
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
ОБРАБОТКА ЭКСПЕРИМЕНТАЛЬНЫХ ДАННЫХ НА ЭВМСтр 1 из 8Следующая ⇒
МИНИСТЕРСТВО РОССИЙСКОЙ ФЕДЕРАЦИИ ПО СВЯЗИ И ИНФОРМАТИЗАЦИИ САНКТ-ПЕТЕРБУРГСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ ТЕЛЕКОММУНИКАЦИЙ ИМ. ПРОФ.М.А.БОНЧ-БРУЕВИЧА
Г.Б. Ходасевич ОБРАБОТКА ЭКСПЕРИМЕНТАЛЬНЫХ ДАННЫХ НА ЭВМ ЧАСТЬ 1. 220200 СОДЕРЖАНИЕ ПРЕДИСЛОВИЕ 1. ОБЩАЯ ХАРАКТЕРИСТИКА ЭКСПЕРЕМЕНТАЛЬНЫХ ДАННЫХ 1.1. Источники и вид представления эксперементальных данных 2. БАЗОВЫЕ ПОНЯТИЯ И ОПЕРАЦИИ ОБРАБОТКИ ЭКСПЕРЕМЕНТАЛЬНЫХ ДАННЫХ 2.1 Эмперическая функция распределения 3. ПРОВЕРКА СТАТИСТИЧЕСКИХ ГИПОТЕЗ 3.1. Сущность задаи проверки статистических гипотез 4. МЕТОДЫ ОЦЕНКИ ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ 4.1. Точечная оценка параметров распределения 5. АППРОКСИМАЦИЯ ЗАКОНА РАСПРЕДЕЛЕНИЯ ЭКСПЕРЕМЕНТАЛЬНЫХ ДАННЫХ 5.1. Задачи аппроксимасимации ПРИЛОЖЕНИЕ. Критические точки распределений ЛИТЕРАТУРА ПРЕДИСЛОВИЕ Эмпирические исследования являются основным источником объективной информации о характеристиках процессов, протекающих в реальных объектах, в том числе в автоматизированных системах, средствах и комплексах телекоммуникаций. Целью обработки экспериментальных данных (ЭД) является выявление закономерностей в характеристиках исследуемых объектов и процессов. Результаты обработки ЭД позволяют оценить качество объекта, они необходимы для оперативного управления процессами, решения задач адаптации объекта к изменившимся условиям или формирования требований ко вновь создаваемым системам. Получение экспериментальной информации связано с решением ряда проблем по организации регистрации первичных параметров, их сбора и обработки. Те данные, которые можно непосредственно зарегистрировать, обычно лишь косвенно отражают существенные свойства изучаемого процесса или объекта. Многие показатели качества автоматизированных систем носят случайный характер и по этой причине не могут быть непосредственно измерены. Ряд событий в системах происходит крайне редко, и получить для них достаточный объем эмпирических данных (в частности, получить данные по отказам систем с высокой надежностью) невозможно. Методы обработки ЭД начали разрабатываться более двух веков тому назад в связи с необходимостью решения практических задач по агробиологии, медицине, экономике, социологии. Полученные при этом результаты составили фундамент такой научной дисциплины, как математическая статистика. В последние 20–30 лет математический аппарат обработки ЭД получил значительное развитие в связи с необходимостью решения принципиально новых задач. И к настоящему времени он включает множество различных направлений, которые выходят за пределы классической математической статистики. Многие методы нашли применение при исследовании технических и человеко-машинных систем, а также при обработке результатов имитационного (статистического) моделирования. В пределах одного учебного пособия изложить все многообразие основных методов обработки ЭД невозможно. Материал ограничен раскрытием основ обработки экспериментальных данных применительно к стационарному режиму функционирования объекта, вопросы оценки характеристик случайных функций в пособии не затрагиваются. Из всех форм представления экспериментальных данных рассматривается только одна наиболее универсальная – числовая. Предполагается, что ЭД получены в результате проведения пассивного эксперимента, а объем данных фиксирован к началу обработки. В основу пособия положен одноименный курс лекций, читаемый студентам специальности " Автоматизированные системы обработки информации и управления". Пособие