|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Два правила целостности для РБД .Стр 1 из 4Следующая ⇒
Таблицы
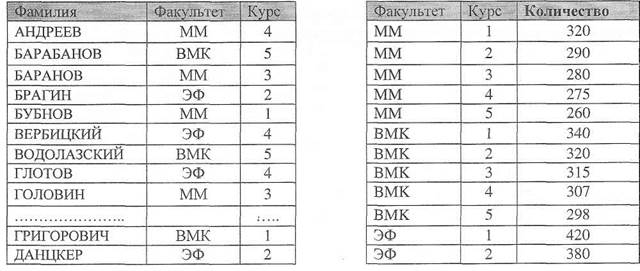
В реляционной базе данных информация организована в виде таблиц. Таблицы в реляционной базе данных разделены на строки {записи, кортежи) и столбцы {поля, атрибуты), на пересечении которых содержатся значения данных. У каждой таблицы имеется уникальное имя, описывающее ее содержимое. Строки ни имени, ни номера не имеют. Столбцы таблицы обязаны иметь имена (Рис. 3).
• Каждая горизонтальная строка таблицы представляет отдельную физическую ха • Каждый вертикальный столбец таблицы представляет один элемент данных.
У каждого столбца в таблице есть свое имя, которое обычно служит заголовком столбца. Все столбцы в одной таблице должны иметь уникальные имена, однако разрешается присваивать одинаковые имена столбцам, расположенным в различных таблицах. В стандарте ANSI/ISO не указывается максимально допустимое число столбцов в таблице, однако почти во всех коммерческих БД этот предел существует и обычно составляет примерно 255 столбцов. В отличие от столбцов, строки таблицы не имеют определенного порядка. Это значит, что если последовательно выполнить два одинаковых запроса для отображения содержимого таблицы, нет гарантии, что оба раза строки будут перечислены в одном и том же порядке. В таблице может содержаться любое количество строк. Допускается существование таблицы с нулевым количеством строк. Такая таблица называется пустой. Пустая таблица сохраняет структуру, определенную ее столбцами, просто в ней не содержатся данные. Стандарт ANSI/ISO не накладывает ограничений на количество строк в таблице, и во многих БД размер таблиц ограничен лишь свободным дисковым пространством компьютера. В других БД имеется максимальный предел, однако он весьма высок - около двух миллиардов строк, а иногда и больше.
Любой объект, информацию о котором мы хотим разместить в РБД, называется сущностью. Каждая сущность характеризуется определенным набором данных. Для хранения этого набора и создается соответствующая таблица. Таблица является хранилищем информационной сущности. Правила хранения информации рассматриваются ниже в разделе «Целостность реляционных данных». Сущности подразделяют на три основных класса: 1. стержни - это независимые сущности. Например, таблица «Факультеты». 2. ассоциации - это связи между двумя и более сущностями. Например, таблицы 3. характеристики - это сущности, цель которых описание или уточнение других Ассоциации и характеристики не являются независимыми, поскольку они предполагают существование некоторой другой сущности или сущностей, которые будут ассоциироваться или характеризоваться. Правила отношений сущностей рассматриваются в разделе «Реляционные отношения между таблицами (сущностями)». Целостность реляционных данных Ключи Понятие первичного ключа По математическому определению, множество не может содержать одинаковых элементов. Так как таблица является множеством (строк), то она не может содержать одинаковые строки. Поэтому каждая таблица реляционной БД должна содержать один или несколько столбцов, все значения или комбинации значений которых различны. Определение первичного ключа
В таблице представленной на Рис. 5 первичным ключом является поле Код. В этом поле ни одно из значений не повторяется, т.е. содержит множество различных значений. В то же время поле Факультет не может быть первичным ключом, так как содержит повторяющиеся значения (ФФ, ФФ).
Рис.5 Требования, предъявляемые к первичному ключу Первичный ключ должен отвечать двум требованиям: уникальность и минималь ность. Пусть имеется таблица со столбцами А\, А2.... Ап. Уникальность предполагает, что в произвольный момент времени никакие две различные строки таблицы не имеют одни и те же значения для А/, А/,..., А&.
