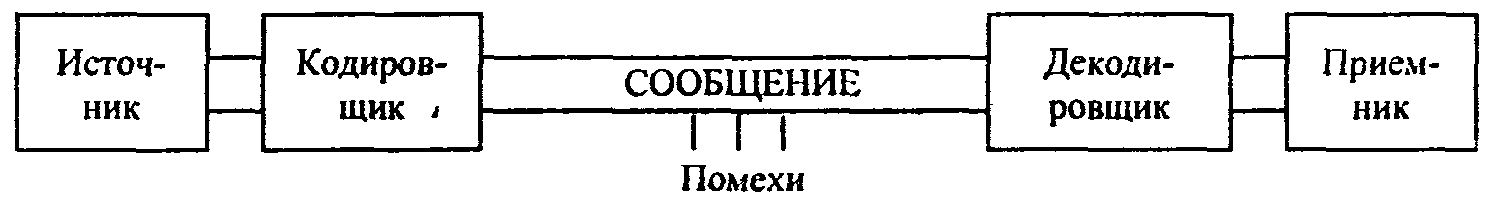|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Теорема Шеннона и передача информации.
Основное значение результатов Шеннона в этой области состоит в том, что они дают универсальный критерий, позволяющий сравнивать технически различные устройства и системы с точки зрения их возможностей по передаче информации. Технически источники сообщений и каналы связи могут быть существенно разными устройствами по используемым сигналам, способам кодирования сообщений, форматам данных, скоростным характеристикам. В этих условиях информационная мера Шеннона и теоремы идеального кодирования позволяют оценить, в какой степени технически различные системы соответствуют друг другу для решения задачи передачи сообщений. Для этого требуется, исходя из технических показателей источника и канала, оценить их информационные показатели: информационную производительность и информационную пропускную способность. Соотношение информационных показателей и является той идеальной мерой, по которой можно судить о степени соответствия реальных систем. Особая заслуга Шеннона состоит в том, что он первым осознал действительную картину влияния случайных помех на процесс передачи сообщений. Принципиальное действие помех выражается в той степени, в какой они влияют на информационные показатели системы. Поэтому каналы с одинаковой пропускной способностью эквивалентны по возможности безошибочной передачи сообщений не зависимо от того, действуют ли в них помехи или нет. Для наглядного пояснения роли теоремы Шеннона прибегнем к следующему сравнению. Пусть имеется трубопровод для доставки от источника некоторого жидкого продукта. Технические возможности трубопровода определяются количеством жидкости, которое можно передать по нему в единицу времени. Производительность источника определим количеством чистого продукта, поступающего от него в единицу времени, а пропускную способность трубопровода — как максимально возможную скорость передачи чистого продукта, соответствующую условию, что от источника поступает чистый продукт без примесей. Аналогом канала с помехами может служить трубопровод с утечкой. Пропускная его способность будет меньше. Чем в трубопроводе без утечки, на величину утечки продукта за единицу времени. Можно теперь представить, какой эффект вызвало бы утверждение, что существует такой способ введения примеси («избыточности») в продукт, при котором, введя количество примеси, равное утечке в трубопроводе, можно по нему доставлять продукт без потерь со скоростью, отвечающей пропускной способности трубопровода с утечкой. Именно такой смысл имеет теорема Шеннона применительно к задаче передачи информации. Продолжая аналогию этого примера, можно сказать, что такой способ введения примеси требует наличия некоего «отстойника», в котором примесь будет отстаиваться в течении определенного времени перед подачей в трубопровод (в идеале — бесконечное время). После такого «отстоя» при движении жидкости по трубопроводув утечку будет уходить только примесь. Интерпретация результатов Шеннона для задач хранения и поиска информации. Результаты теорем Шеннона, традиционно формулируемые для задачи передачи сообщений, легко распространяются на задачи хранения и поиска информации. Рассмотрим задачу хранения данных в следующей обобщенной форме. Пусть данные в виде последовательности записей размещаются в ячейках запоминающего устройства (ЗУ); каждая запись помещается в отдельную ячейку. Записи, предназначенные для хранения, характеризуются некоторой совокупностью технических особенностей: размерами, способами кодирования данных, форматами кодов и т.