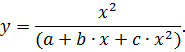|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Организация файлов и анализовСтр 1 из 4Следующая ⇒
Организация файлов и анализов Организация данных Создание файла с данными
Появится окно Create New Document (Создание нового документа). В котором необходимо ввести: · количество переменных Number of variables; · объем выборки (строк) Number of cases. ОК. Появится окно New Data.
В поле Имя файланужно ввести название файла с данными. Сохранить. Чтобы вставить данные в программу Статистика, необходимо просто сделать процедуру копирования из МОExcel (Ctrl+C– копировать из MOExcel, далее при переходе в программу Статистика Ctrl+V). Если строк не хватает, то программа автоматически добавит необходимое количество строк в файл с данными. В итоге в окне появятся данные, скопированные из MOExcel.
Переименование данных Далее необходимо подписать вектора данных. Для этого нужно два раза нажать на название графы VAR1. Появится окно с названием переменной. Необходимо заполнить следующие поля:
Аналогичные действия проведите со всеми признаками, взятыми для анализа.
Генерация данных Сначала нужно выделить колонку. Нажать два раза по заголовку столбца. В появившемся окне ввести Имя переменной, ширину столбца, число цифр после запятой, определить тип данных.
В нижней части окна вводим формулу, по которой рассчитывается данная переменная (=H-H_SH). ОК. ОК.
В окне данных появился новый показатель.
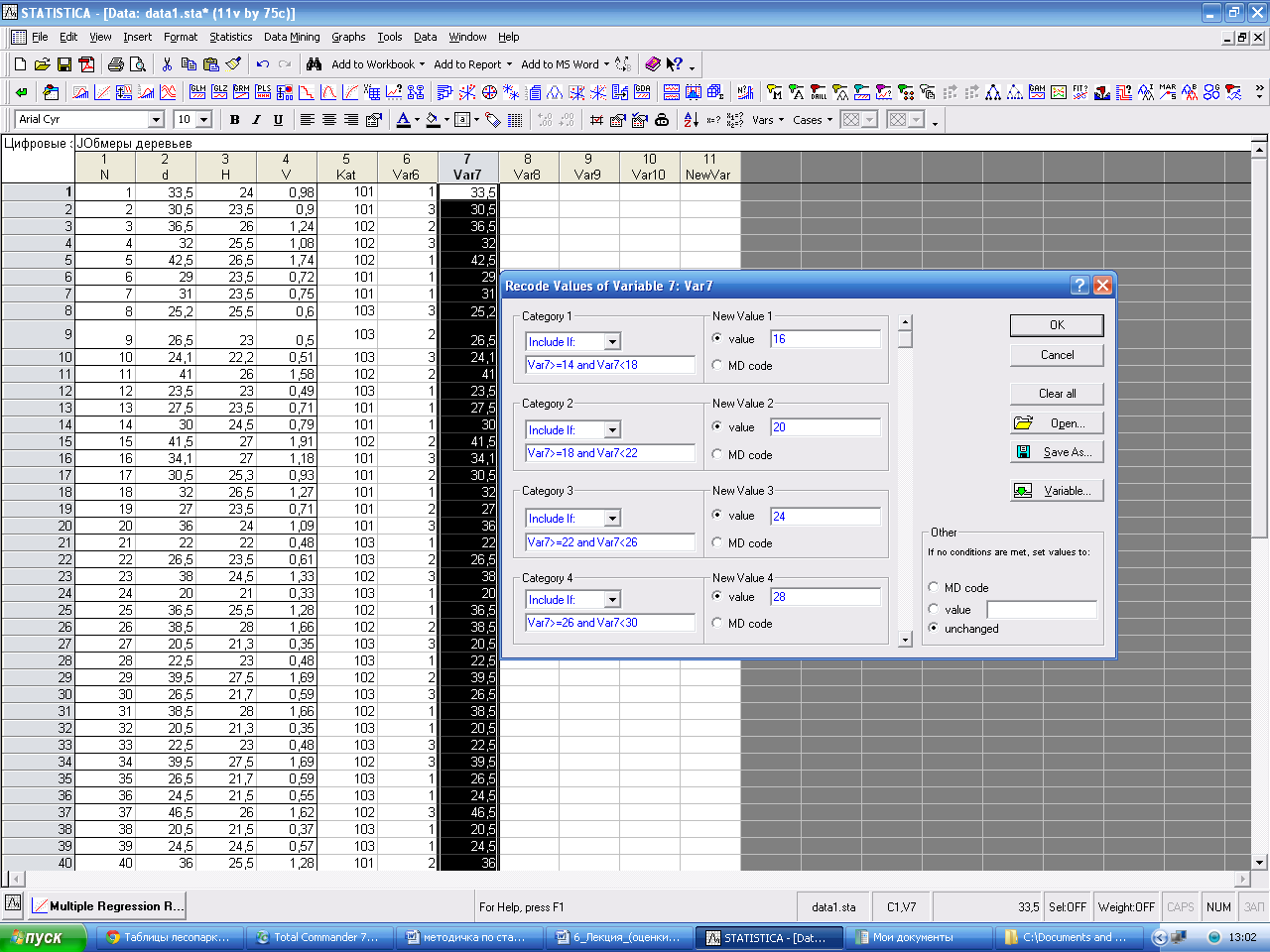
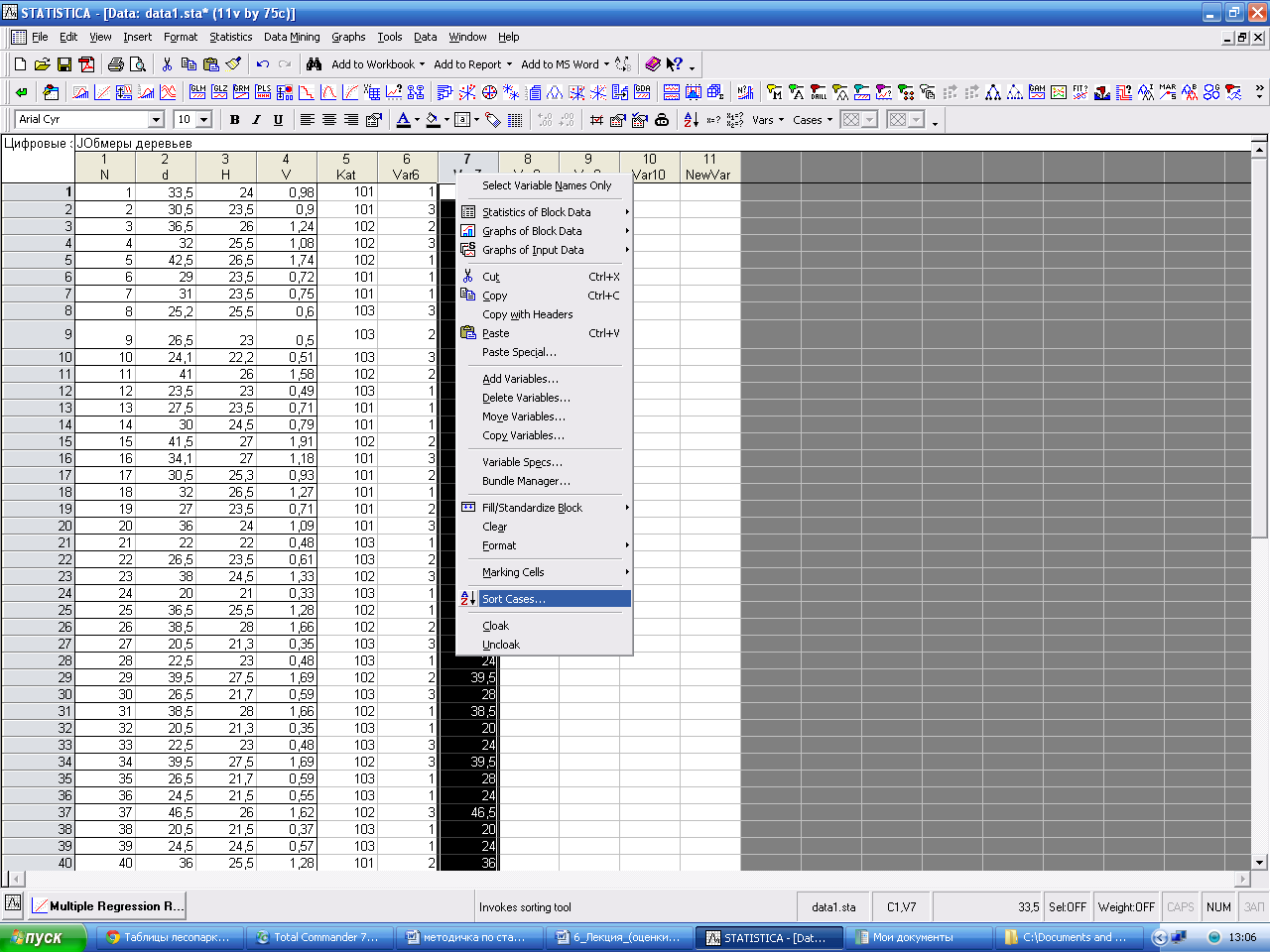
Файл с данными необходимо сохранить. Расширение *.stw. Группировка данных Modify variable(s) (Изменение переменных) / Recode (перекодировка). Появится окно Recode Values of Variable, в котором задаем границы интервалов следующими командами: Var7> =14 and Var7< 18 и т.д. ОК Далее можно отсортировать данные. Для этого встаньте на заголовок с данными, нажмите правую клавишу мыши, вызовите команду Sort Cases (сортировка).
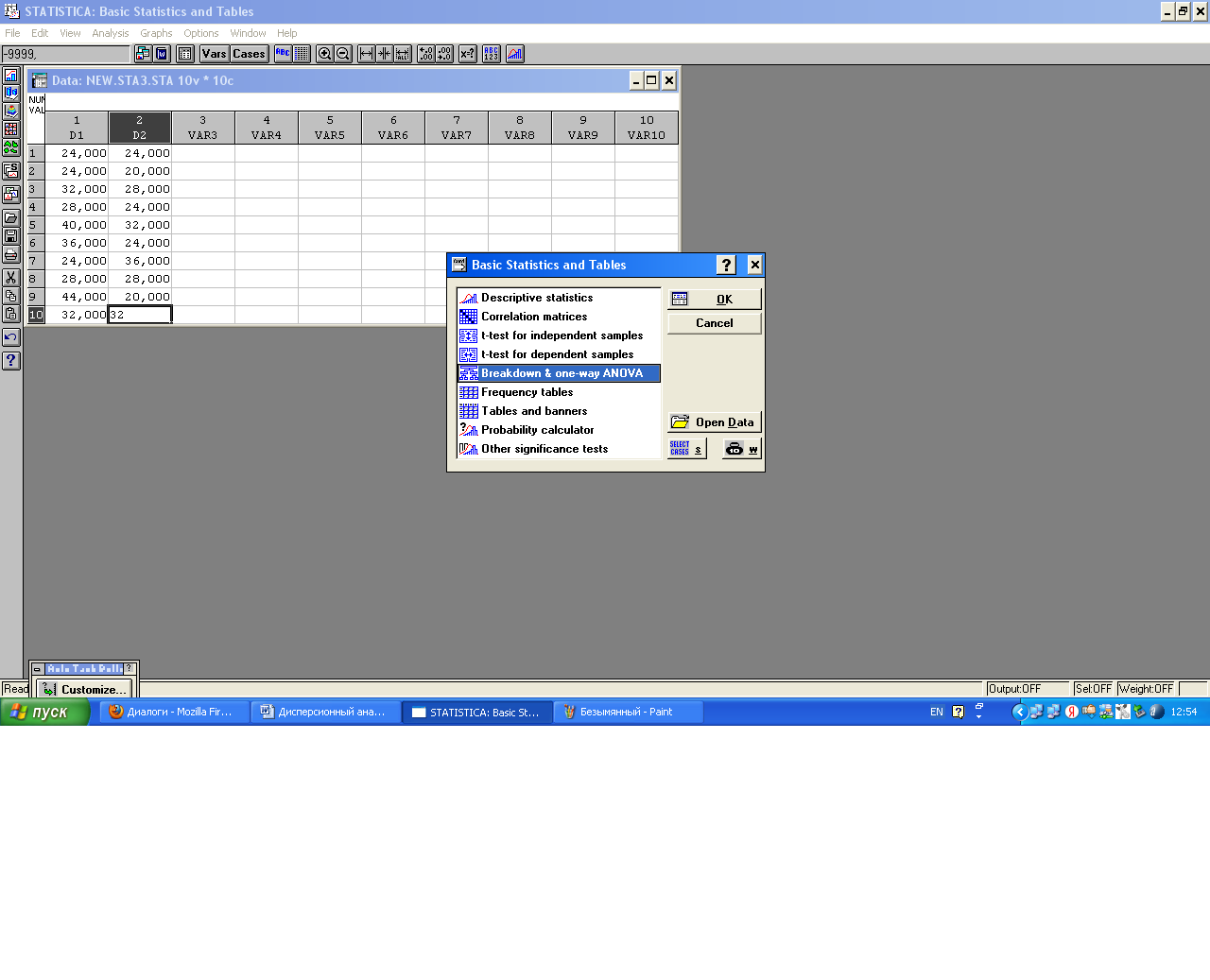
Расчет основных статистик НеобходимовызватькомандуStatistics → Basic Statistics/Tables.ДалеевыберитеDescriptivestatistics (Описательныестатистики). Для несруппированного ряда Появится окно Descriptivestatistics. Необходимо выбратьпеременные, нажав для этого клавишуVariables.Далее перейдите на закладкуAdvanced(Дополнительные).Появляется окно, где можно отметить нужные статистики. Выберите статистики, которые необходимо рассчитать в данном анализе, если есть надобность можно сразу выделить все статистики, для этого нажмите кнопку Selectallstats. Нажмите кнопку Summary.
Данные анализа можно скопировать (Ctrl+C) и вставить (Ctrl+V) в Excel. Для копирования с заголовками можно выделить все данные и далее выполнить команду Edit (Редактирование) – CopywithHeaders (Копировать с заголовками). Далее вставить в Excel(Ctrl+V). Расчет основных статистик для сгруппированного ряда Бывают ситуации, что исследователь имеет уже сгруппированные данные, поэтому надо получить статистики для большой выборки. Это данные в графах 7 и 8 (Ступень толщины и частота). Для расчета статистик по сгруппированному ряду необходимо в окне Descriptivestatistics выбрть переменную по которой необходимо рассчитать статистики. Далее нажмите клавишу W (вес).
ПоявитсяокноDefineWeight. ВполеWeightvariable: введите переменную, которая определяет встречаемость данного класса (N (частота)). ОК. ЗатемнужнонажатькнопкуDetailedDescriptivestatistics.
Построение Гистограммы Необходимо нажать накнопкуHistogramsвокнеFrequencytables. Получим график Гистограмма по выбранной переменной.
Для того чтобы сделать необходимые подписи на русском языке нужно нажать правой клавишей мыши на названии оси и выберите шрифт MS Sans Serif и подписать необходимые оси и заголок графика в окне EditTitles. Графический анализ данных Этапы Сформировать проверяемую H0 и альтернативную H1 гипотезы 1. Назначить уровень значимости α 2. Выбрать статистику Z критерия для проверки гипотезы H0 3. Определить выборочное распределение статистики Z критерия при условии, что верна гипотеза H0 4. Определить критическую область Vk в зависимости от формулировки альтернативной гипотезы одним из неравенств 5. Получить выборку наблюдений и вычислить значение критерия Xв 6. Принять решение В статистических пакетах (таких как Статистика) обычно в прямом виде критерий значимости α не задается. В анализах выдается значение вероятности того, что случайная величина Z (если гипотеза H0 верна) превышает Zв: Вероятность называется p-значением ( p-level ) Если P> α , нулевая гипотеза принимается. Если P< α , нулевая гипотеза опровергается. Пример: Проверить гипотезу, что варианты описываются нормальным распределением. (Распределение по диаметру). Принять α =0, 05. В пакете Статистика выбирается Statistics → DistributionFitting (Подбор распределений). Далее в появившемся окне выбирается ContinuousDistributions (Непрерывные распределения), нормальное – Normal.
ОК. В окне FittingContinuousDistributions в поле Variables введите имя переменной по которой будете проводить анализ. На закладке Parameters (Параметры) программа рассчитает среднее (Mean) и дисперсию (Variance).
По умолчанию, количество интервалов равно 10. Его можно изменить. Нажмите Summary. На экране появится таблица расчета.
χ 2выч=3, 02, число степеней свободы df=4, вычисленное значение вероятности p=0, 553. В результате, вычисленное значение уровня значимости значительно превышает заданный уровень значимости 0, 553 > 0, 05, то гипотезу, что наша переменная описывается нормальным законом распределения принимается.
Работа _ 1. Вычислить доверительные интервалы для среднего и дисперсии нормально распределенной генеральной совокупности при α =0, 05; 2. Проверить гипотезы H0: X=X0, где X0=X+0, 5S
Использование t-статистики Проверка о равенстве средних и дисперсий двух нормально распределенных генеральных совокупностей. Даны 2 выборки d1 и d2. Предположим, что обе выборки получены из генеральных совокупностей, имеющих нормальное распределение. Для проверки гипотезы используется t-статистика (статистика Стьюдента). В программе Statistica используется модуль Statistics-Basic Statistics /Tables- t-test for independent, by variables (t-критерий независимых выборок)
Каждая выборка представлена как переменная. Вводим в соответствующие поля переменные для анализа.
ОК. Summary t-test.
Результаты вычислений представлены в следующем окне.
Mean Group – средние первой и второй выборок. Valid N – объемы выборок Std. Dev. – стандартные (средние квадратические ) отклонения t-value – t-статистика t=-0, 1390 t=
s= p – уровень значимости p = p [| t(df)|> | t|] p[|t(148) |> 0, 1390] = 0, 8896 df – число степеней свободы df = N1+N2-2 Можно сделать выводы, что на уровне значимости α =0, 05 гипотеза о равенстве средних ____
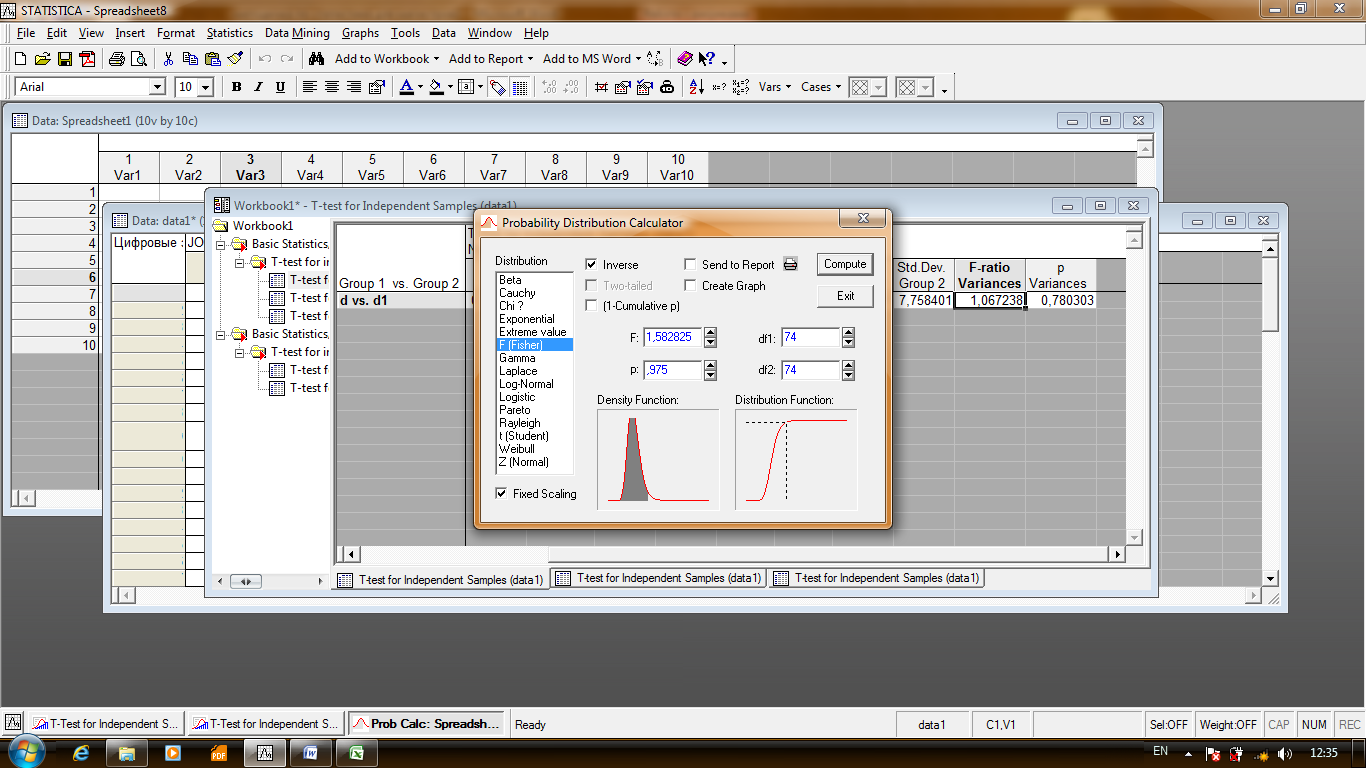
Приведенная t-статистика может быть использована, если дисперсии сравниваемых генеральных совокупностей равны. Это можно проверить Где Для рассматриваемого примера значение t-статистики Его вычисляют при помощи Probality Calculator- Distibutions…. .
