
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Резолюция в логике высказываний
Пусть А, В, С... - атомарные формулы логики высказываний. Формулу вида (AÚ BÚ...Ú D), где А, В, …, D - атомарные формулы, назовем дизъюнктом. Говорят, что два дизъюнкта С1 и С2 содержат контрарную пару литер X и C1 = RÚ...Ú X, C2 = QÚ...Ú Пусть, например С1 = А Ú X и С2 = В Ú Тогда дизъюнкт (АÚ В) является резолюцией дизъюнктов С1 и С2. Лемма. Пусть С1 и С2 - два дизъюнкта и I - атомарная формула. Если IÎ C1 и Доказательство. Пусть СR - резольвента дизъюнктов С1 и С2. Лемма утверждает, что C1, C2 |¾ CR, что равносильно тождественной истинности формулы C1Ù C2 ® CR. Последняя ложна, если С1 Ù С2 истинно и СR ложно. Пусть С1 = СR Ú I и C2 = СR Ú Имеем C1 Ù C2 = (CR Ú I) Ù (CR Ú Следовательно, в силу преобразований логики высказываний С1 Ù C2 эквивалентна СR, а это значит что С1Ù C2 ®CR тождественно истинная формула. На основании метода резолюций устанавливается невыполнимость некоторого множества дизъюнктов. Пусть требуется доказать, что формула j выводима из формул e1, e2, ..., en, т.е. установить, что формула e1 Ù e2 Ù...Ù en ® j (7.2) тождественно истинна. Это эквивалентно доказательству того, что формула e1 Ù e2 Ù...Ù en Ù является тождественно ложной. Обозначим через - логическую константу " ложь" (пустой дизъюнкт). Считается, что множество формул f1, f2, ..., ft противоречиво (невыполнимо), если f1 Ù f2 Ù...Ù ft ® (7.4) является тождественно истинной. Таким образом, если доказывается формула (7.3), то тем самым устанавливается невыполнимость множества формул f1, f2, ..., ft. Из всех этих рассуждений логически следует, что невыполнимость (7.3) эквивалентна выводимости из множества формул e1, e2, ..., en, пустого дизъюнкта. Очевидно, что пустой дизъюнкт () является резольвентой дизъюнктов С1 = I и С2 = В качестве примера установим невыполнимость множества дизъюнктов: C1 = p Ú q; C2 = p Ú r; C3 = C4 = 1. Резольвентой С2 и С4 является С5 = r. 2. Резольвентой С5 и С3 является дизъюнкт С6 = 3. Резольвентой С6 и С1 является дизъюнкт С7 = p. 4. Резольвентой С4 и С7 является пустой дизъюнкт . Существует несколько стратегий резолюционного вывода. Проблема выбора эффективной стратегии связана с уменьшением длины вывода или, в конечном итоге, сокращением числа лишних порожденных резольвент, которые не влияют на выводимость пустого дизъюнкта. Рассмотрим две основные стратегии порождения резольвент: линейную резолюцию и семантическую резолюцию.