п. Ячейки ЗУ, в которых размещаются записи, также характеризуются некоторой совокупностью своих технических особенностей: внутренним представлением данных, способом доступа, системой меток и рядом технических ограничений на процесс размещения данных. Кроме того, информация, размещаемая в ячейках ЗУ, может подвергаться воздействию помех, из-за чего в записях появляются ошибки. Возникает вопрос, при каких условиях возможно достоверное хранение информации, т.е. получение из ЗУ данных в том виде, в каком они были туда помещены. Для ответа на этот вопрос в соответствии с шенноновским подходом необходимо перейти от технических характеристик к информационным: - для запоминаемых данных определить среднюю энтропию записи; - для ЗУ определить максимальное количество информации, которое может быть размещено в ячейке с учетом ее технических ограничений и действующих в ней помех, то есть определить информационную емкость ячейки. Тогда для информационных пользователей будет справедлива следующая формулировка теоремы Шеннона для задачи хранения информации: для запоминающего устройства (с помехами и без помех) существует способ сколь угодно достоверного кодирования и декодирования хранимых данных, если только средняя энтропия записи меньше информационной емкости ячейки. Если рассмотреть применение идеального кодирования к задаче хранения информации, то станет ясно, что для этого потребуется ЗУ с потенциально бесконечным числом ячеек, чтобы разместить в нем типичные последовательности записей сколь угодно большой длины. В этом проявляется техническая нереализуемость идеального кодирования применительно к задаче хранения информации. К идеальному результату можно приблизиться, укрупняя хранимые записи. На практике в устройствах хранения данных для ЭВМ (например, в накопителях на магнитных лентах и дисках) широко применятся так называемое блокирование записей. При этом группы записей объединяются в блоки, которые размещаются в ЗУ как некоторые единые укрупненные записи. Этим достигается более экономное использование информационной емкости ячеек. Практическая реализация помехоустойчивого хранения информации основана на методах помехоустойчивого кодирования. Перед помещением записей в ЗУ искусственно увеличивается их избыточность за счет введения дополнительных контрольных символов. После считывания записей из ЗУ производится обнаружение и коррекция ошибок. Рассмотрим теперь задачу поиска в следующей обобщенной форме. Пусть имеется файл, записи которого идентифицируются ключами. Множество запросов записей образуют последовательность аргументов поиска. Знания ключей и аргументов поиска могут подвергаться искажением из-за действия случайных помех при формировании файла и при подготовке запросов. Возникает вопрос, при каких условиях возможен достоверный поиск информации, т.е. получение на каждый запрос именно тех записей которые требуются. В соответствии с шенноновским подходом перейдем к информационным характеристикам: - для последовательностей аргументов поиска определим среднюю энтропию аргументов. Если на аргументы действуют ошибки, то необходимо учесть увеличение средней энтропии вследствие ошибок; - для множества записей файла определим информационную емкость ключа — максимальное количество информации, которое может содержаться в ключе файла. Если ключи файла могут содержать случайные ошибки, то необходимо учесть уменьшение информационной емкости ключа вследствие ошибок. Тогда для информационных показателей будет справедлива следующая