В итоге получилось
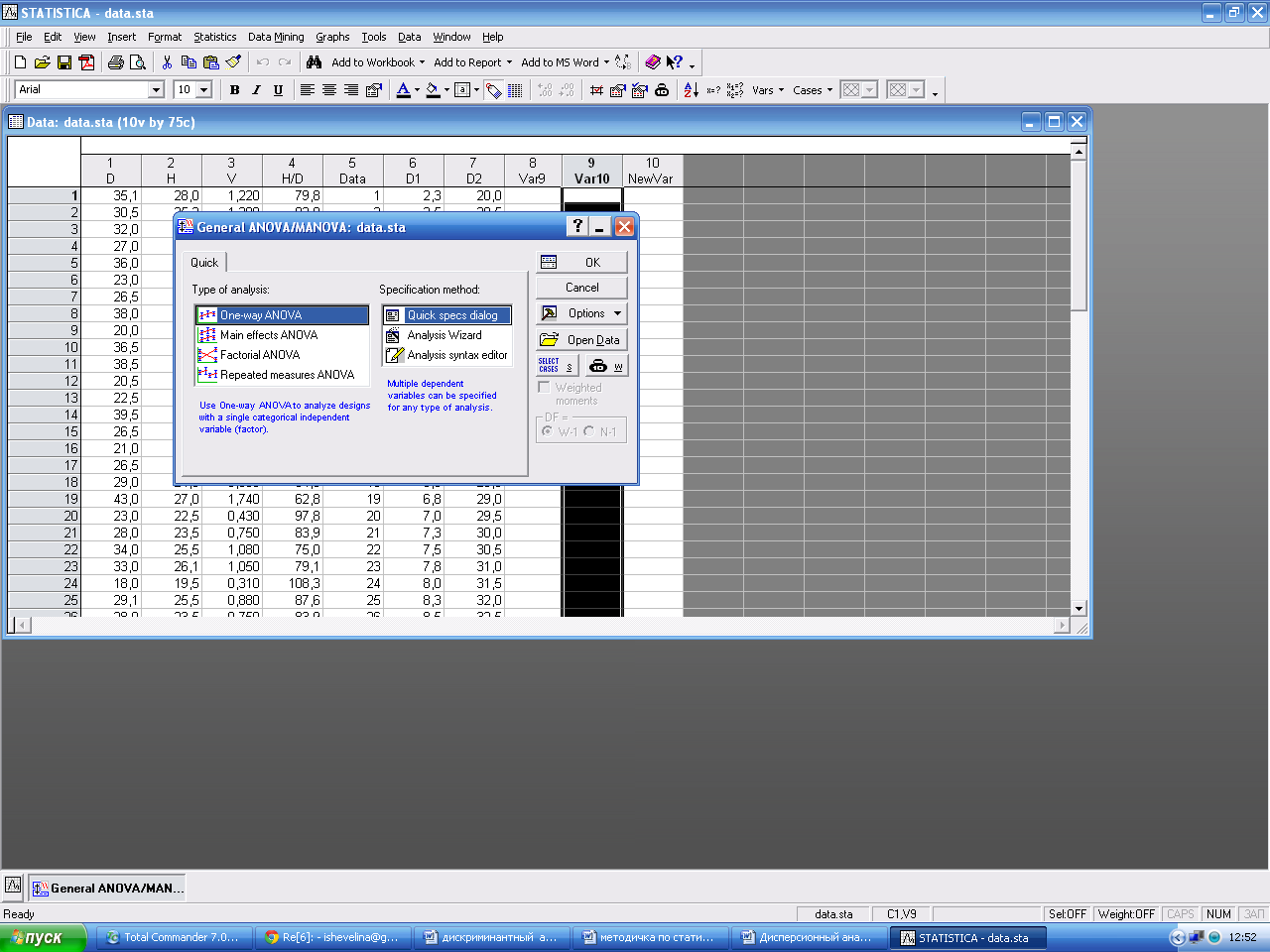
Корреляционный анализ Дисперсионный анализ Задачи 1. Подготовить данные для проведения однофакторного дисперсионного анализа; 2. Рассчитать значения критерия Фишера для исследуемых зависимостей; 3. Получить таблицу средних значений в группах дисперсионного комплекса; 4. Построить графики средних значений и их доверительных интервалов для исследуемых зависимостей.
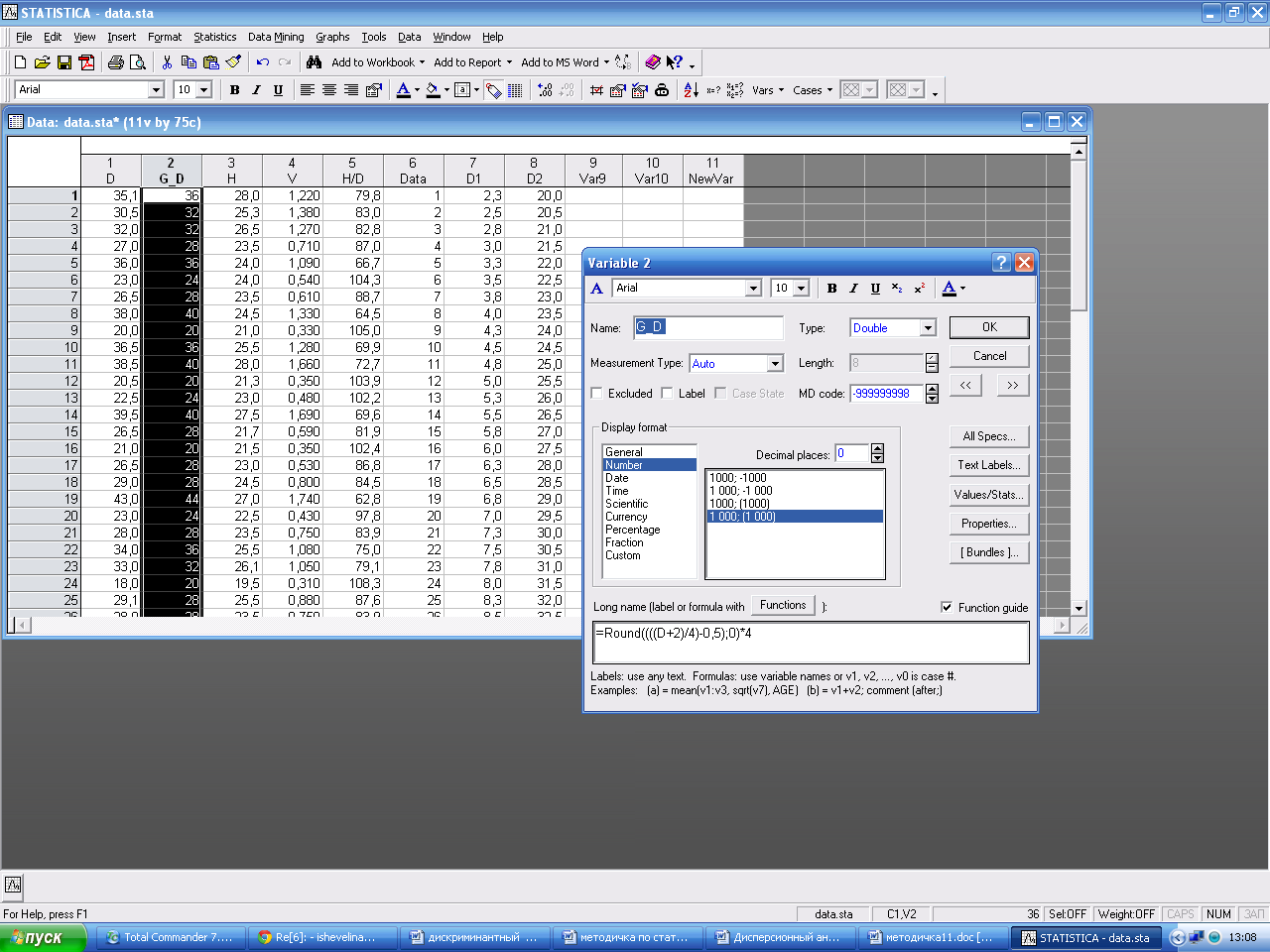
Процедура 1. Подготовка данных До проведения однофакторного дисперсионного анализа необходимо провести предварительную подготовку данных, т.е. преобразовать значения фактора, отнести его к той или иной градации. Диаметры на высоте груди могут быть заменены значением соответствующей ступени толщины. Для этого над каждым членом вектора D произведем следующую модификацию, используя формулу: Gr_D=ROUND(((D + a/2)/a)-0, 5)*a.
В нашем случае величина ступени толщины равняется 4 см, поэтому формулу запишем в следующем виде: ROUND(((D + 4/2)/4)-0, 5)*4. Создаем новую переменную и в поле Functionsвводим формулу для расчета новой переменной:
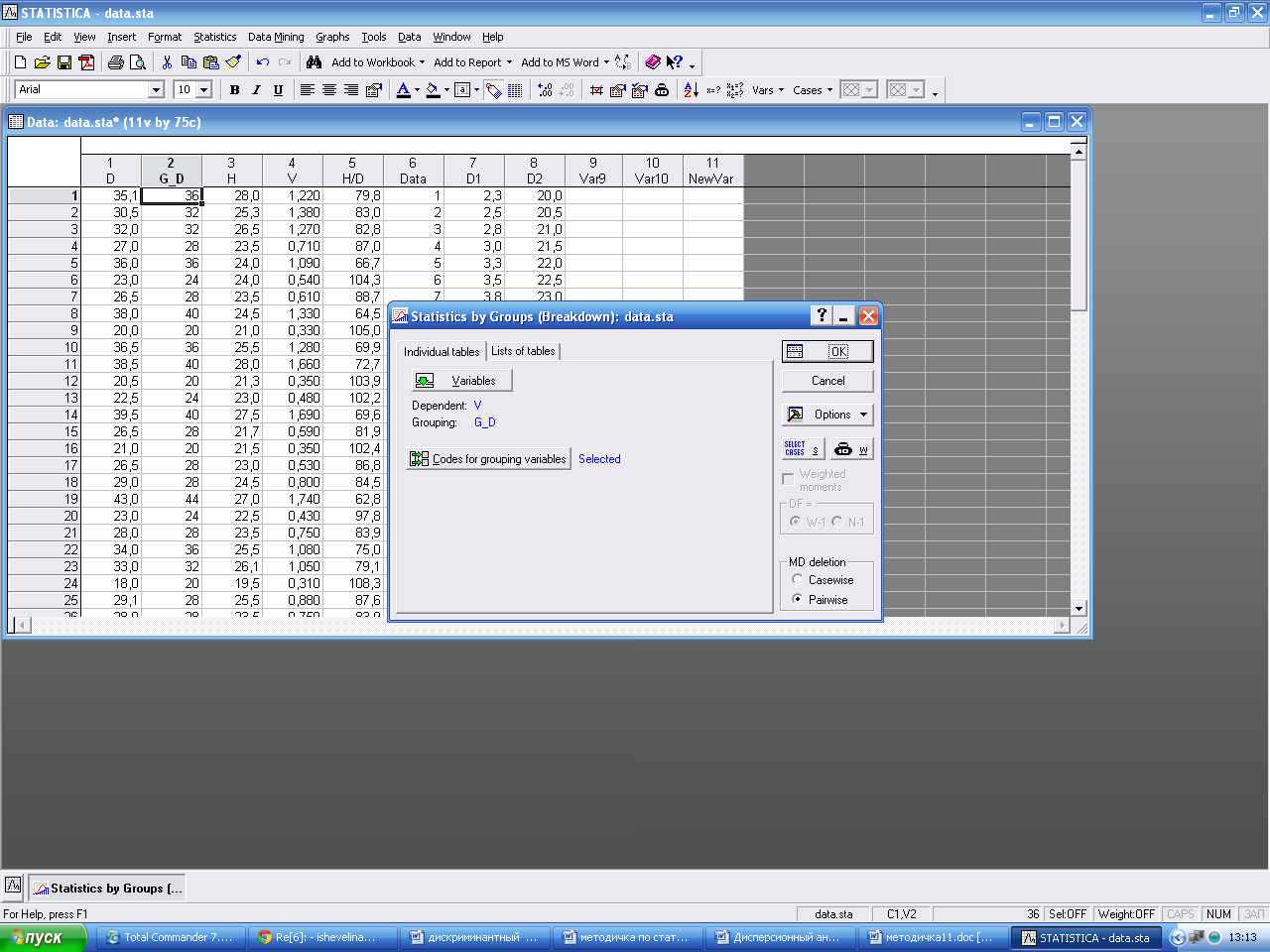
В окне Basic Statistic and Tables выбираем Breakdown & one-way ANOVA, ОК.
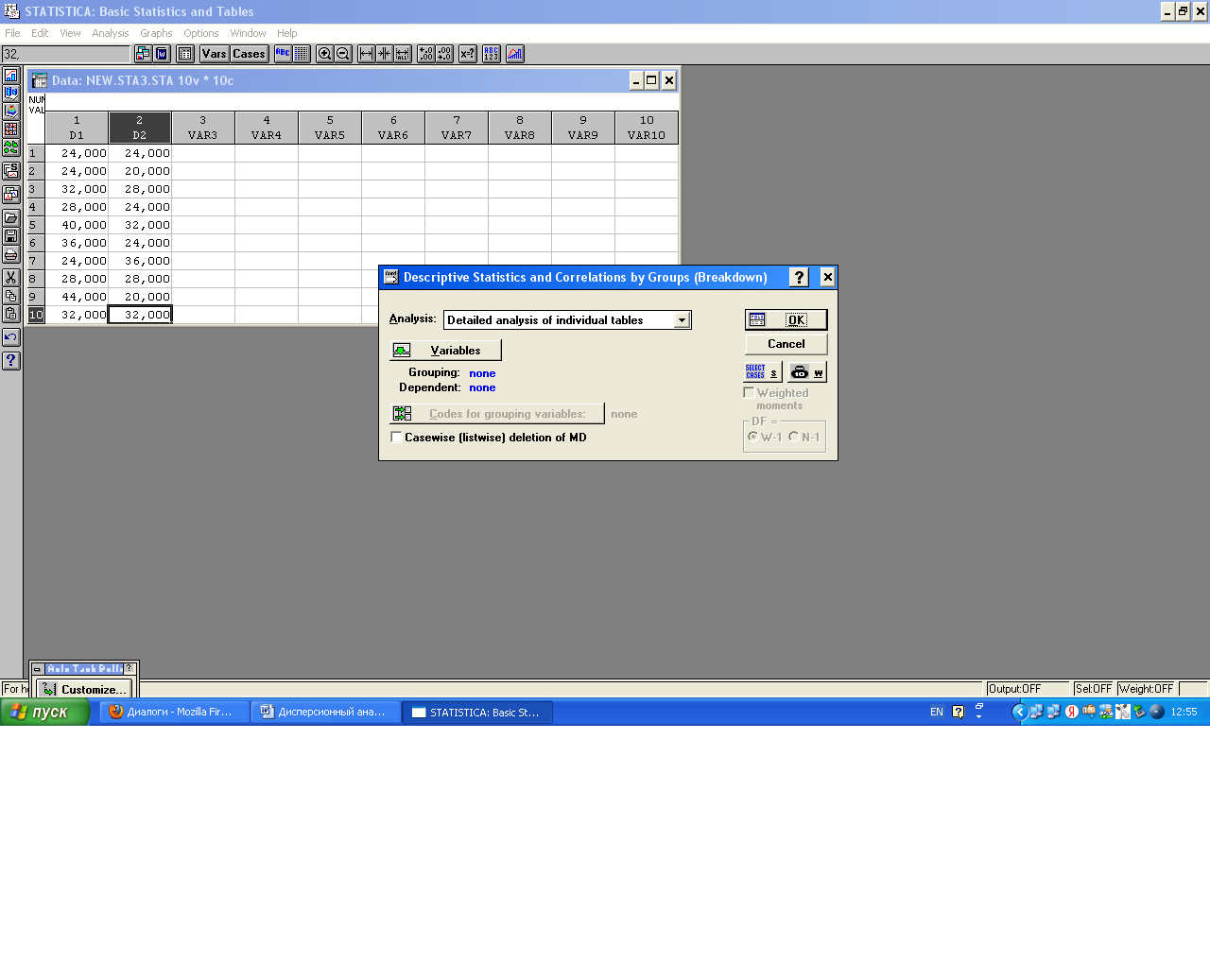
В появившемся окне Descriptive Statistics and Correlations by Groups (Breakdown) в строке Analysis выбираем Detailed analysis of individual tables, ОК.
В окне Selectgroupingvariablesandthedependentvariables выбираем нужные столбики по данным, которых ведется анализ –G_D и V, ОК. Codes for grouping variables нажимаем клавишу All. И появляются все коды групп диаметров. OK. Вокне Descriptive Statistics and Correlations by Groups – Results, напротиввсехстрокставимгалочки, ОК.
OK.
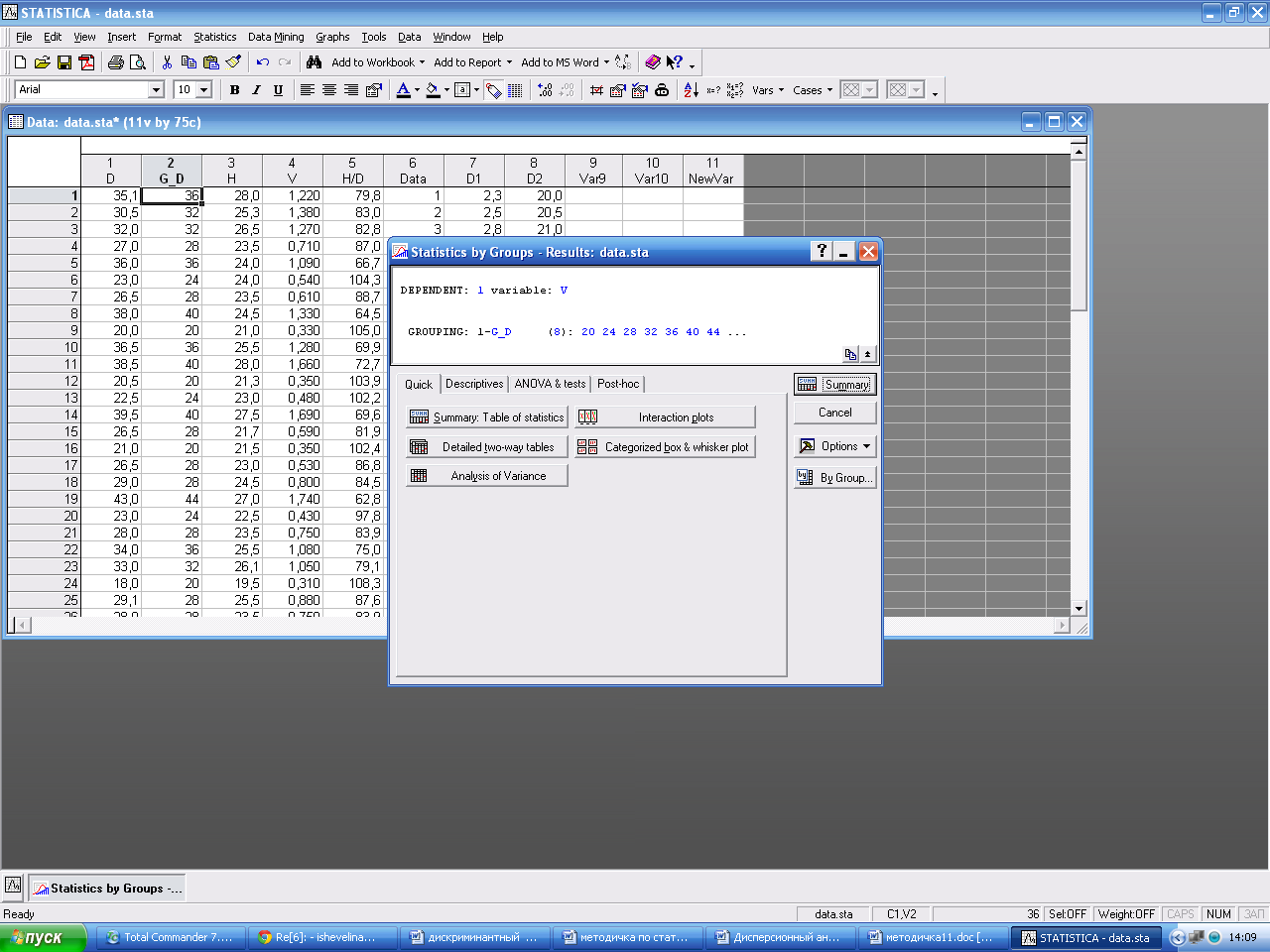
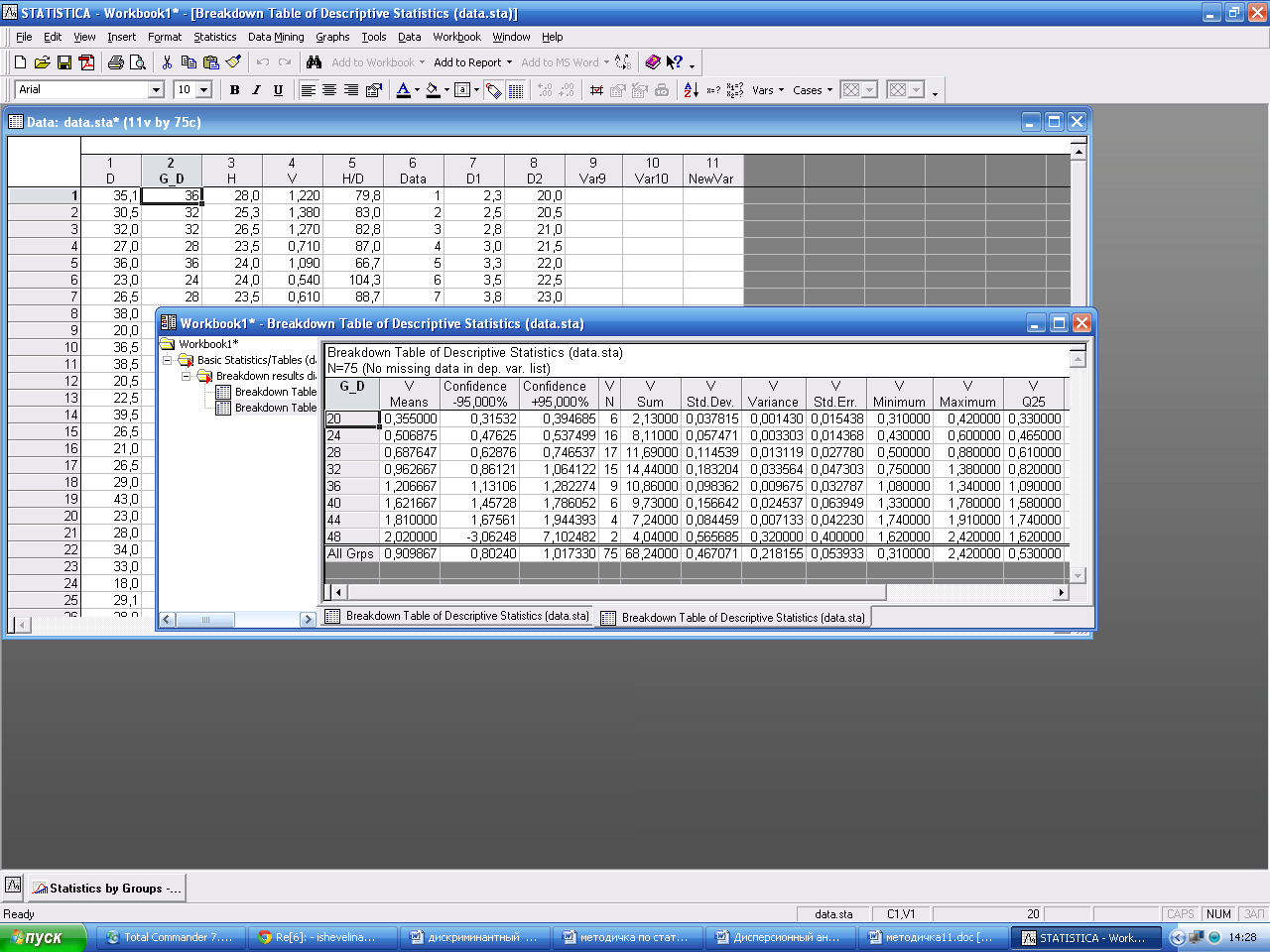
Появляется общая информация по дисперсионному анализу Summary: Table o f statistics–таблица средних квадратов по градациям фактора.
