с математикой, на наш взгляд, не состоятельны, сколь бы образны и метафоричны они ни были. Это – естественное единство. Второе замечание касательно применения статистики в психологии заключается в предостережении: нельзя позволить втянуть себя в так называемую «статистическую мясорубку», когда полагают, что, пропустив через математическую обработку любой материал, можно получить какие-то зависимости, выявить какие-нибудь закономерности и факты. Без гипотезы и без продуманного подбора исходных данных научного результата ожидать только за счет применения статистики нельзя. Необходимо знать, что мы хотим получить от применения статистики и какие методы обработки подходят к условиям и задачам исследования. К тому же надо заметить, что психологу не всегда по силам понять, что происходит с исходным психологическим материалом в процессе его статистического «прокручивания». Для уяснения некоторых операций внутри того или иного статистического метода (например, «варимакс-вращений» в факторном анализе) требуется специальная углубленная подготовка. Некоторые из этих операций базируются на тех или иных постулатах, не всегда подходящих к рабочей гипотезе пользователя. Поэтому для оценки адекватности, валидности намеченного метода иногда требуются весьма специфические знания. Апелляция к частоте и привычности использования в психологической практике таких матметодов не всегда спасает дело. И тогда эти приемы обработки данных становятся действительно «черным ящиком» и «статистической мясорубкой». Поэтому не следует стремиться к излишне сложным методам в погоне за модой или с сомнительной целью повысить уровень «научности» своей работы. Непродуманная стрельба «из пушки по воробьям» только ведет к неоправданным затратам и запутыванию психологической идеи исследования. Следует согласиться с выводом Е. В. Сидоренко, что «чем проще методы математической обработки, чем ближе они к реально полученным эмпирическим данным, тем более надежными и осмысленными получаются результаты» [344, с. 7]. Кроме того, нельзя забывать, что статистические методы – это вспомогательное оружие психолога, призванное лишь усилить исследовательскую мысль. Это лишь «деревья», за которыми должен быть виден «лес» – основная психологическая идея. Тем более что, как только что было сказано, всеобщность детерминации (по крайней мере, причинной) вызывает большие сомнения. Следовательно, поиск с помощью лишь математической обработки психологических зависимостей, тем более зависимостей функциональных, дело не очевидное и чреватое заблуждениями. Психологам хорошо известно, что в реальности невозможно найти ни «чистых», ни «среднестатистических» психологических типов. Это заставляет даже некоторых исследователей отказаться от рассмотрения каждого отдельного психического явления как эманации какой-то общей закономерности и тем паче «отказаться от того, чтобы считать отдельную личность случайной величиной, случайным проявлением более закономерного среднегруп-пового индивида» [345, с. 40]. После этих замечаний с удовольствием повторим вслед за Мак-Коннелом: «Статистика – это не математика, а прежде всего способ мышления, и для ее применения нужно лишь иметь немного здравого смысла и знать основы математики» [89, т. 2, с. 277]. В дальнейшем изложении ограничимся освещением необходимого Minimum minimori в этой области, а именно важнейших элементов описательной и корреляционной статистики. Более подробные сведения по этим разделам статистической науки и о приемах индуктивной статистики применительно к психологической специфике можно почерпнуть из работ [87, 127, 344, 364]. Всю совокупность полученных данных можно охарактеризовать в сжатом виде, если удается ответить на три главных вопроса: 1) какое значение наиболее характерно для выборки?; 2) велик ли разброс данных относительно этого характерного значения, т. е. какова «размытость» данных?; 3) существует ли взаимосвязь между отдельными данными в имеющейся совокупности и каковы характер и сила этих связей? Ответами на эти вопросы служат некоторые статистические показатели исследуемой выборки. Для решения первого вопроса вычисляются меры центральной тенденции (или локализации), второго – меры изменчивости (или рассеивания), третьего – меры связи (или корреляции). Эти статистические