
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Аппроксимация на основе специальных рядов
Типовые ряды, известные из математического анализа (ряды Тейлора, Фурье), не подходят для описания функций распределений, так как не обладают свойствами, присущими этому виду функций. Для подобного описания предложены специальные функции, например, основанные на полиномах Чебышева – Эрмита. К числу таких функций относится ряд Грама – Шарлье
(5.1) где Ф(u) – функция нормального распределения центрированной и нормированной случайной величины u=(х – m 1)/m 20, 5, Ф(k)(u) – k-я производная от функции нормального распределения. Вычисление Ф(u) не требует численного интегрирования, так как имеются ее приближения на основе полиномов, а производные представимы элементарными функциями: Ф(3)(u)=(u2 –1)fн(u), Ф(4)(u)=(– u3 + 3u)fн(u), Ф(6)(u)=(– u5 +10u3 –15u)fн(u), fн(u)= (2p ) – 0, 5exp(– u2/2). (5.2) Ряд Грама – Шарлье целесообразно использовать для описания распределений, близких к нормальному. В других случаях начинают проявляться серьезные недостатки: ряд может вести себя нерегулярно (увеличение количества членов ряда иногда снижает точность аппроксимации); ошибки аппроксимации возрастают с удалением от центра распределения; сумма конечного числа членов ряда при большой асимметрии распределения приводит к отрицательным значениям функций, особенно на краях распределений. Этот ряд применяют только при весьма умеренном коэффициенте асимметрии, не превышающем 0, 7. Следовательно, применение рядов тоже не обеспечивает необходимой общности решения задач аппроксимации. Пример 5.1. Оценить качество аппроксимации ЭД, табл. 2.4, на основе ряда Грама – Шарлье. Проверку согласованности провести с использованием критерия хи-квадрат при уровне значимости a = 0, 05. Решение. В примере 2.3 были вычислены значения оценок моментов: m 1 =27, 508, m 2 = 0, 913, m 3= 0, 132, m 4 =1, 819. На основе табл. 2.4 построим табл. 5.3. Таблица 5.3
В таблице значения функции распределения F(xi) для верхней границыинтервала и теоретическое значение оценки вероятности D Fi попадания случайной величины в i-й интервал вычислены на основе ряда Грама – Шарлье. Обозначения оценки частоты попадания Fi=D Fi*n случайной величины в i-й интервал, вероятности D Fi попадания случайной величины в интервал xi – xi–1, взвешенного квадрата отклонения (ni – Fi)2/Fi аналогичны табл. 3.2. Сумма взвешенных квадратов отклонения c 2 = 0, 872 (критическое значение составляет 7, 815). Выборка имеет слабо выраженную асимметрию. По сравнению с аналогичным значением c 2 = 1, 318 при аппроксимации ЭД нормальным распределением, ряд Грама – Шарлье дает более " точное" описание данных. 5.4. Аппроксимация на основе универсальных Существуют различные подходы к построению универсальных семейств распределений. Рассмотрим два наиболее типичных. Первый подход является дальнейшим развитием метода моментов, а второй основан на замене исходной выборки другой, распределение которой является стандартным. Аппроксимация на основе семейства распределений К. Пирсона В рамках первого подхода одно из универсальных семейств распределений предложил К. Пирсон. Моменты распределения случайной величины, даже если все они существуют, не характеризуют полностью этого распределения, но они определяют его однозначно при некоторых условиях, которые выполняются почти для всех используемых на практике распределений. Иначе говоря, при решении задач обработки ЭД знание моментов эквивалентно знанию функции распределения и совпадение значений первых r моментов двух распределений