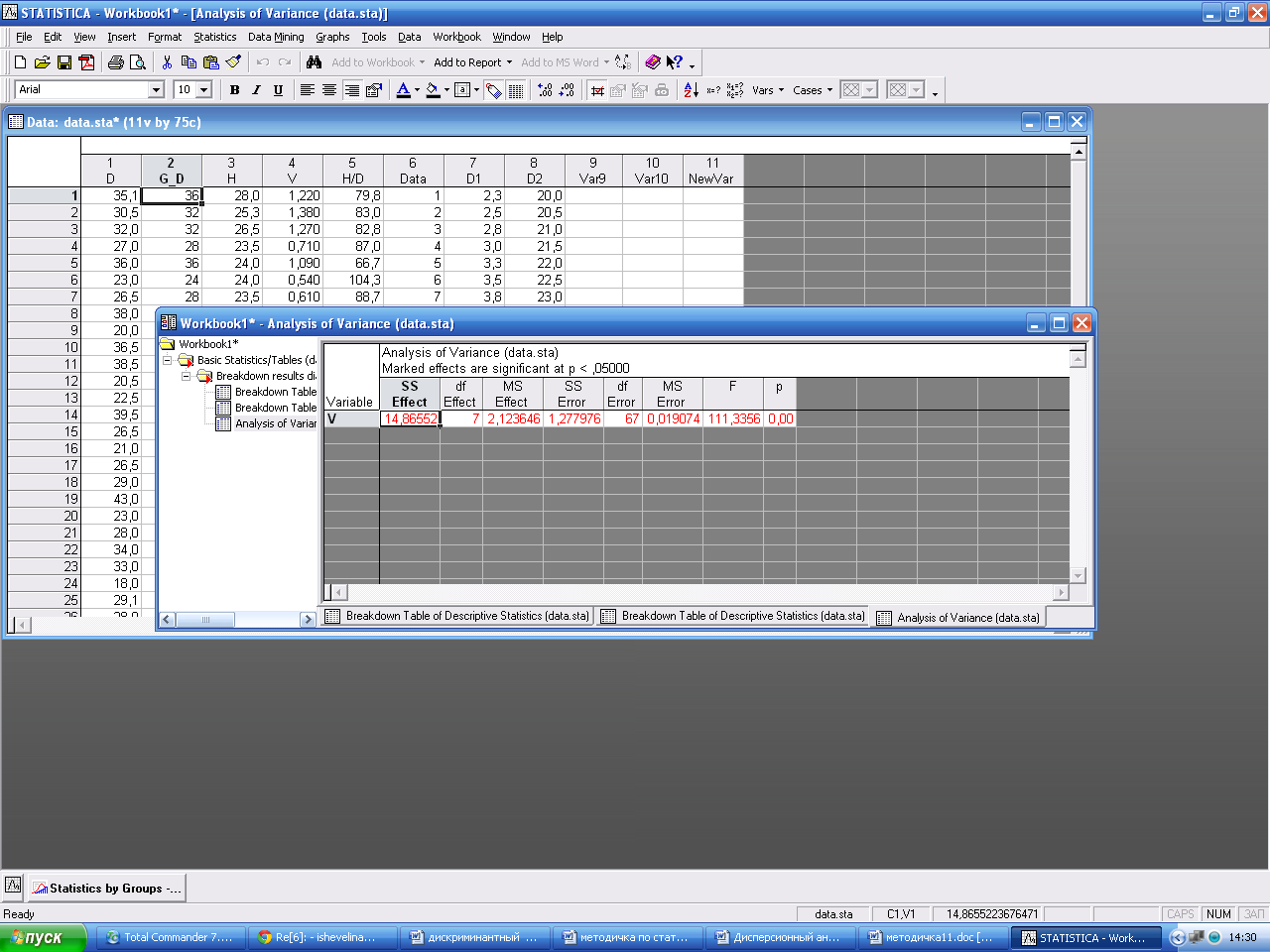
В окне Descriptive Statistics and Correlations by Groups – Results, выбираем кнопку Analysis of Variance (дисперсионный анализ), ОК. Выводится таблица дисперсионного анализа, в которой можно увидеть: сумма квадратов отклонений выборочных средних групп от общего среднего (SS Effect), число степеней свободы (do Effect), средний квадрат (MS Effect), сумма квадратов отклонений результатов наблюдений от выборочных средних групп (SS Error), число степеней свободы (Df Error), средний квадрат (MS Error) выборочное значение F фактическое и вычисленный уровень значимости p.
Вычисленное значение уровня значимости p меньше заданного (p=0, 05), то гипотеза о равенстве средних отклоняется. Диаметр на высоте груди значимо влияет на объем ствола деревьев. Если Fвыч > F stα , df1, df2, то влияние фактора на признак признается достоверным, нулевая гипотеза отвергается; если Fвыч < F stα , df1, df2, то влияние фактора на признак считается несущественным, случайным, т.е. нулевая гипотеза признается достоверной. По таблице (Прилож._) находим значение F stα , df1, df2= 2, 2, сравниваем с вычисленным 111, 34 > 2, 2. Вывод – влияние фактора на признак – достоверно.
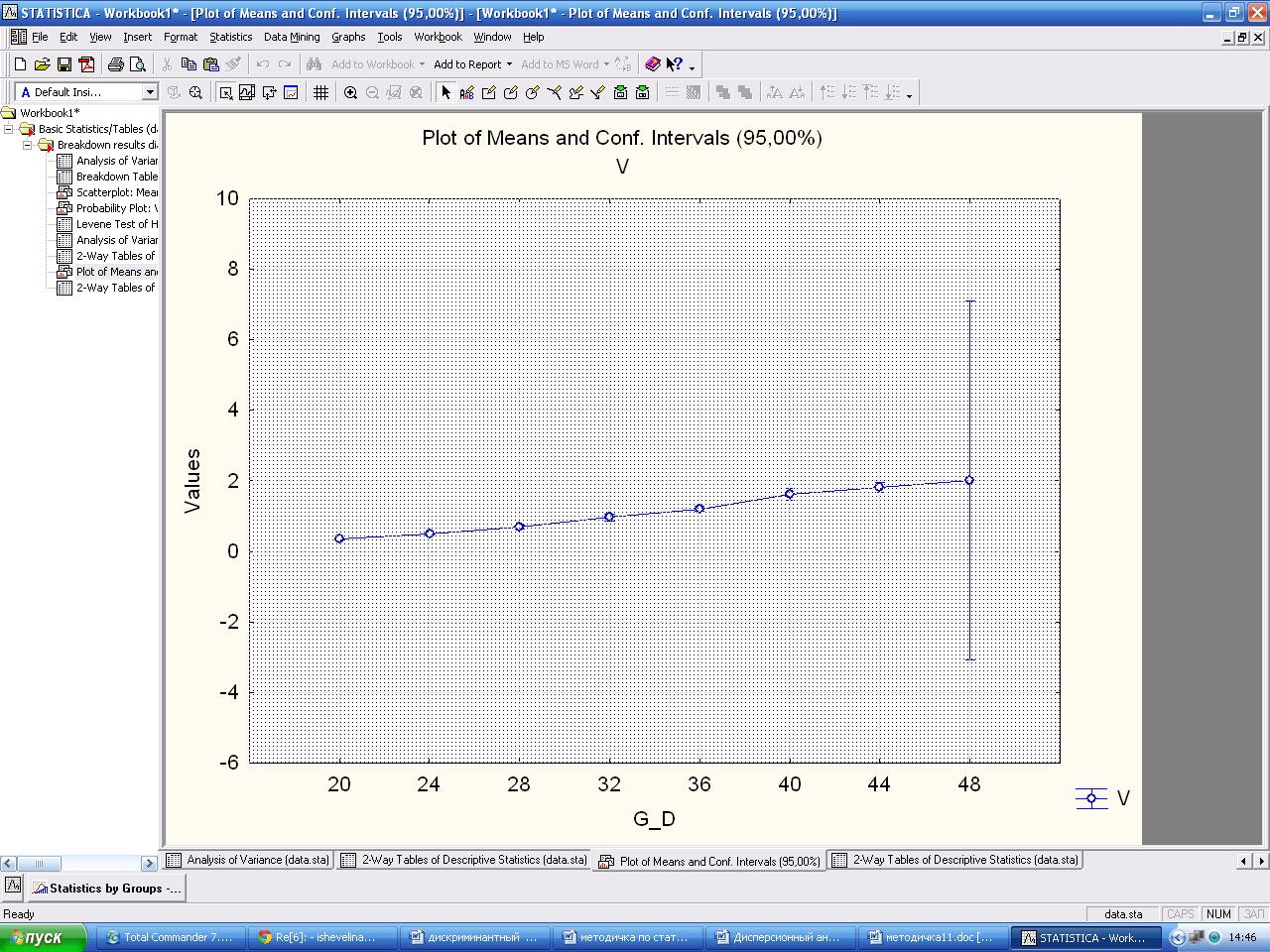
Проверка на нормальность Предполагается, что исходные данные – это независимые выборки, которые получены из нормально распределенных генеральных совокупностей. В окне Descriptive Statistics and Correlations by Groups – Results, выбираем кнопку Levene, ОК. Таким образом, производим дисперсионный анализ на основе критерия однородности дисперсии Левина. Построение графиков В окне Descriptive Statistics and Correlations by Groups – Results, выбираем кнопку Interaction plots, ОК. В результате получаем график для D2.
Настройте оси. Регрессионный анализ 10.1. Проведение парного регрессионного анализа: 10.2. Использование криволинейной регрессии. Вставим данные из MOExcelв пакет Statistica, далее подписываем вектора данных.
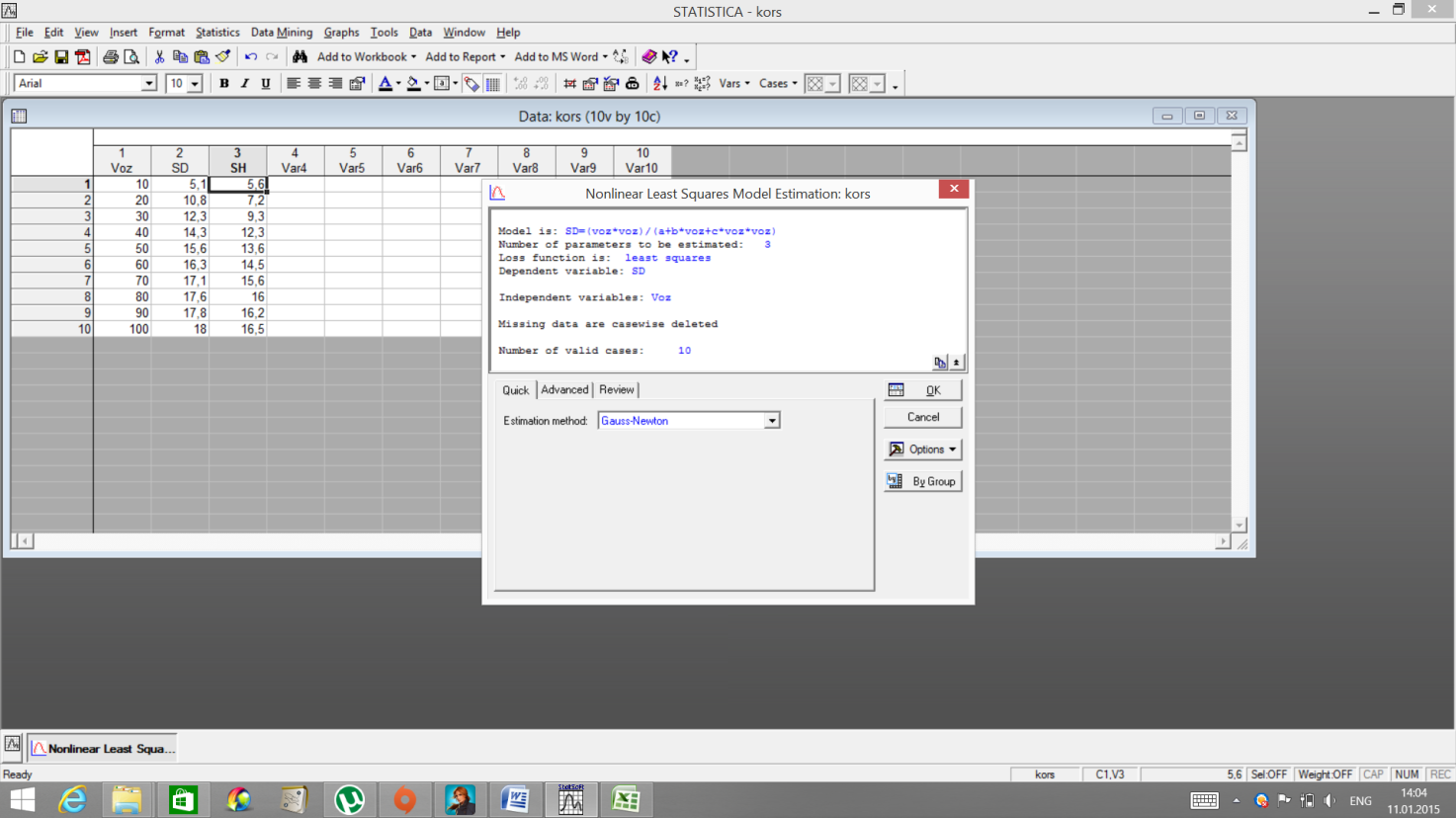
НеобходимовызватьизменюStatistics→ Advanced Linear/NonlinearModels → NonlinearEstimation. Далеевыберите User-specified regression, least squares.
Нажмите OK. Появляется окно User-specified Regression Function. Далее нажмите клавишу Function to be estimated and loss function. Появляется окно Estimated function, в котором необходимо вписать нужную формулу, например, формулу Корсуня, в общем виде, которая имеет вид:
Где х - это возраст древостоя, лет; у - это диаметр древостоя, см. Нажмите ОК. В поле MDdeletion выберите Casewise. Нажмите ОК.
В поле Estimation method выберите метод Gauss-Newton. ОК.
Появляется окно Results.
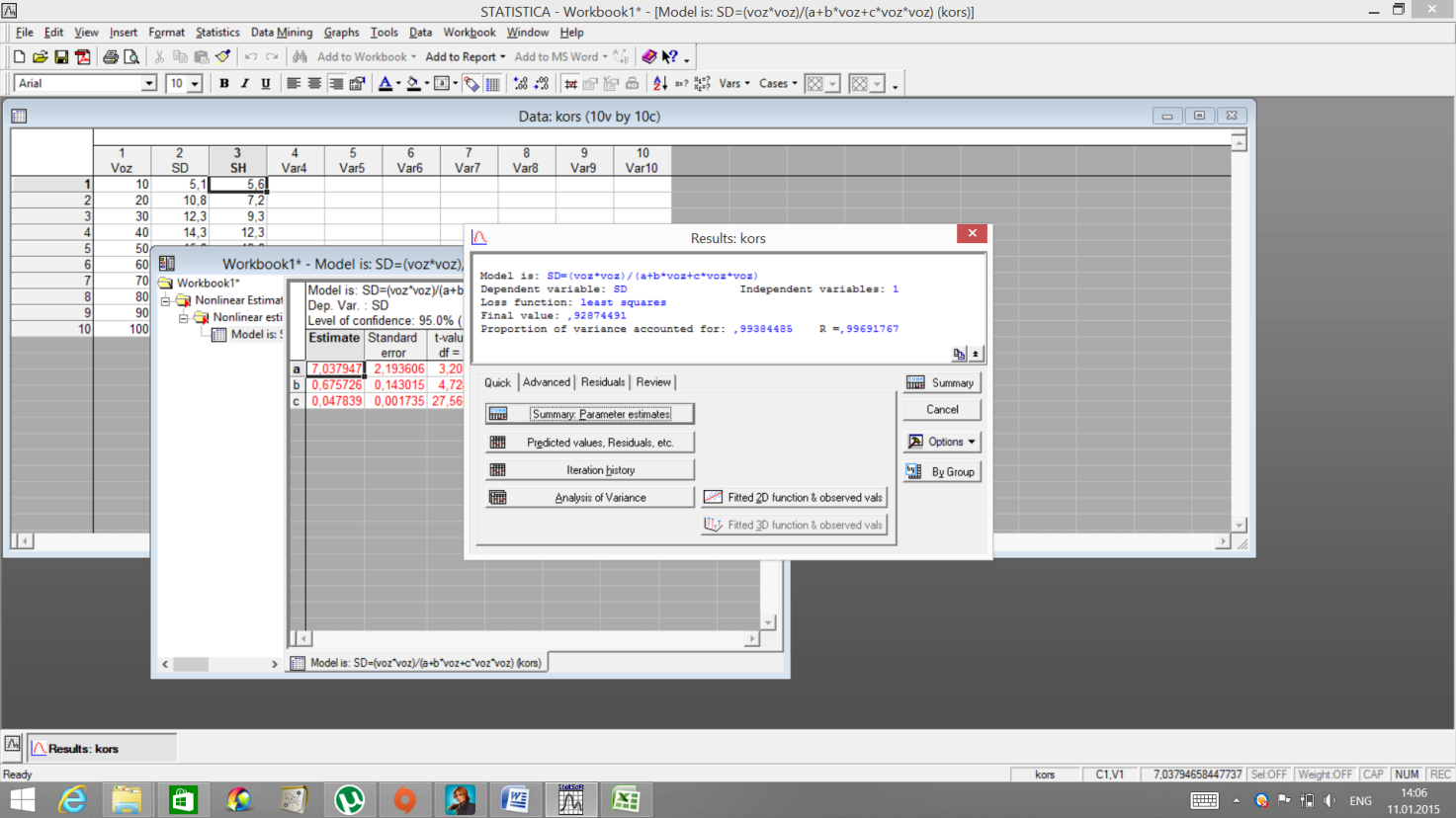
Основные результаты расчетов можно увидеть в окне, нажав Summary Parametrs estimates.
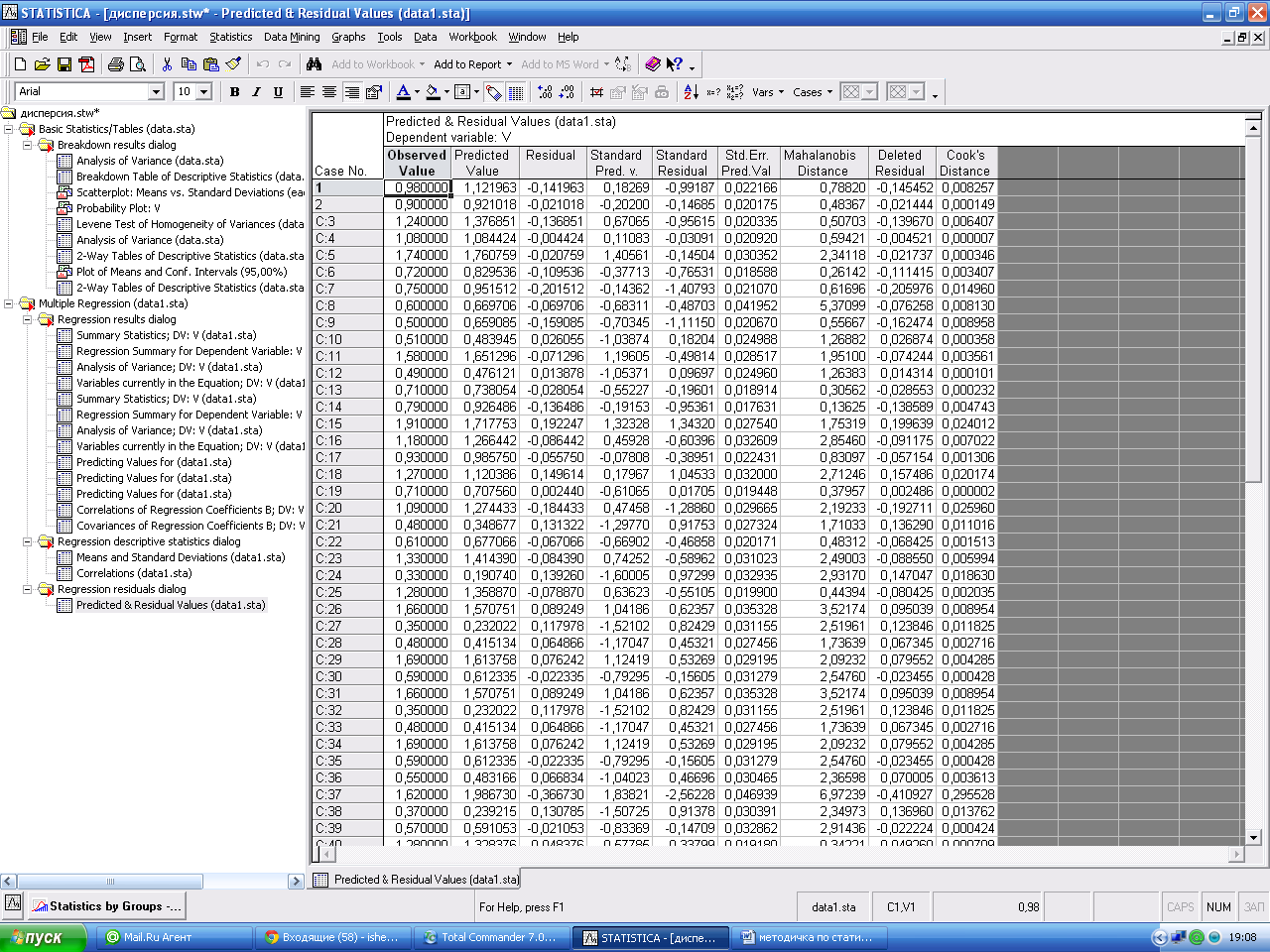
В столбце Estimate представлены результаты расчетов коэффициентов. По клавише Predictedvalues, Residuals можно увидеть наблюдаемые Observed (практические) и предсказуемые Predicted (теоретические) значения.
