
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Блок сохранения данных в рабочей области То Workspace
Назначение: Блок записывает данные, поступающие на его вход, в рабочую область MATLAB. Параметры:
1. Matrix – матрица. Данные сохраняются как массив, в котором число строк определяется числом расчетных точек по времени, а число столбцов – размерностью вектора подаваемого на вход блока. Если на вход подается скалярный сигнал, то матрица будет содержать лишь один столбец. 2. Structure – структура. Данные сохраняются в виде структуры, имеющей три поля: time – время, signals – сохраняемые значения сигналов, blockName – имя модели и блока To Workspace. Поле time для данного формата остается не заполненным. 3. Structure with Time – структура с дополнительным полем (время). Для данного формата, в отличие от предыдущего, поле time заполняется значениями времени. На рис. 1.20 показан пример использования данного блока. Результаты расчета сохраняются в переменной simout. Для считывания данных сохраненных в рабочей области MATLAB можно использовать блок From Workspace (библиотека Sources ).
Рис. 1.20 Применение блока To Workspace DSP Blockset состоит из библиотек Simulink и предназначен для проектирования и моделирования приложений DSP. Данные библиотеки включают такие ключевые операции, как классическая, многоступенчатая и адаптивная фильтрация; преобразования; матричные операции и линейная алгебра; статистика и спектральный анализ. Основные усовершенствования включают в себя:
Если рядом с подписью DSP Blockset стоит пиктограмма свернутого узла дерева (символ " + " ), его необходимо открыть (нажать на символ " + " ). В появившемся списке необходимо нажать на надпись Statistics.
n n число интервалов.
Вычисляет математическое ожидание выборки.
Вычисляет «хи-квадрат».
Вычислят СКО выборки.
Вычисляет дисперсию выборки.
Перед выполнением лабораторной работы не забудьте выставить в настройках блока-источника параметры в соответствии со своим вариантом.
Лабораторная работа № 2 Изучение методики расчета точечных оценок случайных величин Цель работы Овладение практическими навыками расчета оценок математического ожидания и дисперсии случайной величины. Теоретическая часть Измерение - нахождение физической величины опытным путем с помощью специальных технических средств. Главные признаки измерения: - измерять можно свойства реально существующих объектов; - измерение требует проведения опыта; - для проведения опыта требуется наличие специальных технических средств, приводимых во взаимодействие с объектом; - результатом измерения является значение физической величины, выраженное числом в принятых для этой величины единицах.
Погрешность измерения - разность между результатом измерения и истинным значением измеряемой величины. Если истинное значение измеряемой величины неизвестно, то используют оценку этой случайной величины. Погрешности классифицируют по следующим признакам: - по причине возникновения; - по закономерности проявления; - по скорости изменения измеряемой величины.
Наиболее полной характеристикой случайной погрешности является функция ее распределения. Через нее может быть рассчитана вероятность пребывания случайной величины в заданных пределах. При расширении заданного интервала вероятность попадания туда значений увеличивается. Максимальное значение вероятности равно единице, это означает, что все значения попадают на заданный интервал. Функция распределения случайной величины – универсальный способ описания ее поведения, но очень трудоемкий. Поэтому часто случайную величину характеризуют с помощью ограниченного числа специальных величин, которые называются моментами.
Математическое ожидание - центральный момент первого порядка, приближенно равно (тем точнее, чем больше число испытаний) среднему арифметическому наблюдаемых значений случайной величины. Математическое ожидание больше наименьшего и меньше наибольшего возможных значений. Другими словами, на числовой оси возможные значения расположены слева и справа от математического ожидания. В этом смысле математическое ожидание характеризует расположение распределения и поэтому его часто называют центром распределения.
Дисперсия - центральный момент второго порядка. Дисперсия характеризует степень рассеяния значений случайной величины относительно его математического ожидания. Оценка некоторого параметра а называется точечной, если она выражается одним числом. Поскольку количество наблюдений ограничено, при обработке результатов получают не истинное значение параметров, а их оценки. Оценка является случайной величиной. Т.к. оценка случайная величина, то она распределена по определенному закону, который зависит от закона распределения исходных величин, числа измерений и самого оцениваемого параметра. Требование к оценкам: - состоятельность (при увеличении числа измерений оценка должна приближаться к значению оцениваемого параметра); - несмещенность (математическое ожидание оценки должно быть равно оцениваемому параметру); - эффективность (дисперсия оценки должна быть меньше любой другой оценки данного параметра).