Пример: На Рис. 6 первичными ключами для Таблицы 1 предполагаются поля Код и Номер. Тогда для левой таблицы Правила уникальности и минимальности нарушены, а для правой соблюдены. Таблица 1 Таблица 1 Понятие внешнего ключа Для объяснения понятия - внешний ключ, наша БД должна состоять как минимум из двух таблиц Рис. 7. Определение внешнего ключа
Внешний ключ и соответствующий ему первичный ключ должны быть одного типа данных или иметь одну и ту же область определения, например множество целых чисел. Т1
Рисунок 7
Все значения поля «Код Факультета» Т2 соответствуют значениям поля «Код Факультета» Т1. Первичный и внешний ключи необходимы для установления отношений между таблицами их содержащими. Об этом смотри далее. Реляционные отношения между таблицами Между двумя и более таблицами могут существовать отношения подчиненности.
Соответствие записей определяется первичным и внешним ключом
• один к одному; • один ко многим; • многие ко многим. Отношение «один к одному» Отношение «один к одному» это когда одной записи таблицы Т1 (родительской) соответствует одна запись таблицы Т2 (дочерней) (Рис. 8).
Рис. 8 Одной из причин, по которой создают связь один к одному является желание не создавать слишком громоздкую таблицу из-за второстепенной информации. Связь «один к одному» может быть жесткой и нежесткой. Для жесткой связи одной записи в родительской таблице должна существовать одна запись в дочерней таблице. Для нежесткой связи, запись в дочерней таблице может отсутствовать. Данный вид отношений («один к одному») применяется редко. Отношение «один ко многим» Отношение «один ко многим» имеет место, когда одной записи таблицы Т1 (родительской) соответствует несколько записей таблицы Т2 (дочерней) (Рис. 9). На рис. 9 представлена БД, состоящая из двух таблиц «Факультеты» - родительская и «Студенты» - дочерняя.
5-
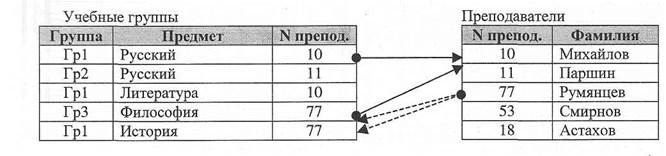
Рис. 9 Различают две разновидности отношений «один ко многим»: 1. любой записи в родительской таблице соответствует одна или несколько записей 2. записи в родительской таблице может несколько записей в дочерней таблице или Связь «один ко многим» является самой распространенной и позволяет создавать иерархическую структуру данных. Отношение «многие ко многим» Отношение «многие ко многим» имеет место, когда: 1. записи в родительской таблице могут соответствовать несколько записей в дочер 2. записи в дочерней таблице могут соответствовать несколько записей в родитель
Рис. 10 Как показано на Рис. 10 каждой учебной группе соответствует несколько преподавателей. Каждый из них может преподавать в разных группах и разные предметы. Считается, что связь «многие ко многим» может быть заменена на несколько связей «один ко многим». Не все БД поддерживают данный вид отношений.
Правила целостности Правила внешних ключей Под целостностью реляционной БД (в дальнейшем РБД) следует понимать выполнение одного из двух правил: 1. Каскадное удаление 2. Ограниченное удаление
Пусть из таблицы «Факультеты», удаляется строка с кодом факультета 3 (pk). Это приводит к удалению из таблицы «Студенты» всех записей, у которых внешний ключ равен 3(fk).
Рис. 13 Аналогично формулируются правила обновления данных в таблицах РБД. Нормализация таблиц Нормализация таблиц - это набор правил по составлению таблиц в целях устранения избыточности данных и приведения таблицы к третьей нормальной форме (ЗНФ). При практической разработке БД рассматривают 3 основные формы: ЩФ, 2НФ, ЗНФ. Дополнительные сведения Запрос на создание таблицы можно использовать для архивирования записей, создания резервных копий таблицы, копий для экспорта в другую базу данных, а также в качестве основы отчета, отображающего данные за конкретный период времени. Например, можно создать отчет «Ежемесячные продажи по областям», выполняя каждый месяц один и тот же запрос на создание таблицы. Примечания • При создании таблицы поля в новой таблице наследуют типы данных и размеры • Чтобы узнать, какие записи будут отобраны при выполнении запроса на создание таблицы, сначала просмотрите результаты инструкции SELECT, использующей те же условия отбора. Новая Таблица.
