
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
ГЛАВА I. ПРОБЛЕМЫ ПОСТРОЕНИЯ ЭКОНОМЕТРИЧЕСКИХ МОДЕЛЕЙ
ВВЕДЕНИЕ Термин эконометрия (эконометрика) был введен в научную литературу в 1930 году норвежским статистиком Рагнаром Фришем для обозначения нового направления научных исследований, возникшего из необходимости научно-обоснованного подтверждения и доказательства концепций и выводов экономической теории результатами количественного анализа рассматриваемых процессов. В этой связи можно сказать, что основная задача эконометрики состоит в построении моделей специфического типа (эконометрических моделей), описывающих взаимообусловленное развитие социально-экономических процессов, на основе информации, отражающей распределение их уровней во времени или (и) в пространстве однородных объектов. Эти модели используются в анализе и прогнозировании общих закономерностей и конкретных количественных характеристик рассматриваемых процессов, определении управляющих воздействий. Вследствие этого в самом широком толковании эконометрию можно рассматривать как объединение ряда дисциплин – экономической теории (включая микро- и макроэкономику, социальную сферу), социально-экономической статистики и теории измерения общественных процессов, математической статистики и методов экономико-математического моделирования. Каждая из перечисленных дисциплин играет свою роль в эконометрическом исследовании. Экономическая теория занимается вопросами разработки концепций относительно законов развития исследуемых процессов с учетом их взаимосвязей; социально-экономическая статистика и теория измерений – выражением количественных и качественных состояний этих процессов (как правило, в последовательные периоды (моменты) времени) в виде набора логически непротиворечивых и содержательных показателей; методы экономико-математического моделирования – разработкой моделей взаимосвязей между рассматриваемыми процессами, адекватно отражающими экономические концепции в рамках выбранной системы показателей; математическая статистика – собственно построением самих моделей (т. е. оценкой их параметров), проверками гипотез относительно их адекватности тенденциям процессов, значимости взаимосвязей между ними, оценками неопределенности в полученных результатах, вызванной систематическими и случайными ошибками и т. п. При этом обычно предполагается, что систематические ошибки в результатах возникают вследствие использования неадекватной тенденциям исследуемых процессов концепции относительно их взаимосвязей, систематических ошибок измерений их уровней, неправильно выбранной спецификации модели и ряда других причин объективного и субъективного характера. Причинами существования случайной ошибки модели, как правило, являются случайные ошибки измерения процессов, невозможность учета в модели случайных воздействий множества незначимых с точки зрения экономической теории факторов и другие подобные причины. Таким образом, при эконометрическом исследовании имеют место две стороны проблемы обеспечения высокого качества его результатов – качественная и количественная. Качественная заключается в установлении соответствия между построенной эконометрической моделью и лежащей в ее основе концепцией, а количественная – в точности аппроксимации (подгонки) имевшихся количественных и качественных характеристик рассматриваемых процессов данными модельных расчетов. В конкретных научных исследованиях “концептуальные” и собственно “вычислительные”, прикладные аспекты эконометрии нередко отделяются друг от друга. В каждом из них имеют место свои проблемы, нерешенные задачи. Основной задачей “вычислительной” эконометрии является собственно построение адекватной тенденциям рассматриваемых процессов эконометрической модели. Исследованию проблем построения таких моделей в данной работе и будет уделено основное внимание.