Виды оценок: - байесовские оценки (используются, если задан закон распределения погрешности и измеряемой величины); - оценки максимального правдоподобия (используется, если известен закон распределения погрешности, но нет сведений об измеряемой величине); - робастные оценки (используются, если неизвестен закон распределения погрешности и нет данных об измеряемой величине). Идентификация закона распределения - выбор закона распределения, в наибольшей мере соответствующего экспериментальным данным. Исходные данные для идентификации получают из гистограммы. Построение гистограммы производится следующим путем: - по результатам измерений определяют вариационный ряд, т.е. располагают результаты измерений в порядке возрастания; - делят полученный интервал на m интервалов одинаковой протяженности d. Выбор интервалов одинаковой длины не всегда целесообразен; - определяют число результатов, попавших в каждый интервал; - по оси абсцисс откладывают границы интервалов и на каждом строят столбец, высота которого равна количеству попаданий в данный интервал; - плавной линией соединяют середины вершин столбцов. Далее для окончательного определения вида закона пользуются критерием согласия Пирсона. С учетом точечных оценок результат измерения может быть записан в виде интервала x = X + s (где x - измеренное значение, X - оценка истинного значения, s - оценка СКО).
Порядок выполнения работы Перед началом работы в окне модели установите время моделирования и шаг в соответствии с вариантом (Simulation-> Simulation Parameters-> Start time = 0, Stop time = 10, Solver option-> Fixed step, Fixed step size = 0.1).
I. Используя пакет simulink программы MATLAB, составить модель, приведенную ниже на рис. 2.1.
Рис. 2.1 Возьмите блоки и установите параметры (нажав два раза на иконке блока мышью). Блоки: 1) Simulink-> Sourses-> Uniform Random Number Параметры: Minimum 0 Maximum 1 2) Simulink-> Sourses-> Constant Параметры: Constant Value 1 3) Simulink-> Math Operators-> Sum 4) Simulink-> Sinks-> To Workspace Параметры: Variable Name x Save Format Array Установите параметры моделирования: начальное время моделирования, конечное время моделирования, установите фиксированный шаг моделирования, установите этот шаг (в соответствии с вариантом). II. Произвести моделирование полученной схемы. Промоделируйте схему. Запуск расчета выполняется с помощью выбора пункта меню Simulation/Start. или инструмента Перейдите в основное меню окна MATLAB. В окне Command Window наберите имя переменной, указанной в Simulink-> Sinks-> To Workspace Variable Name, и нажмите enter. Вы увидите 100 результатов.
III. Из полученных результатов исключить грубые погрешности путем установления границ цензурирования.
IV. Используя полученные данные на выходе сумматора, рассчитать среднеквадратическое отклонение и математическое ожидание в соответствии с принципом максимального правдоподобия.
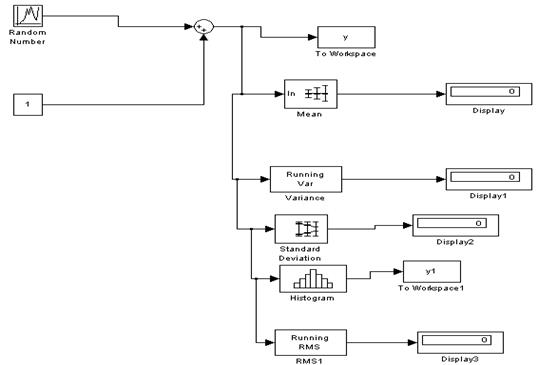
Построить гистограмму распределения результатов измерения. Для этого необходимо определить максимальное и минимальное значение случайной величины. Затем разбить диапазон ее изменения на заданное количество интервалов (задается преподавателем согласно вашему варианту) и определить их границы. Рассчитать количество попаданий в каждый интервал. По оси ОХ отложить мажорированный ряд полученных результатов. По оси ОY отложить относительное количество попаданий в каждый интервал. Для этого необходимо дополнить схему рис. 2.1 до следующей (рис. 2.2).