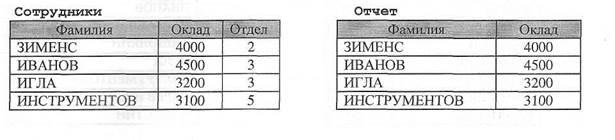
Пример: SELECT Фамилия, Оклад INTO Отчет FROM Сотрудники;
Сортирует записи, полученные в результате запроса, в порядке возрастания или убывания на основе значений указанного поля или полей. Синтаксис SELECT список Полей FROM таблица WHERE условие Отбора
поле1, поле2............... Имена полей, по которым сортируются записи. ASC......................... сортировки по возрастанию (от «А» до «Я» и от 0 до 9). DESC....................... сортировки по убыванию (от «Я» до «А» и от 9 до 0). По умолчанию используется порядок сортировки по возрастанию (от «А» до «Я» и от 0 до 9).
Обе приведенные ниже инструкции SQL одинаково сортируют записи по фамилиям сотрудников: SELECT Фамилия ORDER BY Фамилия ASC; SELECT Фамилия ORDER BY Фамилия; Пример (Сортировка по Окладу, а затем по Фамилии) SELECT Фамилия, Оклад FROM Сотрудники ORDER BY Оклад DESC, Фамилия; Сотрудники Отчет
Предложение WHERE Определяет, какие записи из таблиц, перечисленных в предложении FROM, следует включить в результат выполнения инструкции SELECT. Синтаксис SELECT имена полей FROM имена таблиц WHERE Условие Отбора; Элемент Условие Отбора Описание Выражение, которому должны удовлетворять записи, включаемые в результат выполнения запроса. Предложение WHERE не является обязательным, однако, если оно присутствует, то должно следовать после предложения FROM. Операции отношения Простой отбор. Операции отношения ( =, <, >, о, > =, < = ) Допускается использование различных операций отношения. > больше, < = меньше или равно, > = больше или равно, о не равно. 1. Следующая инструкция SQL отбирает всех сотрудников, зарплата которых превышает 10 000 рублей: SELECT Фамилия, Оклад FROM Сотрудники WHERE Оклад > 10000; 2. Отобрать всех сотрудников отдела продаж SELECT Фамилия FROM Сотрудники WHERE Отдел = " Продажи"; Пример: SELECT Фамилия, Оклад FROM Сотрудники WHERE Оклад > = 4000 Сотрудники
Применение AND, OR Выдать записи, если возраст человека лежит в диапазоне больше 22 или больше 50.
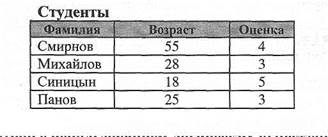
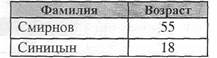
Пример: SELECT [Фамилия], Возраст FROM Сотрудники WHERE ((Возраст > 22) And (Возраст < 30)) Or Возраст > 50;
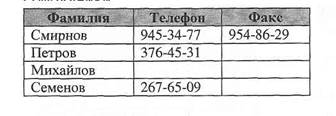
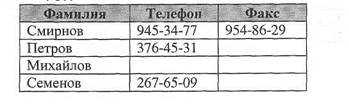
Пример Показать фамилии сотрудников не имеющих телефона. SELECT Фамилия, Телефон FROM Сотрудники
WHERE Телефон IS NULL; Сотрудники
Показать фамилии сотрудников имеющих факс.