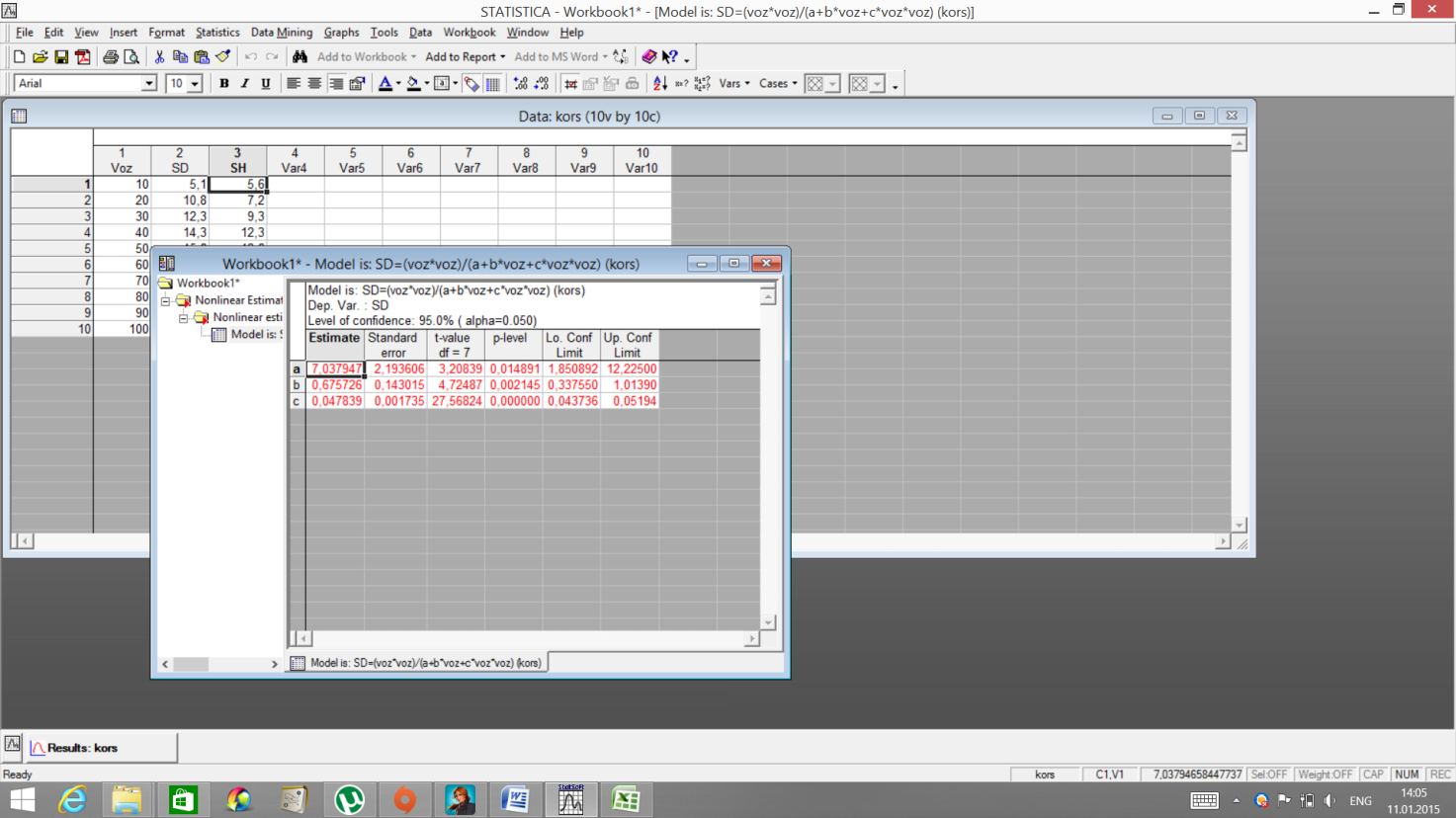
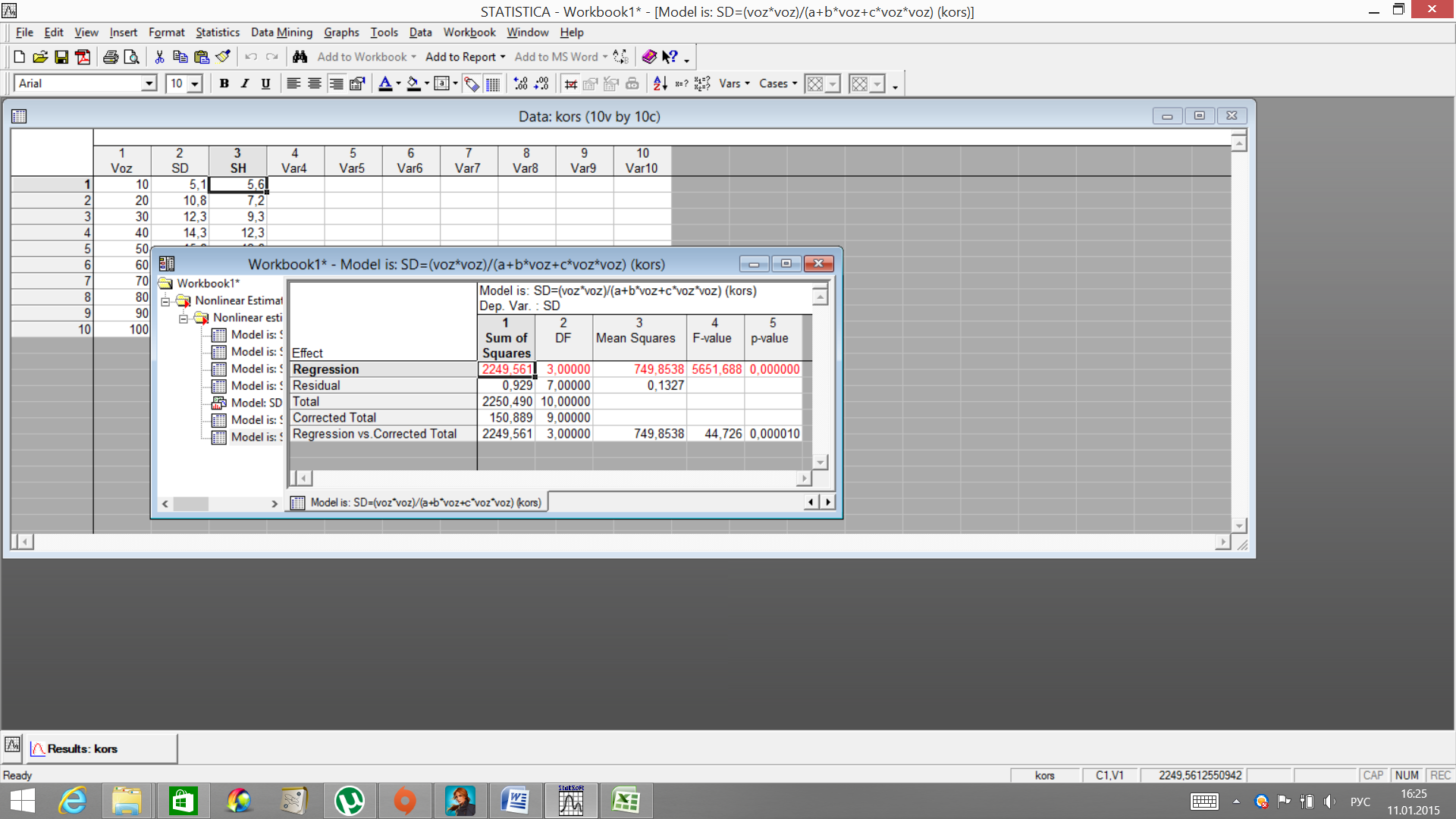
Сравните значения практические и рассчитанные. Далее проанализируйте данные дисперсионного анализа по клавише AnalysesofVariance.
В окне представлены основные данные: Regression (порегрессии) Residual (остаточные) Total(общая)
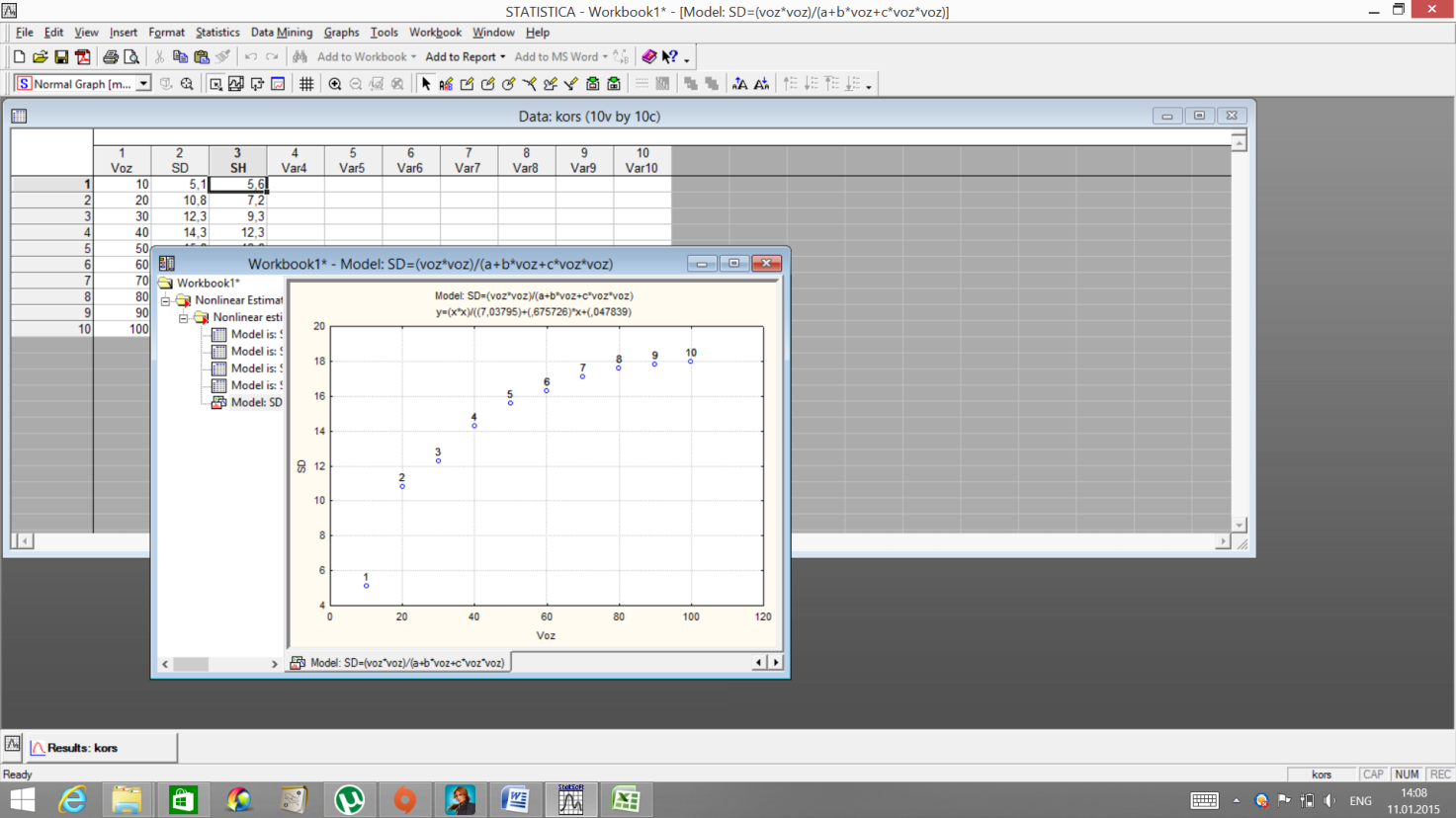
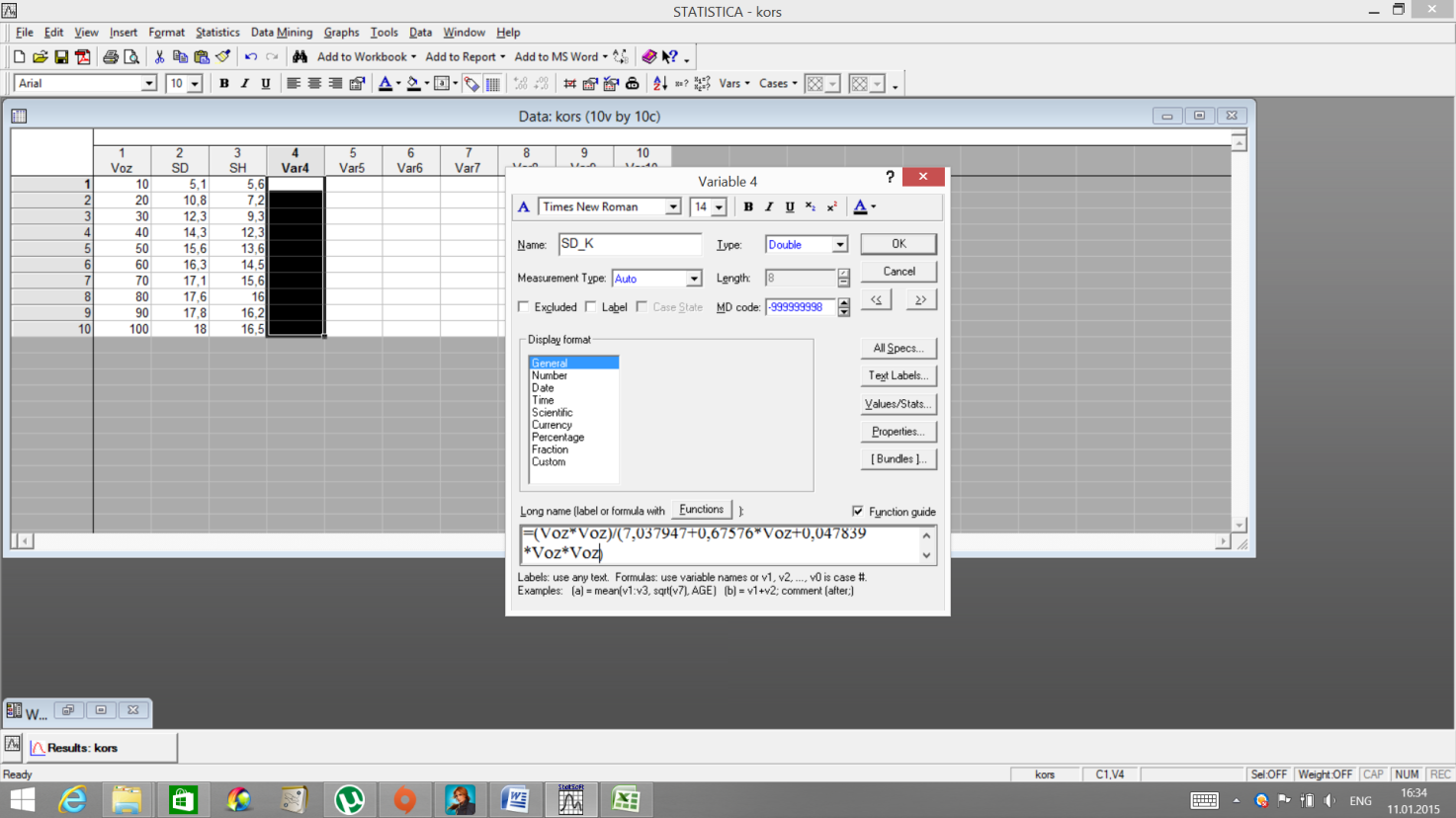
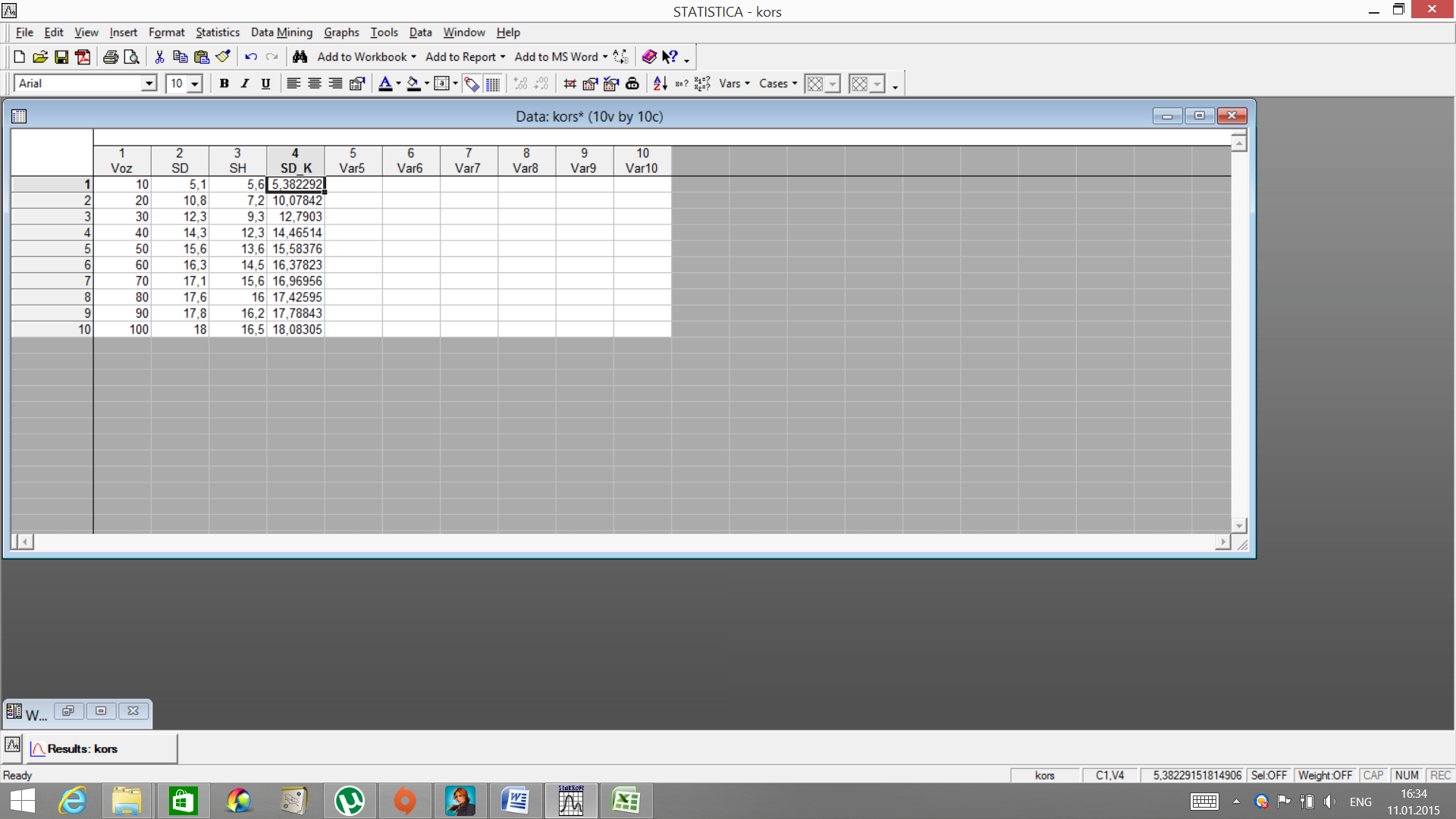
В пакете Statistica имеется возможность протабулировать, используя полученную формулу. Для этого нажмите два раза мышью на заголовок нового столбца. Введите название, в нижней части окна введите формулупо которой рассчитывается данная переменная SD=(Voz*Voz)/(7, 037947+0, 67576*Voz+0, 047839*Voz*Voz). ОК.
Получается следующий результат.
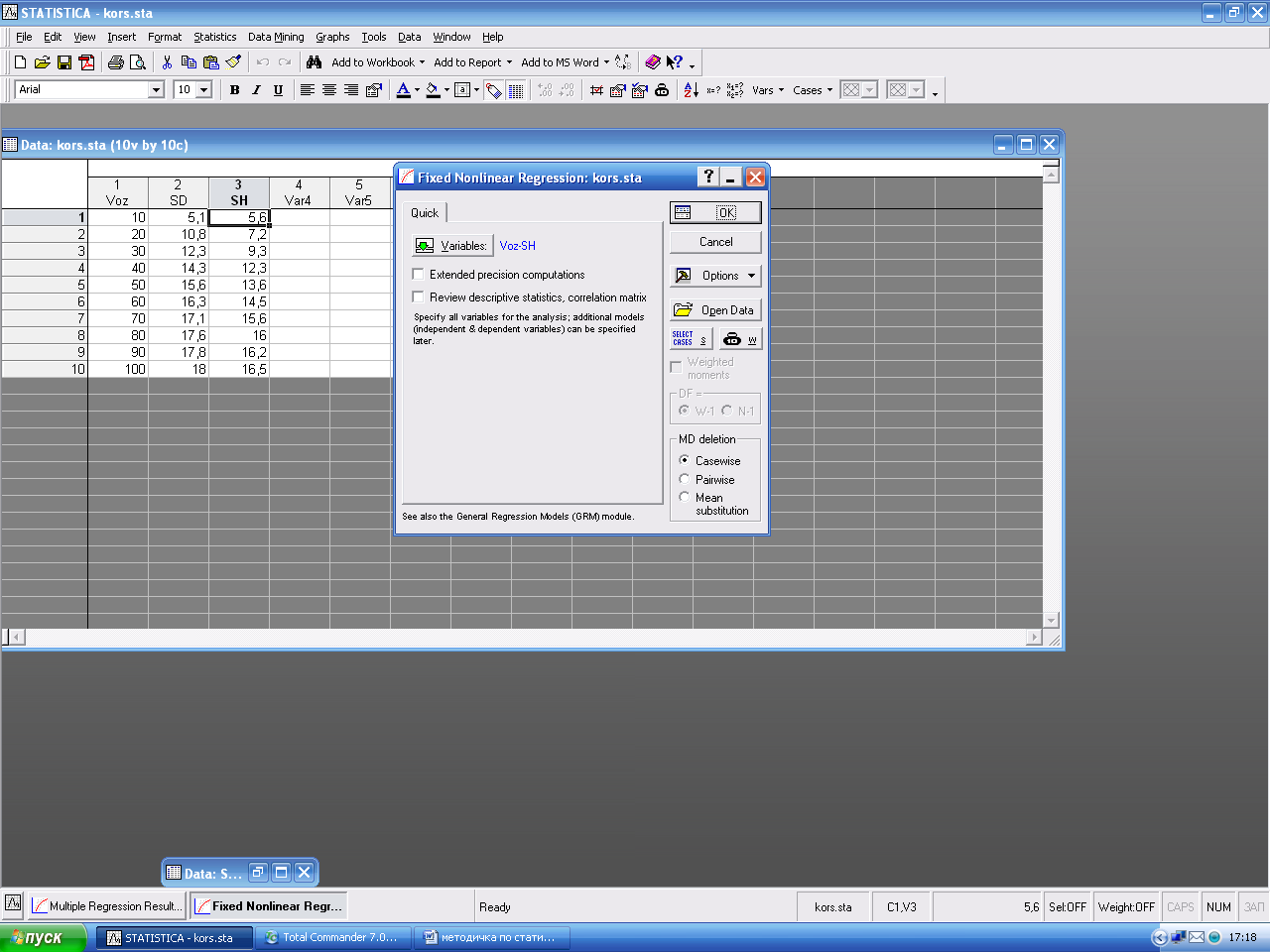
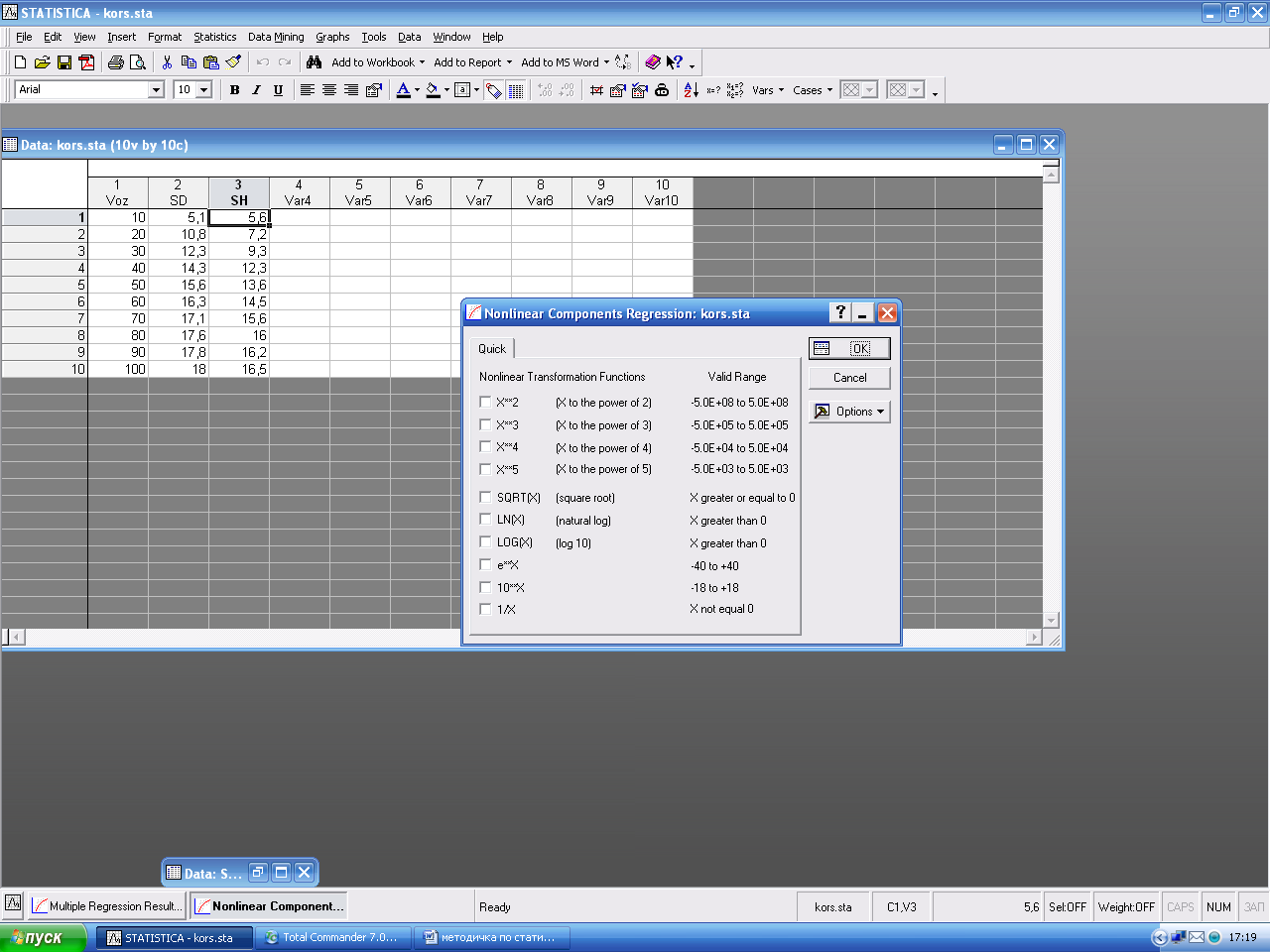
1.1. Проведение полиноминального регрессионного анализа: Вызовите Statistics-Aavansed Linear/Nonlinear Models/Fixed Nonlinear Regression. Появится окно Fixed Nonlinear Regression, в котором необходимо ввести переменные.