показатели приложимы к количественным данным (порядковым, интервальным, пропорциональным). Данные качественные (номинативные) поддаются математическому анализу с помощью дополнительных ухищрений, которые позволяют использовать элементы корреляционной статистики. Меры центральной тенденции Меры центральной тенденции (м. ц. т.) – это величины, вокруг которых группируются остальные данные. Эти величины являются как бы обобщающими всю выборку показателями, что, во-первых, позволяет по ним судить о всей выборке, а во-вторых, дает возможность сравнивать разные выборки, разные серии между собой. К мерам центральной тенденции относятся: среднее арифметическое, медиана, мода, среднее геометрическое, среднее гармоническое. В психологии обычно используются первые три. Среднее арифметическое (М) – это частное от деления всех значений (X) на их количество (N): М = SX / N. Медиана (Me) – это значение, выше и ниже которого количество отличающихся значений одинаково, т. е. это центральное значение в последовательном ряду данных. Примеры: 3, 5, 7, 9, 11, 13, 15 Me = 9. 3, 5, 7, 9, 11, 13, 15, 17 Me =10. Из примеров ясно, что медиана не обязательно должна совпадать с имеющимся замером, это точка на шкале. Совпадение происходит в случае нечетного числа значений (ответов) на шкале, несовпадение – при четном их числе. Мода (Мо) – это значение, наиболее часто встречающееся в выборке, т. е. значение с наибольшей частотой. Пример: 2, 6, 6, 8, 9, 9, 9, 10 Мо = 9. Если все значения в группе встречаются одинаково часто, то считается, что моды нет (например: 1, 1, 5, 5, 8, 8). Если два соседних значения имеют одинаковую частоту и они больше частоты любого другого значения, мода есть среднее этих двух значений (например: 1, 2, 2, 2, 4, 4, 4, 5, 5, 7 Мо = 3). Если то же самое относится к двум несмежным значениям, то существует две моды, а группа оценок является бимодальной (например: 0, 1, 1, 1, 2, 3, 4, 4, 4, 7 Мо = 1 и 4). При выборе м. ц. т. следует учесть, что: 1) в малых группах мода может быть нестабильна. Пример: 1, 1, 1, 3, 5, 7, 7, 8 Мо = 1. Но стоит одной единице превратиться в нуль, а другой – в двойку, и Мо = 7; 2) на медиану не влияют величины «больших» и «малых» значений; 3) на среднее влияет каждое значение. Обычно среднее применяется при стремлении к наибольшей точности и когда впоследствии нужно будет вычислять стандартное отклонение. Медиана – когда в серии есть «нетипичные» данные, резко влияющие на среднее (например: 1, 3, 5, 7, 9, 26, 13). Мода – когда не нужна высокая точность, но важна быстрота определения м. ц. т. 4.6.3.3. Меры изменчивости (рассеивания, разброса) Это статистические показатели, характеризующие различия между отдельными значениями выборки. Они позволяют судить о степени однородности полученного множества, о его компактности, а косвенно – и о надежности полученных данных и вытекающих из них результатов. Наиболее используемые в психологических исследованиях показатели: размах, среднее отклонение, дисперсия, стандартное отклонение, полуквартильное отклонение. Размах (Р) – это интервал между максимальным и минимальным значениями признака. Определяется легко и быстро, но чувствителен к случайностям, особенно при малом числе данных. Примеры: 0, 2, 3, 5, 8 (Р = 8-0 = 8); -0.2, 1.0, 1.4, 2.0 (Р = 2, 0-(-0, 2) = 2, 2); 0, 2, 3, 5, 67 (Р = 67-0 = 67). Среднее отклонение (МД) – это среднеарифметическое разницы (по абсолютной величине) между каждым значением в выборке и ее средним: МД = ∑ d / N, где d = |Х– M|; М – среднее выборки; X – конкретное значение; N – число значений. Множество всех конкретных отклонений от среднего характеризует изменчивость данных, но если их не взять по абсолютной величине, то их сумма будет равна нулю. И вся информация пропадает. МД показывает степень скученности данных вокруг среднего. Кстати, иногда при определении этой характеристики выборки вместо среднего (М) берут иные меры центральной тенденции – моду или медиану. Дисперсия (Д) (от лат. dispersus – рассыпанный). Другой путь измерения степени скученности данных – это избегание нулевой суммы конкретных разниц (d = Х-М) не через их абсолютные величины, а через их возведение в квадрат, и тогда получают дисперсию: Д = ∑ d2 / N – для больших выборок (N > 30); Д = ∑ d2/ (N-1) – для малых выборок (N < 30). Стандартное отклонение (а). Из-за возведения в квадрат отдельных отклонений d при вычислении дисперсии получается очень не наглядная величина, далекая от самих отклонений. Чтобы этого избежать и получить характеристику, сопоставимую со средним отклонением, проделывают обратную математическую операцию – из дисперсии извлекают квадратный корень. Его положительное значение и принимается за меру изменчивости, именуемую среднеквадратическим или стандартным отклонением:
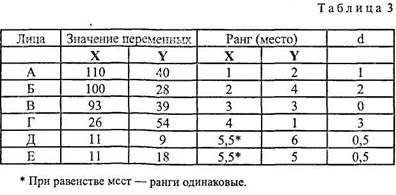
МД, Д и s применимы для интервальных и пропорциональных данных. Для порядковых данных обычно в качестве меры изменчивости берут полуквартилыше отклонение (Q), именуемое еще полукваргттьным коэффициентом или полумеждуквартильным размахом. Вычисляется этот показатель следующим образом. Вся область распределения данных делится на четыре равные части. Если отсчитывать наблюдения начиная от минимальной величины на измерительной шкале (на графиках, полигонах, гистограммах отсчет обычно ведется слева направо), то первая четверть шкалы называется первым квартилем, а точка, отделяющая его от остальной части шкалы, обозначается символом Q1. Вторые 25% распределения – второй квартиль, а соответствующая точка на шкале – Q2. Между третьей и четвертой четвертями распределения расположена точка Q3. Полуквартильный коэффициент определяется как половина интервала между первым и третьим квартилями: Q = (Q3 – Q1)/2. Понятно, что при симметричном распределении точка Q2 совпадет с медианой (а следовательно, и со средним), и тогда можно вычислить коэффициент Q для характеристики разброса данных относительно середины распределения. При несимметричном распределении этого недостаточно. И тогда дополнительно вычисляют еще два коэффициента Q – для правого и левого участков: Qлев. = (Q2-Q1)/2; Qправ.= (Q3-Q2)/2 Меры связи Предыдущие показатели, именуемые статистиками, характеризуют совокупность данных по одному какому-либо признаку. Этот изменяющийся признак называют переменной величиной или просто «переменной». Меры связи же выявляют соотношения между двумя переменными или между двумя выборками. Например, нужно установить, существует ли связь между ростом и весом человека, между типом темперамента и успешностью решения интеллектуальных задач и т. д. Или, скажем, надо выяснить, принадлежат ли две выборки к одной популяции или к разным. Эти связи, или корреляции (от лат. correlatio – соотношение, взаимосвязь), и выявляют через вычисление коэффициентов корреляции (R), если переменные находятся в линейной зависимости между собой. Считается, что большинство психических явлений подчинено именно линейным зависимостям, что и предопределило широкое использование методов корреляционного анализа. Но наличие корреляции не означает, что между переменными существует причинная (или функциональная) связь. Функциональная зависимость [у = f(x)] – это частный случай корреляции. Даже если связь причинна, корреляционные показатели не могут указать, какая из двух переменных причина, а какая – следствие. Кроме того, любая обнаруженная в психологии связь, как правило, существует благодаря и другим переменным, а не только двум рассматриваемым. К тому же взаимосвязи психологических признаков столь сложны, что их обусловленность одной причиной вряд ли состоятельна, они детерминированы множеством причин. Виды корреляции: I. По тесноте связи: 1) Полная (совершенная) – R=l. Констатируется обязательная взаимозависимость между переменными. Здесь уже можно говорить о функциональной зависимости. Например: связь между стороной квадрата и его площадью, между весом и объемом и т. п. 2) Отсутствие связи – R = 0. Например: между скоростью реакции и цветом глаз, длиной ступни и объемом памяти. 