Рис. 2.2
Здесь используются блоки: 1) DSP Blockset-> Statistics-> Mean Параметры: Необходимо поставить галочку возле Runing mean 2) DSP Blockset-> Statistics-> Variance Параметры: Необходимо поставить галочку возле Runing variance 3) DSP Blockset-> Statistics-> Standart Deviation Параметры: Необходимо поставить галочку возле Runing standart deviation 4) DSP Blockset-> Statistics-> Histogram Параметры: Необходимо поставить галочку возле Runing histogram В окне Number of bins указать количество интервалов разбиения. variance 5) DSP Blockset-> Statistics-> RMS Параметры: Необходимо поставить галочку возле Runing rms 6) Simulink-> Sinks-> To Workspace параметры: Variable Name y Save Format Array 7) Simulink-> Sinks-> Display
Теперь промоделируйте схему. На соответствующих дисплеях отобразятся значения СКО, дисперсии, МО, «хи-квадрат». Для того чтобы увидеть сколько значений попало в каждый интервал разбиения необходимо перейти в основное окно MATLAB, в окне Command Window набрать имя переменной, указанной в Simulink-> Sinks-> To Workspace Variable Name y и нажать enter. Постройте гистограмму по полученным значениям. Постройте интегральную функцию распределения погрешности (для этого надо соединить середины столбцов полученной гистограммы).
V. Заменить генератор погрешности с равномерным законом распределения генератором погрешности с нормальным законом распределения (рис. 2.3).
Измените предыдущую схему, заменив блок Simulink-> Sourses-> Uniform Random Number на Simulink-> Sourses-> Random Number: Параметры: Mean 0 Variance 1
Рис. 2.3
В блоке To Workspace переменную х замените на у Для остальных блоков параметры остаются прежними
Для полученной схемы повторить пункты II - IV. Схему рис. 2.3 дополнить до следующей (рис. 2.4). Параметры элементов рис. 2.4 взять из схемы рис. 2.2.
Рис. 2.4
VI. Представить результат измерения с учетом поправки. Пример выполнения работы I. Обработка результатов прямых измерений с многократными наблюдениями. Методика обработки результатов измерений с многократными наблюдениями зависит от свойств погрешностей. Например, если погрешность за время измерений описывается стационарным случайным процессом, то эту стационарность следует контролировать. Нестационарность процесса чаще всего может проявляться в форме изменений математического ожидания — систематической погрешности. Поэтому в ходе обработки данных необходимо убедиться в отсутствии ухода систематической погрешности. Результаты измерений не должны содержать грубых погрешностей, которые исключают из расчетов. Для правильного выбора алгоритма обработки результатов наблюдений необходимо знать закон распределения погрешностей, который оценивают по экспериментальным результатам.
II. Идентификация формы закона распределения погрешностей. Экспериментальные исследования погрешностей средств измерений различных типов показали, что существует много законов распределения погрешностей, причем часто они существенно отличаются от гауссовского. Поскольку знание реального закона распределения необходимо для выбора методики получения оценки измеряемой величины, то в необходимых случаях приходится выбирать закон распределения, в наибольшей мере соответствующий экспериментальным данным — идентифицировать форму закона распределения. Гистограмма. Исходные данные для выбора закона распределения получают из гистограммы. Для ее построения по результатам многократных наблюдений строят вариационный ряд — располагают результаты в порядке возрастания и выбирают минимальное x1 и максимальное xn значения — крайние члены вариационного ряда. Отрезок xn – x1между ними делят на т интервалов одинаковой протяженности d. Интервалы ограничены - значениями xi и xi+1, где xi=x1+(i-1)d; xi+1= x1+id(I=1, 2, 3….m+1). Заметим, что верхняя граница последнего интервала xm+1= xn. По вариационному ряду определяют число ni результатов, попавших в каждый интервал, а затем вычисляют относительные частоты ni/n. Относительные частоты являются оценками вероятности pi/попадания результатов в данный интервал, т. е.