SELECT Фамилия, Факс FROM Сотрудники WHERE Факс IS NOT NULL; Сотрудники
Применение BETWEEN... AND / (NOT BETWEEN...AND). Определяет принадлежность значения выражения указанному диапазону. Синтаксис SELECT имена полей FROM имена таблиц WHERE выражение [Not] Between значение1 And значение2; 1. Выдать записи, если возраст человека лежит в диапазоне от 22 до 30. Например: SELECT Фамилия, Возраст FROM Сотрудники WHERE Возраст BETWEEN 22 And 30;
2. Выдать записи, если возраст человека НЕ лежит в диапазоне от 22 до 30. Пример: SELECT Фамилия], Возраст FROM Сотрудники
WHERE Возраст NOT BETWEEN 22 And 30;
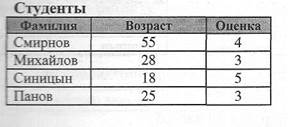
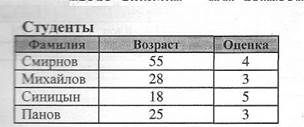
Применение IN (NOT IN) Проверяет, совпадает ли значение выражения с одним из элементов указанного списка. Синтаксис SELECT имена полей FROM имена таблиц WHERE выражение [Not] In (значение1, значенпе2.. ..) 1. Выдать записи, если возраст человека равен 18 или 55. Пример: SELECT Фамилия, Возраст FROM Сотрудники WHERE Возраст IN (18, 55);
Студенты
2. Выдать записи, если возраст человека НЕ равен 18 или 55. Пример: SELECT Фамилия, Возраст FROM Сотрудники WHERE Возраст NOT IN (18, 55);
Студенты
3. Выдать расписание поездов по вокзалам. Пример: SELECT Вокзал, Направление, День, Время FROM Расписание WHERE Вокзал NOT IN ('Киевский'); Поясните, какое расписание будет выдано? Онератор LIKE Используется для сравнения строкового выражения. Синтаксис SELECT имена полей FROM имена таблиц WHERE выражение Like " образец" Элемент Описание выражение Выражение SQL, используемое в предложении WHERE.
Дополнительные сведения Оператор Like используется для нахождения в поле значений, соответствующих указанному образцу. Для аргумента образец можно задавать полное значение (например, Like " Иванов" ) или использовать подстановочные знаки для поиска диапазона значений (например. Like " Ив*" )- Оператор Like используется в выражении для сравнения значений поля со строковым выражением. Например, если в запросе SQL ввести Like " с*", запрос возвратит все значения поля, начинающиеся с буквы " С". В запросе с параметрами можно пригласить пользователя, указать искомый образец. В следующем примере возвращаются данные, начинающихся с буквы «Р», за которой следуютлюбые буквы от «А» до «Д» и три цифры: Like " Р[А-Д]###" Следуюшая таблица содержит примеры использования оператора Like для тестирования выражений с помощью разных образцов. * - Любое количество, любых символов # - Одна, любая цифра
Работа с символами даты При указании аргумента Условие Отбора, символы дат должны вводиться в американском формате, даже если используется неамериканская версия ядра базы данных Jet. Например, дата 10 мая 1996 года записывается в России как 10.05.96, а в США как 5/10/96 Обязательно заключите даты в символы «решетки» (#), как показано в следующих примерах. Для отбора записей с этой датой в российской базе данных необходимо использовать следующую инструкцию SQL: SELECT * FROM Заказы WHERE ДатаИсполнения = #5/10/96#; Кроме того, можно применять функцию DateValue, которая поддерживает международные стандарты, заданные в Microsoft Windows®. Например, для отбора записей в американской базе данных создайте текст программы: SELECT * FROM Заказы WHERE ДатаИсполнения = DateValue('5/10/96'); Для российской базы данных, текст программы будет выглядеть так: SELECT * FROM Заказы WHERE ДатаИсполнения = DateValue('10.5.96');
Пример: SELECT [Наименование товара] AS Товар, Годность FROM Товары WHERE Годность < = #5/7/96#; ИТОГОВЫЙ ПРИМЕР Пусть имеется таблица Товары. Создать итоговую таблицу с наименованием товара и стоимостью не проданного товара при условии, что стоимость непроданного товара должна быть больше... SELECT Товар, (Количество * Цена) AS Стоимость INTO Итоговая FROM Таблица WHERE (Количество * Цена) > 500
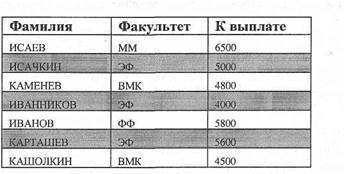
