
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Кафедра «Прогнозирования и статистики экономическихСтр 1 из 10Следующая ⇒
Кафедра «Прогнозирования и статистики экономических И социальных процессов»
Петров А.П.
Статистика Учебное пособие
Санкт-Петербург Содержание Модуль 1. Общие вопросы статистики ………...………………………......4 Блок 1. Предмет и метод статистики ……………………………………4 Блок 2. Статистическое наблюдение ………………………………........7 Блок 3. Статистическая информация и показатели..………………….11 Модуль 2. Обобщение статистических данных ………………………......13 Блок 4. Статистические: сводка, группировка, классификации, таблицы, графики ………………………………………………13 Блок 5. Статистические ряды распределения ………………………….20 Модуль 3. Относительные величины, вариация признаков……………….24 Блок 6. Абсолютные и относительные величины, средние величины ………………………………………..……..24 Блок 7. Структурные средние ………………………………………......31 Блок 8. Показатели вариации ……………………………………………33 Блок 9. Изучение формы распределения ……………………………….38 Модуль 4. Выборочное наблюдение ……………………………………….40 Блок 10. Содержание выборочного наблюдения, ошибки выборочного наблюдения ………………………………………40 Блок 11. Малая выборка …………………………………………………47 Модуль 5. Статистические методы прогнозирования процессов ………..50 Блок 12. Ряды динамики, исследование основных тенденций развития явлений ………………………………………………..50 Блок 13. Прогнозирование на основе изучения тренда ………………..60 Модуль 6. Индексный метод ………………………………………………..63 Блок 14. Понятие индекса, виды индексов ……………………………..63 Блок 15. Индексы средних величин …………………………………….68 Модуль 7. Статистический анализ связей явлений …………..………....72 Блок 16. Виды связей явлений ………………………………………..72 Блок 17. Методы регрессионно-корреляционного анализа связи показателей, критерии согласия …………………….75 Приложение 1. Основные формулы………………………………….…..82 Приложение 2. Вспомогательная таблица ………………………….…...86 Приложение 3. Перечень вопросов для подготовки к экзамену……..…87 Приложение 4. Список литературы …………………………………..….90
Модуль 1. Общие вопросы статистики Блок 3. Статистическая информация и статистические показатели Статистическая информация – это первичный статистический материал, формирующийся в ходе статистического наблюдения, который затем систематизируется, сводится, обрабатывается, анализируется и обобщается. Важными условиями качественного использования статистической информации являются ее: массовость, систематичность получения и обработки, а также возможность длительного ее хранения на различных носителях. Статистическая информация может быть подразделена по: - месту возникновения; - принадлежности к отраслям экономики; - способу передачи; - периодичности поступления. Статистический показатель представляют собой обобщенную количественную характеристику явлений и процессов в тесной увязке с их особенностями в конкретных условиях места и времени. Показатели имеют количественную и качественную стороны. Количественная сторона определяет конкретный размер показателя, его величину, а качественная сторона показателя отражает его содержательную часть. Совокупность показателей, всесторонне отражающих развитие явления, образуют систему показателей. Социально-экономические индикативные показатели выступают в роли индикаторов, характеризующих состояние развития экономики в целом, отдельных отраслей. Такие показатели дают представление об уровне развития страны в динамике по сравнению с другими странами, отдельных регионов в рамках одной страны. Эти показатели являются основой для построения прогнозов развития по различным отраслям экономики, к ним относятся: - площадь территории; - численность населения; - валовой внутренний продукт (ВВП); - объем экспорта и импорта; - среднегодовая численность занятых и безработных; - среднемесячная начисленная заработная плата; - денежные доходы и расходы населения; - средний уровень образования. Индикативными показателями могут выступать и интегральные показатели, которые выражают уровень социально-экономического развития отдельных регионов и страны в целом. Существуют и применяются различные системы оценки уровня жизни населения. Например, рабочая группа по социальной статистике ООН предлагала в качестве таких показателей национальный доход на душу населения, долю расходов на питание в общих расходах домохозяйств, относительный коэффициент смертности и т.д. Единого, универсального показателя пока не выработано.