ГЛАВА I. ПРОБЛЕМЫ ПОСТРОЕНИЯ ЭКОНОМЕТРИЧЕСКИХ МОДЕЛЕЙ Рис. 1.1
t t Рис. 1.2
Аналогично можно показать, что предельная норма замещения факторов i и j для функции (1.17) также является переменной величиной
и ее значение также зависит от соотношения уровней рассматриваемых факторов в каждый момент времени. Методы отбора факторов “Оптимальный” состав факторов, включаемых в эконометрическую модель, является одним из основных условий ее “хорошего” качества, понимаемого и как соответствие формы модели теоретической концепции, выражающей содержание взаимосвязей между рассматриваемыми переменными, и как точность предсказания на рассматриваемом интервале времени t=1, 2,..., Т наблюдаемых значений переменной уt уравнением f( a, x t). Проблема выбора “оптимальных” факторов обычно решается на основе содержательного и количественного (статистического) анализа тенденций рассматриваемых процессов. На этапе содержательного анализа решается вопрос о целесообразности включения в модель тех или иных факторов, исходя из “здравого” смысла. В макроэкономических исследованиях состав факторов, как правило, определяется на основании допущений экономической теории. Пример – двухфакторные производственные функции типа Кобба-Дугласа, постоянной эластичности замены, которые строятся в предположении, что объем выпуска (производства) экономической системы в основном зависит от размеров используемых основных фондов и количества затраченного труда. Далее, как это было отмечено в разделе 1.2, производственная функция типа Кобба-Дугласа учитывает предположение о постоянной эластичности выпуска по каждому из факторов, а функция постоянной эластичности замены – свойство постоянства замещения изменения одного из этих факторов изменением другого. Здесь следует иметь в виду, что на этапе содержательного анализа обычно решается проблема установления самого факта наличия взаимосвязей между явлениями. Однако, как было отмечено в разделе 1.2, каждое из явлений может быть выражено разными факторами и даже их комбинациями. Поэтому в ряде исследований на основании содержательного анализа однозначно состав независимых переменных модели определить практически невозможно. Могут существовать их альтернативные наборы. Например, для исследования закономерностей динамики производительности труда на заводе могут быть отобраны, исходя из содержательной целесообразности, следующие факторы: объем основных фондов, электровооруженность труда, фондовооруженность труда, численность рабочей силы, ее квалификация. При этом квалификация как явление может выражаться разными показателями, например, средним уровнем образования работников, их усредненным квалификационным разрядом и т. п. Кроме того, можно ожидать, что показатели электровооруженности, фондовооруженности труда, объема основных фондов характеризуют одно и то же явление – изменение материально-технической оснащенности производственного процесса. Таким образом, некоторые из рассматриваемых в таком исследовании показателей, выражающих количественные характеристики независимых переменных, относятся к сходным явлениям. Аналогично, в исследованиях заболеваемости населения каждая из определяющих это явление причин может быть количественно отображена разными факторами. Например, уровень жизни – среднедушевым доходом, обеспеченностью жильем, розничным товарооборотом в расчете на одного жителя и т. п.; климатические условия – среднегодовой температурой, числом солнечных дней в году, влажностью и рядом других показателей; качество окружающей среды – среднегодовыми объемами выбросов и сбросов загрязняющих веществ, среднегодовыми уровнями их концентрации в воздухе, воде и почве и т. д., уровень медицинского обслуживания – количеством медицинских работников в расчете на одного жителя; числом койко-мест в лечебных заведениях на одного жителя и другими показателями. Несложно заметить, что факторы, выражающие одну и ту же причину, могут быть тесно взаимосвязаны между собой. Так, например, уровень розничного товарооборота в основном зависит от среднедушевого дохода; концентрация загрязняющих веществ – от объемов их выбросов; наблюдается взаимосвязь между обеспеченностью населения медицинским персоналом и койко-местами в лечебных учреждениях и т. д. Вследствие этого, одновременное включение таких факторов в модель вряд ли целесообразно, поскольку таким образом одна и та же причина будет учтена дважды. В результате в общем случае на этапе обоснования эконометрической модели исследователи могут столкнуться с проблемой выбора наиболее предпочтительного состава независимых факторов среди ряда альтернативных вариантов. Можно выделить два основных подхода к решению этой проблемы. Первый из них предполагает априорное (до построения модели) исследование характера и