Рис. 2.5 Пример построения гистограммы
Расчет гистограммы на ЭВМ имеет некоторые особенности. Границы гистограммы иногда определяют, исходя из априорных сведений о погрешностях с некоторым запасом. После выбора числа разбиений т и расчета границ интервалов переходят к вычислению ni. Перебор результатов наблюдений требует определенных затрат машинного времени, его можно существенно сократить, если номер интервала, в который попадает данный результат, определять как частное (xi-x1)/d, значение которого округляют в большую сторону до ближайшего целого. Принятая методика позволяет рассчитывать гистограмму в реальном масштабе времени по мере поступления экспериментальных данных. Выбор числа разбиений при построении гистограммы. Изрезанность гистограммы можно уменьшить путем укрупнения интервалов. Так, увеличение интервала вдвое приведет к возрастанию Для каждого вида закона распределения существует оптимальное число интервалов, при котором гистограмма будет в наибольшей мере соответствовать изменению плотности вероятности. Оптимальное число интервалов в первую очередь должно зависеть от числа наблюдений. Действительно, если принять СКО высоты столбцов не зависящим от числа измерений, то с ростом п число интервалов также должно возрастать. Кроме того, число интервалов зависит от эксцесса. Исследования показали, что для большинства встречающихся на практике законов распределения, включая трапецеидальный, гауссовский, Лапласа, оптимальное число интервалов:
Если эксцесс закона распределения неизвестен, но заключен в интервале — 1, 2... 3, то оптимальное число m лежит от mн = 5, 4* lgn/10 до тв = 9, 8lgn/10. Область значений т при разных числах наблюдений показана на рис. 2.6.
Рис 2.6
Выбор интервалов одинаковой длины не всегда целесообразен. Так, на участках быстрого изменения плотности вероятностей или в тех точках, где плотность вероятностей меняется скачкообразно, интервалы следует уменьшить. Крайние же столбцы гистограммы можно сделать более протяженными.
III. Обработка результатов наблюдений, содержащих грубые погрешности. В ходе статистической обработки результатов многократных наблюдений иногда выясняется, что некоторые результаты аномальны, т.е. значительно превышают ожидаемую погрешность. Аномальные результаты могут быть проявлением случайного характера погрешностей или особенностей измеряемой величины. Такие результаты следует сохранить для последующей обработки. Однако появление аномальных результатов может быть и обусловлено факторами, не отражающими сущность эксперимента. Например, причиной аномальных результатов могут быть скачки питающего напряжения, вызванные включением в сеть мощных потребителей энергии. Помехи такого типа не в полной мере подавляются стабилизаторами источников питания средств измерений и могут вызывать резкие непредсказуемые изменения показаний. В этом случае считают, что результат содержит грубую погрешность, и его исключают из дальнейшей обработки. Разработка и анализ методов исключения имеют большое практическое значение, поскольку при использовании сложной измерительной аппаратуры доля аномальных результатов может достигать 10...15% общего числа измерений. Общие методы исключения грубых погрешностей. Вопрос об исключении аномальных результатов невозможно однозначно решить в общем виде, поскольку для принятия такого решения необходим тщательный анализ конкретных целей эксперимента, особенностей измерительной аппаратуры и характера поведения измеряемой величины. Особую осторожность следует проявлять тогда, когда исследуются процессы с мало изученными характеристиками. Иногда основанием для исключения аномальных результатов могут служить эвристические b, связанные, например, с воспоминаниями экспериментатора о нарушениях условий эксперимента. Если же проведение эксперимента и обработку его результатов осуществляют с помощью ИВК, то необходимы формальные признаки исключения грубых погрешностей. Наиболее распространенным методом исключения результатов, содержащих грубые погрешности, является цензурирование результатов измерений — исключение результатов, погрешности которых превышают установленные границы цензурирования ± xц. Грубые оценки границы получают, пользуясь правилом «трех сигма», согласно которому границы цензурирования хц = 3s. Для гауссовского закона распределения погрешностей вероятность превышения погрешностью этого уровня составляет 0, 0027 (рис. 2.7) и результат с такой погрешностью исключают. При равномерном законе промахами вызваны все результаты, превышающие уровень Рис. 2.7 Для закона Лапласа вероятность выхода погрешности за пределы ±3s составляет 0, 05, так что такие события нельзя считать маловероятными и исключать