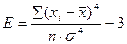|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Распределение признака. Параметры распределенияСтр 1 из 17Следующая ⇒
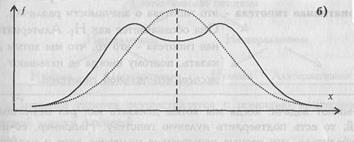
Распределением признака называется закономерность встречаемости разных его значений (Плохинский Н.А., 1970, с. 12). В психологических исследованиях чаще всего ссылаются на нормальное распределение. Нормальное распределение характеризуется тем, что крайние значения признака в нем встречаются достаточно редко, а значения, близкие к средней величине - достаточно часто. Нормальным такое распределение называется потому, что оно очень часто встречалось в естественнонаучных исследованиях и казалось " нормой" всякого массового случайного проявления признаков. Это распределение следует закону, открытому тремя учеными в разное время: Муавром в 1733 г. в Англии, Гауссом в 1809 г. в Германии и Лапласом в 1812 г. во Франции (Плохинский Н.А., 1970, с.17). График нормального распределения представляет собой привычную глазу психолога-исследователя так называемую колоколообразную кривую (см. напр., Рис. 1.1, 1.2). Параметры распределения - это его числовые характеристики, указывающие, где " в среднем" располагаются значения признака, насколько эти значения изменчивы и наблюдается ли преимущественное появление определенных значений признака. Наиболее практически важными параметрами являются математическое ожидание, дисперсия, показатели асимметрии и эксцесса. В реальных психологических исследованиях мы оперируем не параметрами, а их приближенными значениями, так называемыми оценками параметров. Это объясняется ограниченностью обследованных выборок. Чем больше выборка, тем ближе может быть оценка параметра к его истинному значению. В дальнейшем, говоря о параметрах, мы будем иметь в виду их оценки. Среднее арифметическое (оценка математического ожидания) вычисляется по формуле:
где xi - каждое наблюдаемое значение признака; i - индекс, указывающий на порядковый номер данного значения признака; п - количество наблюдений; ∑ - знак суммирования. Оценка дисперсии определяется по формуле:
где xi - каждое наблюдаемое значение признака;
n - количество наблюдений. Величина, представляющая собой квадратный корень из несмещенной оценки дисперсии (S), называется стандартным отклонением или средним квадратическим отклонением. Для большинства исследователей привычно обозначать эту величину греческой буквой σ (сигма), а не S. На самом деле, σ - это стандартное отклонение в генеральной совокупности, a S - несмещенная оценка этого параметра в исследованной выборке. Но, поскольку S - лучшая оценка σ (Fisher R.A., 1938), эту оценку стали часто обозначать уже не как S, а как σ:
В тех случаях, когда какие-нибудь причины благоприятствуют более частому появлению значений, которые выше или, наоборот, ниже среднего, образуются асимметричные распределения. При левосторонней, или положительной, асимметрии в распределении чаще встречаются более низкие значения признака, а при правосторонней, или отрицательной - более высокие (см. Рис. 1.5). Показатель асимметрии (A)вычисляется по формуле:
В тех случаях, когда какие-либо причины способствуют преимущественному появлению средних или близких к средним значений, образуется распределение с положительным эксцессом. Если же в распределении преобладают крайние значения, причем одновременно и более низкие, и более высокие, то такое распределение характеризуется отрицательным эксцессом и в центре распределения может образоваться впадина, превращающая его в двувершинное (см. Рис. 1.6). Показатель эксцесса (E) определяется по формуле:
Рис. 1.6. Эксцесс: а) положительный; 6) отрицательный В распределениях с нормальной выпуклостью E=0. Параметры распределения оказывается возможным определить только по отношению к данным, представленным по крайней мере в интервальной шкале. Как мы убедились ранее, физические шкалы длин, времени, углов являются интервальными шкалами, и поэтому к ним применимы способы расчета оценок параметров, по крайней мере, с формальной точки зрения. Параметры распределения не учитывают истинной психологической неравномерности секунд, миллиметров и других физических единиц измерения. На практике психолог-исследователь может рассчитывать параметры любого распределения, если единицы, которые он использовал при