3) Частичная – 0< R< l; (меньше 0, 2) – очень слабая связь, трудно о ней говорить всерьез; (0, 2–0, 4) – корреляция явно есть, но невысокая; (0, 4-0, 6) – явно выраженная корреляция; (0, 6-0, 8) – высокая корреляция; (больше 0, 8) – очень высокая. Встречаются и другие градации оценок тесноты связи [288]. Кроме того, в психологии при оценке тесноты связи используют так называемую «частную» классификацию корреляционных связей. Эта классификация ориентирована не на абсолютную величину коэффициентов корреляции, а на уровень значимости этой величины при определенном объеме выборки. Эта классификация применяется при статистической оценке гипотез. Тогда чем больше выборка, тем меньшее значение коэффициента корреляции может быть принято для признания достоверности связей. А для малых выборок даже абсолютно большое значение R может оказаться недостоверным [344]. II. По направленности: 1) Положительная (прямая). Коэффициент R со знаком «плюс» означает прямую зависимость: увеличение значения одной переменной влечет увеличение другой. Например, связь между числом повторений и запоминанием положительна. 2) Отрицательная (обратная). Коэффициент R со знаком «минус» означает обратную зависимость: увеличение значения одной переменной влечет уменьшение другой. Например, увеличение объема информации ухудшает ее запоминание. III. По форме: 1) Прямолинейная. При такой связи равномерным изменениям одной переменной соответствуют равномерные изменения другой. Например, последовательному изменению величины стороны прямоугольника соответствует столь же последовательное изменение его площади. Если говорить не только о корреляциях, но и о функциональных зависимостях, то такие формы зависимости называют пропорциональными. В психологии строго прямолинейные связи – явление не частое. Например, иногда наблюдается прямолинейная связь между тренированностью и успешностью деятельности. 2) Криволинейная. Это связь, при которой равномерное изменение одного признака сочетается с неравномерным изменением другого. Эта ситуация типична для психологии. Классическими иллюстрациями могут служить знаменитые законы Йеркса–Додсона и Вебера-Фехнера. Согласно первому успешность деятельности при увеличении мотивации к ней изменяется по колоколообраз-ной кривой: до определенного уровня рост мотивации сопровождается увеличением успешности, после чего с повышением мотивации успешность деятельности спадает. Согласно второму закону интенсивность наших ощущений при равномерном увеличении стимула увеличивается по логарифмической кривой, т. е. при изменении стимуляции в арифметической прогрессии ощущения изменяются в геометрической прогрессии. Формулы коэффициента корреляции 1. При сравнении порядковых данных применяется коэффициент ранговой корреляции по Ч. Спирмену (р): p = 6Sd2/N(N2-l), где d – разность рангов (порядковых мест) двух величин; N – число сравниваемых пар величин двух переменных (X и Y). Пример вычисления р дан в таблице 3.
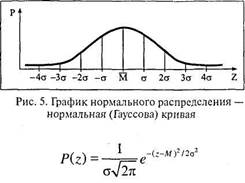
2. При сравнении метрических данных используется коэффициент корреляции произведений по К.Пирсону (г): r = Sxy/Nσ xσ y, где х – отклонение отдельного значения X от среднего выборки (Мх); у – то же для Y; σ х – стандартное отклонение для X; σ у – то же для Y; N – число пар значений X и Y. Рекомендации по анализу коэффициентов корреляции 1. R – это не процент соответствия переменных, а только степень связи. 2. Сравнение коэффициентов дает только неметрическуюинформацию, т. е. нельзя говорить, на сколько или во сколько раз один больше или меньше другого. Они сравниваютсяв оценках «равно – неравно», «больше – меньше». Можно сказать, что один коэффициент превышает (слабо, заметно, очень заметно) другой, но какова величина этого превышения говорить нельзя. 3. Существуют явления, в которых заведомо известно, чтомежду ними слабая (или сильная) связь. Тогда R приобретает не абсолютный, а относительный характер. Так, для слабой связи R = 0, 2 может считаться высоким показателем, а для сильной и R = 0, 7 будет считаться низким. 4. Иногда и слабая корреляция заслуживает внимания, еслиэто обнаружено впервые, т. е. выявлена новая связь. 5. Надежность R зависит от надежности исходных данных. Нормальное распределение Мы уже знакомы с понятиями «распределение», «полигон» (или «частный полигон») и «кривая распределения». Частным случаем этих понятий является «нормальное распределение» и «нормальная кривая». Но этот частный вариант очень важен при анализе любых научных данных, в том числе и психологических. Дело в том, что нормальное распределение, изображаемое графически нормальной кривой, есть идеальное, редко встречающееся в объективной действительности распределение. Но его использование многократно облегчает и упрощает обработку и объяснение получаемых в натуре данных. Более того, только для