результаты неправомерно. Таким образом, границу цензурирования следует выбирать в зависимости от того, насколько быстро спадает плотность вероятности на краях графика. Протяженность спадающей части графика характеризуют эксцессом, поэтому и граница цензурирования должна быть возрастающей функцией эксцесса. Если задать определенную вероятность а выхода результатов за границу цензурирования, то очевидно, что число результатов, превысивших уровень границы, будет возрастать с ростом числа наблюдений. Для того чтобы практически все результаты, не содержащие грубых погрешностей, не выходили за границы цензурирования, необходимо сам уровень увеличивать сростом п. Границы цензурирования, при которых в среднем из результатов измерений исключается менее одного, определяются соотношением: справедливым для гауссовского и равномерного законов распределения, а также закона Лапласа. Иногда границы рассчитывают по формуле xц =s (1+1, 3 Методика обработки результатов измерений, содержащих грубые погрешности. Для расчета границ цензурирования необходимо знать значения s и Е, вместо которых в формулу (*) подставляют их оценки, полученные по результатам наблюдений. При ограниченном числе наблюдений оценки определяются со значительными погрешностями, которые сильно возрастают из-за наличия результатов, содержащих промахи. Вычисленные на основании грубых оценок границы цензурирования могут быть сильно завышенными и служить основанием для ошибочных выводов. Поэтому задачу цензурирования решают методом последовательных приближений, постепенно уточняя полученные результаты. Сначала определяют оценку математического ожидания методами, устойчивыми к промахам, например, взяв в качестве оценки медиану результатов измерений. Наиболее удаленные от математического ожидания результаты исключают во избежание резкого возрастания погрешностей оценок и рассчитывают границы цензурирования. Если в пределах границ окажется часть отброшенных результатов, то их возвращают в выборку и снова рассчитывают оценки Если же среди не исключенных имеются результаты, превышающие границы, то их отбрасывают и снова рассчитывают оценки. Процесс повторяют до тех пор, пока не будут исключены все результаты, содержащие грубые погрешности. На окончательном этапе обработки выбирают эффективную оценку математического ожидания, для которой определяют окончательные значения
IV. Методика обработки результатов многократных наблюдений. Пусть проведено п наблюдений измеряемой величины и получены независимые результаты х1, х2, ..., хn, каждый из которых содержит постоянную систематическую погрешность q и случайную погрешность. Если в качестве оценки измеряемой величины принято среднеарифметическое полученных значений, то
Отсюда следует, что измерения с многократными наблюдениями не приводят к изменению систематической погрешности. Отдельные значения случайной погрешности могут иметь разные знаки, поэтому при суммировании некоторые значения будут взаимно компенсироваться. Можно показать, что дисперсия третьего слагаемого, являющегося случайной погрешностью результата измерений х, уменьшается с ростом п. Следовательно, многократные наблюдения целесообразно применять тогда, когда доминирует случайная погрешность и ее уменьшение может существенно уменьшить общую погрешность. Принцип максимального правдоподобия. Пусть результаты xi наблюдений измеряемой величины подчинены закону распределения р(xi, X; q), где X — математическое ожидание, s — СКО. Вероятность появления результата измерений xi pi(xi) = p(xi; X; s)Dx, где Dx – малый интервал. Вероятность появления совокупности независимых результатов х1, х2, ..., хn определяется как произведение вероятностей:
Параметры X и s до измерений неизвестны, поэтому их можно рассматривать как переменные. Метод максимального правдоподобия заключается в подборе таких значений Хиs, при которых вероятность появления результатов измерений максимальна. Полученные оценки называют оценками максимального правдоподобия. Их отыскивают по максимуму функции правдоподобия которая отличается от вероятности Р(х1, x2, ..., хn)множителем Dxn, не влияющим на решение:
Вычисление оценок максимального правдоподобия. Для гауссовского закона:
Если функция правдоподобия содержит сомножители с показательными функциями, удобнее пользоваться логарифмической функцией правдоподобия
В данном случае функция правдоподобия дифференцируема, а ее производные непрерывны в точках xt. Поэтому оценки максимального правдоподобия находят, решая систему уравнений:
в результате:
Согласно закону Лапласа:
Логарифмическая функция правдоподобия не дифференцируема в точках хi, и ее максимум нельзя отыскать, приравняв нулю частные производные.