формулировка теоремы Шеннонадля задачи поиска информации: Для поиска в файле (с помехами и без помех) существует способ сколь угодно достоверного поиска нужных записей, если только средняя энтропия аргумента меньше информационной емкости ключа. Применение алгоритма идеального кодирования в данной задаче потребует потенциально бесконечного укрупнения файла, чтобы производить поиск в качестве аргумента выступают типичные последовательности исходных аргументов. В этом проявляется техническая нереализуемость идеального кодирования применительно к задаче поиска информации. Как упоминалось во второй главе, разработка технически реализуемых способов помехоустойчивого поиска в настоящее время находится в зачаточном состоянии своего развития. Имеющиеся здесь результаты существенно скромнее, чем, например, в помехоустойчивом кодировании, где создана обширная и глубокая математическая теория кодирования. В чем здесь дело? Почему бы не воспользоваться результатами теории кодирования для решения родственной задачи поиска. Основная идея помехоустойчивого кодирования состоит в искусственном введении избыточности в сообщения по подачи их в канал с помехами. В большинстве задач поиска мы имеем дело с естественной избыточностью сообщений, на которую мы не можем активно воздействовать. Мы получаем уже искаженный аргумент поиска, например, невнятно произнесенную по телефону фамилию клиента, и можем рассчитывать только на естественную избыточность языка (естественная избыточность русского языка, как и большинства европейских языков, оставляет примерно 60 % ). Однако, учитывая принципиальную разрешимость этой задачи в свете результатов Шеннона, а также последние публикации по проблемам помехоустойчивого поиска можно надеяться, что эта проблема будет решена и технически. Сжатие данных. Закодированные сообщения передаются по каналам связи, хранятся в запоминающих устройствах, обрабатываются процессором. Объемы данных, циркулирующих в АСУ, велики, и поэтому в о многих случаях важно обеспечить такое кодирование данных, которое характеризуется минимальной длиной получающихся сообщений. Эта проблема сжатия данных. Решение её обеспечивает увеличение скорости передачи информации и уменьшение требуемой памяти запоминающих устройств. В конечном итоге это ведет к повышению эффективности системы обработки данных. Существует два подхода (или два этапа) сжатия данных: - сжатие, основанное на анализе конкретной структуры и смыслового содержания данных; - сжатие, основанное на анализе статистических свойств кодируемых сообщений. В отличие от первого второй подход носит универсальный характер и может использоваться во всех ситуациях, где есть основания полагать, что сообщения подчиняются вероятностным законам. Далее мы рассмотрим оба этих подхода. 4.1. Сжатие на основе смыслового содержания данных Эти методы носят эвристический, уникальный характер, однако основную идею можно пояснить следующим образом. Пусть множество содержит элементов. Тогда для кодирования элементов множества равномерным кодом потребуется двоичных знаков. При этом будут использованы все двоичные кодовые комбинации. Если используются не все комбинации, код будет избыточным. Таким образом, для сокращения избыточности следует попытаться очертить множество возможных значений элементов данных и с учетом этого произвести кодирование. В реальных условиях это не всегда просто, некоторые виды данных имеют очень большую мощность множества возможных значений. Посмотрим, как же поступают в конкретных случаях. Переход от естественных обозначений к более компактным. Значения многих конкретных данных кодируются в виде, удобном для чтения человеком. При этом они содержат обычно больше символов, чем это необходимо. Например, дата записывается в виде «26 января 1982 г.» или в самой краткой форме: «26.01.82». при этом многие кодовые комбинации, например «33.18.53» или «95.00.11», никогда не используются. Для сжатия таких данных день можно закодировать пятью разрядами, месяц — четырьмя, год — семью, т.