говорит о приблизительной одинаковости распределений. Не зная точно вид функции распределения, но, найдя r первых моментов, можно подобрать другое распределение с теми же первыми моментами. Практически такая аппроксимация оказывается хорошей при совпадении первых трех – четырех моментов. Анализ характерных черт функций плотности унимодальных распределений показывает, что эти распределения начинаются с нуля, поднимаются до максимума, а затем уменьшаются снова до нуля. Это означает, что для описания подобных функций плотности распределений f(x) необходимо выбрать такие уравнения, для которых df(x)/dx=0 при следующих условиях: f(x)=0, тогда по крайней мере на одномкраю распределения будет соприкосновение с осью абсцисс высшего порядка; x=a, где величина a соответствует моде распределения. Этим условиям для центрированной переменной x удовлетворяет дифференциальное уравнение df / dx = (x-a)f /(b0 + b1x + b2x2), решение которого приводит к семейству распределений Пирсона. Действительно, в этом уравнении df(x)/dx равно нулю, если f(x)=0или x=a. Семейство распределенийПирсона включает не только унимодальные, но и распределения, имеющие U-образную форму (две моды). Уравнение содержит четыре неизвестных параметра. Их вычисление основано на методе моментов – четыре выборочных момента приравниваются к соответствующим моментам теоретического распределения, являющимся функциями от неизвестных параметров. Решая полученную систему уравнений относительно неизвестных параметров, получают искомые оценки параметров в виде функций выборочных моментов
(5.3) Выражения для плотности f(x) выводятся путем интегрирования дифференциального уравнения. Интегрирование позволяет получить 11 типов функций плотности распределения, три из которых являются основными, а остальные – их частными случаями, в том числе и такие общеизвестные, как нормальное, экспоненциальное, гамма-распределение. Распределение f(x) сосредоточено: на конечном интервале, если корни уравнения B0 + B1x + B2x2 = 0 представляют собой действительные числа различных знаков; на положительной полупрямой, если корни – действительные числа одного знака и a> 0, или на отрицательной полупрямой при a< 0; на всей оси абсцисс, если уравнение не имеет действительных корней. Принимая моду за начало отсчета исходной центрированной величины, т.е., полагая t = х – a, исходное уравнение представим в виде
Первый основной тип распределения получается в случае, когда корни уравнения B0 + B1t + B2t2 = 0являются действительными числами с различными знаками. Обозначим корни уравнения через –c1 и c2 соответственно, где величины c1 и c2 – положительные числа. Тогда по известной теореме B0 + B1t + B2t2 = B2(t +c1)(t - c2). Исходное уравнение преобразуем к виду
Обозначим g = c1/(B2(c1+ c2)) и h = c2/(B2(c1+ c2)). Тогда можно записать f1(y) = (1/B(g+1, h+1))yg(1 - y)h, (5.4) где 0£ y£ 1. Переменная у определяется через исходный (не центрированный и несмещенный) аргумент x в соответствии с ранее введенными подстановками: y = (c1 + x - m1 - a)/(c1 + c2). Функция плотности распределения первого типа соответствует бета-распределению, рис. 5.5. Функция распределения
(5.5) При наличии действительных корней одного знака получается распределение Пирсона шестого типа. Пусть корни –c1 и –c2 меньше нуля, т. е. B2, c1 и c2 положительны (с1< с2), тогда можно записать
где –с1< t< ¥. Обозначим a=-c1/(B2(c1-c2) и b=c2/(B2(c1-c2). После преобразований получим Здесь, как и для распределения первого типа, t = x – m 1 – a. Используем подстановку (c1-c2)/(c2+t), тогда dt = -(c2 - c1)z-2dz.