силы взаимосвязей между рассматриваемыми переменными, по результатам которого в модель включаются факторы, наиболее значимые по своему “непосредственному” влиянию на зависимую переменную уt. И, наоборот, из модели исключаются факторы, которые, либо малозначимы с точки зрения силы своего влияния на переменную уt, либо их сильное влияние на нее можно трактовать как индуцированное взаимосвязями с другими экзогенными переменными. Второй подход к отбору независимых факторов можно назвать апостериорным. Он предполагает первоначально включить в модель все отобранные на этапе содержательного анализа факторы. Уточнение их состава в этом случае производится на основе анализа характеристик качества построенной модели, одной из групп которых являются и показатели, выражающие силу влияния каждого из факторов на зависимую переменную уt. Рассмотрим особенности процедуры отбора факторов на основе использования каждого из этих подходов более подробно. В основе “априорного” подхода лежат следующие предположения. 1. Сильное влияние фактора на зависимую переменную должно подтверждаться и определенными количественными характеристиками, важнейшей из которых является их парный линейный коэффициент корреляции, выборочное значение которого рассчитывается на основании имеющейся информации по формуле:
где Логика использования коэффициента парной корреляции при отборе значимых факторов на практике состоит в следующем. Если значение Здесь следует иметь в виду, что значение 2. Если два и более факторов выражают одно и то же явление (см. рассмотренные выше примеры), то, как правило, между ними также должна существовать достаточно сильная взаимосвязь. На это может указать выборочное значение их парного коэффициента корреляции
На практике взаимосвязь между факторами признается существенной, если Отметим, что приведенные рубежные значения (в первом случае – 0, 5–0, 6; во втором – 0, 8–0, 9) достаточно условны. В каждом конкретном случае они устанавливаются индивидуально. При их выборе существенную роль играет интуиция исследователя. Обычно считается, что, если для фактора хi Здесь следует еще раз подчеркнуть, что при таком отборе, основанном на эмпирике и интуиции, обычно не принимается во внимание точность оценки выборочных коэффициентов корреляции, которая растет с увеличением выборки, т. е. значения Т. При фиксированном значении Т точность оценок всех коэффициентов примерно одинакова. Логика такого отбора в большей степени ориентирована на содержательную сторону проблемы учета взаимосвязей между переменными модели. Значительно усложняет проблему отбора факторов явление ложной корреляции, которое характеризуется достаточно высокими по абсолютной величине значениями коэффициентов парной корреляции у процессов, с содержательной точки зрения между собой никак не связанных. Иными словами, большие значения парных коэффициентов корреляции могут иметь место и в тех случаях, когда тенденции рассматриваемых процессов совпали случайно, при отсутствии между ними логически обоснованной взаимосвязи. Примерами ложных корреляций являются совпадающие тенденции роста потребительских расходов в постоянных ценах и роста потребительских цен, роста выпуска продукции и потребления алкоголя и т. п. Ложная корреляция может помешать при построении “правильной” модели по двум причинам. Во-первых, в модель случайно могут быть введены незначимые с содержательной точки зрения факторы, характеризующиеся значимыми величинами Среди основных причин включения в модель переменных с ложной корреляцией часто называют ненадежность информации, используемой при определении значений факторов в различные моменты времени, трудности формализации факторов, имеющих качественный характер, неустойчивость тенденций изменения рассматриваемых переменных, неправильную форму взаимосвязи между ними и т. п. Еще раз отметим, что основной путь, придерживаясь которого можно избежать ошибок, связанных с понятием “ложной корреляции”, связан с проведением качественного анализа проблемы, направленного на обоснование адекватного ей содержания и формы модели. При этом можно предложить и некоторые общие рекомендации, которых целесообразно придерживаться, следуя этим путем: 1. Число факторов, включаемых в модель, не должно быть слишком велико. Их увеличение может свести к минимуму ее практическую ценность, так как в этом случае модель начинает отражать не закономерность развития на фоне случайности, а саму случайность. 