В окне определяется вид преобразования переменной.
Вид нелинейных преобразований регрессии:
ОК. Появляется окно для отбора зависимой и независимой переменных.
ОК. ОК. Далее анализ аналогичен парному и множественному регрессионному анализу. В верхней части окна приводятся параметры полученной регрессионной модели:
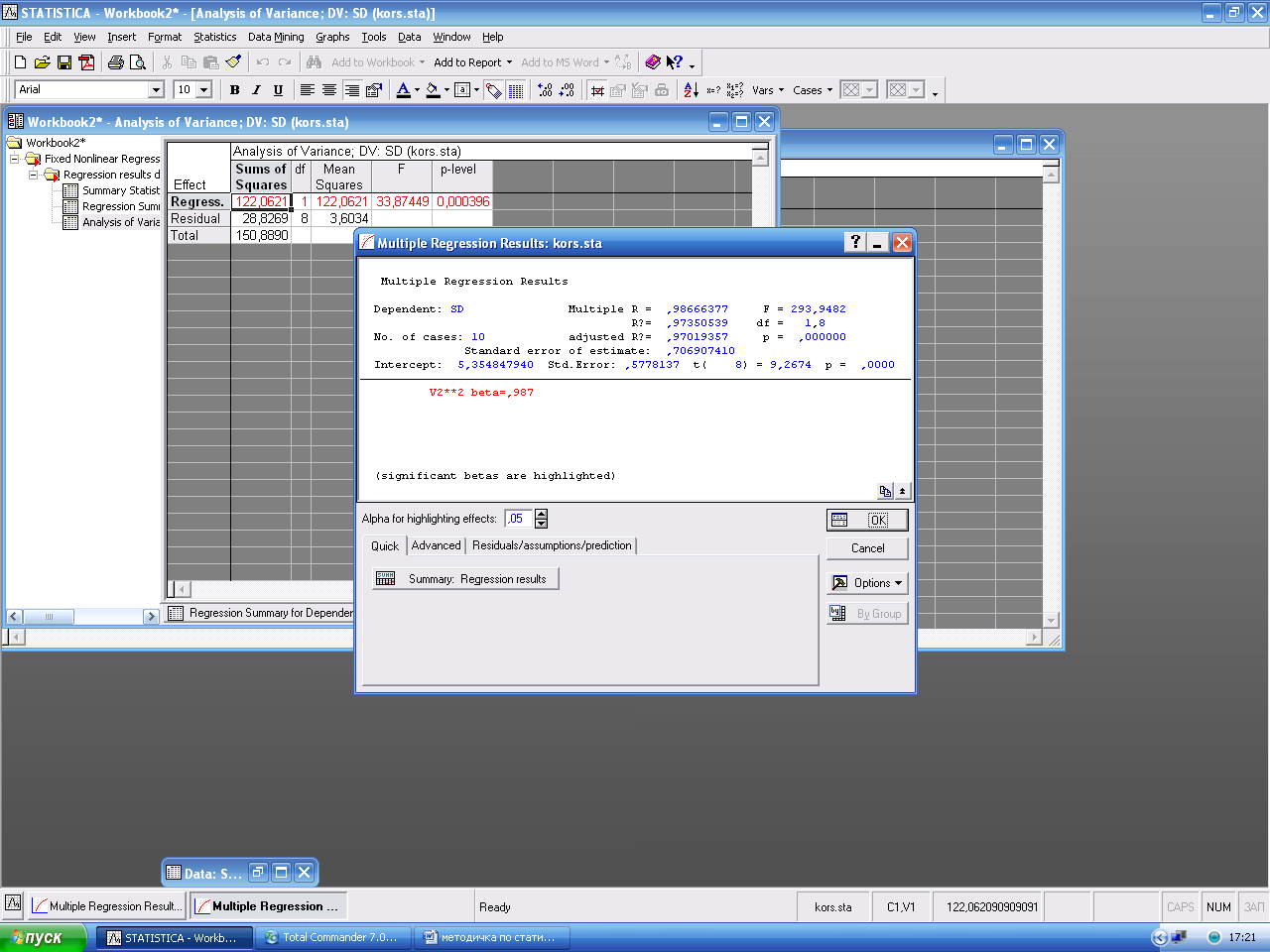
Кнопка Regression summary results позволяет просмотреть основные результаты регрессионного анализа.
Столбец BETA -; В - коэффициенты уравнения регрессии; St. Err. of B - стандартные ошибки коэффициентов уравнения регрессии; t - t-критерии для коэффициентов уравнения регрессии; р-level - вероятность нулевой гипотезы для коэффициентов уравнения регрессии. Уравнение регрессии имеет вид: V= 5, 354848+0, 040592*SD2.
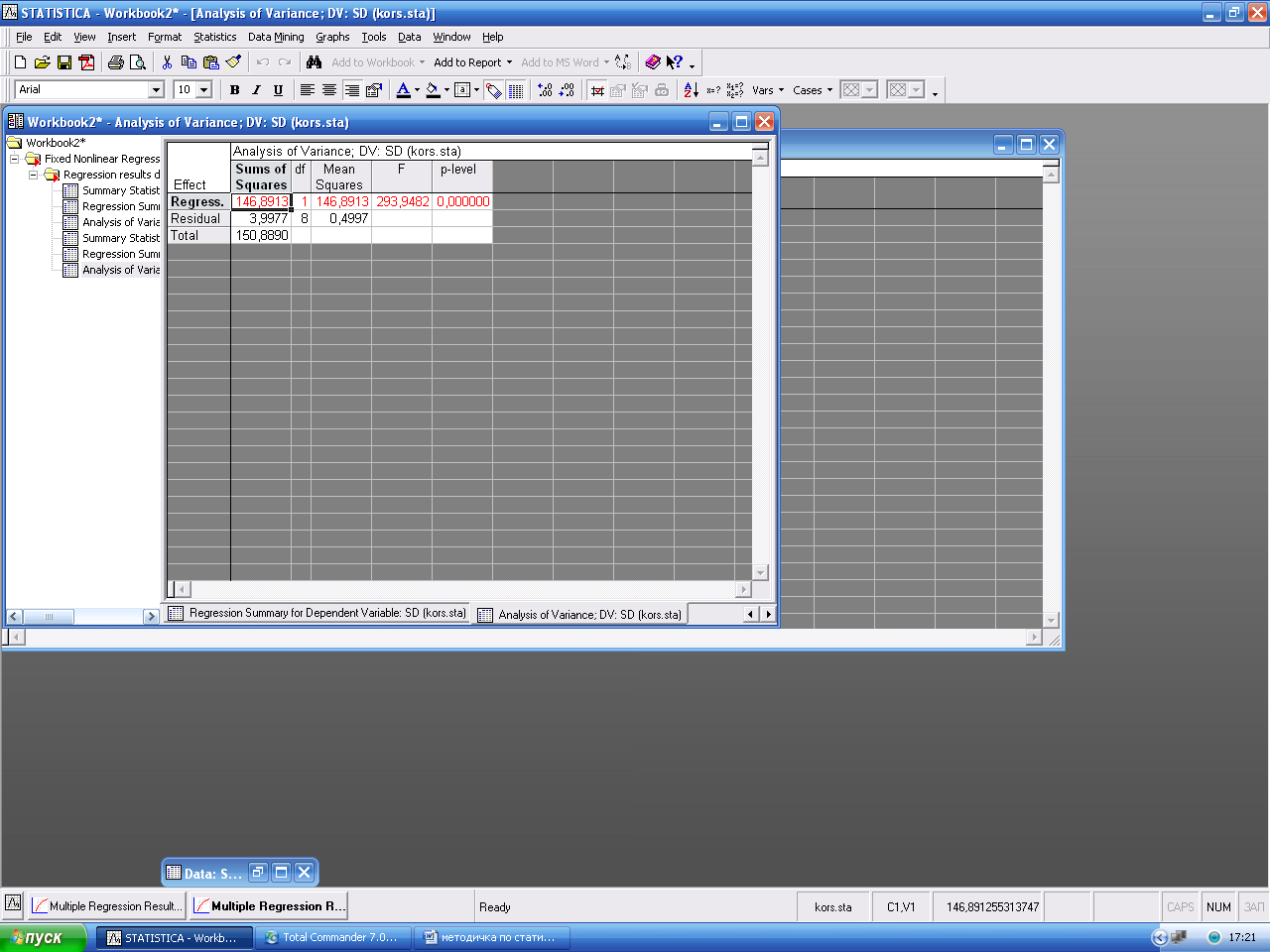
Кнопка Anova (Overal goodness of fit) открывает окно с данными дисперсионного анализ Analysis of variance - позволяет ознакомиться с результатами дисперсионного анализа уравнения регрессии.
1.2. Проведение множественного регрессионного анализа: Выбираем модуль MultipleRegressions.
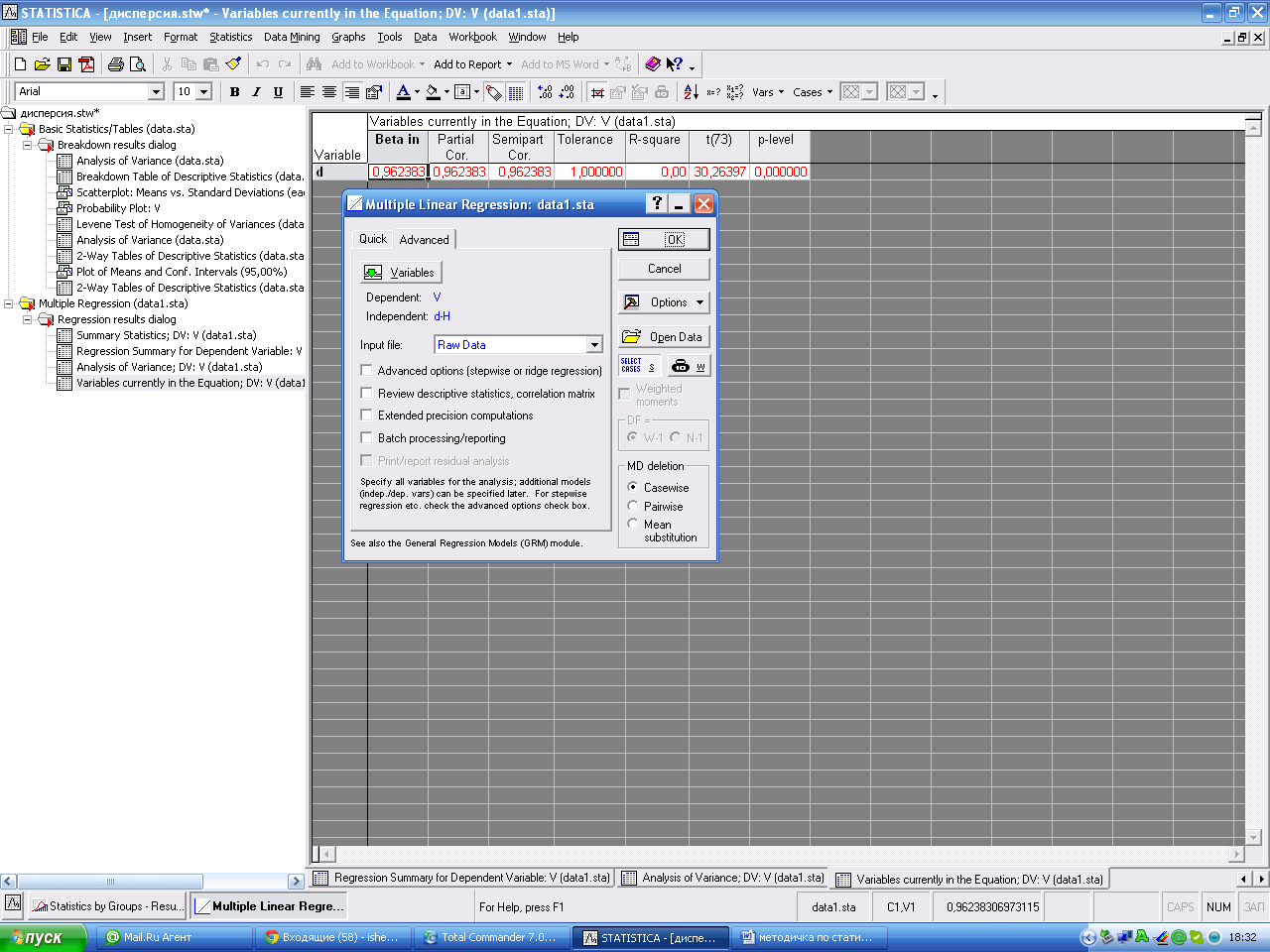
При помощи кнопки Variables указываются независимые (ая) (independent) и зависимая (dependent) переменные. В поле Input file указывается тип файла с данными в виде: Raw Date - данные в виде строчной таблицы; или Correlarion Matrix - корреляционной матрицы
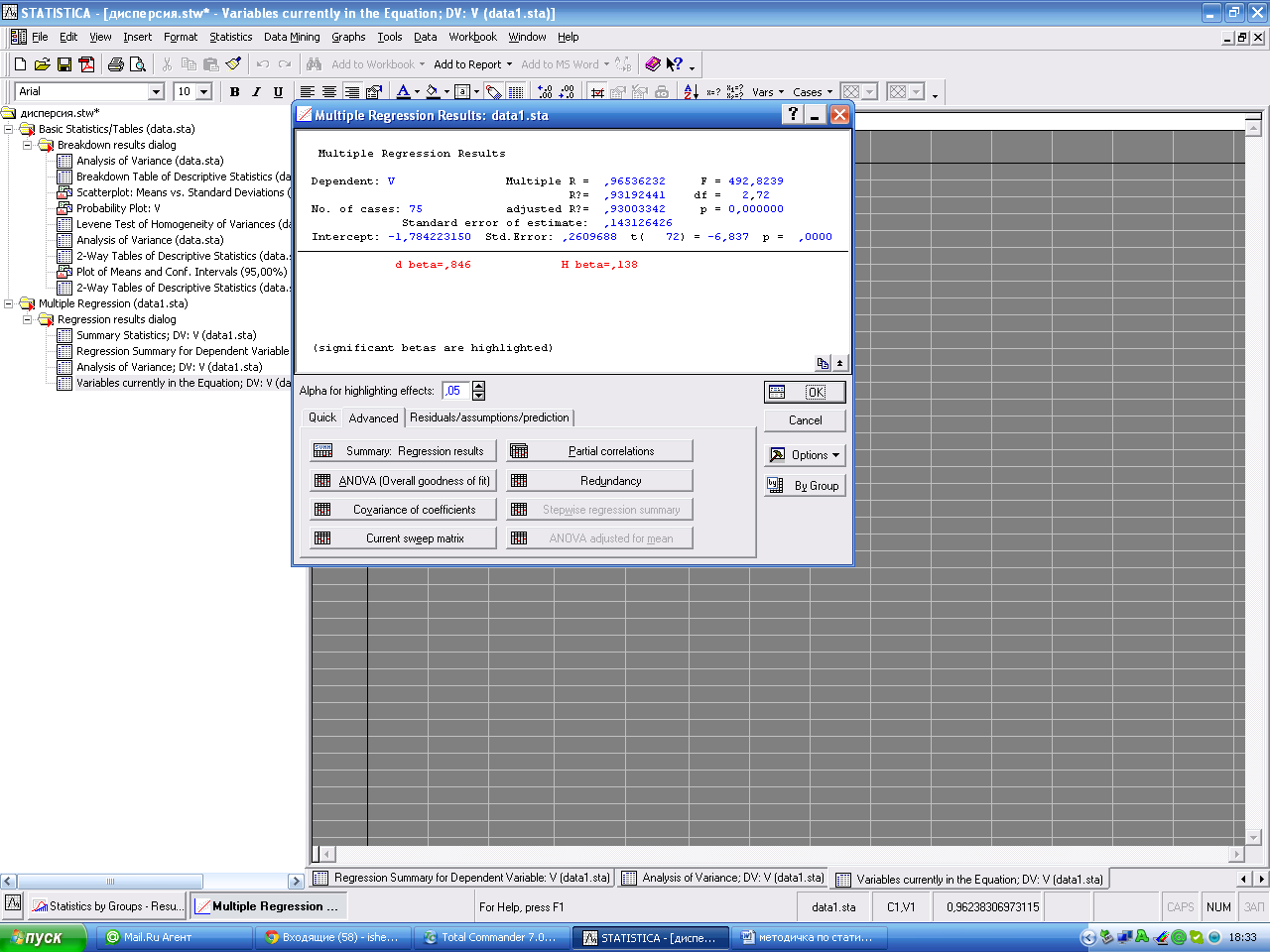
Нажмите «ОК», в результате выводится окно с данными по регрессионному анализу.
В верхней части окна приводятся параметры полученной регрессионной модели:
Multiple R - характеризует тесноту линейной связи между зависимой и всеми независимыми переменными. Может принимать значения от 0 до 1. R2 - численно выражает долю вариации зависимой переменной, объясненную с помощью регрессионного уравнения. Чем больше R2, тем большую долю вариации объясняют переменные, включенные в модель. Включение новой переменной в регрессионное уравнение увеличивает R не всегда, а только в том случае, когда частный F-критерий при проверке гипотезы о значимости включаемой переменной больше или равен 1. В противном случае включение новой переменной уменьшает значение R и adjusted R2. adjusted R2 - cкорректированный R2 можно с большим успехом (по сравнению с R2) применять для выбора наилучшего подмножества независимых переменных в регрессионном уравнении.