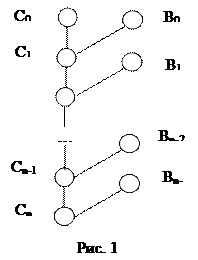
Линейная резолюция в L Определение. Для данного множества S дизъюнктов и дизъюнкта С0 из S линейный вывод дизъюнкта Сn из S с верхним дизъюнктом С0 - это вывод, изображенный на рис. 1, где 1) для i = 0, 1, ..., n-1 дизъюнкт Ci+1 есть резольвента дизъюнкта Сi и Вi; дизъюнкты Ci называется центральными Вi - боковыми. 2) Вi либо принадлежит S, либо есть Сj для некоторого j < i. Показано, что линейная резолюция является полной, т.е. для любого противоречивого множества дизъюнктов всегда выводится пустой дизъюнкт. Дополнительное усиление рассмотренной стратегии предложено Лавлендом, Ковальским и Кюнером. Ими установлены условия, при которых центральный дизъюнкт позднее может участвовать в роли бокового дизъюнкта. Это свойство позволяет сократить число лишних дизъюнктов, поскольку становится ясно, будет или нет тот или иной центральный дизъюнкт использован для порождения пустого дизъюнкта. Прежде всего, множество литер произвольным образом упорядочивается, т.е. считается известным, какую литеру поставить левее в записи дизъюнкта, а какую правее. Например, пусть P > Q > R > При порождении резольвент отсекаемая литера включается в представление резольвенты, но при этом указывается в рамке. Например, если C1 = P Ú Q C2 =
P Ú Ú R. Литеры в рамке служат для учета отрезанных литер: они не участвуют в дальнейшем порождении резольвент. Рассмотрим дизъюнкт специального вида, в котором последняя литера не обрамлена и для этой последней литеры имеется контрарная обрамленная литера, например, Ú Ú Дизъюнкт такого типа называется редуцируемым. Если С - редуцируемый дизъюнкт, то его можно сократить за счет отбрасывания последней литеры, а также всех обрамленных литер, за которыми не следует необрамленной литеры. Для редуцируемого дизъюнкта Ú Ú Следующая лемма формализует введенные определения. Лемма. Если в некотором выводе С является редуцируемым упорядоченным дизъюнктом, то существует центральный упорядоченный дизъюнкт Cj (j< 1), такой, что редукция Сi+1 дизъюнкта Ci является резольвентой Сi и Сj. Доказательство. Если Сk и Сk+1, два соседних упорядоченных дизъюнкта на рис.7.1, то все литеры дизъюнкта Сk содержатся в Сk+1 (обрамленные литеры учитываются). Действительно, Сk+1 представляется как
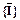 ), ),
где I - отсекаемая литера.
 , где Р - некоторая дизъюнкция литер. Но тогда резольвентой Сi и P Ú является Сi Ú P = Ci поскольку Р содержится в С. , где Р - некоторая дизъюнкция литер. Но тогда резольвентой Сi и P Ú является Сi Ú P = Ci поскольку Р содержится в С.
С учетом доказанной леммы упорядоченный вывод (называемый OL - выводом ) определяется следующим образом: 1) Каждый дизъюнкт Вi либо принадлежит S, либо является ранее порожденным центральным дизъюнктом. 2) Если Сi редуцируемый упорядоченный дизъюнкт, то Сi+1 является результатом редукции Сi. В противном случае Сi+1 есть резольвента Сi и Вi, причем Вi принадлежит исходному множеству дизъюнктов и отсекаемая литера в Сi последняя. 3) В вывод не входят тавтологии. Пример. Построим OL - вывод пустого дизъюнкта из множества дизъюнктов: C1 = P Ú Q, C2 = R Ú C3 = R Ú C4 = C5 = P > Q > R > 1. Находим резольвенту дизъюнктов С1 и С2, для которых отсекаемая литера последняя
2. Находим резольвенту дизъюнктов С6 и С4:
 . .
3. Поскольку дизъюнкт С7 редуцируем, то сразу находим С8 = Р как результат редукции С7. 4. Находим резольвенту дизъюнктов С8 и С3:
5. Находим резольвенту С9 и С5:
 . .
C10 является редуцируемым дизъюнктом. Следовательно, его редукция сразу дает C11 = . 3.5.2.2 Метод линейного вывода в L Лавленда, Ковальского и Кюнера Рассмотрим пример линейного вывода. Пусть дано
Введем дополнительные определения: 1. Входная резолюция – это применение правила резолюции, в котором одна из посылок – входной дизъюнкт (входная резолюция – это частный случай линейной резолюции). 2. Входным дизъюнктом является каждый член исходного множества S дизъюнктов. 3. Входной вывод – это вывод, в котором любое применение резолюции является входной резолюцией. 4. Входное опровержение – это входной вывод дизъюнкта ÿ из S. 5. Упорядоченный дизъюнкт – это последовательность различных литер. Это означает, что мы должны установить порядок всех литер в дизъюнкте. Примем соглашение, что литера L2 меньше, чем литера L1, в дизъюнкте С в точности тогда, когда L2 следует за L1 в последовательности, указанной в задании этого дизъюнкта. Таким образом, последняя литера всегда будет считаться наибольшей в дизъюнкте. Уточним, что же предложили Лавленд, Ковальский и Кюнер. Для этого рассмотрим пример.