2. Простота модели в значительной степени является гарантией ее адекватности, поскольку более сложные зависимости часто априорно трудно уловимы на ограниченном временном интервале, но в то же время они допускают аппроксимацию достаточно простыми функциями. Иными словами, сложная модель может в большей степени выражать второстепенные взаимосвязи между переменными в ущерб основным. При апостериорном подходе уточнение состава факторов эконометрической модели осуществляется на основе анализа значений ряда качественных характеристик уже построенного ее варианта. Одну из групп таких характеристик, являющихся наиболее важными при отборе факторов, образуют значения критерия Стьюдента, рассчитываемые для коэффициентов при каждом из факторов модели. С помощью этого критерия проверяется гипотеза о значимости влияния фактора на зависимую переменную у. Здесь следует отметить, что окончательное решение о целесообразности оставления фактора или его удаления из модели принимается на основе анализа всего комплекса ее характеристик качества с учетом содержательной стороны проблемы взаимосвязей между зависимой и независимыми переменными. Вопросы их расчета и логика принятия такого решения будут изложены в разделе 1.4. Критерий Стьюдента лишь указывает на те факторы, которые с точки зрения статистики являются возможными (целесообразными) кандидатами на удаление. Заметим, что ответ на вопрос о целесообразности включения в число факторов-кандидатов на удаление каждой из независимых переменных хi, i=1, 2,..., n, при апостериорном подходе решается уже после того, как оценены значения коэффициентов модели и определены некоторые дополнительные характеристики точности полученных оценок. Вопросы определения этих характеристик рассмотрены в главе II. Будем считать, что с помощью какого-либо из методов, рассмотренных в главе II, например, метода наименьших квадратов, найдены численные значения оценок параметров a0, a1,..., an линейной эконометрической модели (1.2)*. Как будет показано в главе II, эти оценки являются выборочными (определенными по наблюдаемой выборке исходных данных). Согласно этому они рассматриваются как случайные величины, распределенные «приблизительно» по нормальному закону с соответствующими математическими ожиданиями и дисперсиями (среднеквадратическими отклонениями). Методы оценивания параметров позволяют определить и значения дисперсий полученных оценок s(ai ). Логика использования критерия Стьюдента при выявлении факторов-кандидатов на удаление из уже построенного варианта модели основывается на следующих его свойствах. Напомним, что случайная величина t, определенная согласно выражению
распределена по закону Стьюдента с k степенями свободы, k – объем выборки; Таким образом, с помощью критерия Стьюдента может быть проверена гипотеза о равенстве найденного выборочного среднего предполагаемому значению математического ожидания. На практике обычно эта гипотеза принимается, если оказывается, что для расчетного значения критерия Стьюдента выполняется следующее соотношение t< t*( k), где t*( k) – табличное значение критерия Стьюдента, соответствующее доверительной вероятности р* и числу степеней свободы k*. При определении значимости (незначимости) i-го фактора принимаются во внимание следующие обстоятельства. Оценка соответствующего ему коэффициента ai, полученная с использованием выбранного метода оценивания параметров, приравнивается к выборочному среднему С учетом этого расчетное значение критерия Стьюдента при проверке гипотезы о значимости i-го фактора определяется по следующей формуле:
где ½ ai½ – абсолютное значение оценки коэффициента ai в модели, характеризующее степень влияния i-го фактора на результирующий показатель; s(ai) – среднеквадратическая ошибка оценки этого коэффициента, определяемая на этапе его расчета (см. главу II). Рис. 1.3. Различие между интерполирующим и описывающим общую тенденцию переменной уt вариантами функционала f ( a, x t )
Вместе с тем очевидно, что среди нескольких различных вариантов функционала f( a, x t), примерно одинаково отражающих общие тенденции процесса уt, более предпочтительным является тот из них, который обеспечивает и лучшую аппроксимацию (в математическом понимании этого термина). В общем случае “качество” эконометрической модели оценивается по двум группам характеристик, хотя, как это будет показано далее, предполагаемая группировка не вполне однозначна, поскольку, во-первых, характеристики каждой из групп часто имеют двойное назначение, а, во-вторых, многие из них взаимосвязаны друг с другом. В первую из групп включим показатели, критерии, выражающие “степень” соответствия построенной модели основным закономерностям описываемого ею процесса. Во вторую – показатели и критерии, в большей степени оценивающие точность ее аппроксимации наблюдаемых значений процесса уt . В этой связи следует отметить, что к критериям первой группы могут быть отнесен и критерий Стьюдента, используемый для оценки значимости влияния каждого из факторов хi, i=1, 2,..., n, на зависимую переменную уt (см. раздел 1.3). Соответствие