Рис. 5. 5. Распределение Пирсона первого типа (бета-распределение)
Функция плотности распределения шестого типа примет вид f6(t)=k6(1– z)a z – (a +b +2). Нормировочный коэффициент k6 определяется аналогично ранее рассмотренному варианту. Нормирующее условие имеет вид Окончательно функция плотности распределения шестого типа f6(z) = 1/[В(– a – b – 1, a +1)] z – (a +b +2)(1–z)a. (5.6) Функция распределения шестого типа
(5.7) Для положительных корней уравнения B0 + B1t + B2t2 = 0 диапазон изменения аргумента –¥ < t < c1, а выражения для плотности и функции распределения получаются такие же, только при выводе используется другая подстановка z=(c2 – c1)/(c2 – t). Таким образом, шестой тип распределения является разновидностью первого типа. Функции распределения (5.5) и (5.7) представляют собой неполные бета-функции Ву(p, q). Когда оба показателя степени в формулах (5.4) и (5.6) больше нуля, плотность имеет единственную моду и обращается в нуль на краях интервала. Если один из показателей отрицателен, то значение плотности на одном краю интервала стремится к бесконечности и распределение имеет L– или J–образную форму. При двух отрицательных показателях распределения принимают U–образную форму, значения функций плотности стремятся к бесконечности на обоих краях. В указанных случаях применение численного интегрирования для вычисления значений функций распределения невозможно. Вычисления значений функций распределения первого и шестого типов целесообразно осуществлять разложением интеграла (неполной бета-функции) в гипергеометрический ряд. Гипергеометрический ряд
(5.8) сходится абсолютно и равномерно при |w|< 1. Для ускорения сходимости ряда неполную бета-функцию вычисляют по различным формулам в зависимости от значения предела интегрирования
(5.9) В формуле (5.9) для распределения первого типа p = g +1 и q = h +1, а для распределения шестого типа p = – a – b – 1, q = a + 1. Если корни уравнения B0 + B1t + B2t2 = 0 комплексные числа, то получается распределение Пирсона четвертого типа с диапазоном изменения переменной по всей оси абсцисс и единственной модой. Путем тождественных преобразований и вводя соответствующие обозначения, исходное дифференциальное уравнение представим в виде
где j = B1/(2B2), Используя правила интегрирования элементарных дробей, уравнение преобразуем к виду
Следовательно, функция плотности четвертого типа
(5.10) Коэффициент R находится из нормирующего условия (интеграл от плотности распределения в пределах изменения переменной равен единице). Для вычисления коэффициента приходится проводить численное интегрирование, так как первообразная функция через элементарные функции не представима. Чтобы перейти к конечным пределам при численном интегрировании, воспользуемся заменой переменной
(5.11) Последовательность подгонки описания эмпирических данных распределениями Пирсона включает следующие этапы: вычисление значения оценок первых четырех моментов эмпирического распределения путем обработки ЭД; вычисление параметров В0, В1, В2, а семейства распределений, переход от исходной переменной x к центрированной и смещенной переменной t; анализ корней квадратного уравнения B0, B1, B2, и определение типа распределения. При этом реальная область значений случайной величины играет второстепенную роль. Например, четвертое распределение Пирсона может служить хорошей аппроксимацией распределения ограниченной случайной величины или наоборот первое распределение – для случайной величины с бесконечными пределами изменения; вычисление параметров выбранного типа распределения; проверку гипотезы о возможности применения выбранного распределения для описания ЭД. Распределения Пирсона вполне удовлетворительно обобщают результаты наблюдений. Но эти оценки не являются наилучшими, так как имеют неминимальные дисперсии, а, следовательно, не являются наилучшими оценками параметров генеральной совокупности. Области в плоскости квадрата коэффициента асимметрии b12 и коэффициента эксцесса b2, соответствующие различным распределениям семейства Пирсона, показаны на рис. 5.6. Из рисунка видно, что распределения Пирсона охватывают широкую область возможных видов распределений и включают в себя как частные случаи нормальное (н. р.), экспоненциальное (э. р.), гамма (г. р.) и другие типовые распределения. Нормальное и экспоненциальное распределения не имеют параметров формы, поэтому на рисунке отображаются точками, гамма-распределение имеет только один параметр формы и ему соответствует линия. Иначе говоря, типовые распределения обладают скромными возможностями по аппроксимации ЭД.