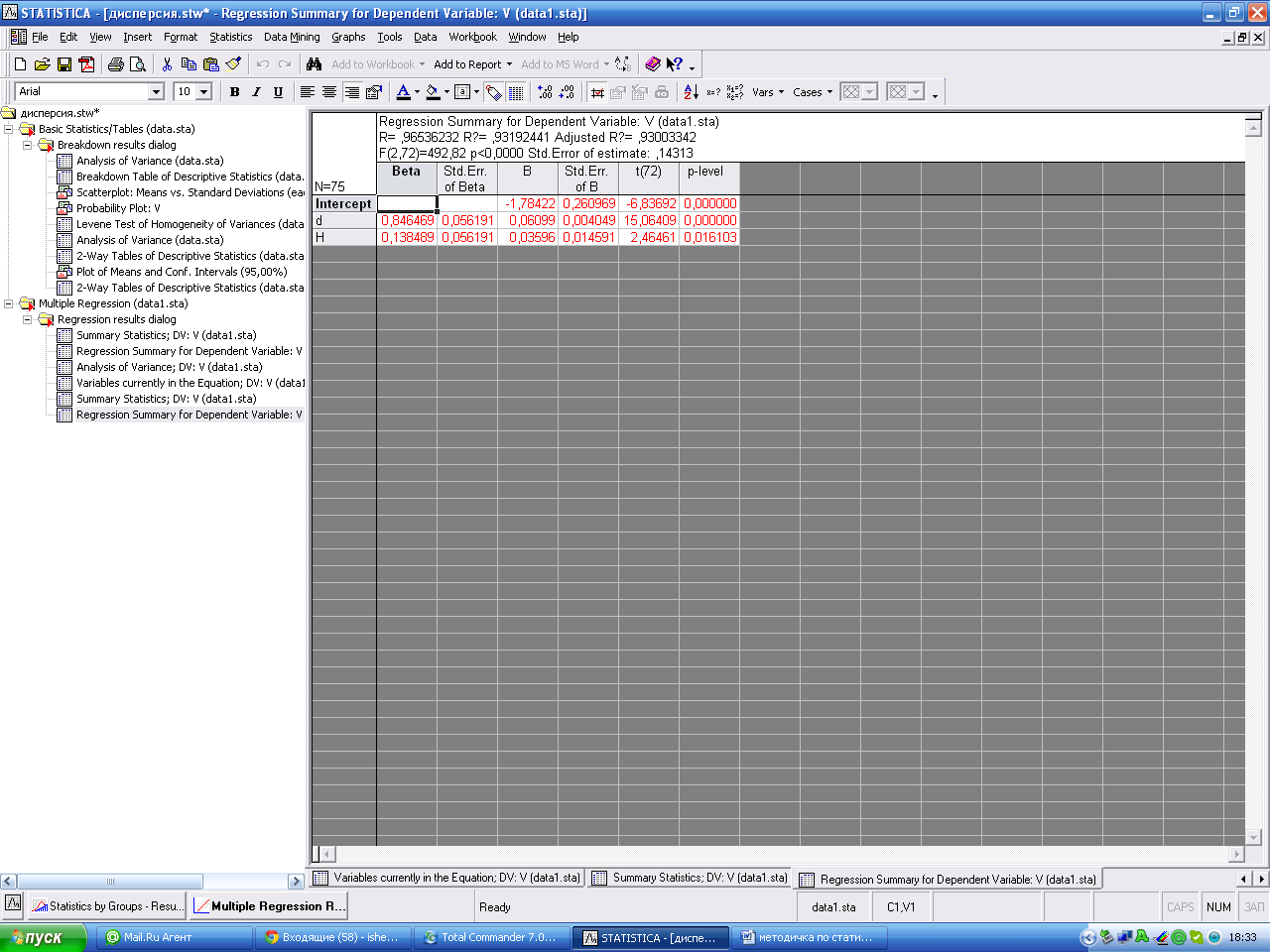
Кнопка Regression summary results позволяет просмотреть основные результаты регрессионного анализа.
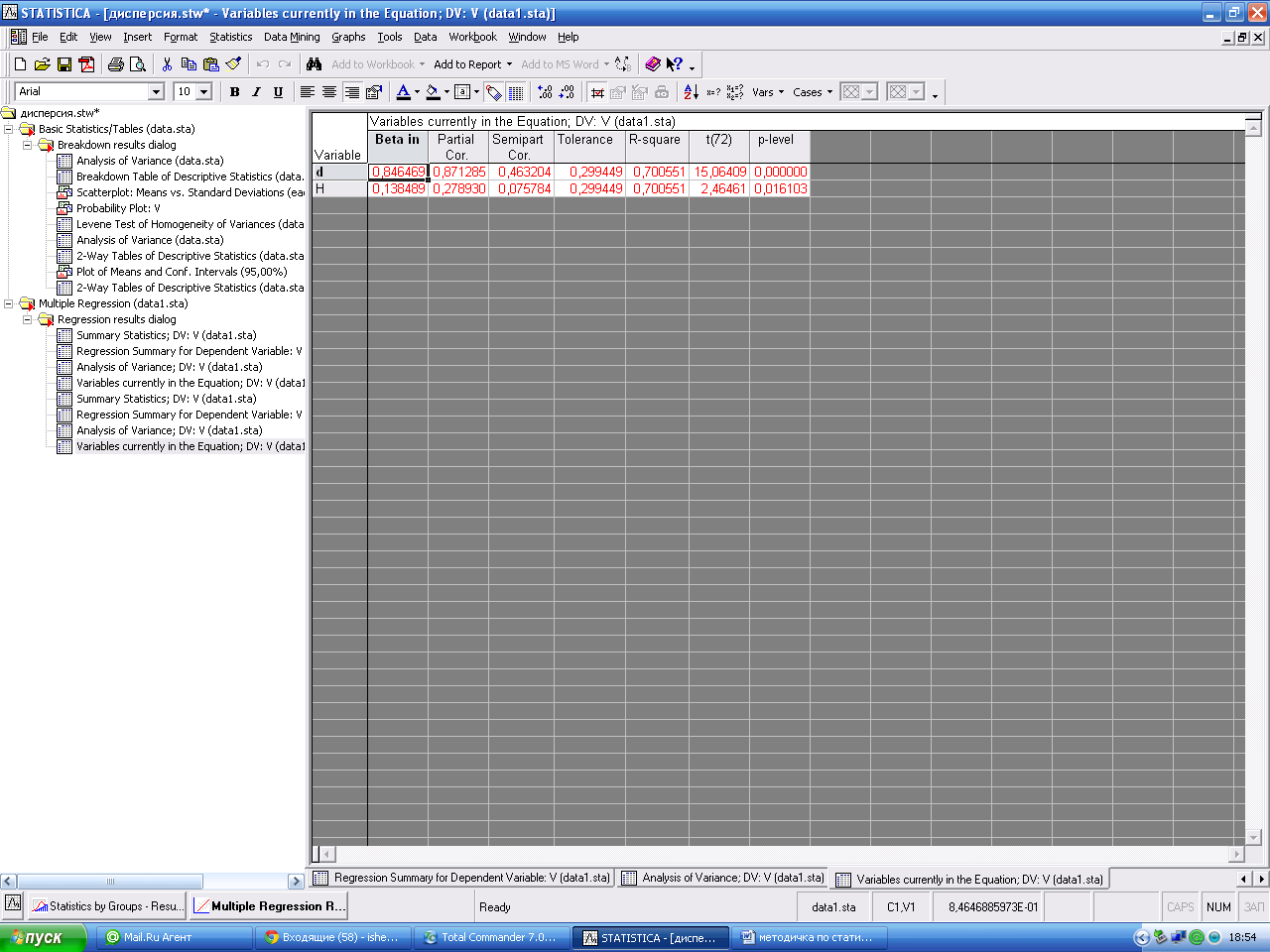
Столбец BETA -; В - коэффициенты уравнения регрессии; St. Err. of B - стандартные ошибки коэффициентов уравнения регрессии; t - t-критерии для коэффициентов уравнения регрессии; р-level - вероятность нулевой гипотезы для коэффициентов уравнения регрессии. Уравнение регрессии имеет вид: V= -1, 78422+0, 06099*D+0, 03596*H.
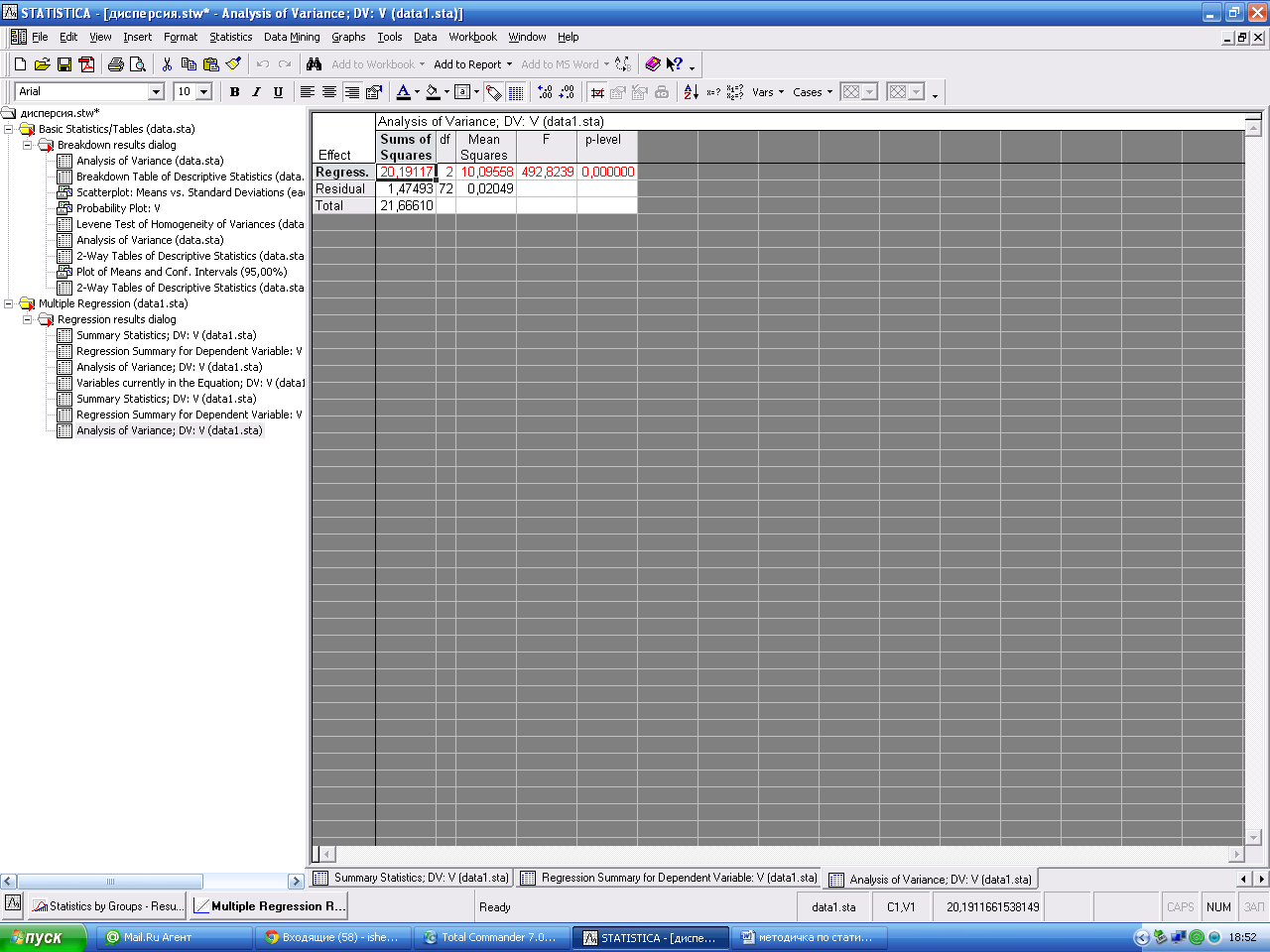
Кнопка Anova (Overalgoodnessoffit) открывает окно с данными дисперсионного анализ Analysisofvariance - позволяет ознакомиться с результатами дисперсионного анализа уравнения регрессии.
В строках таблицы дисперсионного анализа уравнения регрессии - источники вариации: Regress. - обусловленная регрессией, Residual - остаточная, Total - общая. В столбцах таблицы: Sums of Squares –сумма квадратов, df - число степеней свободы, MeanSquares - средний квадрат, F - значение F – критерия (критерия Фишера), p-level - вероятность нулевой гипотезы для F - критерия.
Вывод: F - критерий полученного уравнения регрессии сравнить с критерием Фишера табличным и сделать вывод.
Вероятность нулевой гипотезы (p-level) значительно меньше 0, 05, что говорит об общей значимости уравнения регрессии.
Кнопка Partialcorrelations –вызывает окно с частными коэффициентами корреляции ( PartialCor.) между исследуемыми переменными Частная корреляция - это корреляция между двумя переменными, когда одна или больше из оставшихся переменных удерживаются на постоянном уровне (т.е. имеют постоянное значение). Частные коэффициенты корреляции, как и парные, могут принимать значения от -1 до +1.
Кнопка Predict dependent variable (на закладке Residual…) - позволяет рассчитать по полученному регрессионному уравнению значение зависимой переменной по значениям независимых переменных. На рисунке приводится пример расчета запаса при величине диаметра ствола - 20 см и высоты - 20 м. Предсказанный (Predicted) запас составил 0, 15478м3.
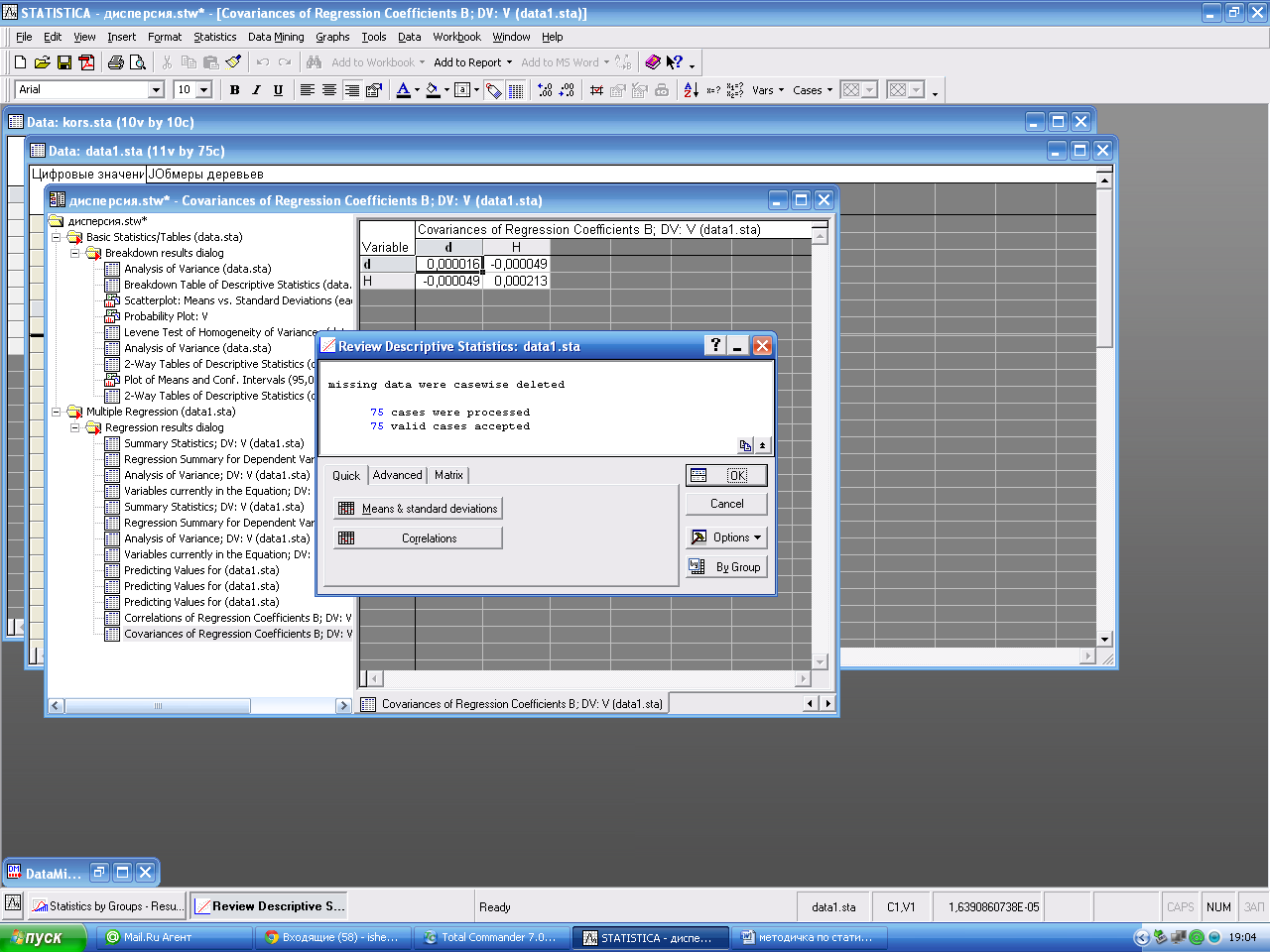
Кнопка Descriptivestatistics позволяет просмотреть описательные статистики и корреляционную матрицу с парными коэффициентами корреляции переменных, которые участвующих в регрессионной модели
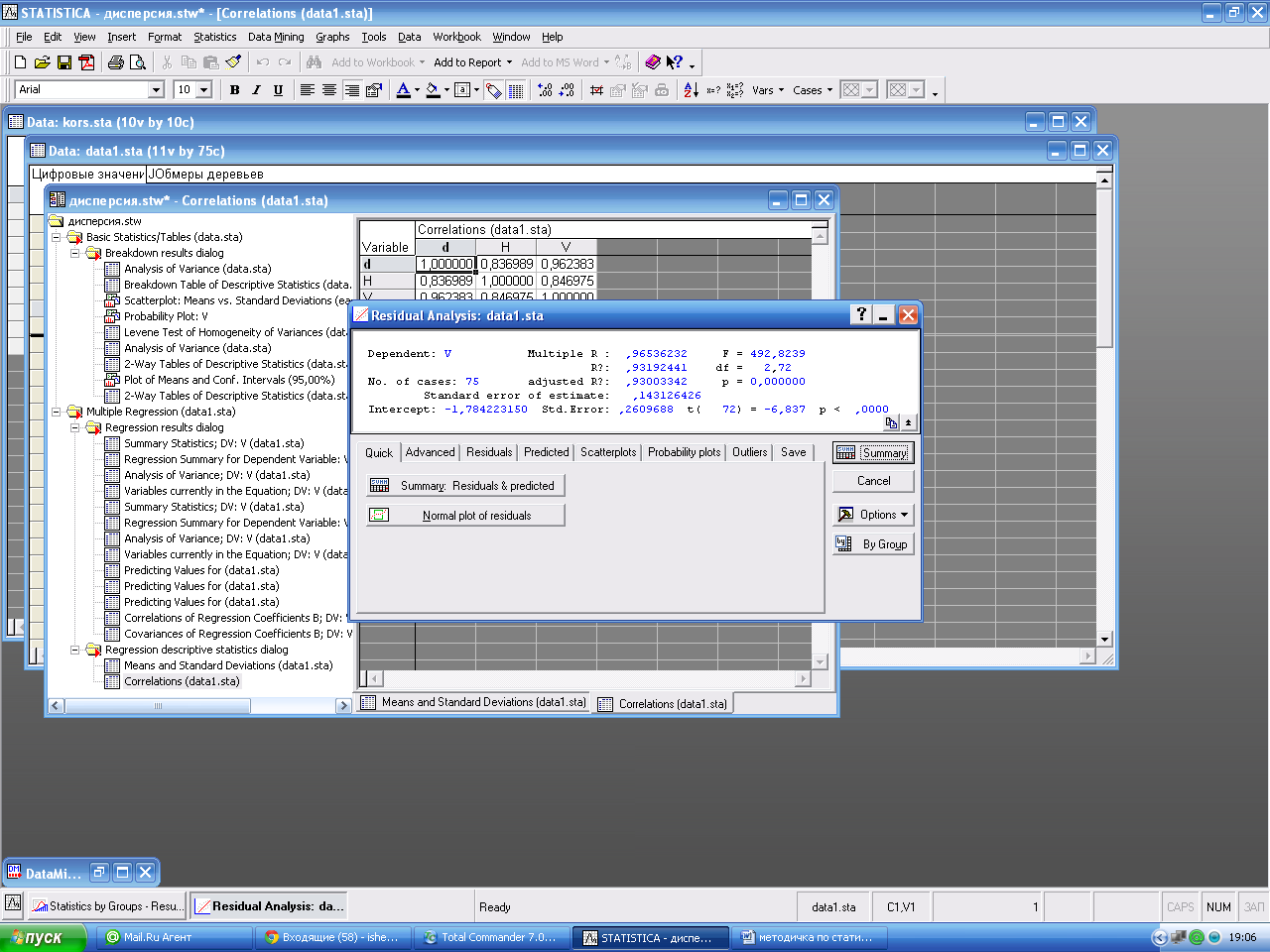
Кнопка PerfomResidualanalysis вызывает процедуру всестороннего анализа остатков регрессионного уравнения. Остатки - это разности между опытными и предсказанными значениями зависимой переменной в построенной регрессионной модели.
Нажав кнопку Summary: Residual& predicted появляется окно с наблюдаемыми (Observed) и предсказанными (Predicted) значениями зависимой переменной. А также остатков (Residual).