е. вся дата займет не более двух байтов. Другой способ записи даты, предложенный еще в средние века состоит в том, чтобы записывать общее число дней, прошедших к настоящему времени с некоторой точки отсчета. При этом часто ограничиваются четырьмя последними цифрами этого представления. Например, 24 мая 1967 года записывается в виде 0000 и отсчет дней от этой даты требует, очевидно, два байта в упакованном десятичном формате. КОДИРОВАНИЕ ИНФОРМАЦИИ. АБСТРАКТНЫЙ АЛФАВИТ
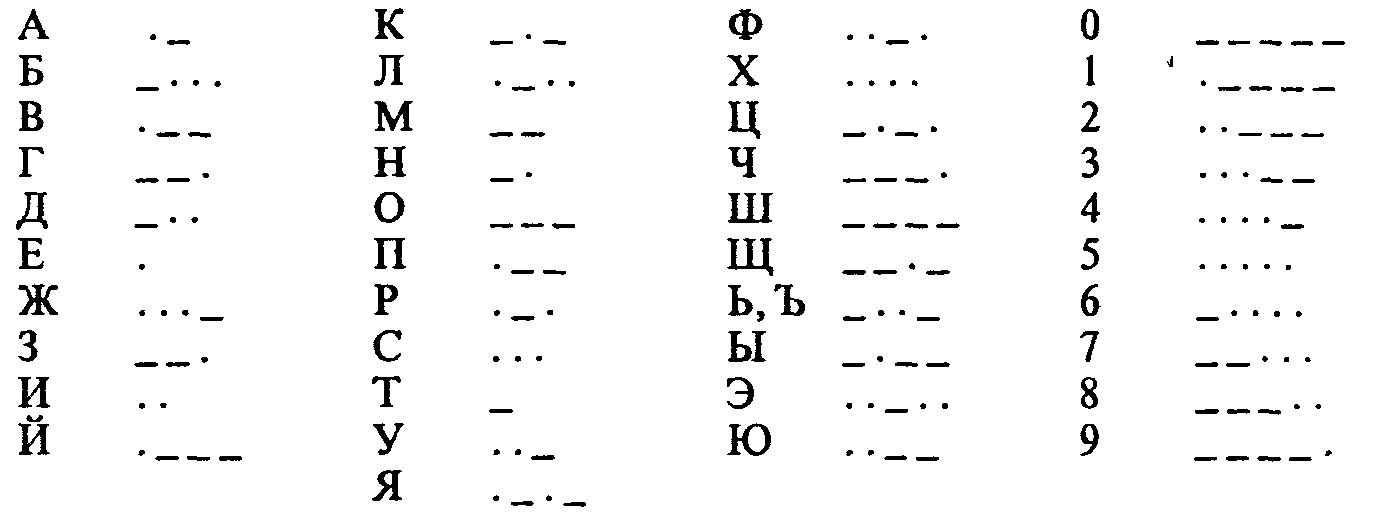
Информация передается в виде сообщений. Дискретная информация записывается с помощью некоторого конечного набора знаков, которые будем называть буквами, не вкладывая в это слово привычного ограниченного значения (типа «русские буквы» или «латинские буквы»). Буква в данном расширенном понимании - любой из знаков, которые некоторым соглашением установлены для общения. Например, при привычной передаче сообщений на русском языке такими знаками будут русские буквы - прописные и строчные, знаки препинания, пробел; если в тексте есть числа - то и цифры. Вообще, буквой будем называть элемент некоторого конечного множества (набора) отличных друг от друга знаков. Множество знаков, в котором определен их порядок, назовем алфавитом (общеизвестен порядок знаков в русском алфавите: А, Б,..., Я). Рассмотрим некоторые примеры алфавитов. 1, Алфавит прописных русских букв: А Б В Г Д Е Е Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я 2. Алфавит Морзе:
3. Алфавит клавиатурных символов ПЭВМ IBM (русифицированная клавиатура):
4. Алфавит знаков правильной шестигранной игральной кости:
5. Алфавит арабских цифр: 6. Алфавит шестнадцатиричных цифр: 0123456789ABCDEF Этот пример, в частности, показывает, что знаки одного алфавита могут образовываться из знаков других алфавитов. 7. Алфавит двоичных цифр: 0 1 Алфавит 7 является одним из примеров, так называемых, «двоичных» алфавитов, т.е. алфавитов, состоящих из двух знаков. Другими примерами являются двоичные алфавиты 8 и 9: 8. Двоичный алфавит «точка, «тире»:. _ 9. Двоичный алфавит «плюс», «минус»: + - 10. Алфавит прописных латинских букв: ABCDEFGHIJKLMNOPQRSTUVWXYZ 11. Алфавит римской системы счисления: I V Х L С D М 12. Алфавит языка блок-схем изображения алгоритмов:
13. Алфавит языка программирования Паскаль (см. в главе 3). КОДИРОВАНИЕ И ДЕКОДИРОВАНИЕ
В канале связи сообщение, составленное из символов (букв) одного алфавита, может преобразовываться в сообщение из символов (букв) другого алфавита. Правило, описывающее однозначное соответствие букв алфавитов при таком преобразовании, называют кодом. Саму процедуру преобразования сообщения называют перекодировкой. Подобное преобразование сообщения может осуществляться в момент поступления сообщения от источника в канал связи (кодирование) и в момент приема сообщения получателем (декодирование). Устройства, обеспечивающие кодирование и декодирование, будем называть соответственно кодировщиком и декодировщиком. На рис. 1.5 приведена схема, иллюстрирующая процесс передачи сообщения в случае перекодировки, а также воздействия помех (см. следующий пункт).