эконометрической модели описываемому ею процессу уt в значительной степени может быть установлено на основе анализа свойств рассчитанного ряда ошибки et, t=1, 2,..., Т*. Если вариант модели “верно” отражает основные тенденции процесса уt , то можно ожидать, что значения ошибки в определенной степени случайны, их свойства близки к свойствам процесса “белого шума”. Если же тенденция, закономерности процесса уt учитываются моделью не в полной мере (в модель не включены какие-либо существенные с содержательной точки зрения факторы, выбрана форма функционала f( a, x t), не адекватная характеру взаимосвязей между рассматриваемыми переменными и т. п.), то в ряду ошибки обычно появляется некоторая закономерность, свидетельствующая об утрате свойства ее “случайности”. Заметим, что “неслучайный” характер фактической ошибки модели et может быть предопределен и неверно выбранным методом оценки параметров модели. Забегая вперед, отметим, что среди методов оценки параметров линейных эконометрических моделей наибольшее распространение получили метод максимального правдоподобия, метод наименьших квадратов и метод моментов. Каждый из них используется при вполне определенных исходных предпосылках относительно свойств ошибки модели et. Например, классические варианты этих методов используются в предположении, что ошибки совпадают со свойствами процесса “белого шума” (нулевое среднее, конечная дисперсия, отсутствие автокорреляционных связей). При этом “метод максимального правдоподобия” предполагает известным закон распределения ошибки. Чаще всего используется предположение о “нормальности” ее распределения. В этой связи построенная с использованием метода максимального правдоподобия модель будет считаться адекватной рассматриваемому процессу, если свойства фактической ошибки et, определенной согласно выражению (1.27), будут не слишком сильно отличаться от предполагаемых свойств ошибки et (“белого шума” с нормальным распределением). Метод наименьших квадратов не выдвигает столь жестких требований к закону распределения ошибки. Согласно ему оценки параметров моделей определяются исходя из критерия минимума суммы квадратов ошибки. В такой ситуации модель, построенная с использованием данного метода, будет считаться адекватной рассматриваемым процессам, если ее ошибка по своим свойствам идентична “белому шуму”. Если в отношении ошибки эконометрической модели et выдвигаются предположения, что ее свойства отличны от свойств “белого шума”, то для оценки параметров модели обычно используются так называемые обобщенные модификации данных методов. Отличие ошибки модели от “белого шума” может выражаться, например, непостоянством ее дисперсии на различных участках интервала t=1, 2,..., Т; наличием взаимосвязи между ее соседними значениями, выражаемыми, например, уравнением следующего вида et =b× et–1+xt, где xt – новая ошибка, по своим свойствам близкая к процессу “белого шума” и т. п. Однако на практике для моделей многих типов такие свойства ошибки модели априорно предвидеть обычно не представляется возможным. Их можно установить, только анализируя свойства фактической ошибки et, полученной для моделей, оценки коэффициентов которых определены с использованием “классических” методов оценивания. Таким образом, наличие или отсутствие свойства “случайности” в ряду выборочной ошибки модели et, t =1, 2,..., Т; в определенной мереуказывает на “соответствие” или “несоответствие” модели описываемому ею процессу у. В том случае, когда ошибка модели “неслучайна”, может быть рекомендовано уточнить рассматриваемый вариант модели, выбрать более подходящий для данной ситуации метод оценки ее параметров. Как было отмечено выше, “неслучайность” ошибки может иметь различный характер. Наиболее часто она выражается наличием автокорреляционной связи между соседними ее значениями, тенденциями, характеризующими изменения их квадратов, т. е. тенденциями в ряду et2, t=1, 2,..., Т и других ее производных. Для выявления “неслучайности” в ряду ошибки модели обычно используют специфические тесты, многие из которых будут рассмотрены в последующих главах учебника применительно к моделям соответствующих типов. Здесь же в качестве примера опишем особенности использования для этих целей достаточно универсального теста (критерия) Дарбина-Уотсона. Он наиболее широко применяется в эконометрических исследованиях вследствие своей простоты, хотя и не обладает существенной эффективностью (достоверностью). Тест Дарбина-Уотсона обычно используется для установления факта наличия автокорреляционной зависимости первого порядка в ряду ошибки et, т. е. между соседними ее значениями, et и et+1, t=1, 2,..., Т. Обычно соседние значения ошибки связаны более сильной зависимостью, чем значения et и et+2, et и et+3 и т. д. Вследствие этого отсутствие автокорреляционной связи между рядами значений выборочной ошибки et и et–1, t=1, 2,..., Т–1; позволяет с большой степенью уверенности утверждать, что в ряду истинной ошибки модели et отсутствуют вообще какие-либо автокорреляционные взаимосвязи. Значение критерия Дарбина-Уотсона рассчитывается по следующей формуле