состоит из двух частей. Первая часть посвящена изложению исходных понятий по обработке результатов наблюдений, раскрытию сущности задач и методов обработки ЭД, относящихся к одному простому свойству исследуемого объекта. Рассмотрены три основные группы вопросов: оценка параметров распределения; проверка статистических гипотез; подбор (аппроксимация) закона распределения для описания данных. В приложении приведены фрагменты статистических таблиц, широко применяемых в задачах обработки экспериментальных данных. Вторая часть пособия посвящена задачам и методам обработки однотипных, многомерных и цензурированных экспериментальных данных. Обработка однотипных данных направлена на объединение сведений, полученных от различных источников или от одного источника, но на различных этапах эксплуатации объекта. Обработка многомерных данных предусматривает установление связей между параметрами, оценку влияния факторов на показатели качества объекта. Методы оценки параметров по цензурированным ЭД направлены на учет того обстоятельства, что некоторые события, подлежащие регистрации, происходят в неизвестные моменты времени вне периода наблюдения. Рассмотренные в пособии задачи снабжены примерами, иллюстрирующими последовательность и сущность этапов обработки ЭД. Для освоения материала пособия необходимы начальные сведения по математическому анализу и теории вероятностей. Выполнение практических задач предполагает применение типовых пакетов прикладных программ для проведения расчетов (например, пакета символьной математики MathCAD, табличного процессора MS Excel) или специализированных пакетов обработки статистических данных типа STATISTICA, SPSS. ОБЩАЯ ХАРАКТЕРИСТИКА ЭКСПЕРИМЕНТАЛЬНЫХ ДАННЫХ БАЗОВЫЕ ПОНЯТИЯ И ОПЕРАЦИИ ОБРАБОТКИ ЭКСПЕРИМЕНТАЛЬНЫХ ДАННЫХ ПРОВЕРКА СТАТИСТИЧЕСКИХ ГИПОТЕЗ Типовые распределения При проверке гипотез широкое применение находит ряд теоретических законов распределения. Наиболее важным из них является нормальное распределение. С ним связаны распределения хи-квадрат, Стьюдента, Фишера, а также интеграл вероятностей. Для указанных законов функции распределения аналитически не представимы. Значения функций определяются по таблицам или с использованием стандартных процедур пакетов прикладных программ. Указанные таблицы обычно построены в целях удобства проверки статистических гипотез в ущерб теории распределений – они содержат не значения функций распределения, а критические значения аргумента z(a ). Для односторонней критической области z(a ) = z1–a, т.е. критическое значение аргумента z(a ) соответствует квантили z1–a уровня 1– a, так как
Рис. 3.3. Односторонняя критическая область Для двусторонней критической области, с уровнем значимости a, размер левой области a 2, правой a 1 (a 1+a 2=a ), рис. 3.4. Значения z(a 2) и z(a 1) связаны с квантилями распределения соотношениями z(a 1)=z1–a 1, z(a 2)=za 2, так как
Рис. 3.4. Двусторонняя критическая область Нормальное распределение Этот вид распределения является наиболее важным в связи с центральной предельной теоремой теории вероятностей: распределение суммы независимых случайных величин стремится к нормальному с увеличением их количества при произвольном законе распределения отдельных слагаемых, если слагаемые обладают конечной дисперсией. Так как реальные физические явления часто представляют собой результат суммарного воздействия многих факторов, то в таких случаях нормальное распределение является хорошим приближением наблюдаемых значений. Функция плотности нормального распределения
(3.1) – унимодальная, симметричная, аргумент х может принимать любые действительные значения, рис. 3.5.