Определим максимум функции правдоподобия графическим методом. Для этого сделаем х переменным, заменив его. Семейства зависимостей отдельных слагаемых |хi, — х| от х для четных и нечетных п построены на рис 2.8а и 2.8б. Суммируя их, получаем зависимости
Рис. 2.8
Для четных п функция правдоподобия максимальна на интервале от хn/2до xn/2+1. За оценку максимального правдоподобия принимают середину этого интервала
При равномерном распределении погрешностей
где Функция правдоподобия:
Очевидно, что все экспериментальные точки должны располагаться в пределах графика плотности вероятностей (рис. 2.9а), т.е. оценки должны удовлетворять условиям Оценка максимального правдоподобия:
Рис. 2.9
V. Обработка результатов измерений с многократными наблюдениями, подчиненных гауссовскому закону. Полученные в IV пункте оценки максимального правдоподобия х и s называют точечными оценками результата измерений. В некоторых случаях удобнее пользоваться интервальной оценкой – интервалом, в котором с заданной вероятностью лежит измеряемая величина. Пусть результаты наблюдений подчинены гауссовскому закону, статистически независимы и не содержат систематических погрешностей. Оценка математического ожидания и дисперсии. Оценка максимального правдоподобия несмещенная, поскольку
Определение ее таким образом можно рассматривать как косвенные измерения, поэтому СКО оценки
Оценка
Рис. 2.10
Использовать закон распределения р( Определим, является ли эта оценка несмещенной. Для этого найдем математическое ожидание и после преобразований получим
Следовательно, оценка максимального правдоподобия При расчетах используют несмещенную оценку:
Оценка СКО среднеарифметического:
которая является случайной величиной. Критерий согласия хи-квадрат (Пирсона). Пусть произведено п независимых измерений некоторой величины X, рассматриваемой как случайная. Результаты измерений для удобства представляются в виде вариационного ряда, - последовательности измеренных значений величины, расположенных в порядке возрастания от наименьшего до наибольшего. Например, пусть имеются результаты измерений постоянного электрического напряжения U на выходе электронного узла (в порядке произведения измерений) – табл. 2.1: Таблица 2.1
Данная первичная форма записи результатов измерений преобразуется в вариационный ряд (табл. 2.2): Таблица 2.2
Дальше весь диапазон измеренных значений величины U разделяется на некоторое число разрядов (интервалов). Число этих разрядов определяется различными способами; так можно пользоваться формулой где k – число разрядов; n – число измерений. В рассмотренном примере число разрядов можно принять равным пяти. После определения числа разрядов вариационного ряда строиться статический ряд-таблица, в которой приведены длины разрядов Ii (в порядке их соответствия оси абсцисс измеряемой величины X), количества значений величины mi, оказавшихся в том или ином разряде, а также статические частоты P*i. В таблице границы разрядов обозначаются как xi, xi+1. Затем находятся теоретические вероятности попадания величины X в каждый из разрядов: P1, P2, …, Pk. Например, если теоретический закон нормальный, то с помощью формулы нетрудно определить теоретическую вероятность в разряде (xi, xi+1).
где mx и Таблица 2.3
В качестве меры расхождения между теоретическими вероятностями и статистическими частотами критерий хи-квадрат предусматривает использование величины
где n и k – число измерений и разрядов статического ряда соответственно. Популярное:
|
Последнее изменение этой страницы: 2016-03-22; Просмотров: 2133; Нарушение авторского права страницы
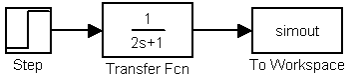
 Ст Строит гистограмму, разбивая выборку на заданное
Ст Строит гистограмму, разбивая выборку на заданное
 на панели инструментов.
на панели инструментов.