Пусть С1 и С2 следующие упорядоченные дизъюнкты:
Результатом резолюции этой пары будет упорядоченный дизъюнкт – (p Ú r). При этом литеры q и 1. Обрамленную литеру должны выбрасывать только тогда, когда за ней не следует никакая необрамленная литера. 2. Если в упорядоченном дизъюнкте имеется более одного вхождение одной и той же необрамленной литеры, то всегда сохраняем самое левое вхождение, остальные совпадающие отбрасываем. Этот процесс называется отождествлением влево. Перерисуем предыдущий пример
Это и есть необходимо и достаточное условие использования централизованного дизъюнкта в качестве бокового. В нашем случае это дизъюнкт р.
Применяя резолюцию дизъюнктов
Все литеры в результате обрамлена, т.е. за ними не следует необрамленная литера, поэтому мы их удаляем все, в результате получаем пустой дизъюнкт, т.е линейное опровержение.
Эффективная реализация Условимся обозначать боковой дизъюнкт Bi сбоку от ребра Ci, тогда линейный вывод можно представить в виде дерева. Рассмотрим его на примере
Процесс закончен, так как порожден. Самая левая ветвь соответствует OL – опровержению. Метод поиска в глубину Определение: cc) глубина дизъюнкта С0 в OL - выводе с верхним укороченным дизъюнктом С0 равна 0; dd)если глубина некоторого укороченного дизъюнкта с равна k и R – есть укороченного результата дизъюнкции С с некоторым боковым дизъюнктом, то глубина дизъюнкта R равна k+1; ee) длина доказательства (опровержения) с верхним дизъюнктом С0 – это глубина пустого дизъюнкта. Пусть d* – заранее заданное пороговое число. Описание метода: 1. Положить CLIST = (C0) 2. Если CLIST пуст, закончим, не найдя доказательства, иначе на следующий шаг. 3. Пусть С – первый упорядоченный дизъюнкт в списке CLIST. Выбросим С из CLIST. Если глубина С > d*, то на шаг 2, иначе на шаг 4. 4. Найдем все укор. дизъюнкты в S, которые могут быть боковыми дизъюнктами для С. Если таких боковых дизъюнктов нет, то на шаг 2. В противном случае построим результаты R1, …, Rm дизъюнкта С с его боковыми дизъюнктами. Пусть Ri* есть редукция дизъюнкта Ri, если Ri редуцируем. В противном случае положим Ri*=Ri. 5. Если какой-либо из дизъюнктов Rq* (1£ q£ m) пуст, то закончим, получив доказательство, иначе на следующий шаг. 6. Поместим R1*, …, Rm* (в произвольном порядке) в начало списка CLIST и перейдем к шагу 2.