Раскрывая квадрат в числители выражения (1.29), получим:
где r1– коэффициент автокорреляции первого порядка ошибки et, т. е. корреляции между рядами et и et+1. Из выражения (1.30) непосредственно вытекает, что
0 £ d £ 4. (1.31)
Значение d=0 соответствует случаю, когда между рядами et и et+1существует строгая положительная линейная зависимость, т. е. r1=+1, и значение d=4 соответствует строгой отрицательной связи, r1=–1. Если ряды et и et +1независимы, то r1=0 и d=2. Точки d=0; 2; 4 и определяют границы критерия Дарбина-Уотсона, в пределах которых гипотеза о наличии автокорреляции первого порядка в последовательности ошибок либо принимается (в областях близких к 0 или 4), либо отвергается (в области d=2), либо решение по данному критерию остается неопределенным (в промежутках между отмеченными областями). Иными словами, на отрезке [0, 4] выделяются четыре промежуточные точки, таким образом, что 0£ d1£ d2£ 2£ d3£ d4£ 4. Если расчетное значение критерия Дарбина-Уотсона находится на отрезках [0, d1], [d4, 4], то гипотеза о наличии автокорреляции первого порядка в ряду ошибок модели принимается, если расчетное значение d находится в интервале [d2, d3], – то отвергается. Значения d, приходящиеся на полуинтервалы [d1, d2] и [d3, d4], не позволяют сделать однозначного суждения по данной гипотезе. В последнем случае необходимо проводить более глубокий анализ зависимостей между значениями ошибки et, t=1, 2,..., Т. Другую группу критериев, в большей степени направленных на выявление степени точности аппроксимации функционалом f( a, x t ) наблюдаемых значений зависимой переменной уt, образуют широко используемые в статистике и эконометрике коэффициент множественной корреляции R, коэффициент детерминации D, критерий Фишера F. Здесь следует отметить, что общепринятой в статистике мерой точности “аппроксимации” является дисперсия (в нашем случае дисперсия модели). Ее значение на практике обычно определяется на основании следующей формулы:
где Однако значение дисперсии не отражает многих существенных аспектов качества модели и, кроме того, оно не очень пригодно для целей содержательного анализа. Несложно заметить, что величина ошибки тесно связана с уровнем зависимой переменной у, и в этой связи она имеет “абсолютное” содержание. В то же время “точность” в большей степени относительна. Поэтому меньшее значение дисперсии еще не свидетельствует о более высоком “качестве” модели, ее аппроксимирующих возможностях. Большая дисперсия может выражать лишь более высокие уровни независимой переменной, а не ухудшение точности ее аппроксимации построенной моделью. Здесь следует отметить, что и “относительность” ошибки может рассматриваться в двух аспектах. Во-первых, по отношению к уровню переменной у, а, во-вторых, – к некоторому уже установленному “эталону” точности. Как раз эти аспекты в большей степени и учитывают указанные критерии и коэффициенты. Коэффициент множественной корреляции показывает степень приближения расчетных (по построенной модели) значений зависимой переменной Значения коэффициента детерминации также находятся на отрезке [0, 1], 0£ D£ 1. Его конкретная величина показывает долю изменчивости переменной у, объясняемую включенными в модель факторами хi, i=1, 2,..., n. Например, если D=0, 81, то это означает, что включенные в модель переменные объясняют 81% изменчивости переменной уt, а остальная ее изменчивость объясняется неучтенными в модели причинами. Значения коэффициентов множественной корреляции и детерминации рассчитываются на основании следующего выражения*:
Обоснование целесообразности использования коэффициента детерминации при определении качества построенной эконометрической модели заключается в следующем. “Удачная“ модель должна “объяснять” основные закономерности изменчивости зависимой переменной уt. Количественной мерой этой изменчивости в статистике принято считать показатель, рассчитываемый на основании следующей формулы:
Заметим, что разница
Первое из слагаемых правой части выражения (1.35) представляет собой расчетное значение ошибки модели в момент t, т. е.
Как будет показано во II главе, ошибка et обладает рядом свойств
При этом первая из них
выражает сумму квадратов ошибки модели, т. е. часть изменчивости переменной уt, необъясненную построенной моделью, а второе слагаемое Разделив левую и правую части выражения (1.36) на
Из последнего выражения непосредственно следует (1.33), т. е.