Рис. 3.5. Плотность нормального распределения Функция плотности нормального распределения стандартизованной величины u имеет вид Вычисление значений функции распределения Ф(u) для стандартизованного неотрицательного аргумента u (u ³ 0) можно произвести с помощью полинома наилучшего приближения [9, стр. 694] Ф(u)= 1– 0, 5(1 + 0, 196854u + 0, 115194u2 + + 0, 000344u3 + 0, 019527u4)– 4. (3.2) Такая аппроксимация обеспечивает абсолютную ошибку не более 0, 00025. Для вычисления Ф(u) в области отрицательных значений стандартизованного аргумента u (u< 0) следует воспользоваться свойством симметрии нормального распределения Ф(u) = 1 –Ф(–u). Иногда в справочниках вместо значений функции Ф(u) приводят значения интеграла вероятностей
(3.3) Интеграл вероятностей связан с функцией нормального распределения соотношением Ф(u) = 0, 5 + F(u). Распределение хи-квадрат Распределению хи-квадрат (c 2-распределению) с k степенями свободы соответствует распределение суммы
(3.4) где х = c 2, Г(k/2) – гамма-функция. Число степеней свободы k определяет количество независимых слагаемых в выражении для c 2. Функция плотности при k, равном одному или двум, – монотонная, а при k > 2 – унимодальная, несимметричная, рис. 3.6.
Рис. 3.6. Плотность распределения хи-квадрат Математическое ожидание и дисперсия величины c 2 равны соответственно k и 2k. Распределение хи-квадрат является частным случаем более общего гамма-распределения, а величина, равная корню квадратному из хи-квадрат с двумя степенями свободы, подчиняется распределению Рэлея. С увеличением числа степеней свободы (k > 30) распределение хи-квадрат приближается к нормальному распределению с математическим ожиданием k и дисперсией 2k. В таких случаях критическое значение c 2(k; a ) » u1– a (k, 2k), где u1– a (k, 2k) – квантиль нормального распределения. Погрешность аппроксимации не превышает нескольких процентов. Распределение Стьюдента Распределение Стьюдента (t-распределение, предложено в 1908 г. английским статистиком В. Госсетом, публиковавшим научные труды под псевдонимом Student) характеризует распределение случайной величины
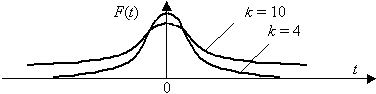
(3.5) Величина k характеризует количество степеней свободы. Плотность распределения – унимодальная и симметричная функция, похожая на нормальное распределение, рис. 3.7.
Область изменения аргумента t от –¥ до ¥ . Математическое ожидание и дисперсия равны 0 и k/(k–2) соответственно, при k> 2. По сравнению с нормальным распределение Стьюдента более пологое, оно имеет меньшую дисперсию. Это отличие заметно при небольших значениях k, что следует учитывать при проверке статистических гипотез (критические значения аргумента распределения Стьюдента превышают аналогичные показатели нормального распределения). Таблицы распределения содержат значения для односторонней Распределение Стьюдента применяется для описания ошибок выборки при k £ 30. При k > 100 данное распределение практически соответствует нормальному, для 30 < k < 100 различия между распределением Стьюдента и нормальным распределением составляют несколько процентов. Поэтому относительно оценки ошибок малыми считаются выборки объемом не более 30 единиц, большими – объемом более 100 единиц. При аппроксимации распределения Стьюдента нормальным распределением для односторонней критической области вероятность Р{t > t(k; a )} = u1– a (0, k/(k–2)), где u1– a (0, k/(k–2)) – квантиль нормального распределения. Аналогичное соотношение можно составить и для двусторонней критической области. Распределение Фишера Распределению Р.А. Фишера (F-распределению Фишера – Снедекора) подчиняется случайная величина х =[(y1/k1)/(y2/k2)], равная отношению двух случайных величин у1и у2, имеющих хи-квадрат распределение с k1 и k2 степенями свободы. Область изменения аргумента х от 0 до ¥ . Плотность распределения
(3.6) В этом выражении k1обозначаетчисло степеней свободы величины y1 с большей дисперсией, k2– число степеней свободы величины y2 с меньшей дисперсией. Плотность распределения – унимодальная, несимметричная, рис. 3.8.