Смэйгл и Нильсон модифицировали этот метод. В модифицированном методе поиска в глубину в CLIST помещаются пары (С, В). В шестом шаге, если нет пары для Ri*, то эту резольвенту отбрасываем. Эвристики поиска в дереве Использование эвристики может привести к тому, что доказательство не будет найдено, хотя оно и существует. Однако она может значительно ускорить работу модифицированного метода поиска в глубину. В области доказательства имеется много эвристик. Обсудим некоторые из них: А. Стратегия отбрасывания. Говорят, что упорядоченный дизъюнкт С1 поглощает другой упорядоченный дизъюнкт С2, если дизъюнкт, состоящий из необрамленных литер в С1, поглощает дизъюнкт, состоящий из необрамленных литер в С2. Упорядоченный дизъюнкт называется тавтологией, если он содержит контрарную пару необрамленных литер. В модифицированном методе поиска в глубину в конце шага 4 нужно проверить, является ли Ri* (i=1, …, m) тавтологией. Если Ri* – тавтология, то отбрасываем его. Кроме того, следует отбросить Ri*, если в CLIST имеется пара (С, В) такая, что Ri* поглощается дизъюнктом С. В. Стратегия предпочтения кратчайших дизъюнктов. Эта стратегия вводит в модифицированный метод поиска в глубину упорядочение пар (С, В) в CLIST, чтобы лучшие пары стояли первыми. Оценивать пары рекомендуется по длине получаемого результата Length(R). Чем короче длина, тем лучше пара (С, В). В действительности не надо вычислять R, чтобы найти ее длину, достаточно оценки: Length (R) £ Length (C) + Length (B) – 2. Смэйгл рекомендует упорядочивать пары (С, В) в списке CLIST по возрастанию. С. Использование эвристических оценочных функций Определим h*(C, B) для пары (С, В), как число применений правила резолюции в минимальном доказательстве с верхним укор. дизъюнктом С и первым боковым дизъюнктом В. Однако h*(C, B) заранее неизвестна, поэтому введем оценку h(C, B) величины h*(C, B). Предположим, что h(C, B) можно выразить в виде: h(C, B) = w0+w1f1(C, B)+…+wnfn(C, B) (1), где fi (i=1, …, n) – вещественная функция от С и В, а wi – вес, сопоставленный величине fi. (fi называют характеристикой пары (С, В)). Возможны следующие характеристики пар: 1. Число необрамленных литер в C. 2. Число обрамленных литер в С. 3. Число боковых дизъюнктов для С. 4. Число констант в последней литере из С. 5. Число функциональных символов в последней литере из С. 6. Число обрамленных литер в С, поглощающих последнюю литеру из В. 7. Число различных переменных в С и В. 8. length (C) + length (B) – 2 9. Число констант в С / (1+число переменных в С) 10. Число констант в С / (1+число различных переменных в С) 11. Глубина С. 12. Число необрамленных литер, входящих как в С, так и в В. 13. Число литер в В, имеющих обрамленное дополнение в С. 14. Число различных предикатных символов в С и В. Функция h(C, B) может быть линейной или нелинейной от f1(C, B), …, fn(C, B), будем называть ее эвристической оценочной функцией, или просто оценочной функцией. Будем помещать пары (С, В) в CLIST по возрастанию значений h(C, B). Рассмотрим один из способов определения подходящих величин w0, …, wn.Способ определения значений множества w. Допустим, что мы знаем величины h*(C1, B1), …, h(Cq, Bq), тогда определение w0, …, wn таких, что минимально выражение Определим матрицы H, F и W следующим образом:
Тогда W=(F’F)–1F’H (3), где F’ – транспонированная матрица F, (F’F)–1 – обратная матрица к (F’F). Рассмотрим пример. Занумеруем все дизъюнкты дерева. Используем следующие характеристики. f1(C, B) = length (C) + length (B) – 2 f2(C, B) = число обрамленных литер в С f3(C, B) = число необрамленных литер, входящих как в С, так и в В f4(C, B) = число литер в В, имеющих обрамленное дополнение в С f5(C, B) = число обрамленных литер в С, поглощающих последнюю литеру из В Вычисляя характеристики для любой пары дерева, получим:
Вычисляя по (3) W, получим:
Тогда линейная оценочная функция примет вид: h(C, B)=0, 30+1, 68f1(C, B)+0, 76 f2(C, B)–0, 24 f3(C, B)–1, 44 f4(C, B)+0, 6 f5(C, B) Если упорядочить пары в CLIST непосредственно перед 3 шагом модифицированного метода поиска в глубину, то получим 144 ветки дерева. Конечно, чтобы оценочная функция была хорошей, Но нас должен волновать вопрос и о том, необходимо рассмотреть как можно больше примеров.является ли выбранное множество характеристик хорошим? Конечно, если оценочная функция обобщается на новые примеры, то можно считать это множество хорошим, в противном случае его надо менять. Семантическая резолюция Обратимся теперь к стратегии семантической резолюции, предложенной Слэйглом. Стратегия на основе семантической резолюции также использует упорядочение литер, как и OL -резолюция. Кроме того, эта стратегия основывается на разделении всего множества исходных и порождаемых дизъюнктов на два непересекающихся класса, назовем их Т и F. Такое разбиение возможно, если задать некоторую интерпретацию I для формул исходного множества. В интерпретации I часть дизъюнктов окажется истинной, а часть ложной. Множество истинных дизъюнктов в интерпретации I - это по определению множество Т; множество ложных дизъюнктов в интерпретации I - это по определению есть множество F. При построении вывода требуется выполнение двух условий: 1) резольвента строится для дизъюнктов С1 и С2 таких, что С1 Î T, а C2 Î F 2) отсекаемая литера в дизъюнкте С2 должна быть самой правой литерой. Пусть E1, E2, ..., Eq некоторое множество дизъюнктов, принадлежащих F, а N - дизъюнкт из Т. Тогда множество { E1, E2, ..., Eq, N } называется клашем, если выполняется следующее условие: (i) R1 = N; (ii) i < 1, Ri+1 есть резольвента Ri-1 и Ei-1; отсекаемая литера - старшая в Ei (самая правая); (iii) Rq+1 Î F. Rq+1 называется резольвентой данного клаша. Пример. Пусть C1 = R Ú C2 = P Ú R, C3 = Q Ú R, C4 = P > Q > R > Пусть в интерпретации I R - ложен, Р - ложен, Q - ложен. Тогда клашами являются множества K1 = {С3, C4}, K2 = {C2, C4}. Вывод на основе семантической резолюции строится так, что каждый дизъюнкт либо принадлежит исходному множеству дизъюнктов, либо является резольвентой некоторого клаша. Так резольвентой С5 клаша К1 является Q; резольвентой С6 клаша К2 является Р. Резольвентой С5 и С1 является дизъюнкт C7 = R Ú Резольвентой С7 и С6 является дизъюнкт С8 = R. Резольвентой дизъюнктов С8 и С4 является . Резолюция в PL Применению OL-вывода в PL предшествует подготовительный этап, предложенный Девисом и Патнемом. Он включает в себя 3 стадии: 1) преобразование формулы в ПНФ; 2) преобразование матрицы в КНФ; 3) преобразование формулы в ССФ. С реализацией второй стадии вы хорошо знакомы, поэтому рассмотрим 1-ю и 3-ю стадии. В L имеются две нормальные формы: ДНФ и КНФ, в PL роль нормальной формы играет ПНФ – предваренная нормальная форма. Определение: Говорят, что