нормального распределения приведенные коэффициенты корреляции имеют истолкование в качестве меры тесноты связи, в других случаях они такой функции не несут, а их вычисление приводит к труднообъяснимым парадоксам. В научных исследованиях обычно принимается допущение о нормальности распределения реальных данных и на этом основании производится их обработка, после чего уточняется и указывается, насколько реальное распределение отличается от нормального, для чего существует ряд специальных статистических приемов. Как правило, это допущение вполне приемлемо, так как большинство психических явлений и их характеристик имеют распределения, очень близкие к нормальному. Так что же такое нормальное распределение и каковы его особенности, привлекающие ученых? Нормальным называется такое распределение величины, при котором вероятность ее появления и не появления является одинаковой. Классическая иллюстрация – бросание монеты. Если монета правильна и броски выполняются одинаково, то выпадение «орла» или «решки» равновероятно. То есть «орел» с одинаковой вероятностью может выпасть и не выпасть, то же касается и «решки». Мы ввели понятие «вероятность». Уточним его. Вероятность – это ожидаемая частота наступления события (появления – не появления величины). Выражается вероятность через дробь, в числителе которой – число сбывшихся событий (частота), а в знаменателе – предельно возможное число этих событий. Когда выборка (число возможных случаев) ограниченна, то лучше говорить не о вероятности, а о частости, с которой мы уже знакомы. Вероятность предполагает бесконечное число проб. Но на практике эта тонкость часто игнорируется. Пристальный интерес математиков к теории вероятности в целом и к нормальному распределению в частности появляется в XVII веке в связи со стремлением участников азартных игр найти формулу максимального выигрыша при минимальном риске. Этими вопросами занялись знаменитые математики Я. Бернулли (1654-1705) и П. С. Лаплас (1749-1827). Первым математическое описание кривой, соединяющей отрезки диаграммы распределения вероятностей выпадения «орлов» при многократном бросании монет, дал Абрахам де Муавр (1667-1754). Эта кривая очень близка к нормальной кривой, точное описание которой дал великий математик К. Ф. Гаусс (1777-1855), чье имя она и носит поныне. График и формула нормальной (Гауссовой) кривой выглядит следующим образом.
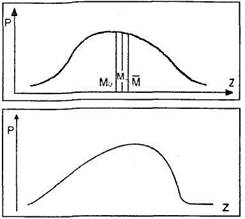
где Р – вероятность (точнее, плотность вероятности), т. е. высота кривой над заданным значением Z; е – основание натурального логарифма (2.718...); π = 3.142...; М – среднее выборки; σ – стандартное отклонение. Свойства нормальной кривой 1. Среднее (М), мода (Мо) и медиана (Me) совпадают. 2. Симметричность относительно среднего М. 3. Однозначно определяется всего лишь двумя параметрами – М и о. 4. «Ветви» кривой никогда не пересекают абсциссу Z, асимптотически к ней приближаясь. 5. При М = 0 и о =1 получаем единичную нормальную кривую, так как площадь под ней равна 1. 6. Для единичной кривой: Рм = 0.3989, а площадь под кривой в диапазоне: -σ до +σ = 68.26%; -2σ до + 2σ = 95.46%; -Зσ до + Зσ = 99.74%. 7. Для неединичных нормальных кривых (М ≠ 0, σ ≠ 1) закономерность по площадям сохраняется. Разница – в сотых долях. Вариации нормального распределения Представленные ниже вариации относятся не только к нормальному распределению, но к любому. Однако для наглядности мы их приводим здесь. 1. Асимметрия – неодинаковость распределения относительно центрального значения.
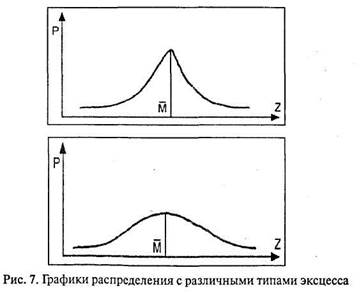
Рис. 6. Графики асимметричного распределения Асимметрия – третий показатель, описывающий распределение наряду с мерами центральной тенденции и изменчивостью. Эксцесс – показатель, характеризующий скорость нарастания концентрации данных к центральному значению. На графиках это выражается «островершинностью» или «плосковершинностью».
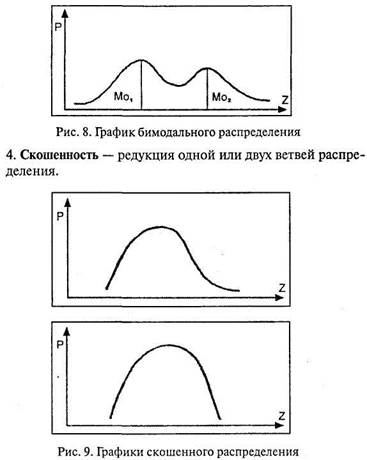
Эксцесс – четвертый основной показатель распределения. 3. Бимодальность – распределение с двумя классами данных в выборке. Об этом эффекте уже говорилось при рассмотрении моды (Мо). На графике это выражается «двувершинностью».
Популярное:
|
Последнее изменение этой страницы: 2016-03-17; Просмотров: 727; Нарушение авторского права страницы