Рис. 3.8. Плотность распределения Фищера Математическое ожидание случайной величины х равно k2/(k2–2) при k2> 2, дисперсия т2 = [2 k22 (k1+k2–2)]/[k1(k2–2)2(k2–4)] при k2 > 4. При k1 > 30 и k2 > 30 величина х распределена приближенно нормально с центром (k1 – k2)/(2 k1 k2) и дисперсией (k1 + k2)/(2 k1 k2). Задачи аппроксимации Конкретное содержание обработки одномерных ЭД зависит от поставленных целей исследования. В простейшем случае достаточно определить первый момент распределения, например, среднее время обработки запросов к распределенной базе данных. В других случаях требуется установить вероятностно-временные характеристики распределения, например, оценить вероятность своевременной обработки запросов или вероятность безотказной работы системы в течение заданного периода времени. Для нахождения таких значений требуется знание закона распределения как наиболее полной характеристики соответствующей случайной величины. В классической математической статистике предполагается известным вид закона распределения и производится оценка значений его параметров по результатам наблюдений. Но обычно заранее вид закона распределения неизвестен, а теоретические предположения не позволяют его однозначно установить. Обработка ЭД также не позволит точно вычислить истинный закон распределения показателя. В таком случае следует говорить только об аппроксимации (приближенном описании) реального закона некоторым другим, который не противоречит ЭД и в каком-то смысле похож на этот неизвестный истинный закон. В соответствии с этими положениями постановка задачи аппроксимации закона распределения ЭД формулируется следующим образом. Имеется выборка наблюдений (x1, x2, …, xn) за случайной величиной Х. Объем выборки п фиксирован. Необходимо подобрать закон распределения (вид и параметры), который бы в статистическом смысле соответствовал имеющимся наблюдениям. Ограничения: выборка представительная, ее объем достаточен для оценки параметров и проверки согласованности выбранного закона распределения и ЭД; плотность распределения унимодальная. Наличие в функции плотности распределения нескольких мод может быть следствием различных причин, например существованием различных по длине маршрутов прохождения запросов в системе обработки. Выборку с несколькими модами разделяют на составные части так, чтобы каждая из них имела одну моду. В последнем случае функция распределения исходной выборки представляет собой взвешенную сумму соответствующих функций отдельных выборок: Решение поставленной задачи аппроксимации осуществляется на основе применения " типовых" распределений, специальных рядов или семейств универсальных распределений [3, 7, 8, 9, 12]. ПРИЛОЖЕНИЕ Распределение Мизеса
Таблица П.3 Распределение хи-квадрат
Таблица П.4 Распределение Стьюдента
Таблица П.5 Распределение Вилкоксона
Таблица П.6 Распределение Р. Фишера (F-распределение)
Продолжение табл. П.6
Продолжение табл. П.6
Таблица П.7 Распределение Кочрена
Продолжение таблицы П.7
ЛИТЕРАТУРА
Т.6. Экспериментальная отработка и испытания. – М.: Машиностроение, 1989.