Таблица Итоговая Статистические функции Статические функции готовы к вьщаче готовых значений. К статистическим функциям относятся следующие функции: Синтаксис COUNT (выражение)........ вычисляет количество записей, возвращаемых запросом. SUM (выражение)............ возвращает сумму набора значений, содержащихся в за данном поле запроса. AVG (выражение)............ вычисляет арифметическое среднее набора чисел, содержащихся в указанном поле запроса. MIN (выражение)....... возвращают минимальное и максимальное значения из МАХ (выражение) набора значений, содержащихся в указанном поле запроса. Функция COUNT Вычисляет количество записей, возвращаемых запросом. Синтаксис SELECT Count (выражение) as.... таблица [WHERE...] Аргумент выражение является строковым выражением, которое определяет поле, содер-жащее данные для подсчета, или выражение, выполняющее вычисления с данными из юля. Операнды аргумента выражение могут включать имя поля таблицы или функцию. (Функция может быть внутренней или определяться пользователем, но не мо- жет быть другой статистической функцией SQL). Подсчитывать можно любые данные, включая текстовые. Дополнительные сведения Функцию Count используют для подсчета количества записей в базовом запросе. Count возвращает просто количество записей. Это значение не зависит от того, какие данные содержатся в этих записях. Count не подсчитывает записи со значениями Null, если только аргумент вы-ражение не содержит подстановочный знак звездочки (*). Если используются знаки звез- дочки, Count вычисляет общее количество записей, включая те, которые содер-жат пустые поля. Функция Count(*) работает значительно быстрее функции Сunt([Имя столбца].Не следует заключать символ звездочки в прямые кавычки (" " ). В следующем примере вычисляется количество записей в таблице «Заказы»: SELECT Count(*) AS ЧислоЗаказов FROMЗаказы; Следующий запрос подсчитывает количество студентов 104 группы. ELECT Count(Фамилия) AS [Студенты 104] FROM Студенты WHERE группа = 104; Если в аргументе выражение задано несколько полей, функция Count подсчитывает за- пись только в том случае, если хотя бы одно из полей не содержит значения Null. Если все указанные поля содержат значения Null, запись не подсчитывается. Для разделения имен полей используется символ (& ). В следующем примере демонстрируется способ ог- раничения числа записей теми записями, для которых поле «ДатаИсполнения» или поле " СтоимостьДоставки" не содержат пустые значения: SELECT Count('ДатаИсполнения в стоимость доставки' )AS [Not Null] FROMЗаказы; Статистические функции Статистические функции готовы к выдаче готовых значений. К статистическим функциям относятся следующие функции: Синтаксис • COUNT (выражение)...... вычисляет количество записей, возвращаемых запросом. • SUM ( выражение )........... возвращает сумму набора значений, содержащихся в за данном поле запроса. • AVG ( выражение ).......... вычисляет арифметическое среднее набора чисел, содержащихся в указанном поле запроса. • MIN ( выражение )............ возвращают минимальное и максимальное значения из МАХ ( выражение ) набора значений, содержащихся в указанном поле запроса. Функция COUNT Вычисляет количество записей, возвращаемых запросом. Синтаксис SELECT Count (выражение) as.... FROM таблица [WHERE...] Аргумент выражение является строковым выражением, которое определяет поле, содержащее данные для подсчета, или выражение, выполняющее вычисления с данными из этого поля. Операнды аргумента выражение могут включать имя поля таблицы или функцию. (Функция может быть внутренней или определяться пользователем, но не может быть другой статистической функцией SQL). Подсчитывать можно любые данные, включая текстовые. Дополнительные сведения Функцию Count используют для подсчета количества записей в базовом запросе. Функция Count возвращает просто количество записей. Это значение не зависит от того, какие данные содержатся в этих записях. Функция Count не подсчитывает записи со значениями Null, если только аргумент выражение не содержит подстановочный знак звездочки (*). Если используются знаки звездочки, функция Count вычисляет общее количество записей, включая те, которые содержат пустые поля. Функция Count(*) работает значительно быстрее функции Соunt([Имя столбца]). Не следует заключать символ звездочки в прямые кавычки (" " ). В следующем примере вычисляется количество записей в таблице «Заказы»: SELECT Count{*) AS ЧислоЗакаЗов FROM Заказы; Следующий запрос подсчитывает