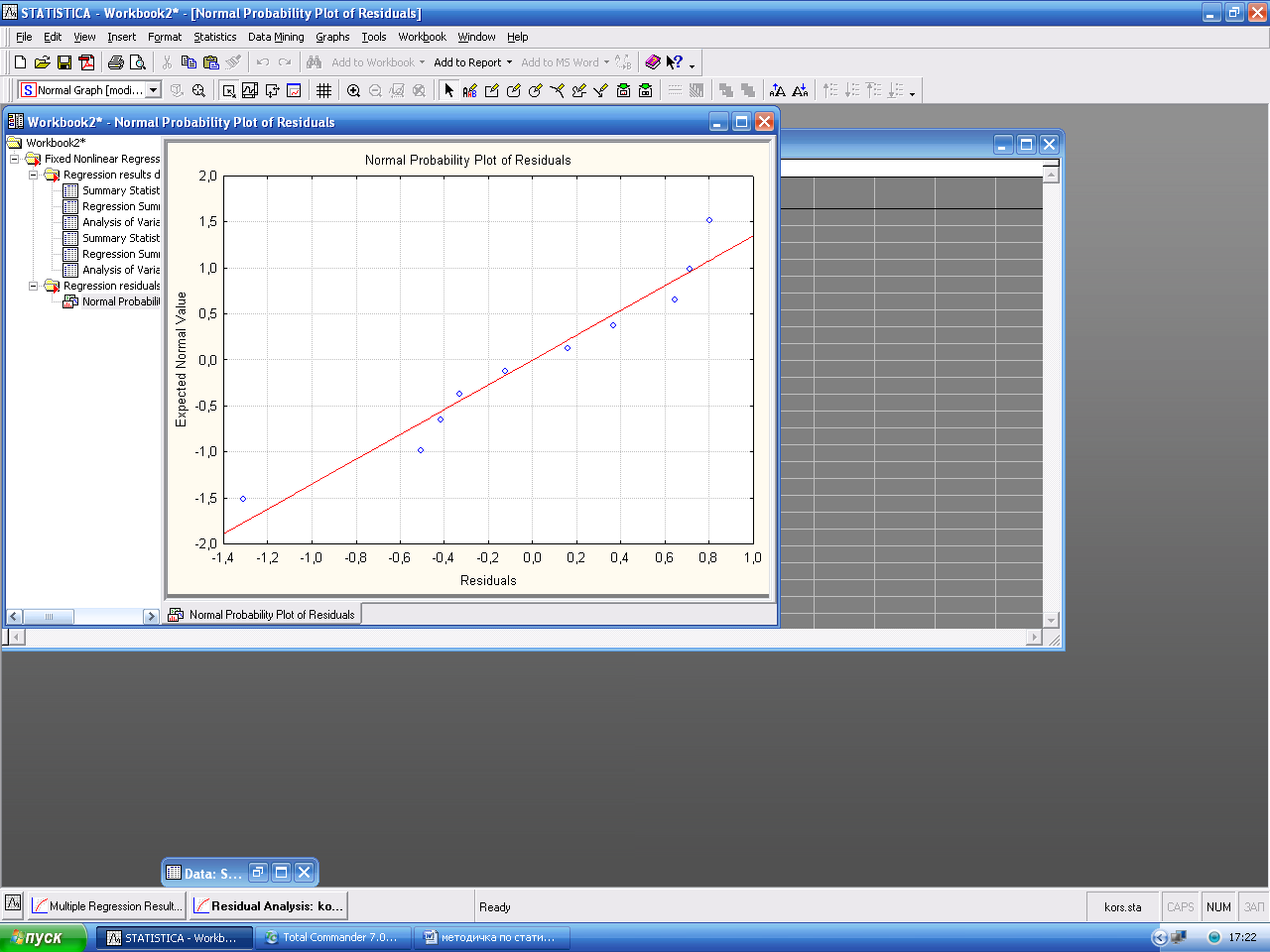
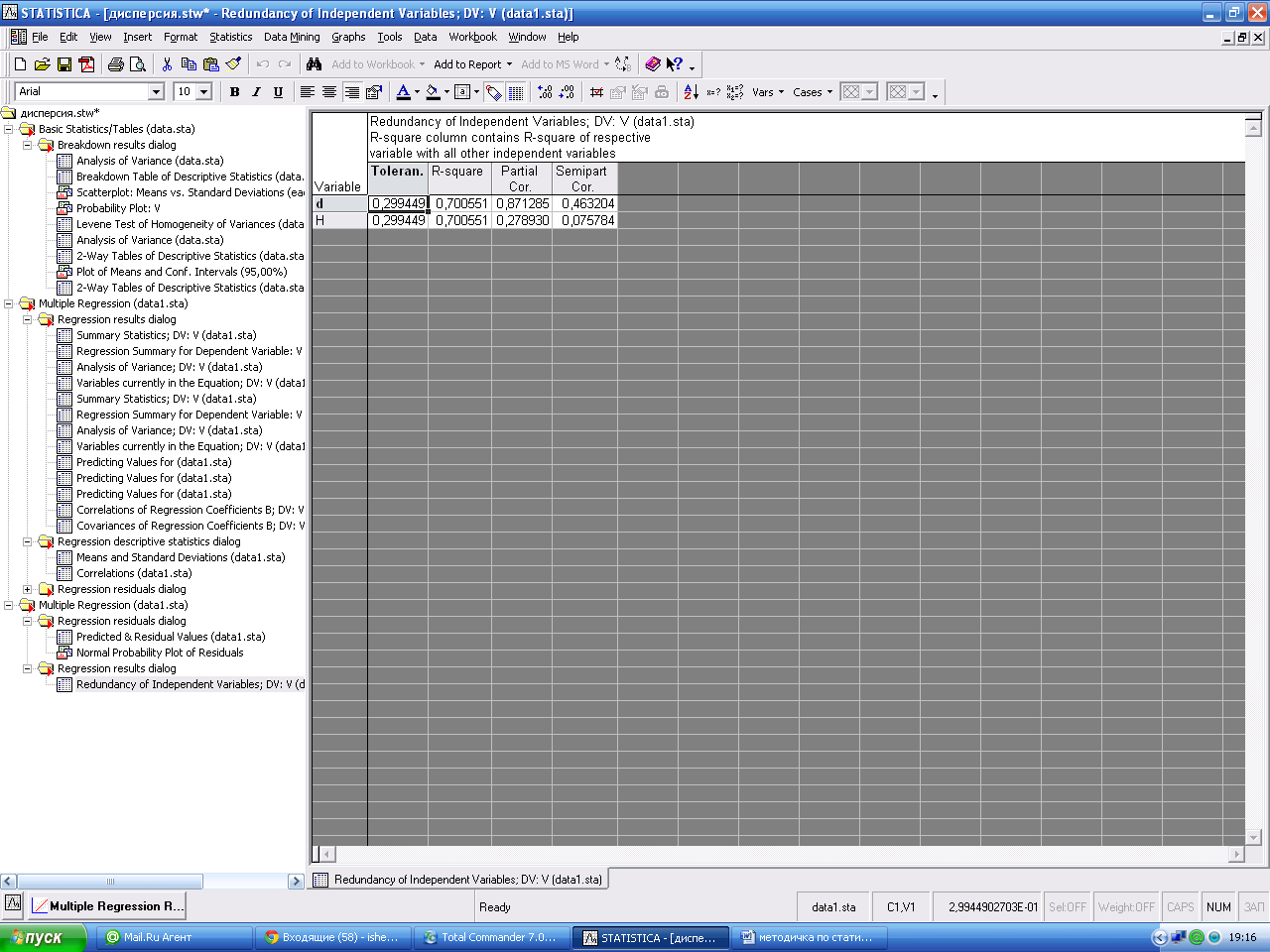
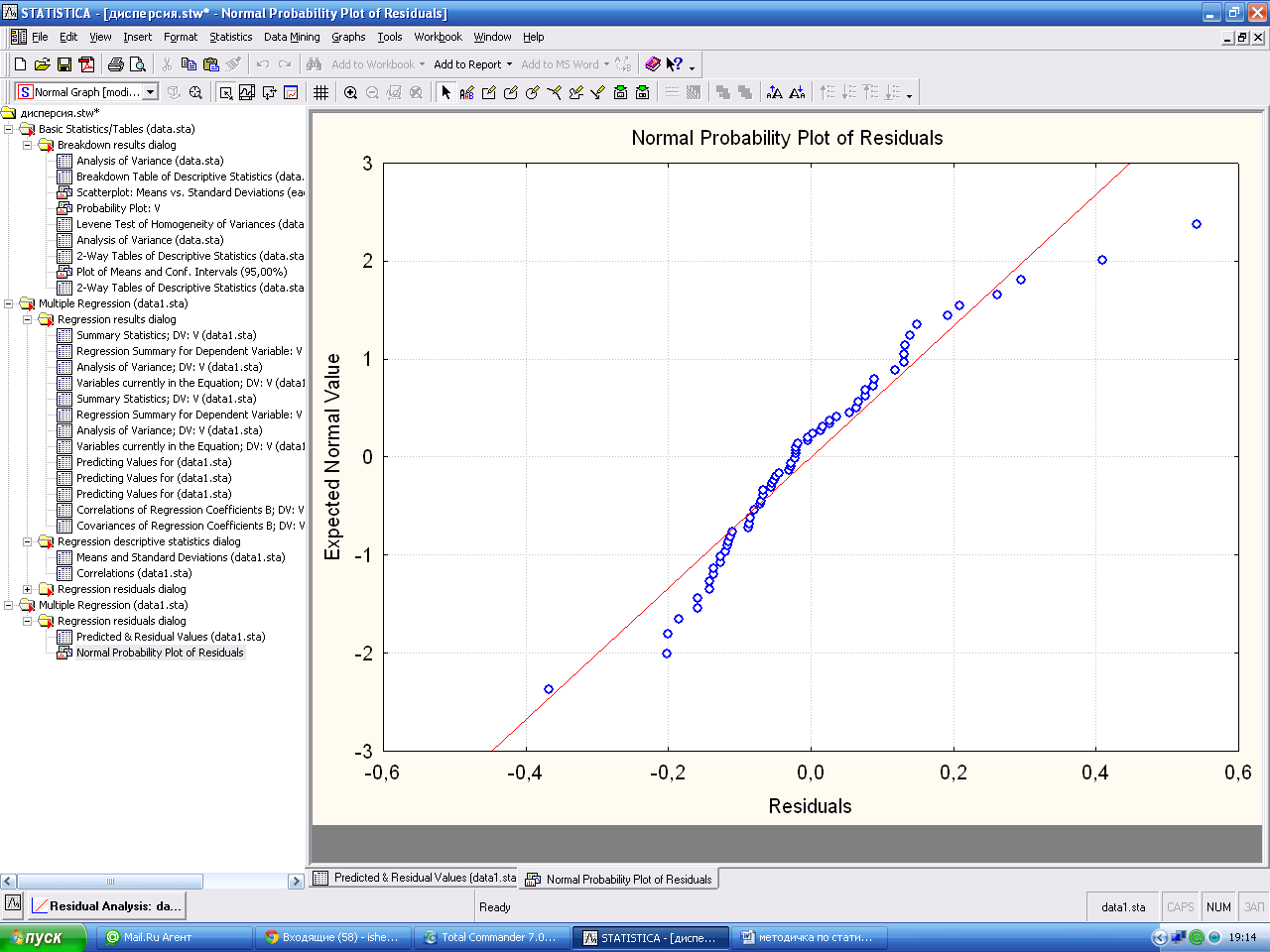
Кнопка Redundancy предназначена для поиска выбросов. Выбросы - это остатки, которые значительно превосходят по абсолютной величине остальные. Выбросы показывают опытные данные, которые являются не типичными по отношению к остальным данным, и требует выяснения причин их возникновения. Выбросы должны исключаться из обработки, если они вызваны ошибками регистрации, измерения. О нормальности остатков можно судить по графику остатков на нормальной вероятностной бумаге. Чем ближе распределение к нормальному виду, тем лучше значения остатков ложатся на прямую линию. Он строится при помощи кнопки Normal plot of resids. окна Residual analysis.
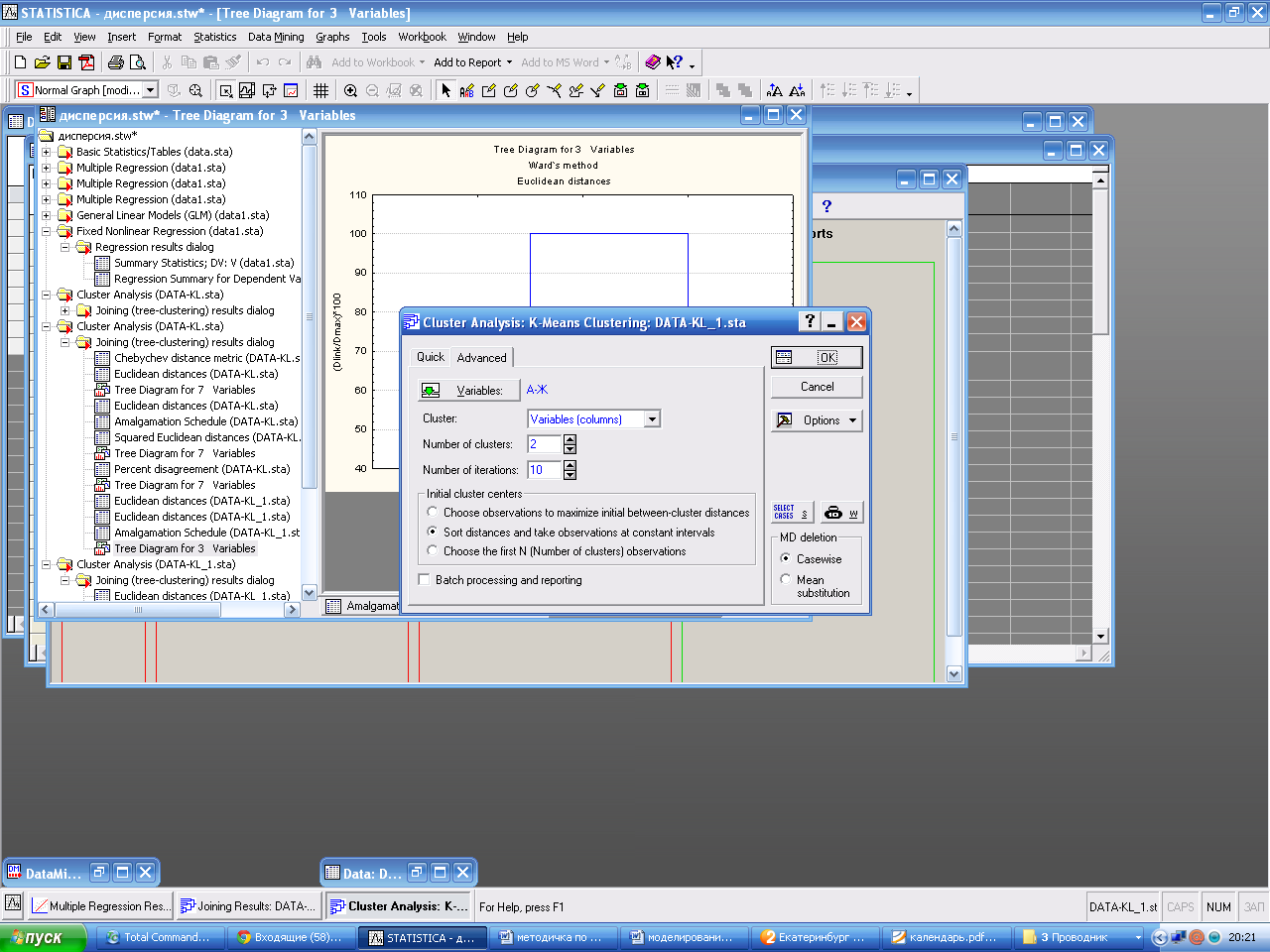
Кластерный Цель анализа – Методы кластерного анализа: Иерархические - группа методов характеризуется последовательным объединением исходных элементов и соответствующим уменьшением числа кластеров. агломеративные - первоначально все объекты являются отдельными кластерами. На первом шаге наиболее похожие объекты объединяются в кластер. На последующих шагах объединение продолжается до тех пор, пока все объекты не будут составлять один кластер; и итеративные – сначала все объекты принадлежат одному кластеру, который на последующих шагах делится на меньшие кластеры, в результате образуется последовательность расщепляющих групп. Запустите анализ, выбрав в меню Statistics (Анализ) -MultivariateExploraryTechniques (Многомерные разведочные анализы) - ClusterAnalysis (Кластерный анализ). Выберите метод кластеризации: Joining (treeclustering) – дендрограммы K-meansclustering - кластеризация методом k-средних. 1. Иерархическая кластеризация - Joining (treeclustering) – дендрограммы.
Появится окно для настроек анализа. Выберите закладку Advanced (Дополнительно).
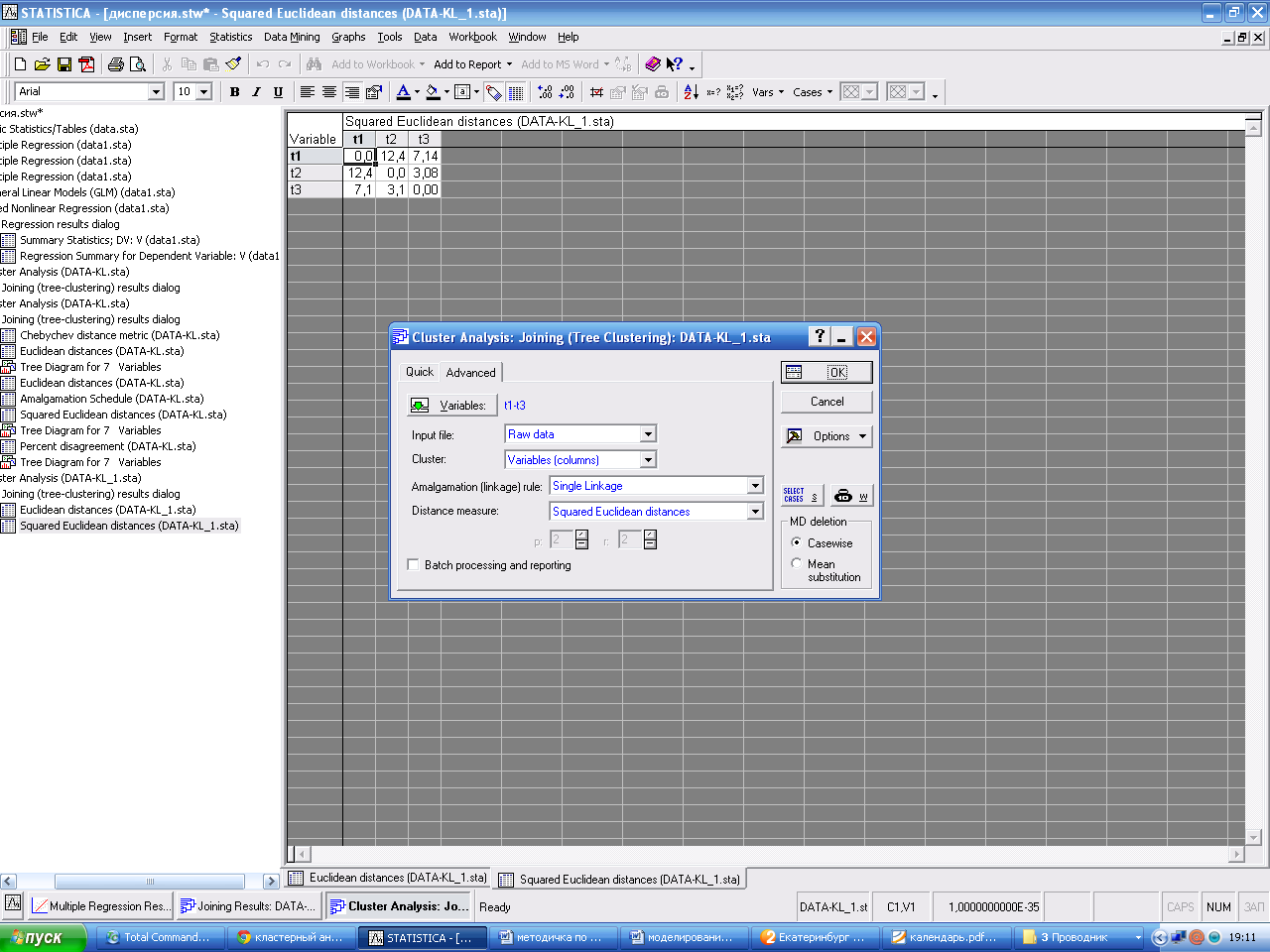
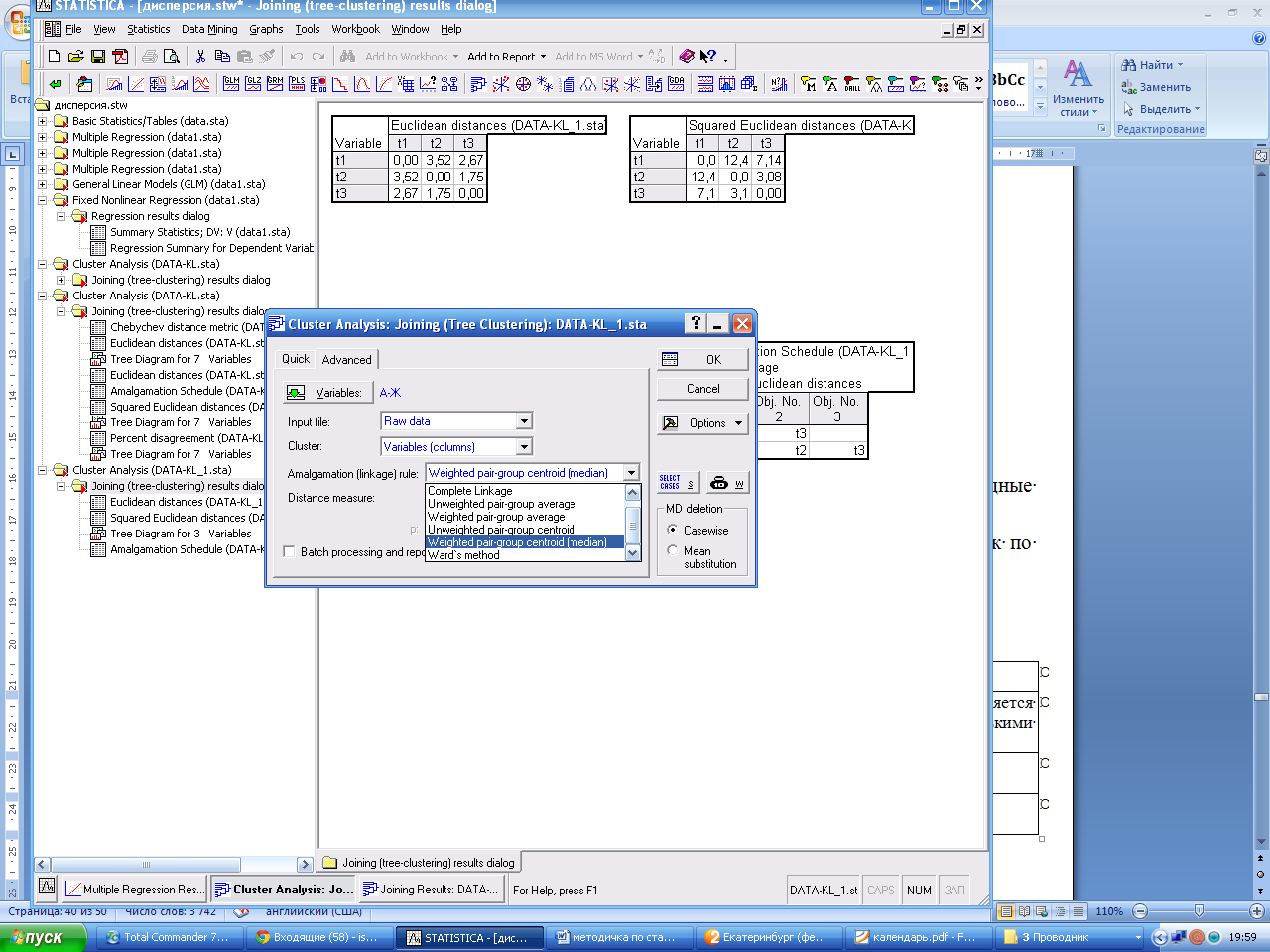
Выберите: · Variables (переменные), по которым проводится анализ; · Inputfile (Файл данных) – файл может содержать как исходные данные, так и матрицы расстояний; · Cluster (Объект) – исходные данные могут располагаться как по строкам (Cases (rows)), так и в столбцах (Variables (Columns)); · Amalgamation-linkage rule (правило объединения); · Distance measure (мера близости). ·
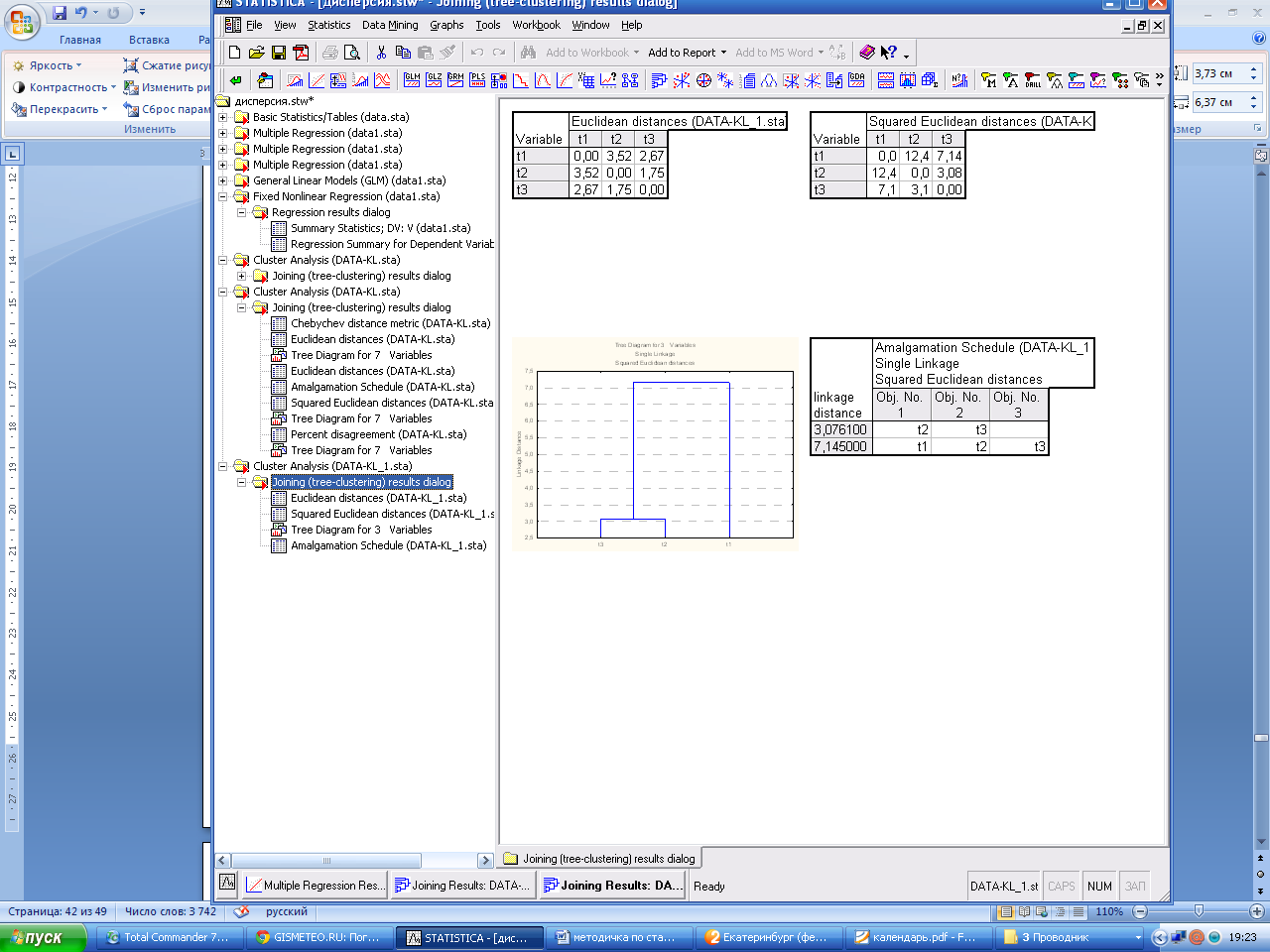
Выберите первоначально: правило объединения - метод одиночной связи (ближайшего соседа) и мера близости - Евклидово расстояние. Задав установки, нажмите ОК. Появляется окно с общей информацией о выбранных ранее условиях. Для продолжения анализа в нижнем левом углу программы нажмите на панель анализа Joiningresults. Перейдите на закладку дополнительно (Advanced)
Нажмите кнопку Distance matrix(Матрица расстояний).Появится окно с рассчитанной матрицей расстояний.