измерении, признаются разумными в научном сообществе. Статистические гипотезы Формулирование гипотез систематизирует предположения исследователя и представляет их в четком и лаконичном виде. Благодаря гипотезам исследователь не теряет путеводной нити в процессе расчетов и ему легко понять после их окончания, что, собственно, он обнаружил. Статистические гипотезы подразделяются на нулевые и альтернативные, направленные и ненаправленные. Нулевая гипотеза - это гипотеза об отсутствии различий. Она обозначается как H0 и называется нулевой потому, что содержит число 0: X1- Х2=0, где X1, X2 - сопоставляемые значения признаков. Нулевая гипотеза - это то, что мы хотим опровергнуть, если перед нами стоит задача доказать значимость различий. Альтернативная гипотеза - это гипотеза о значимости различий. Она обозначается как H1. Альтернативная гипотеза - это то, что мы хотим доказать, поэтому иногда ее называют экспериментальной гипотезой. Бывают задачи, когда мы хотим доказать как раз незначимость различий, то есть подтвердить нулевую гипотезу. Например, если нам нужно убедиться, что разные испытуемые получают хотя и различные, но уравновешенные по трудности задания, или что экспериментальная и контрольная выборки не различаются между собой по каким-то значимым характеристикам. Однако чаще нам все-таки требуется доказать значимость различий, ибо они более информативны для нас в поиске нового. Нулевая и альтернативная гипотезы могут быть направленными и ненаправленными. Направленные гипотезы H0: X1 не превышает Х2 H1: X1 превышает Х2 Ненаправленные гипотезы H0: X1 не отличается от Х2 Н1: Х1 отличается от Х2 Если вы заметили, что в одной из групп индивидуальные значения испытуемых по какому-либо признаку, например по социальной смелости, выше, а в другой ниже, то для проверки значимости этих различий нам необходимо сформулировать направленные гипотезы. Если мы хотим доказать, что в группе А под влиянием каких-то экспериментальных воздействий произошли более выраженные изменения, чем в группе Б, то нам тоже необходимо сформулировать направленные гипотезы. Если же мы хотим доказать, что различаются формы распределения признака в группе А и Б, то формулируются ненаправленные гипотезы. При описании каждого критерия в руководстве даны формулировки гипотез, которые он помогает нам проверить. Построим схему - классификацию статистических гипотез.
Проверка гипотез осуществляется с помощью критериев статистической оценки различий. Статистические критерии Статистический критерий - это решающее правило, обеспечивающее надежное поведение, то есть принятие истинной и отклонение ложной гипотезы с высокой вероятностью (Суходольский Г.В., 1972, с. 291). Статистические критерии обозначают также метод расчета определенного числа и само это число. Когда мы говорим, что достоверность различий определялась по критерию χ 2, то имеем в виду, что использовали метод χ 2 - для расчета определенного числа. Когда мы говорим, далее, что χ 2=12, 676, то имеем в виду определенное число, рассчитанное по методу χ 2. Это число обозначается как эмпирическое значение критерия. По соотношению эмпирического и критического значений критерия мы можем судить о том, подтверждается ли или опровергается нулевая гипотеза. Например, если χ 2эмп> χ 2кр, H0 отвергается. В большинстве случаев для того, чтобы мы признали различия значимыми, необходимо, чтобы эмпирическое значение критерия превышало критическое, хотя есть критерии (например, критерий Манна-Уитни или критерий знаков), в которых мы должны придерживаться противоположного правила. Эти правила оговариваются в описании каждого из представленных в руководстве критериев. В некоторых случаях расчетная формула критерия включает в себя количество наблюдений в исследуемой выборке, обозначаемое как п. В этом случае эмпирическое значение критерия одновременно является тестом для проверки статистических гипотез. По специальной таблице мы определяем, какому уровню статистической значимости различий соответствует данная эмпирическая величина. Примером такого критерия является критерий φ *, вычисляемый на основе углового преобразования Шишера. В большинстве случаев, однако, одно и то же эмпирическое значение критерия может оказаться значимым или незначимым в зависимости от количества наблюдений в исследуемой выборке (n) или от так называемого количества степеней свободы, которое обозначается как v или как df. Число степеней свободы v равно числу классов вариационного ряда минус число условий, при которых он был сформирован (Ивантер Э.