количество студентов 104 группы. SELECT Count(Фамилия) AS [Студенты 104] PROM Студенты WHERE группа = 104; Если в аргументе выражение задано несколько полей, функция Count подсчитывает запись только в том случае, если хотя бы одно из полей не содержит значения Null. Если все указанные поля содержат значения Null, запись не подсчитывается. Для разделения имен полей используется символ (& ). В следующем примере демонстрируется способ ограничения числа записей теми записями, для которых поле «ДатаИсполнения» или поле «СтоимостьДоставки» не содержат пустые значения: SELECT Count (' ДатаИсполнения & СтоимостьДоставки' )AS [Not Null] FROM Заказы; Функция SUM Возвращает сумму набора значений, содержащихся в заданном поле запроса. Синтаксис SELECT Sum (выражение) as.... FROM таблица [WHERE...] Аргумент выражение является строковым выражением, которое определяет поле, содержащее добавляемые числовые данные, или выражение, выполняющее вычисления с данными из этого поля. Операнды аргумента выражение могут включать: • имя поля таблицы, • константу, • или функцию. (Функция может быть внутренней или определяться пользователем, но не может быть другой статистической функцией SQL). Дополнительные сведения Функция Sum выполняет суммирование значений в поле. Функция Sum пропускает записи с полями, содержащими значения Null. Следующий запрос подсчитывает итоговую сумму раздаточной ведомости преподавателей Экономического факультета. SELECT Sum([К выплате])AS Итого FROM Ведомость WHERE Факультет = " ЭФ";
Ведомость
В следующем примере показано, как вычислить сумму произведений полей «Цена» и «Количество»: SELECT Sum(Цена * Количество)AS [ Доход] FROM Заказано; Функция AVG Вычисляет арифметическое среднее набора чисел, содержащихся в указанном поле запроса. Синтаксис SELECT Avg (выражение) as.... [WHERE...] Аргумент выражение является строковым выражением, которое определяет поле, содержащее числовые данные для вычисления среднего значения, или выражение, выполняющее вычисления с данными из этого поля. Операнды аргумента выражение могут включать: • имя поля таблицы, • константу, • или функцию. (Функция может быть внутренней или определяться пользователем, но не может быть другой статистической функцией SQL). Дополнительные сведения Среднее значение, вычисленное функцией Avg, является числовым значением (сумма значений, деленая на их количество). Функция Avg не включает в вычисления поля со значениями Null. Следующий запрос определяет средний балл 112 группы. SELECT AVG([Экзамен])AS [Cp балл] WHERE Группа - 112;
Функции MIN, MAX Возвращают минимальное и максимальное значения из набора значений, содержащихся в указанном поле запроса. Синтаксис
SELECT Min (выражение) as.... FROM таблица [WHERE...] Аргумент выражение является строковым выражением, которое определяет поле, содержащее обрабатываемые данные, или выражение, выполняющее вычисления с данными из этого поля. Операнды аргумента выражение могут включать: • имя поля таблицы, • константу, • или функцию. (Функция может быть внутренней или определяться пользователем, но не может быть другой статистической функцией SQL). Дополнительные сведения Функции Mm и Мах используются для определения наименьшего и наибольшего значений из поля на основе выборки или группировки. Например, можно применить эти функции для возврата наименьшей и наибольшей стоимости доставки. Если не указан способ группировки, используется вся таблица. Следующий запрос определяет максимальную зарплату. SELECT Маx([К выплате])AS Максимум FROM Ведомость WHERE Факультет = " ЭФ";
Предложение GROUP BY
Объединяет записи с одинаковыми значениями в указанном списке полей в одну запись. Если инструкция SELECT содержит статистическую функцию SQL, например Sum или Count, то для каждой записи будет вычислено итоговое значение. Синтаксис SELECT списокПолей FROM таблица [WHERE] условиеОтбора GROUP BY [группируемыеПоля] Ниже перечислены аргументы инструкции SELECT, содержащей предложение GROUP BY: группируемыеПоля Имена полей (до 10), которые используются для группировки записей. Порядок имен полей в аргументе группируемыеПоля определяет уровень группировки для каждого из этих полей.