Рис. 1.5. Процесс передачи сообщения от источника к приемнику
1. Азбука Морзе в русском варианте (алфавиту, составленному из алфавита русских заглавных букв и алфавита арабских цифр ставится в соответствие алфавит Морзе):
2. Код Трисиме (знакам латинского алфавита ставятся в соответствие комбинации из трех знаков: 1, 2, 3):
3. Кодирование чисел знаками различных систем счисления см. §3. ^ ПОНЯТИЕ О ТЕОРЕМАХ ШЕННОНА
Ранее отмечалось, что при передаче сообщений по каналам связи могут возникать помехи, способные привести к искажению принимаемых знаков. Так, например, если вы попытаетесь в ветреную погоду передать речевое сообщению человеку, находящемуся от вас на значительном расстоянии, то оно может быть сильно искажено такой помехой, как ветер. Вообще, передача сообщений при наличии помех является серьезной теоретической и практической задачей. Ее значимость возрастает в связи с повсеместным внедрением компьютерных телекоммуникаций, в которых помехи неизбежны. При работе с кодированной информацией, искажаемой помехами, можно выделить следующие основные проблемы: установления самого факта того, что произошло искажение информации; выяснения того, в каком конкретно месте передаваемого текста это произошло; исправления ошибки, хотя бы с некоторой степенью достоверности. Помехи в передачи информации - вполне обычное дело во всех сферах профессиональной деятельности и в быту. Один из примеров был приведен выше, другие примеры - разговор по телефону, в трубке которого «трещит», вождение автомобиля в тумане и т.д. Чаще всего человек вполне справляется с каждой из указанных выше задач, хотя и не всегда отдает себе отчет, как он это делает (т.е. неалгоритмически, а исходя из каких-то ассоциативных связей). Известно, что естественный язык обладает большой избыточностью (в европейских языках - до 7%), чем объясняется большая помехоустойчивость сообщений, составленных из знаков алфавитов таких языков. Примером, иллюстрирующим устойчивость русского языка к помехам, может служить предложение «в словох всо глосноо зомононо боквой о». Здесь 26% символов «поражены», однако это не приводит к потере смысла. Таким образом, в данном случае избыточность является полезным свойством. Избыточность могла бы быть использована и при передаче кодированных сообщений в технических системах. Например, каждый фрагмент текста («предложение») передается трижды, и верным считается та пара фрагментов, которая полностью совпала. Однако, большая избыточность приводит к большим временным затратам при передаче информации и требует большого объема памяти при ее хранении. Впервые теоретическое исследование эффективного кодирования предпринял К.Шеннон. ^ Первая теорема Шеннона декларирует возможность создания системы эффективного кодирования дискретных сообщений, у которой среднее число двоичных символов на один символ сообщения асимптотически стремится к энтропии источника сообщений (в отсутствии помех). Задача эффективного кодирования описывается триадой:
Для решения данной задачи должна быть известна вероятность Рi появления сообщения хi, которому соответствует определенное количество символов пi алфавита В. Тогда математическое ожидание количества символов из Вопределится следующим образом:
Коэффициент избыточности
^ Вторая теорема Шеннона гласит, что при наличии помех в канале всегда можно найти такую систему кодирования, при которой сообщения будут переданы с заданной достоверностью. При наличии ограничения пропускная способность канала должна превышать производительность источника сообщений. Таким образом, вторая теорема Шеннона устанавливает принципы помехоустойчивого кодирования. Для дискретного канала с помехами теорема утверждает, что, если скорость создания сообщений меньше или равна пропускной способности канала, то существует код, обеспечивающий передачу со сколь угодно мглой частотой ошибок. Доказательство теоремы основывается на следующих рассуждениях. Первоначально последовательность Х = {xi}кодируется символами из В так, что достигается максимальная пропускная способность (канал не имеет помех). Затем в последовательность из В длины п вводится r символов и по каналу передается новая последовательность из п + rсимволов. Число возможных последовательностей длины и + т больше числа возможных последовательностей длины п. Множество всех последовательностей длины п + r может быть разбито на п подмножеств, каждому из которых сопоставлена одна из последовательностей длины п. При наличии помехи на последовательность из п + rвыводит ее из соответствующего подмножества с вероятностью сколь угодно малой. Это позволяет определять на приемной стороне канала, какому подмножеству принадлежит искаженная помехами принятая последовательность длины п + r, и тем самым восстановить исходную последовательность длины п. Эта теорема не дает конкретного метода построения кода, но указывает на пределы достижимого в создании помехоустойчивых кодов, стимулирует поиск новых путей решения этой проблемы. ^ Популярное:
|
Последнее изменение этой страницы: 2016-04-11; Просмотров: 1823; Нарушение авторского права страницы