В., Коросов А.В., 1992, с. 56). К числу таких условий относятся объем выборки (n), средние и дисперсии. Если мы расклассифицировали наблюдения по классам какой-либо номинативной шкалы и подсчитали количество наблюдений в каждой ячейке классификации, то мы получаем так называемый частотный вариационный ряд. Единственное условие, которое соблюдается при его формировании - объем выборки п. Допустим, у нас 3 класса: " Умеет работать на компьютере - умеет выполнять лишь определенные операции - не умеет работать на компьютере". Выборка состоит из 50 человек. Если в первый класс отнесены 20 испытуемых, во второй - тоже 20, то в третьем классе должны оказаться все остальные 10 испытуемых. Мы ограничены одним условием - объемом выборки. Поэтому даже если мы потеряли данные о том, сколько человек не умеют работать на компьютере, мы можем определить это, зная, что в первом и втором классах - по 20 испытуемых. Мы не свободны в определении количества испытуемых в третьем разряде, " свобода" простирается только на первые две ячейки классификации: v= c-l = 3-1 = 2 Аналогичным образом, если бы у нас была классификация из 10 разрядов, то мы были бы свободны только в 9 из них, если бы у нас было 100 классов - то в 99 из них и т. д. Способы более сложного подсчета числа степеней свободы при двухмерных классификациях приведены в разделах, посвященных критерию χ 2и дисперсионному анализу. Зная n и/или число степеней свободы, мы по специальным таблицам можем определить критические значения критерия и сопоставить с ними полученное эмпирическое значение. Обычно это записывается так: " при n=22 критические значения критерия составляют..." или " при v=2 критические значения критерия составляют..." и т.п. Критерии делятся на параметрические и непараметрические. Параметрические критерии Критерии, включающие в формулу расчета параметры распределения, то есть средние и дисперсии (t - критерий Стьюдента, критерий F и др.) Непараметрические критерии Критерии, не включающие в формулу расчета параметров распределения и основанные на оперировании частотами или рангами (критерий Q Розенбаума, критерий Т Вилкоксона и др.) И те, и другие критерии имеют свои преимущества и недостатки. На основании нескольких руководств можно составить таблицу, позволяющую оценить возможности и ограничения тех и других (Рунион Р., 1982; McCall R., 1970; J.Greene, M.D'Olivera, 1989). Таблица 1.1 Возможности и ограничения параметрических и непараметрических критериев
Из Табл. 1.1 мы видим, что параметрические критерии могут оказаться несколько более мощными[5], чем непараметрические, но только в том случае, если признак измерен по интервальной шкале и нормально распределен. С интервальной шкалой есть определенные проблемы (см. раздел " Шкалы измерения" ). Лишь с некоторой натяжкой мы можем считать данные, представленные не в стандартизованных оценках, как интервальные. Кроме того, проверка распределения " на нормальность" требует достаточно сложных расчетов, результат которых заранее неизвестен (см. параграф 7.2). Может оказаться, что распределение признака отличается от нормального, и нам так или иначе все равно придется обратиться к непараметрическим критериям. Непараметрические критерии лишены всех этих ограничений и нетребуют таких длительных и сложных расчетов. По сравнению с параметрическими критериями они ограничены лишь в одном - с их помощью невозможно оценить взаимодействие двух или более условий или факторов, влияющих на изменение признака. Эту задачу может решить только дисперсионный двухфакторный анализ. Учитывая это, в настоящее руководство включены в основном непараметрические статистические критерии. В сумме они охватывают большую часть возможных задач сопоставления данных. Единственный параметрический метод, включенный в руководство - метод дисперсионного анализа, двухфакторный вариант которого ничем невозможно заменить. Популярное:
|
Последнее изменение этой страницы: 2016-03-22; Просмотров: 1139; Нарушение авторского права страницы
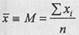

 - среднее арифметическое значение признака;
- среднее арифметическое значение признака;