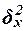|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Алгоритм 2.1. Расчет внутригрупповых дисперсий результативного признака
1. В ячейке, выделенной для внутригрупповых дисперсий первойгруппы ( D52 ), перед формулой поставить знак равенства «=»; 2. В качествеаргумента функции ДИСПР() указать диапазон ячеек из табл. 2.1 со значениями yi первойгруппы – визуально легко определяется по цвету заливки диапазона; ► Внимание! Здесь возможен ошибочный захват мышью столбца значений первого (факторного признака) Х . Необходимо проконтролировать правильность задания аргумента функции ДИСПР(). 3. Enter; 4. Выполнить действия 1–3 поочередно для всех групп, используя цветовые заливки диапазонов. 5. Для расчета итоговой суммы в табл. 2.3 (в ячейке C57 ) перед формулой необходимо поставить знак равенства «=»; 6. Enter. Результат работы алгоритма 2.1 для демонстрационного примера представлен в табл.2.3–ДП.
Алгоритм 2.2. Расчет эмпирического корреляционного отношения 1. В ячейке, выделенной для общей дисперсии ( А63 ), перед формулой поставить знак равенства «=»; 2. Enter; 3. В ячейке, выделенной для средней из внутригрупповых дисперсий ( В63 ), перед формулой поставить знак равенства «=»; 4. Enter; ► Примечание. В случае если при выполнении вычисления в ячейке В63 выдается сообщение " Ошибка в формуле", то разделительный знак «, » между аргументами функции СУМПРОИЗВ(Д1, Д2) необходимо заменить на знак «; ». 5. В ячейке, выделенной для значения межгрупповой (факторной) дисперсии ( С63 ), перед формулой поставить знак равенства «=»; 6. Enter; 7. В ячейке, выделенной для эмпирического корреляционного отношения ( D63), перед формулой поставить знак равенства «=»; 8. Enter. Результат работы алгоритма 2.2 для демонстрационного примера представлен в табл.2.4–ДП.
Задание 2 Построение однофакторной линейной регрессионной модели связи изучаемых признаков с помощью инструмента Регрессия надстройки Пакет анализа Алгоритм выполнения Задания 2 Алгоритм 1. Расчет параметров уравнения линейной регрессии и проверки адекватности модели исходным данным 1. Сервис => Анализ данных => Регрессия => ОК; 2. Входной интервал Y < = диапазон ячеек таблицы со значениями признака Y –Выпуск продукции ( С4: С33 ); 3. Входной интервал X – диапазон ячеек таблицы со значениями признака X –Среднегодовая стоимость основных производственных фондов ( В4: В33 ); 4. Метки в первой строке/Метки в первом столбце – НЕ активизировать; 5. Уровень надежности < = 68, 3 (или 68.3); 6. Константа – ноль – НЕ активизировать; 7. Выходной интервал < = адрес ячейки заголовка первого столбца первой выходной результативной таблицы ( А75 ); 8. Новый рабочий лист и Новая рабочая книга – НЕ активизировать; 9. Остатки – Активизировать; 10. Стандартизованные остатки – НЕ активизировать; 11. График остатков – НЕ активизировать; 12. График подбора – НЕ активизировать; 13. График нормальной вероятности – НЕ активизировать; 14. ОК. В результате указанных действий осуществляется вывод четырех выходных таблиц на Лист 2 Рабочего файла, начиная с ячейки, указанной в поле Выходной интервал диалогового окна инструмента Регрессия (для демонстрационного примера они имеют следующий вид).
Задание 3 Построение однофакторных нелинейных регрессионных моделей связи признаков с помощью инструмента Мастер диаграмм и выбор наиболее адекватного нелинейного уравнения регрессии Алгоритмы выполнения Задания 3 Алгоритм 1. Построение уравнений регрессионных моделей для различных видов нелинейной зависимости признаков с использованием средств инструмента Мастер диаграмм 1. Выделить мышью диаграмму рассеяния признаков, расположенную начиная с ячейки Е4, и увеличить диаграмму на весь экран, используя прием " захват мышью"; 2. Диаграмма => Добавить линию тренда; 3. В появившемся диалоговом окне Линия тренда выбрать вкладку Тип и задать вид регрессионной модели – полином 2-го порядка; 4. Выбрать вкладку Параметры и выполнить действия: 1. Переключатель Название аппроксимирующей кривой: автоматическое/другое – установить в положение другое и ввести имя тренда– полином 2-го порядка; 2. Поле Прогноз вперед на – НЕ активизировать; 3. Поле Прогноз назад на – НЕ активизировать; 4. Флажок Пересечение кривой с осью Y в точке – НЕ активизировать; 5. Флажок Показывать уравнение на диаграмме – Активизировать; 6. Флажок Поместить на диаграмму величину достоверности аппроксимации R2 – Активизировать; 7. ОК; 8. Установить курсор на линию регрессии и щелкнуть правой клавишей мыши; 9. В появившемся диалоговом окне Формат линии тренда выбрать по своему усмотрению тип, цвет и толщину линии; 10. ОК; 11. Выделить уравнение регрессии и индекс детерминации R2 и с помощью приема " захват мышью" вынести их за корреляционное поле. При необходимости уменьшить размер шрифта. 5. Действия 2 – 4 (в п.4 шаги 1–11) выполнить поочередно для следующих видов регрессионных моделей: – полином 3-го порядка, По окончании работы алгоритма 1 выполнить следующие действия: 1. Присвоить полученной диаграмме заголовок " Диаграмма 2.1 " и удалить линии сетки по оси Y (алгоритм 2); 2. Снять заливку области построения (алгоритм 3); 3. При необходимости изменить масштаб шкалы осей диаграммы (алгоритм 4). Алгоритм 2. Присвоение полученной диаграмме заголовка " Диаграмма 2.1" и удаление линий сетки по оси Y 1. Выделить мышью построенную диаграмму; 2. Диаграмма => Параметры диаграммы; 3. В появившемся диалоговом окне Параметры диаграммы выбрать вкладку Заголовки и в поле Название диаграммы ввести заголовок диаграммы " Диаграмма 2.1" ; 4. Выбрать вкладку Линии сетки, в полях Ось Х и Ось Y все флажки – Не активизировать; 5. ОК. Популярное:
|
Последнее изменение этой страницы: 2016-05-03; Просмотров: 999; Нарушение авторского права страницы