Таким образом, если модель абсолютно точно соответствует исходному ряду зависимой переменной уt, т. е. расчетные значения В тех случаях, когда модель не может ни в како Популярное:
|
Последнее изменение этой страницы: 2016-03-25; Просмотров: 1394; Нарушение авторского права страницы


 y хi
y хi




 – средние значения соответствующих переменных, а
– средние значения соответствующих переменных, а  – их среднеквадратические отклонения.
– их среднеквадратические отклонения. достаточно велико, т. е.
достаточно велико, т. е.  , тем сильнее это влияние (положительное или отрицательное, в зависимости от знака r).
, тем сильнее это влияние (положительное или отрицательное, в зависимости от знака r).
 > r2, где r 2 »0, 8–0, 9. В таких ситуациях один из этих факторов целесообразно исключить из модели, с тем, чтобы одна и та же причина не учитывалась дважды. Однако повторим, что такое исключение следует проводить только в тех случаях, когда факторы выражают одно и то же явление.
> r2, где r 2 »0, 8–0, 9. В таких ситуациях один из этих факторов целесообразно исключить из модели, с тем, чтобы одна и та же причина не учитывалась дважды. Однако повторим, что такое исключение следует проводить только в тех случаях, когда факторы выражают одно и то же явление.
 – выборочное среднее некоторой случайной величины z;
– выборочное среднее некоторой случайной величины z;  – ее математическое ожидание (среднее по генеральной совокупности);
– ее математическое ожидание (среднее по генеральной совокупности);  – среднеквадратическое отклонение выборочного среднего.
– среднеквадратическое отклонение выборочного среднего.



 =f ( a, x t) – рассчитанные на основании уравнения модели f( a, x t) значения зависимой переменной, Т– количество измерений, п+1 – число параметров модели.
=f ( a, x t) – рассчитанные на основании уравнения модели f( a, x t) значения зависимой переменной, Т– количество измерений, п+1 – число параметров модели. ( a, x t) к действительным ее значениям уt . Величина коэффициента множественной корреляции меняется в пределах от нуля до единицы (0£ R£ 1). Значения R, близкие к нулю, свидетельствуют о том, что расчетные значения
( a, x t) к действительным ее значениям уt . Величина коэффициента множественной корреляции меняется в пределах от нуля до единицы (0£ R£ 1). Значения R, близкие к нулю, свидетельствуют о том, что расчетные значения  плохо аппроксимируют значения уt. Если R близок к единице, то это означает, что модель хорошо аппроксимирует исходный ряд значений уt, t=1, 2,..., T.
плохо аппроксимируют значения уt. Если R близок к единице, то это означает, что модель хорошо аппроксимирует исходный ряд значений уt, t=1, 2,..., T.

 представляет собой отклонение значения уt от среднего уровня этой переменной, а общая изменчивость, таким образом, выражается в виде суммы квадратов всех таких отклонений. После построения модели и определения на ее основании “расчетных” значений
представляет собой отклонение значения уt от среднего уровня этой переменной, а общая изменчивость, таким образом, выражается в виде суммы квадратов всех таких отклонений. После построения модели и определения на ее основании “расчетных” значений 
 . Второе слагаемое выражает отклонение этого расчетного значения от среднего уровня переменной уt. С учетом (1.35) выражение (1.34) можно записать в следующем виде:
. Второе слагаемое выражает отклонение этого расчетного значения от среднего уровня переменной уt. С учетом (1.35) выражение (1.34) можно записать в следующем виде: 
 , используя которые можно доказать, что последняя сумма в правой части выражения (1.36) равна нулю. Отсюда вытекает, что общая изменчивость переменной уt также может быть представлена в виде двух составляющих
, используя которые можно доказать, что последняя сумма в правой части выражения (1.36) равна нулю. Отсюда вытекает, что общая изменчивость переменной уt также может быть представлена в виде двух составляющих

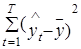 – часть изменчивости переменной уt , которую построенная модель объяснила.
– часть изменчивости переменной уt , которую построенная модель объяснила. , получим
, получим

 f( a, x t) равны уt для всех t =1, 2,..., T, то D=R=1.
f( a, x t) равны уt для всех t =1, 2,..., T, то D=R=1.