формула F в PL находится в ПНФ тогда и только тогда, когда формула F имеет вид: (Q1x1)…(Qnxn)(M), где (Qixi) (i=1, …, n) есть либо (" xi), либо ($xi) и М есть формула, не содержащая кванторов. (Q1x1)…(Qnxn) называется префиксом формулы F, М – матрицей формулы F. Для преобразования формулы F в ПНФ используются законы эквивалентных преобразований, называемых законами принесения кванторов через Ù и Ú: (1а) (Qx)F(x)Ú G=(Qx)(F(x)Ú G) (1б) (Qx)F(x)Ù G=(Qx)(F(x)Ù G) (2а) Ø ((" x)F(x))=($x)(Ø F(x)) (2б) Ø (($x)F(x))=(" x)(Ø F(x)) (3а) (" x)F(x)Ù (" x)M(x)=(" x)( F(x)Ù M(x)) (3б) ($x)F(x)Ù ($x)M(x)=($ x)( F(x)Ù M(x)) Однако " и $ нельзя проносить через Ú и Ù соответственно. В подобных случаях нужно поступать специальным образом. Т.к. каждая связанная переменная в формуле может рассматриваться лишь как место для подстановки какой угодно переменной, то каждую связанную переменную х можно переименовать в z и формула (" x)M(x) перейдет в (" z)M(z), т.е. (" x)M(x)= (" z)M(z). Предположим, что мы выбираем переменную z, которая не встречается в F(x). Тогда (" x)F(x)Ú (" x)M(x)= (" x)F(x)Ú (" z)M(z) путем замены всех х, входящих в (" x)M(x) на z, тогда согласно (1а): (4а) (" x)F(x)Ú (" x)M(x)= (" x)(" z)(F(x)Ú M(z)) (4б) ($x)F(x)Ú ($x)M(x)= ($x)($z)(F(x)Ú M(z)). Преобразование формул в ПНФ: 1) используем законы, чтобы исключить логические связки ~ и É (5) F~G=(FÉ G)Ù (GÉ F) (6) FÉ G=Ø FÚ G 2) используем законы, чтобы пронести знак отрицания внутрь формулы (7) Ø (Ø F)=F (8) Ø (FÚ G)=Ø FÙ Ø G (9) Ø (FÙ G)=Ø FÚ Ø G (10) Ø ((" x)F(x))=($x)(Ø F(x)) (11) Ø (($x)F(x))=(" x)(Ø F(x)) 3) переименовываем связанные переменные, если это необходимо 4) используем законы (1а–4б), чтобы вынести кванторы в самое начало формулы для получения формулы, находящейся в ПНФ. Пример 1: приведем формулу (" x)P(x)É ($x)Q(x). (" x)P(x)É ($x)Q(x)= =Ø ((" x)P(x))Ú ($x)Q(x)= по (6) =($x)(Ø P(x))Ú ($x)Q(x)= по (2а) =($x)(Ø P(x)Ú Q(x)) по (3б) где ($x) – префикс, а (Ø P(x)Ú Q(x)) – матрица. Пример 2: получить ПНФ для формулы: (" x)(" y)(($z)P(x, z)Ù P(y, z))É ($u)Q(x, y, u))= = (" x)(" y)(Ø (($z)P(x, z)Ù P(y, z)))Ú ($u)Q(x, y, u))= по (6) = (" x)(" y)(" z)(Ø P(x, z)Ù Ø P(y, z))Ú ($u)Q(x, y, u))= по (2б) и (9) = (" x)(" y)(" z)($u)(Ø P(x, z)Ù Ø P(y, z))Ú Q(x, y, u)) по (1а) где (" x)(" y)(" z)($u) – префикс, а (Ø P(x, z)Ù Ø P(y, z))Ú Q(x, y, u)) – матрица.
Рассмотрим вопрос преобразования формулы F в скулемовскую стандартную форму (ССФ). Для этого мы должны, сохраняя противоречивость формулы, элиминировать в ней кванторы существования путем использования скулемовских функций. Условимся, что формула F находится в ПНФ: (Q1x1)…(Qnxn)M, где М в свою очередь находится в КНФ, тогда: 1) выберем самый левый квантор существования Qr в префиксе (Q1x1)…(Qnxn) (1£ r£ n); 2) если никакой " не стоит в префиксе левее Qr, то выберем новую константу С, отличную от других констант, входящих в М, заменим все хr, встречающиеся в М, на С и вычеркнем (Qrxr) из префикса; 3) Если Qs1, …, Qsm – список всех ", стоящих левее Qr, (1£ S1< S2< …< Sm< r), то выберем новый m-местный функциональный символ f, отличный от других функциональных символов, заменим все xr в M на f(xs1, …, xsm) и вычеркнем (Qr, xr) из префикса; 4) Весь этот процесс применим для всех $ в префиксе, двигаясь слева направо (следует отметить, что порядок выбора $ из префикса несущественен).