Рис. 5.6. Области аппроксимации ЭД семейством распределений Пирсона Недостаток рассмотренного метода состоит в большой трудоемкости расчетов значений функции распределения. Пример 5.2. Необходимо подобрать распределение Пирсона для описания ЭД, табл. 2.4, и оценить качество аппроксимации. Проверку согласованности провести с использованием критерия хи-квадрат при уровне значимости a =0, 05. Решение. Значения оценок моментов были вычислены ранее: m 1 =27, 508, m 2 = 0, 913, m 3= 0, 132, m 4 =1, 819. По формулам (5.3) вычислим параметры распределения: А = 2, 6995; а = 0, 2112; В0 = – 2, 2290; В1 = – 0, 2112; В2 = 0, 4804. Корни уравнения b0+b1x+b2 x2 = 0 – действительные числа различных знаков: – с1 = – 1, 945; с2 = 2, 385. Значит, распределение относится к первому типу и сосредоточено на ограниченном интервале. Построим табл. 5.4, иллюстрирующую расчеты. Таблица 5.4
В таблице значения функции распределения F(xi) для верхней границыинтервала и теоретическое значение оценки вероятности D Fi попадания случайной величины в i-й интервал вычислены на основе распределения Пирсона первого типа. Расчет оценки частоты Fi=n ´ D Fi, вероятности D Fi попадания случайной величины в интервал xi – xi–1, взвешенного квадрата отклонения (n i – Fi)2/Fi проводится аналогично примеру 5.1. Значение критерия составляет c 2 =1, 757. По сравнению с критическим значением хи-квадрат, равным 7, 815, аппроксимация с помощью распределения Пирсона дает вполне допустимый результат, хотя в данном случае и уступает по " точности" аппроксимации с помощью ряда Грама – Шарлье (c 2 = 0, 872). Повысить точность аппроксимации можно, если проанализировать плотность аппроксимирующего распределения. Полученная функция плотности имеет небольшой коэффициент эксцесса, поэтому наблюдаются относительно большие отклонения функции распределения от ЭД. Такая ситуация является следствием значительной погрешности в оценке четвертого момента из-за ограниченного объема выборки. Следовательно, для повышения качества аппроксимации необходимо увеличить значение четвертого момента. Увеличим значение четвертого момента до 2, 2 (ошибки в 20 – 25% при оценке четвертого момента по выборке малого объема вполне реальны) и пересчитаем все параметры. В результате получится значение c 2 =0, 864, что практически одинаково с аппроксимацией рядом Грама – Шарлье. Потенциально аппроксимация по Пирсону является более универсальной по сравнению с рядами Грама – Шарлье. Семейство Пирсона охватывают широкий класс законов распределений, а не только близкие к нормальному, как это имеет место при применении рядов. Аппроксимация на основе семейства распределений Джонсона Этот универсальный вид аппроксимации основан на таком преобразовании g(x) исходной случайной величины Х (заданной в некотором интервале), которое позволит рассматривать результат преобразования как стандартизованную случайную величину, распределенную по нормальному закону. Данное преобразование допустимо при следующих условиях: функция плотности распределения случайной величины Х является унимодальной; функция g(x) является монотонной на заданном интервале; область значений функции g(x) лежит в диапазоне от –¥ до ¥ . Указанным условиям отвечает система функций, предложеннаяДжонсоном. Достоинство данного подхода состоит в том, что значения эмпирической функции распределения случайной величины Х вычисляются как значения функции нормального распределения. Преобразование Джонсона в общем случае имеет вид x = g + ht(z, e, l); h > 0, –¥ < g < ¥, l> 0, –¥ < e < ¥, (5.12) где g, h, e, l – параметры распределения; u – центрированная и нормированная случайная величина, распределенная по нормальному закону; t – некоторая функция; х – случайная величина с произвольной унимодальной плотностью распределения. В качестве t предложено использовать три вида функций:
(5.13) Для семейства функций первого вида
(5.14) Эта функция соответствует логарифмически нормальному распределению и называется семейством распределений SL Джонсона. Логарифмически нормальное распределение не обладает общностью исходного семейства, так как оно фактически зависит от трех, а не от четырех параметров. Действительно, выражение Аналогично можно найти плотность распределения для второго и третьего семейств распределений Джонсона:
(5.15) Эти функции получили названия SB и SU семейства распределений Джонсона соответственно. Они имеют два параметра формы g и h, параметр e характеризует центр, l – масштаб распределения. Возможности распределений Джонсона по описанию статистических данных практически эквивалентны распределениям Пирсона. Функции распределения Джонсона в явном виде представить нельзя, да в этом и нет необходимости, так как расчет значений функций распределения осуществляется на основе нормального распределения. Чтобы определить одно из трех семейств распределений для аппроксимации полученной совокупности ЭД, можно воспользоваться следующим подходом. По экспериментальным данным находят значения оценок первых четырех центральных моментов, затем значения оценок параметров асимметрии
(5.16) то выбирается семейство распределений SL, рис. 5.7. Если точка лежит выше этой линии, то выбирается семейство SB, если ниже – то SU распределение Джонсона. Точки для описания линии, разделяющей области аппроксимации, находят путем решения первого уравнения (5.16) относительно w и подстановкой найденного значения во второе уравнение. Некоторые значения параметра w и соответствующие ему значения b12 и b2 представлены в табл. 5.5 и на рис. 5.7. Таблица 5.5
Рис. 5.7. Области аппроксимации распределениями Джонсона Определение моментов или построение функции правдоподобия для распределений Джонсона достаточно трудоемко. Для целей аппроксимации проще использовать метод квантилей. Количество используемых квантилей и соответственно уравнений равно количеству определяемых параметров распределения. Уравнения для нахождения неизвестных параметров для SL, SB, SU распределений Джонсона имеют соответственно вид:
(5.17) Первая система уравнений допускает решение в аналитическом виде. Для этого целесообразно в качестве одной из квантилей взять 0, 5-ю квантиль (квантиль уровня 0, 5 функции стандартизованного нормального распределения равна нулю), а в качестве двух других взять симметричные значения хa и х1– a, например х0, 35 и х0, 65. Значения таких квантилей ua функции стандартизованного нормального распределения равны по величине, но различаются знаком. Тогда оценки параметров SL распределения:
(5.18) Решение систем уравнений для двух других семейств возможно только на основе численных методов. При этом основная сложность состоит в определении начальных приближений для искомых параметров. Завершающим этапом аппроксимации с использованием семейств распределений Джонсона должна быть проверка согласованности подобранного распределения и ЭД. Пример 5.3. Необходимо подобрать распределение Джонсона для описания ЭД, представляющих интервалы времени между поступлениями запросов к базе данных, табл. 5.6. Проверку согласованности провести с использованием критерия Мизеса при уровне значимости a = 0, 1. Таблица 5.6
Решение. Определим вид семейства распределений Джонсона. Для этого вычислим значения оценок: моментов m 1=11, 25, m 2=98, 18, m 3=1614, 33, m 4=44140, 97. Оценка третьего момента имеет положительное значение, поэтому плотность распределения характеризуется положительной асимметрией; коэффициентов асимметрии и эксцесса b 12 = 2, 75, b 2 = 4, 58. На основе полученного значения величины b 12 в соответствии с первым уравнением (5.16) определим значение вспомогательного параметра w = 5, 24. Этому значению w соответствует точка линии с координатой b2 = 1125, 7. Так как b 2 < < b2, то выборку целесообразно аппроксимировать распределением SU Джонсона, рис. 5.7. Для подбора значений параметров распределения SU Джонсона воспользуемся методом квантилей. Возьмем четыре квантили, соответствующие области максимальных значений плотности распределения, например: х4/12 = 5, 18; х5/12 = 6, 22; х6/12 = 9, 14; х7/12 = 9, 94. Этим квантилям исходной выборки соответствуют квантили стандартизованного нормального распределения: u4/12 = – 0, 4307; u5/12 = – 0, 2104; u6/12 = 0, 0; u7/12 = 0, 2104. Приравнивая квантили, получим систему уравнений:
Воспользуемся пакетом символьной математики MathCAD для нахождения параметров, отвечающих указанной системе уравнений. Результаты вычислений зависят от начальных условий, поэтому потребуется выполнение ряда итераций: первоначально зададим начальные значения оцениваемых параметров, например, равными единице; применяя средства решения системы нелинейных уравнений и функцию Minerr, найдем приближенные значения параметров; подставим найденные значения как начальные приближения и получим уточненные значения параметров. Последние два этапа повторим несколько раз до тех пор, пока корни уравнений перестанут существенно отличаться от начальных приближений. В результате получим приближенные значения искомых величин: g = – 0, 2; h = 0, 188; l = 1, 046; e = 7, 809. Преобразование Джонсона примет вид u = - 0, 2 + 0, 188 arcsh ((x - 7, 809)/1, 046). (5.19) В целях проверки качества аппроксимации ЭД подобранным законом распределения по аналогии с примером 3.3 построим табл. 5.7. Таблица 5.7
В этой таблице: Fn(xi)=(i–0, 5)/12 – значения эмпирической функции распределения; ui – значения аргумента в соответствии с преобразованием (5.19); Ф(ui) – значения функции нормального распределения стандартизованной величины ui; D i = [Fn (xi) – Ф(ui)] 2 . Значение критерия Мизеса пw 2=1/(12´ 12)+ Таким образом, универсальные методы аппроксимации, обеспечивая высокую гибкость решения задачи подгонки распределений к ЭД, требуют существенных вычислительных затрат на свою реализацию и применения специализированных пакетов обработки данных. Следует учитывать, что рассмотренные универсальные способы аппроксимации не являются всеобъемлющими – существуют случайные величины, распределение которых плохо описывается указанными зависимостями. В первую очередь к ним относятся случайные величины с усеченными законами распределения. Например, распределение времени ожидания заявок в очереди к одноканальной системе массового обслуживания при пуассоновском входном потоке и экспоненциальном времени обслуживания (теоретическая функция распределения имеет вид усеченного слева экспоненциального распределения F(t) = 1 - p exp( - m(1 - p)t), где r – загрузка системы, m – интенсивность обслуживания заявок). Аппроксимация универсальным распределением дает существенные погрешности в области малых значений аргумента t, хотя и может применяться в области больших значений этого аргумента. ПРИЛОЖЕНИЕ Популярное:
|
Последнее изменение этой страницы: 2016-06-05; Просмотров: 2028; Нарушение авторского права страницы

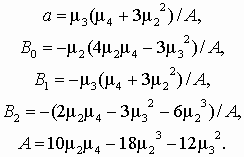
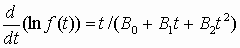 .
.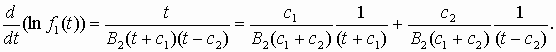
 Решение дифференциального уравнения с точностью до некоторого коэффициента k1 можно представить в виде f1(t) = k1(c1 + t)g(c2 - t)h. Размах данного распределения сосредоточен на интервале (–c1, c2). Проведем замену переменной t = (c1+ c2)y -c1, учитывая, что dt = (c1+c2)dy, включим постоянный сомножитель (c1+c2)g+h+1 в состав коэффициента k1. В итоге получим f1(y)=k1yg (1–y)h , где y изменяется в пределах от 0 до 1. Интегрируя в этих пределах функцию f1(t), можно найти значение k1из условия
Решение дифференциального уравнения с точностью до некоторого коэффициента k1 можно представить в виде f1(t) = k1(c1 + t)g(c2 - t)h. Размах данного распределения сосредоточен на интервале (–c1, c2). Проведем замену переменной t = (c1+ c2)y -c1, учитывая, что dt = (c1+c2)dy, включим постоянный сомножитель (c1+c2)g+h+1 в состав коэффициента k1. В итоге получим f1(y)=k1yg (1–y)h , где y изменяется в пределах от 0 до 1. Интегрируя в этих пределах функцию f1(t), можно найти значение k1из условия 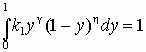 . Интеграл в данном выражении по определению соответствует бета-функции B(g+1, h+1), которая определяется через гамма-функцию B(g+1, h+1) = Г(g+1)Г(h+1)/Г(g+h+2). Итак, k1= 1/B(g+1, h+1). Окончательно плотность распределения
. Интеграл в данном выражении по определению соответствует бета-функции B(g+1, h+1), которая определяется через гамма-функцию B(g+1, h+1) = Г(g+1)Г(h+1)/Г(g+h+2). Итак, k1= 1/B(g+1, h+1). Окончательно плотность распределения
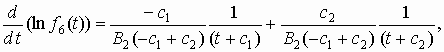
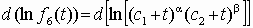 или f6(t)=k6(c1+t)a (c2 + t)b.