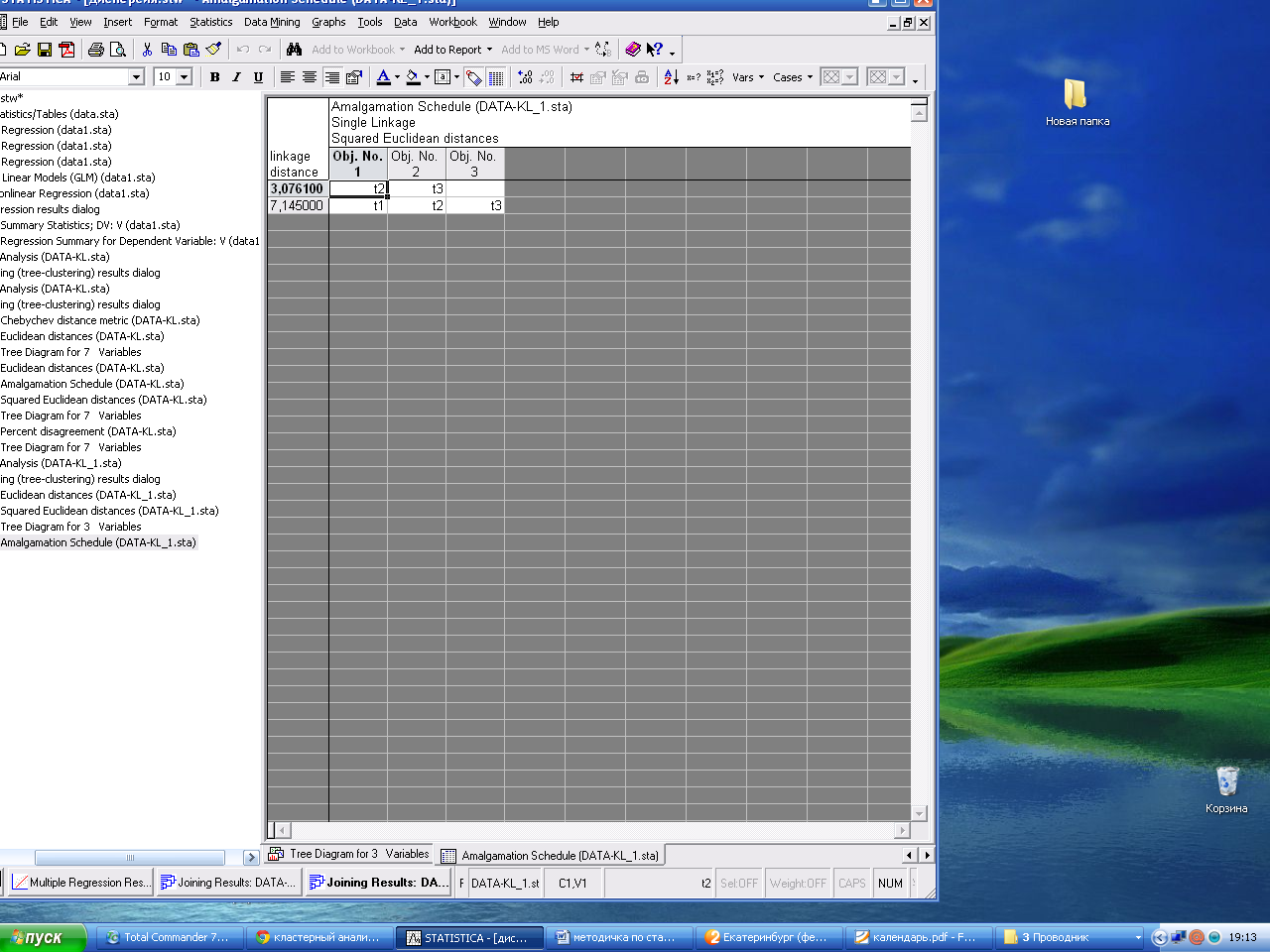
Нажатие по клавишам Horizontal hierar chical tree plot (горизонтальная дендрограмма) или Vertical icical tree plot (вертикальная дендрограмма) позволяет построить нужный график. Порядок объединения можно увидеть в виде таблице в окне Amalgamation Schedule (Схема объединения).
А также график схемы объединения (Graph of Amalgamation Schedule) и описательные статистики (Descriptive statistics).
Метод k-средних.
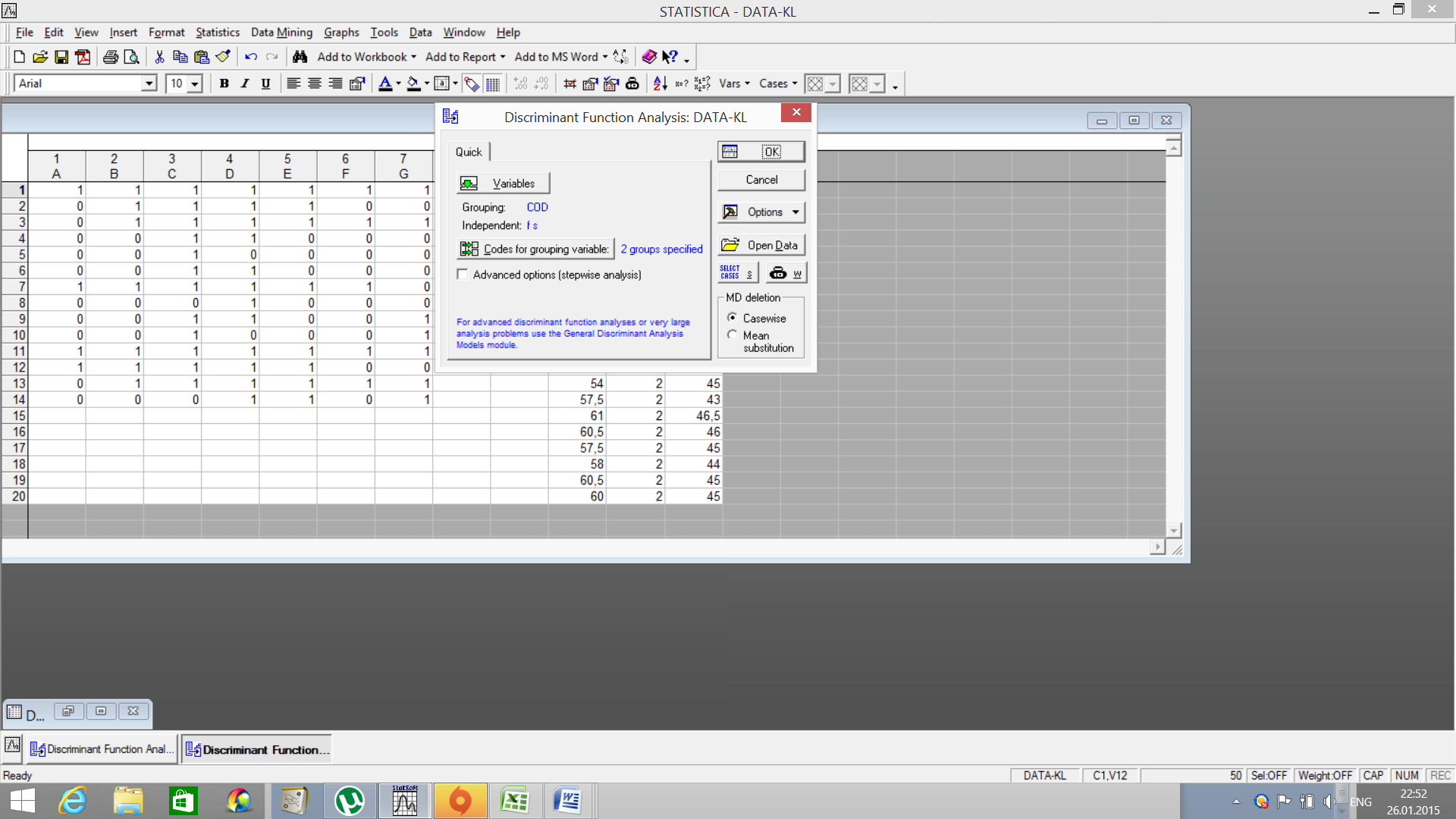
Дискриминантный анализ Запуститеанализ, выбраввменю Statistics (Анализ) -Multivariate Explorary Techniques (Многомерныеразведочныеанализы) - Discriminant Analysis (Дискриминантныйанализ). В окне настройки анализа введите следующую информацию: Variables (Переменные) – переменные двух видов – группирующую (Grouping) и Independent (Независимые). Группирующую (Grouping) – это группирующий признак, в нашем примере пол особи – 1- самец, 2 –самка. Independent (Независимые) – это переменные по которым рассчитывается дискриминантная функция.
Для отнесения переменной к той или иной группе введите коды, использованные для обозначения групп в поле Codesforgroupingvariable (Коды для группирующей переменной). ОК. Откроется окно Discriminant Function Analysis (Общие данные по Дискриминантному анализу).
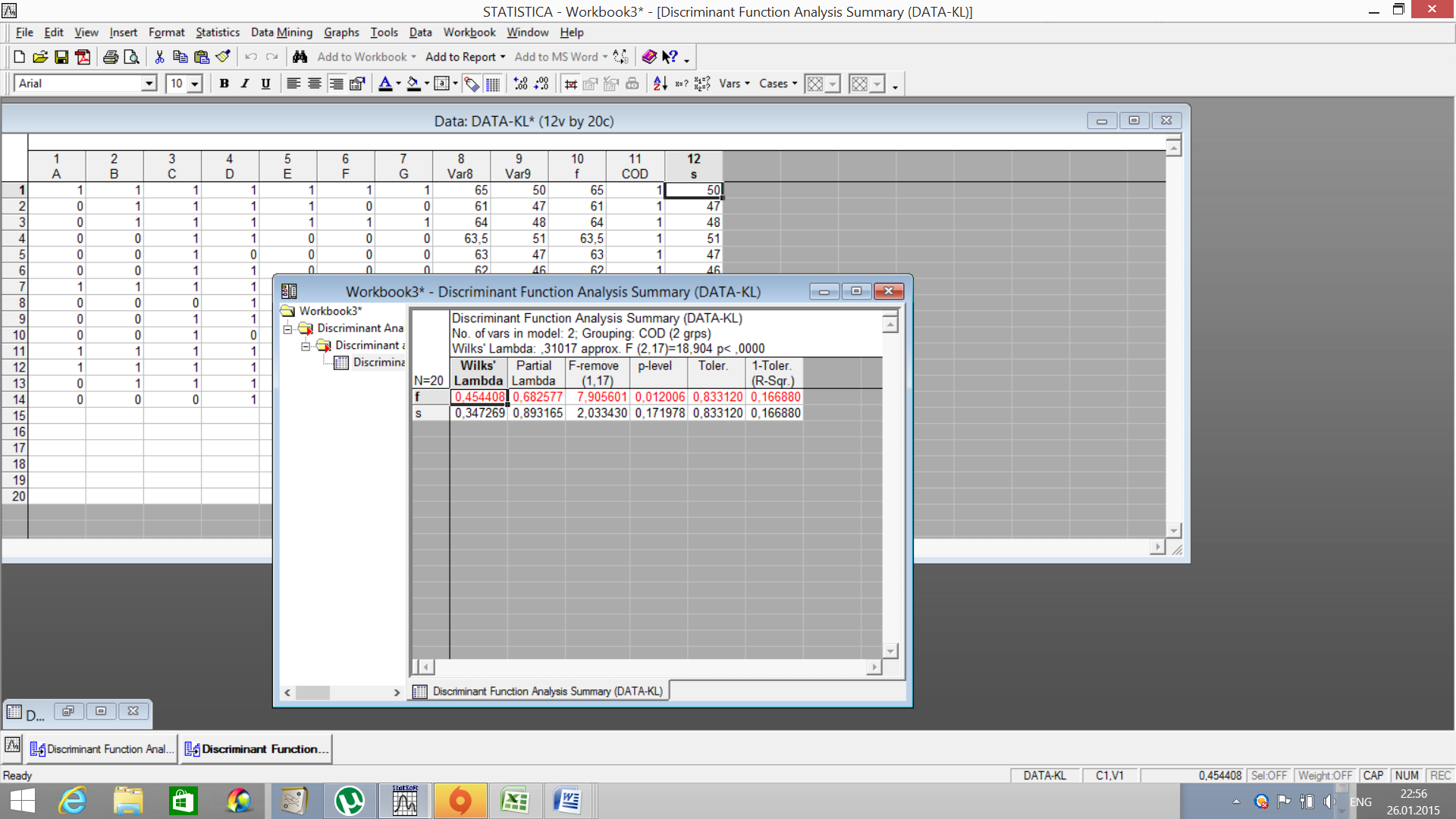
Анализируем статистику лямбда Уилкса (WilksLambda), которая используется для оценки дискриминации в данной модели. Значение статистики изменяется от 0 до 1. Если значение лямбда Уилкса равно 0, 0 – это полная дискриминация, если 1, 0 – нет дискриминации. В нашем примере значение лямбда Уилкса равно 0, 31, дискриминация присутствует. Нажмите на клавишу Summary: Variablesinmodel (Переменные в модели).
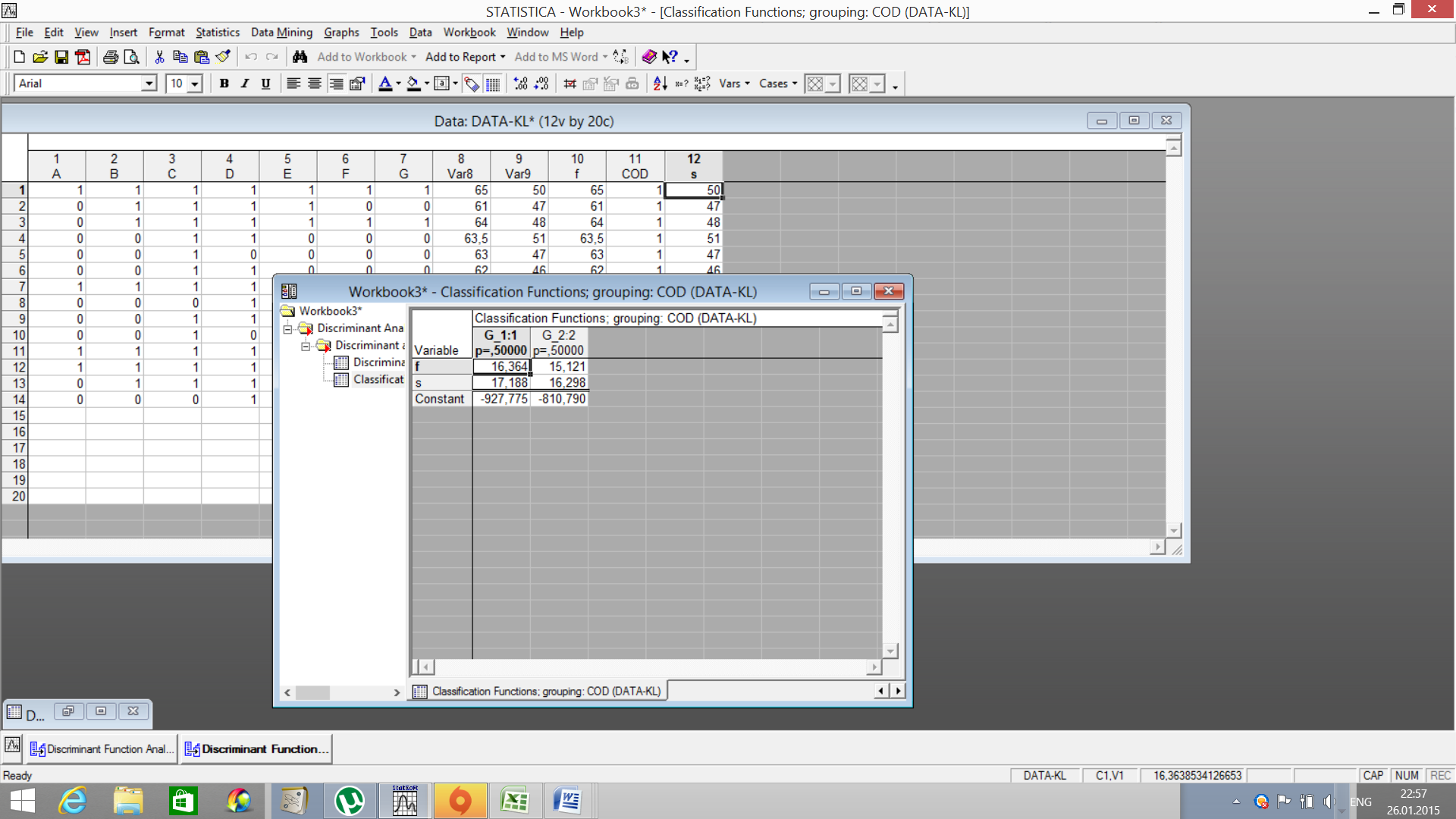
Появится окно с результатами статистики по каждой переменной в модели. Анализ статистики лямбды Уилкса по двум переменным показывает, что вклад второй переменной (S) в дискриминацию выше (значение лямбда Уилкса меньше). Процедура Classification function (Функции классификации)
Функции классификации рассчитываются для каждой группы объектов, используются при классификации объектов. Организация файлов и анализов Организация данных Создание файла с данными
Появится окно Create New Document (Создание нового документа). В котором необходимо ввести: · количество переменных Number of variables; · объем выборки (строк) Number of cases. ОК. Появится окно New Data.
В поле Имя файланужно ввести название файла с данными. Сохранить. Чтобы вставить данные в программу Статистика, необходимо просто сделать процедуру копирования из МОExcel (Ctrl+C– копировать из MOExcel, далее при переходе в программу Статистика Ctrl+V). Если строк не хватает, то программа автоматически добавит необходимое количество строк в файл с данными. В итоге в окне появятся данные, скопированные из MOExcel.
Переименование данных Далее необходимо подписать вектора данных. Для этого нужно два раза нажать на название графы VAR1. Появится окно с названием переменной. Необходимо заполнить следующие поля:
Аналогичные действия проведите со всеми признаками, взятыми для анализа.
Генерация данных Сначала нужно выделить колонку. Нажать два раза по заголовку столбца. В появившемся окне ввести Имя переменной, ширину столбца, число цифр после запятой, определить тип данных.
В нижней части окна вводим формулу, по которой рассчитывается данная переменная (=H-H_SH). ОК. ОК.
В окне данных появился новый показатель.
Файл с данными необходимо сохранить. Расширение *.stw. Группировка данных Modify variable(s) (Изменение переменных) / Recode (перекодировка). Появится окно Recode Values of Variable, в котором задаем границы интервалов следующими командами: Var7> =14 and Var7< 18 и т.д. ОК Далее можно отсортировать данные. Для этого встаньте на заголовок с данными, нажмите правую клавишу мыши, вызовите команду Sort Cases (сортировка).
Расчет основных статистик НеобходимовызватькомандуStatistics → Basic Statistics/Tables.ДалеевыберитеDescriptivestatistics (Описательныестатистики). Для несруппированного ряда Появится окно Descriptivestatistics. Необходимо выбратьпеременные, нажав для этого клавишуVariables.Далее перейдите на закладкуAdvanced(Дополнительные).Появляется окно, где можно отметить нужные статистики. Популярное:
|
Последнее изменение этой страницы: 2016-04-10; Просмотров: 1023; Нарушение авторского права страницы


























 - квантиль распределения Фишера порядка 1-α /2 со степенями свободы
- квантиль распределения Фишера порядка 1-α /2 со степенями свободы  .
. =0, 9370, а квантиль F 0, 975(74, 74)=1, 58.
=0, 9370, а квантиль F 0, 975(74, 74)=1, 58.