Последняя из полученных формул и есть ССФ формулы F (или просто стандартная форма формулы F). Константы и функции, используемые для замены переменных $, называются скулемовскими функциями. Пример 1: получить стандартную форму формулы ($x)(" y)(" z)($u)(" v)($w) P(x, y, z, u, v, w). В этой формуле левее ($x) нет ни одного ", значит заменяем х на а. ($u) находится (" y)(" z), значит заменяем u на f(y, z) ($w) находится (" y)(" z)(" v), значит заменяем w на g(y, z, v). Тогда (" y)(" z)(" v)P(a, y, z, f(y, z), v, g(y, z, v)) – стандартная форма. При использовании процедур опровержения не происходит потери общности, поэтому при доказательстве кванторы общности можно опустить. Рассмотрим теперь непосредственно метод резолюций, применяемый в PL при построении OL-вывода. Как и в L здесь существенным является нахождение в дизъюнкте литеры, которая контрарна литере в другом дизъюнкте. Рассмотрим дизъюнкты: С1: P(x)Ú Q(x) и C2: Ø P(f(x))Ú R(x). С первого взгляда в С1 нет литеры, контрарной какой-либо литере в С2, однако если подставить f(0) вместо x в С1 и a вместо x в C2, то получим: С1’: P(f(a))Ú Q(f(a)) и C2’: Ø P(f(a))Ú R(a). C1’ и C2’ называются основными примерами С1 и С2 соответственно, а P(f(a)) и Ø P(f(a)) контрарны друг другу. Следовательно, из C1’ и C2’ можно получить резольвенту: C3’: Q(f(a))Ú R(a). В общем случае, подставив f(x) вместо x в C1, получим: C1*: P(f(x))Ú Q(f(x)). Снова С1* есть пример С1. Литера P(f(x)) из С1* контрарна литере Ø P(f(x)), тогда резольвента С1* и С2: С3: Q(f(x))Ú R(x). При этом С3’ является примером С3. Кроме того, дизъюнкт С3 является наибольшим общим дизъюнктом в том смысле, что все другие дизъюнкты, порожденные подобным образом, есть приме С3 будем называть резольвентой С1 и С2. Таким образом, получение резольвенты из двух дизъюнктов в PL связано с подстановкой. Определение: Подстановка – это конечное множество вида {t1/v1, …, tn/vn}, где каждая vi – переменная, а ti – терм, отличный от vi, при этом все vi различны. Если t1, …, tn – основные термы, то подстановка называется основной. Подстановка, которая не содержит элементов, называется пустой и обозначается e. Будем использовать греческие буквы для обозначения подстановки. Определение: Пусть q ={t1/v1, …, tn/vn} – подстановка и Е – выражение. Тогда Еq – выражение, полученное из Е заменой одновременно всех вхождений переменной vi (1£ i£ n) в Е на ti. Еq называют примером Е. Определение: Пусть q ={t1/x1, …, tn/xn} и l={u1/y1, …, um/ym} – две подстановки. Тогда композиция q·l есть подстановка, которая получается из множества {t1/x1, …, tn/xn, u1/y1, …, um/ym} вычеркиванием всех элементов tjl/xj, для которых tjl = xj, и всех элементов ui/yi, таких что yiÎ {x1, …, xn}. Пример: q ={t1/x1, t2/x2}={f(y)/x, z/y} l ={u1/y1, u2/y2, u3/y3}={a/x, b/y, y/z}, тогда q·l={t1/x1, t2/x2, u1/y1, u2/y2, u3/y3}={ f(y)/x, z/y, a/x, b/y, y/z} Так как t2l=x2, а именно z/y, то этот элемент вычеркивается из множества y1 и y2Î {x1, x2, x3}, т.е. a/x и b/y должны быть тоже вычеркнуты. Таким образом, получаем: q·l={f(b)/x, y/z}. Композиция подстановок ассоциативна, а пустая подстановка e есть одновременно и левое и правое тождество, т.е. (q·l)·m=q·(l·m) и e·q=q·e для всех m, q, l. Популярное:
|
Последнее изменение этой страницы: 2016-03-17; Просмотров: 1548; Нарушение авторского права страницы
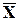 , если они имеют следующее представление:
, если они имеют следующее представление:  .
.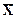 .
.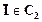 , то дизъюнкт (С1\{I})
, то дизъюнкт (С1\{I}) 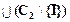 является логическим следствием дизъюнктов С1 и С2.
является логическим следствием дизъюнктов С1 и С2.  .
.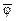 (7.3)
(7.3) 
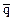 Ú
Ú 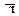 ;
; 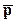 .
. 
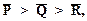 тогда считаем, что дизъюнкт PÚ QÚ
тогда считаем, что дизъюнкт PÚ QÚ  записан верно, а PÚ
записан верно, а PÚ  Ú Q - нет.