Модуль 2. Обобщение статистических данных Модуль 3. Относительные величины, вариация признаков Блок 7. Структурные средние Структурные средние характеризуют структуру рядов распределения. К структурным средним относятся мода и медиана. Мода (Мо) – значение признака, которое наиболее часто встречается в изучаемой совокупности. В дискретном ряду мода – это варианта с наибольшей частотой. В интервальном вариационном ряду мода определяется по формуле:
где Модальный интервал – интервал, имеющий наибольшую частоту (частость). Например, среднедушевые доходы городского населения распределись следующим образом (табл.6). Таблица 6
Рассчитаем модальное значение среднедушевых доходов населения города:
Наиболее частое значение среднедушевых доходов – 13125 рублей. Медиана (Ме) - это величина, которая делит численность упорядоченного вариационного ряда на две равные части – одна часть меньше, чем средний вариант, а другая больше. Для ранжированного ряда с нечетным числом членов медианой является варианта, расположенная в центре ряда. Например, стажи работы специалистов в туристской фирме – 1, 2, 2, 3, 3, 4, 5 лет – медианой является четвертая варианта – 3 года. Для ранжированного ряда с четным числом членов ряда медианой будет средняя арифметическая из двух смежных вариант, находящихся в середине ряда. Например, сотрудники туристской фирмы имеют следующие стажи работы по специальности: 2, 2, 3, 4, 4, 6 лет – медианой является значение, равное: (3+4): 2=3, 5 года. Чтобы определить медиану, необходимо найти ее порядковый номер, а затем по накопленным частотам (частостям) определить величину варианта, обладающего таким номером. Для определения медианного значения в интервальном ряду используется следующая формула:
где, Медианный интервал – интервал, в котором находится порядковый номер медианы. Для его определения подсчитывают суммы накопленных частот (частостей) до числа, превышающего половину объема совокупности. Медианное значение среднедушевых доходов населения города составит:
Аналогичным образом могут быть рассчитаны четверти общего ряда – квартили, десятые доли – децили, сотые доли – процентили. Блок 8. Показатели вариации Различие индивидуальных значений признака внутри изучаемой совокупности называется вариацией признака. Колеблемость отдельных значений характеризуют показатели вариации. Различают вариацию признака случайную и систематическую. Анализ вариации позволяет оценить ее характер и определить насколько однородной является изучаемая совокупность и насколько характерной является ее средняя величина для данной совокупности. Выделяют абсолютные и средние показатели вариации. Наиболее простой – размах вариации (R) – разность между наибольшим и наименьшим значением признака в распределении: R= Для получения обобщенной характеристики отклонений от средней рассчитывают среднее линейное отклонение На практике вариацию чаще оценивают с помощью показателя дисперсии Если из дисперсии извлечь корень квадратный, то получится еще один показатель вариации – среднее квадратическое отклонение:
Коэффициент осцилляции характеризует относительную колеблемость крайних значений признака вокруг средней:
Относительное линейное отклонение характеризует долю усредненного значения абсолютных отклонений от средней величины:
Наиболее распространенный показатель колеблемости, который дает обобщающую характеристику – коэффициент вариации:
Рассмотрим пример, где оценивается вариация стажа работы по специальности работников двух турфирм: 1-я 2-я 1 4 2 4 3 5 4 5 4 5 9 7 10 7 12 7 45 лет 45 лет Проведем предварительные расчеты:
Сопоставим показатели вариации стажа работников у двух турфирм. 1-я фирма 2-я фирма
При одинаковых средних величинах стажа работников фирм вариация признака в первой фирме в три раза выше, чем в первой. Преобразование формулы среднего квадратического отклонения приводит ее к виду Дисперсия альтернативного признака характеризует вариацию альтернативных признаков. Альтернативными признаками являются признаки, которыми обладают одни единицы изучаемой совокупности и не обладают другие. Например, в фирме работают мужчины и женщины, доля мужчин (р) и доля женщин (q) образуют целый коллектив сотрудников фирмы: p +q = 1. Средняя величина для альтернативных признаков равна Правило сложения дисперсий. Если совокупность варьирующих элементов подразделить на несколько групп, то можно выделить: общую дисперсию ( Общая дисперсия характеризует колеблемость признака во всей изучаемой совокупности и рассчитывается по формуле:
Внутригрупповая дисперсия характеризует колеблемость признака внутри группы и рассчитывается по формуле:
Средняя из внутригрупповых характеризует внутригрупповую колеблемость вокруг внутригрупповых средних и рассчитывается как средняя величина из внутригрупповых дисперсий:
Межгрупповая дисперсия показывает вариацию групповых средних вокруг общей средней, измеряет вариацию изучаемого признака под влиянием признака - фактора (группировочного признака) и рассчитывается по формуле:
Между всеми приведенными дисперсиями существует взаимосвязь, которая называется правилом сложения дисперсий – общая дисперсия равна сумме средней из внутригрупповых дисперсий и межгрупповой дисперсии:
Логика этого правила следующая: общая дисперсия, возникающая под влиянием всех факторов, должна быть равна сумме дисперсий, возникающих под влиянием всех прочих факторов, и дисперсии возникающей за счет фактора группировки. Зная два вида дисперсий, всегда можно определить или проверить правильность расчета третьего вида дисперсии. Например, имеются данные по среднедневной выработке сотрудников фирмы с различным стажем работы:
В статистике применяется показатель, представляющий собой долю межгрупповой дисперсии в общей дисперсии, который показывает, какая часть общей вариации изучаемого признака обусловлена вариацией группировочного признака. Это коэффициент детерминации, рассчитываемый по формуле: Если извлечь корень квадратный из коэффициента детерминации, получаем новый показатель, который носит название корреляционное отношение:
Блок 10. Содержание выборочного наблюдения, ошибки выборочного наблюдения Мы уже знаем, что если возникает необходимость проведения наблюдения, то оно может проводиться как сплошное наблюдение, когда обследуются все без исключения единицы наблюдения и как несплошное наблюдение, когда обследуется только определенная часть общей совокупности. Выборочное наблюдение – основной вид из ряда способов несплошного наблюдения. Выборочным называется наблюдение заранее определенного числа единиц совокупности, отобранных в особом порядке. Выборочный метод исследования предполагает получение обобщающих показателей изучаемой совокупности по обследованной ее части. При этом подлежащая исследованию совокупность называется генеральной совокупностью, а отобранная из генеральной совокупности ее часть называется выборочной совокупностью . Выборочный метод позволяет при минимальной численности обследуемых единиц получить объективные характеристики всей изучаемой совокупности. Это особенно актуально в современных условиях, когда сплошные наблюдения дороги и не всегда эффективны. Теория и опыт показали, что при правильной организации выборочного наблюдения можно получить достоверные данные о изучаемой совокупности. Эти данные (абсолютные и относительные) достаточно точно воспроизводят – репрезентируют всю совокупность. Выборочные наблюдения практикуются во всех видах социальной и экономической деятельности. Для более глубокого изучения выборочного метода введем некоторые условные обозначения: N – объем генеральной совокупности – число входящих в нее единиц; n - объем выборочной совокупности – число единиц, попавших в выборку;
р - генеральная доля – доля единиц, обладающих данным признаком в генеральной совокупности; w - выборочная доля – доля единиц, обладающих данным признаком в выборочной совокупности;
Предельная ошибка выборки Средняя ошибка выборки используется для определения возможных отклонений показателей выборочной совокупности от соответствующих показателей генеральной совокупности. С определенной вероятностью можно утверждать, что эти отклонения не превысят заданной величины
С увеличением t величина вероятности Основные виды выборки Индивидуальный отбор единиц наблюдения должен производиться из генеральной совокупности таким образом, чтобы обеспечить всем единицам одинаковую возможность попасть в выборку. Если это условие соблюдается, то это собственно случайная выборка . Если совокупность разбивается на однородные группы единиц, из которых производится индивидуальный отбор, то это типичная или районированная выборка. Если вместо индивидуального отбора выбираются серии единиц и в них производится сплошное наблюдение, то это Отбор единиц наблюдения из общей совокупности может производиться повторно и бесповторно. Повторный отбор предполагает, что каждая единица наблюдения может принять участие в отборе несколько раз, т.е. каждый раз при отборе единица возвращается в общую совокупность. При бесповторном отборе выбранная единица не участвует в дальнейшем отборе. При расчете ошибок возникает существенное затруднение – величины