или f6(t)=k6(c1+t)a (c2 + t)b.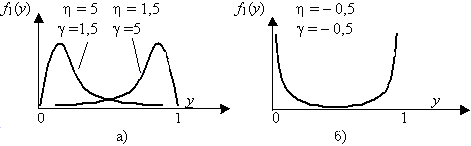

 . Следовательно, коэффициент k6 определяется через бета-функцию: k6 = 1/В(– a – b – 1, a +1).
. Следовательно, коэффициент k6 определяется через бета-функцию: k6 = 1/В(– a – b – 1, a +1). .
.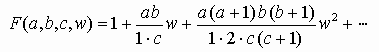
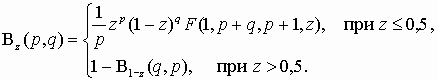

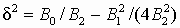 .
. .
.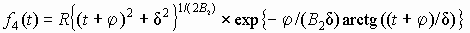
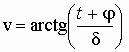 , тогда интегрирование следует провести в пределах от –p /2 до p /2 (здесь, как и ранее, t = x– m 1 – a). Окончательно получим
, тогда интегрирование следует провести в пределах от –p /2 до p /2 (здесь, как и ранее, t = x– m 1 – a). Окончательно получим


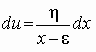 , тогда
, тогда
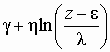 можно записать в виде g - h ln l, и величину g - h ln l следует рассматривать как единый параметр.
можно записать в виде g - h ln l, и величину g - h ln l следует рассматривать как единый параметр.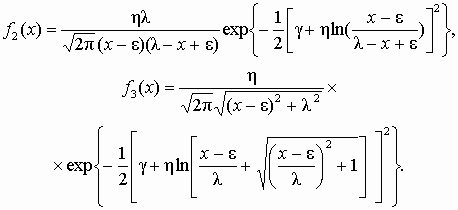
 и эксцесса
и эксцесса  распределения. Если точка с координатами
распределения. Если точка с координатами 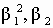 находится вблизи линии с координатами
находится вблизи линии с координатами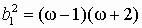 и b2 = w4 + 2w3 +3w2 - 3
и b2 = w4 + 2w3 +3w2 - 3
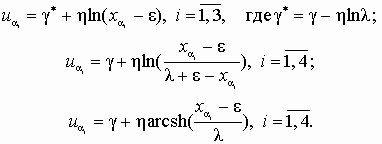
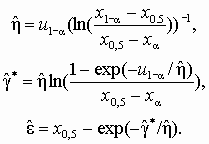

 = 0, 241. Критическое значение этого критерия при уровне значимости a = 0, 1 составляет 0, 347, табл. П.2. Расчетное значение меньше критического, следовательно, подобранное распределение Джонсона не противоречит ЭД и его можно использовать для аппроксимации.
= 0, 241. Критическое значение этого критерия при уровне значимости a = 0, 1 составляет 0, 347, табл. П.2. Расчетное значение меньше критического, следовательно, подобранное распределение Джонсона не противоречит ЭД и его можно использовать для аппроксимации.