Ú Q - нет. то резольвента С1 и С2 имеет вид
то резольвента С1 и С2 имеет вид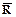

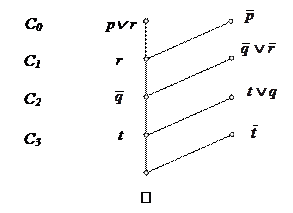

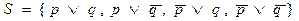 Здесь дизъюнкт p не является входным дизъюнктом. При этом легко видеть, что входное опровержение для исходного множества S отсутствует. Поэтому неизбежно использование одного из центральных дизъюнктов в качестве бокового. Однако, тогда возникает необходимость поиска необходимого и достаточного условия, при котором боковой дизъюнкт должен быть одним из ранее порожденных центральных дизъюнктов.
Здесь дизъюнкт p не является входным дизъюнктом. При этом легко видеть, что входное опровержение для исходного множества S отсутствует. Поэтому неизбежно использование одного из центральных дизъюнктов в качестве бокового. Однако, тогда возникает необходимость поиска необходимого и достаточного условия, при котором боковой дизъюнкт должен быть одним из ранее порожденных центральных дизъюнктов. Так вот, информация об отрезаемых литерах, записанная надлежащим образом, а также использование упорядоченного дизъюнкта дают возможность определить это условие. Уточним один важный момент - о записи отрезаемых литер .
Так вот, информация об отрезаемых литерах, записанная надлежащим образом, а также использование упорядоченного дизъюнкта дают возможность определить это условие. Уточним один важный момент - о записи отрезаемых литер .
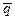 - контрарны, примем соглашение, что результат их дизъюнкции удалять не будем, а запишем его в виде одной левой литеры, обрамленной ее в рамку. Обрамленная литера – это отрезаемая литера, которая учитывается в дальнейших резолюциях следующим образом:
- контрарны, примем соглашение, что результат их дизъюнкции удалять не будем, а запишем его в виде одной левой литеры, обрамленной ее в рамку. Обрамленная литера – это отрезаемая литера, которая учитывается в дальнейших резолюциях следующим образом: 

 Здесь дизъюнкт p Ú q Ú
Здесь дизъюнкт p Ú q Ú 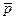 - редуцируемый дизъюнкт, который сразу дает пустой дизъюнкт.
- редуцируемый дизъюнкт, который сразу дает пустой дизъюнкт.







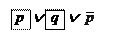 Порождаемые дизъюнкты типа называются редуцируемыми, их появление означает, что некоторый централизованный дизъюнкт нужно использовать в качестве бокового.
Порождаемые дизъюнкты типа называются редуцируемыми, их появление означает, что некоторый централизованный дизъюнкт нужно использовать в качестве бокового.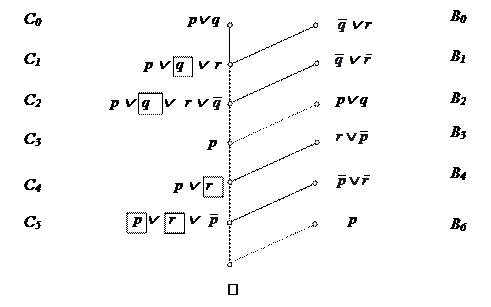 Пример:
Пример: 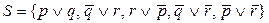
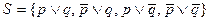
 Выберем в качестве C0 = p Ú q, тогда пригодные на первом шаге в качестве бокового – дизъюнкты
Выберем в качестве C0 = p Ú q, тогда пригодные на первом шаге в качестве бокового – дизъюнкты  и т.д.
и т.д.
 В методе поиска в глубину узел разворачивается полностью, если он вообще выбирается для развертывания, т.е. порождаются все возможные узлы-наследники.
В методе поиска в глубину узел разворачивается полностью, если он вообще выбирается для развертывания, т.е. порождаются все возможные узлы-наследники.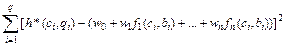 (2) – оценка по наименьшим квадратам.
(2) – оценка по наименьшим квадратам.