 . Нормированные по ширине интервала относительные частоты ni/nd могут служить оценкой среднего значения плотности вероятностей на интервале. Границы интервалов откладывают на числовой оси, а на каждом интервале строят столбик высотой ni/nd. По совокупности столбиков оценивают форму изменения плотности вероятностей. В пределе при п®¥ и d®¥ гистограмма превращается в плавную кривую.
. Нормированные по ширине интервала относительные частоты ni/nd могут служить оценкой среднего значения плотности вероятностей на интервале. Границы интервалов откладывают на числовой оси, а на каждом интервале строят столбик высотой ni/nd. По совокупности столбиков оценивают форму изменения плотности вероятностей. В пределе при п®¥ и d®¥ гистограмма превращается в плавную кривую.
 приблизительно в два раза, а относительное СКО высоты столбцов уменьшится в
приблизительно в два раза, а относительное СКО высоты столбцов уменьшится в  раз. Однако cростом интервала d теряется информация о форме изменения искомой плотности вероятностей, так как сглаживаются его особенности. Так, по гистограмме из трех столбиков любое колоколообразное или трапецеидальное распределение будет оценено как треугольное. Если же взять один интервал, то независимо от формы исходной плотности вероятностей распределение будет сведено к равномерному.
раз. Однако cростом интервала d теряется информация о форме изменения искомой плотности вероятностей, так как сглаживаются его особенности. Так, по гистограмме из трех столбиков любое колоколообразное или трапецеидальное распределение будет оценено как треугольное. Если же взять один интервал, то независимо от формы исходной плотности вероятностей распределение будет сведено к равномерному. .
.
 , поэтому граница оказывается сильно завышенной.
, поэтому граница оказывается сильно завышенной.
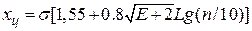 , (*)
, (*) ).
). и
и  .
.
 .
.

 .
.

 .
.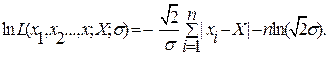
 от х (рис. 2.8в и 2.8г). Функция правдоподобия достигает максимума, если сумма минимальна. Следовательно, при нечетном п за оценку максимального правдоподобия следует взять медиану вариационного ряда, т.е.
от х (рис. 2.8в и 2.8г). Функция правдоподобия достигает максимума, если сумма минимальна. Следовательно, при нечетном п за оценку максимального правдоподобия следует взять медиану вариационного ряда, т.е. 

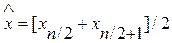


 .
. , где х1и xn - крайние значения вариационного ряда результатов хi. Функция правдоподобия построена на рис. 2.9б, из которого следует, что условный максимум функции правдоподобия имеет место при
, где х1и xn - крайние значения вариационного ряда результатов хi. Функция правдоподобия построена на рис. 2.9б, из которого следует, что условный максимум функции правдоподобия имеет место при  .
.

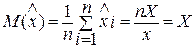 .
. .
. подчиняется гауссовскому закону распределения при любых п, поскольку композиция гауссовских законов при любом числе слагаемых дает гауссовский закон. Плотности вероятности p(xi) и р(
подчиняется гауссовскому закону распределения при любых п, поскольку композиция гауссовских законов при любом числе слагаемых дает гауссовский закон. Плотности вероятности p(xi) и р( 
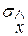 обычно неизвестны. Вместо s при анализе используют оценку максимального правдоподобия ее.
обычно неизвестны. Вместо s при анализе используют оценку максимального правдоподобия ее. .
. при конечном п является смещенной. При п®¥ [(n—1)/n®¥ и
при конечном п является смещенной. При п®¥ [(n—1)/n®¥ и  , откуда следует асимптотическая несмещенность оценки.
, откуда следует асимптотическая несмещенность оценки. .
.
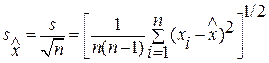 ,
,  ,
, 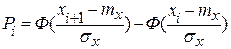 ,
,  - соответственно математическое ожидание и СКО величины X. Поскольку они неизвестны, то при расчетах заменяются статическими значениями m*x – средним арифметическим значением и статическим СКО Sx (табл. 2.3)
- соответственно математическое ожидание и СКО величины X. Поскольку они неизвестны, то при расчетах заменяются статическими значениями m*x – средним арифметическим значением и статическим СКО Sx (табл. 2.3)