Предложение GROUP BY является необязательным. Итоговые значения не рассчитываются, если инструкция SELECT не содержит статистической функции SQL. Значения Null, которые находятся в полях, заданных в предложении GROUP BY, группируются и не опускаются. Однако статистические функции SQL не обрабатывают значения Null. Используйте предложение WHERE для исключения записей из группировки, а предложение HAVING для применения фильтра к записям после группировки. При использовании предложения GROUP BY все поля в списке полей инструкции SELECT должны быть либо включены в предложение GROUP BY, либо использоваться в качестве аргументов статистической функции SQL. Следующий запрос анализирует экзаменационную оценочную ведомость и создает итоговую таблицу содержащую номер группы, количество студентов в группе и средний балл по предметам. SELECT Группа, Count(Гpyппa) as Колич, Avg(Эк) as [Ср б Эк], Avg(Инф)) as [Cp б Инф]
SELECT Факультет, Курс, Соunt(Фамилия) as Количество from Ведомость GROUP BY Факультет, Курс; Ведомость
Предложение HAVING Определяет, какие сгруппированные записи отображаются при использовании инструкции SELECT с предложением GROUP BY. После того как записи будут сгруппированы с помощью предложения GROUP BY, предложение HAVING отберет те из полученных записей, которые удовлетворяют условиям отбора, указанным в предложении HAVING. Синтаксис SELECT списокПолей FROM таблица WHERE условиеОтбора GROUP BY группируемыеПоля HAVING условиеГруппировки Ниже перечислены аргументы инструкции SELECT, содержащей предложение HAVING: Элемент группируемыеПоля Описание Имена полей (до 10), которые используются для группировки записей. Порядок имен полей в аргументе группируемыеПоля определяет уровень группировки для каждого из этих полей.
условиеГруппировки Выражение, определяющее, какие сгруппированные записи следует отображать. Предложение HAVING является необязательным. Популярное:
|
Последнее изменение этой страницы: 2016-07-13; Просмотров: 940; Нарушение авторского права страницы

 Рис. 3 Рис. 4
Рис. 3 Рис. 4 Все значения, содержащиеся в одном и том же столбце, являются данными одного типа (текст, число, дата,...)
Все значения, содержащиеся в одном и том же столбце, являются данными одного типа (текст, число, дата,...) Пересечение строки и столбца образует элементарное значение данных, которое является наименьшей единицей данных в РБД. Такие значения рассматриваются как атомарные, т.е. они неразложимы.
Пересечение строки и столбца образует элементарное значение данных, которое является наименьшей единицей данных в РБД. Такие значения рассматриваются как атомарные, т.е. они неразложимы. Сущности
Сущности Столбец, или совокупность столбцов, называется первичным ключом (primary key, обозначается pk), если все его значения, или комбинации значений, различны..
Столбец, или совокупность столбцов, называется первичным ключом (primary key, обозначается pk), если все его значения, или комбинации значений, различны.. Например:
Например:  Минимальность предполагает, что нп один из столбцов Аи А/, ..., А* не может быть изъят из ключа без нарушения условия уникальности.
Минимальность предполагает, что нп один из столбцов Аи А/, ..., А* не может быть изъят из ключа без нарушения условия уникальности.
 Внешний ключ (foreign key, обозначается fk) - это столбец таблицы Т2, любое значение которого должно обязательно совпадать с одним из значений первичного ключа некоторой другой таблицы Т1.
Внешний ключ (foreign key, обозначается fk) - это столбец таблицы Т2, любое значение которого должно обязательно совпадать с одним из значений первичного ключа некоторой другой таблицы Т1.

 Отношение подчиненности определяет, что для каждой записи одной таблицы (Т1), существуют одна или несколько записей в другой таблице (Т2). При этом таблица Т1 именуется родительской, а таблица Т2 - дочерней.
Отношение подчиненности определяет, что для каждой записи одной таблицы (Т1), существуют одна или несколько записей в другой таблице (Т2). При этом таблица Т1 именуется родительской, а таблица Т2 - дочерней. Существует три разновидности связи между таблицами БД:
Существует три разновидности связи между таблицами БД: 
 В родительской таблице поле Код_Факультета является первичным ключом, а в дочерней одноименное поле является внешним ключом. Между этими таблицами должны быть соблюдены правила целостности (смотри ниже).
В родительской таблице поле Код_Факультета является первичным ключом, а в дочерней одноименное поле является внешним ключом. Между этими таблицами должны быть соблюдены правила целостности (смотри ниже). Как видим, одной записи родительской таблицы соответствует несколько записей дочерней таблицы (Рис. 9). Не исключено, что в дочерней таблице может и не быть записей соответствующих записи в родительской таблице (например: нет студентов на химическом факультете (ХФ)).