МИНИСТЕРСТВО РОССИЙСКОЙ ФЕДЕРАЦИИ ПО СВЯЗИ И ИНФОРМАТИЗАЦИИ САНКТ-ПЕТЕРБУРГСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ ТЕЛЕКОММУНИКАЦИЙ ИМ. ПРОФ.М.А.БОНЧ-БРУЕВИЧА
Г.Б. Ходасевич ОБРАБОТКА ЭКСПЕРИМЕНТАЛЬНЫХ ДАННЫХ НА ЭВМ ЧАСТЬ 1. 220200 СОДЕРЖАНИЕ ПРЕДИСЛОВИЕ 1. ОБЩАЯ ХАРАКТЕРИСТИКА ЭКСПЕРЕМЕНТАЛЬНЫХ ДАННЫХ 1.1. Источники и вид представления эксперементальных данных 2. БАЗОВЫЕ ПОНЯТИЯ И ОПЕРАЦИИ ОБРАБОТКИ ЭКСПЕРЕМЕНТАЛЬНЫХ ДАННЫХ 2.1 Эмперическая функция распределения 3. ПРОВЕРКА СТАТИСТИЧЕСКИХ ГИПОТЕЗ 3.1. Сущность задаи проверки статистических гипотез 4. МЕТОДЫ ОЦЕНКИ ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ 4.1. Точечная оценка параметров распределения 5. АППРОКСИМАЦИЯ ЗАКОНА РАСПРЕДЕЛЕНИЯ ЭКСПЕРЕМЕНТАЛЬНЫХ ДАННЫХ 5.1. Задачи аппроксимасимации Популярное:
|
Последнее изменение этой страницы: 2016-06-05; Просмотров: 1351; Нарушение авторского права страницы
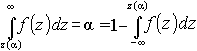 , рис. 3.3.
, рис. 3.3.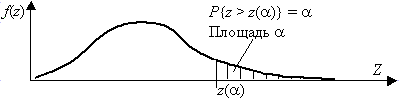
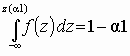 ,
, 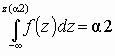 . Для симметричной функции плотности распределения f(z) критическую область выбирают из условия a 1=a 2=a /2 (обеспечивается наибольшая мощность критерия). В таком случае левая и правая границы будут равны |z(a /2)|.
. Для симметричной функции плотности распределения f(z) критическую область выбирают из условия a 1=a 2=a /2 (обеспечивается наибольшая мощность критерия). В таком случае левая и правая границы будут равны |z(a /2)|.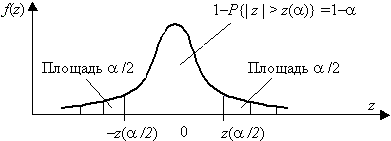
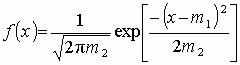
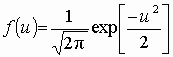 .
.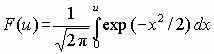 , u > 0.
, u > 0. квадратов n стандартизованных случайных величин ui, каждая из которых распределена по нормальному закону, причем k из них независимы, n ³ k. Функция плотности распределения хи-квадрат с k степенями свободы
квадратов n стандартизованных случайных величин ui, каждая из которых распределена по нормальному закону, причем k из них независимы, n ³ k. Функция плотности распределения хи-квадрат с k степенями свободы , x ³ 0,
, x ³ 0, 
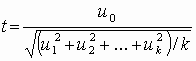 , где u0, u1, …, uk взаимно независимые нормально распределенные случайные величины с нулевым средним и конечной дисперсией. Аргумент t не зависит от дисперсии слагаемых. Функция плотности распределения Стьюдента
, где u0, u1, …, uk взаимно независимые нормально распределенные случайные величины с нулевым средним и конечной дисперсией. Аргумент t не зависит от дисперсии слагаемых. Функция плотности распределения Стьюдента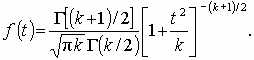
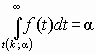 или двусторонней
или двусторонней  критической области.
критической области.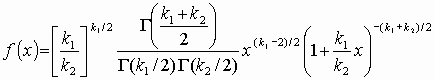 .
.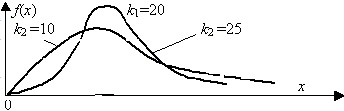
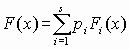 , где s – количество выборок, выбранное исходя из требований унимодальности распределения; pi – вероятность принадлежности элемента выборки к выборке i; Fi(x) – функция распределения выборки i.
, где s – количество выборок, выбранное исходя из требований унимодальности распределения; pi – вероятность принадлежности элемента выборки к выборке i; Fi(x) – функция распределения выборки i.