Как видим, одной записи родительской таблицы соответствует несколько записей дочерней таблицы (Рис. 9). Не исключено, что в дочерней таблице может и не быть записей соответствующих записи в родительской таблице (например: нет студентов на химическом факультете (ХФ)).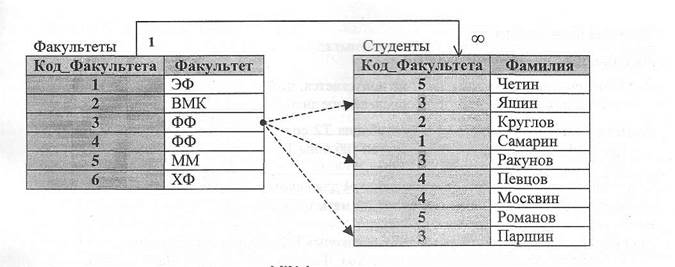
 Каскадное удаление: при удалении строки из таблицы Т1 удаляются также все строки из таблицы Т2, соответствующие строке из Т1 по внешнему ключу.
Каскадное удаление: при удалении строки из таблицы Т1 удаляются также все строки из таблицы Т2, соответствующие строке из Т1 по внешнему ключу.
 Ограниченное удаление: при попытке удаления строки из таблицы Т1 проверяется наличие в таблице Т2 строк, соответствующих строке из Т1 по внешнему ключу. Если такие строки в таблицах Т2 имеются, то удаление отвергается.
Ограниченное удаление: при попытке удаления строки из таблицы Т1 проверяется наличие в таблице Т2 строк, соответствующих строке из Т1 по внешнему ключу. Если такие строки в таблицах Т2 имеются, то удаление отвергается. Пример каскадного удаления (Рис. 13).
Пример каскадного удаления (Рис. 13).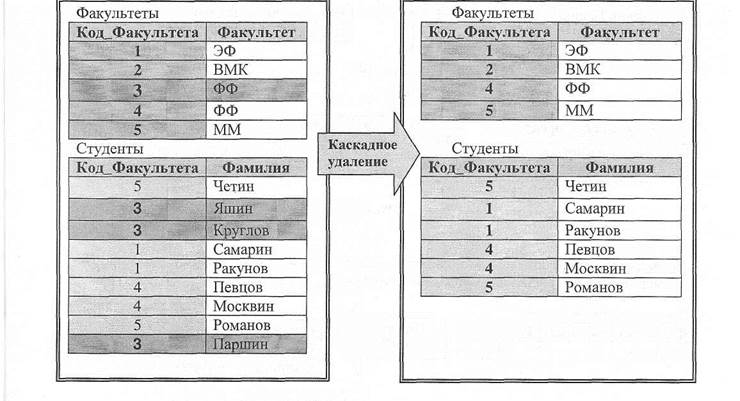
 Предложение ORDER BY
Предложение ORDER BY 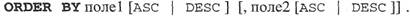
 Предложение ORDER BY может содержать несколько полей. Сначала записи сортируются по первому полю в списке ORDER BY. Затем записи, имеющие совпадающие значения в первом поле, сортируются по второму полю и т.д.
Предложение ORDER BY может содержать несколько полей. Сначала записи сортируются по первому полю в списке ORDER BY. Затем записи, имеющие совпадающие значения в первом поле, сортируются по второму полю и т.д. Предложение ORDER BY является необязательным. Однако оно необходимо для отображения данных в порядке сортировки.
Предложение ORDER BY является необязательным. Однако оно необходимо для отображения данных в порядке сортировки.















 Дополнительные сведения
Дополнительные сведения 

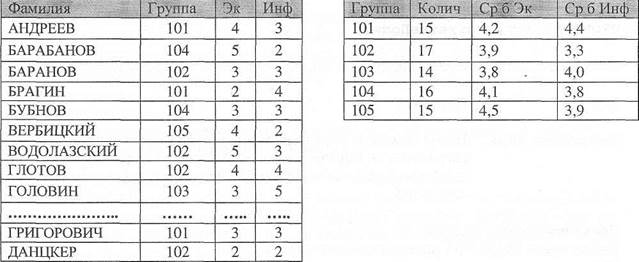
 Следующий пример подсчитывает количество студентов в МГУ, обучающихся на каждом факультете по курсам обучения.
Следующий пример подсчитывает количество студентов в МГУ, обучающихся на каждом факультете по курсам обучения.