По данным вышеприведенного примера рассчитаем предельную ошибку выборки c вероятностью 0, 954 при бесповторном отборе: N=1000, n=200, 1. для средней 2. для доли С вероятностью 0, 954 можно утверждать, что разность между выборочной средней и генеральной средней не превышает по абсолютным размерам - 0, 13 тыс. рублей, а между частостью и долей - 0, 0475. Доверительный интервал, в котором может находиться средняя и доля:
Для нашего примера доверительный интервал: 13, 99-0, 13 0, 83-0, 0475 На практике часто ставится задача определения объема выборочной совокупности при заранее заданной предельной ошибке выборки. В этом случае используются формулы, выведенные из формул ошибок выборки:
При определении n точные данные о генеральной дисперсии, как правило, не известны, поэтому используют данные прежних обследований и их дисперсий. При полном отсутствии данных вариации альтернативного признака вместо pq подставляют максимальное значение дисперсии – 0, 25. По данным вышеприведенного примера рассчитаем объем необходимой выборки. Необходимо определить, какое количество сделок нужно отобрать для выборочного наблюдения, чтобы ошибка выборки с вероятностью 0, 954 не превышала 0, 1 тыс. рублей для средней и 3% для доли при бесповторном отборе. Для решения этой задачи имеем следующие условия: N=1000; Для определения средней доходности сделок:
При заданных условиях для определения средней величины доходности сделок необходимо отобрать информацию о не менее 304 сделках, а для определения доли сделок с доходностью 14 и более тыс. рублей необходимо отобрать информацию о не менее 416 сделках. Блок 11. Малая выборка Малая выборка – это несплошное статистическое наблюдение, при котором выборочная совокупность образуется из сравнительно небольшого числа единиц генеральной совокупности. Обычно объем малой выборки не превышает 30 единиц, а минимальный объем может доходить до 4-5 единиц. В отдельных случаях к малой может быть отнесена выборка до 45 единиц. Малая выборка широко применяется в экономических исследованиях и при организации контроля качества товаров и услуг. Средняя ошибка малой выборки определяется по формуле:
Предельная ошибка малой выборки рассчитывается по формуле:
Для проведения малой выборки в качестве доверительной вероятности принимается 0, 95 и 0, 99. Для определения предельной ошибки малой выборки используют распределения Стьюдента и определяют коэффициент доверия t:
Пример. При анализе прибыли по сделкам, совершенным фирмой в течение года, была сделана выборка и установлена по ним прибыльность в %: 4, 5; 5, 0; 4, 2; 3, 5; 6, 0; 5, 2; 4, 5; 5, 2; 4, 3; 6, 6. Нужно по данным выборочного наблюдения установить с вероятностью 0, 95 предел, в котором находится средняя прибыльность сделок, по результатам работы фирмы за год. Средняя прибыльность сделок по данным малой выборки:
Определяем среднюю ошибку малой выборки:
Находим предельную ошибку малой выборки. Для этого по распределению Стьюдента при заданной вероятности
Следовательно, с вероятностью 0, 95 можно утверждать, что средняя годовая прибыльность сделок фирмы находится в пределах:
Характеристики динамики Для количественной оценки динамики развития явлений используются статистические показатели динамики: абсолютные приросты, темпы роста и прироста, которые дают характеристику направления и размер изменений явления во времени. Рассмотрим условный пример с потоками туристов в регион в течение ряда лет:
Средний уровень динамики для интервальных рядов представим как Для моментных рядов фиксируется состояние явления на определенный момент, это могут быть данные на начало или конец какого-либо периода (например, по состоянию на 1 января текущего года). Средний уровень здесь определяется как средняя арифметическая из двух этих показателей. Например, численность работников турфирмы на 1 января.
60 человек на 1 января 2003 г. – это одновременно численность работников фирмы на 31 декабря 2002 г. Поэтому средняя численность работников: за 2003 г. за 2005г. Средняя численность за период составила Средний уровень моментного ряда рассчитывается также по средней хронологической:
Например, имеются данные о числе гостей в отеле по состоянию на начало квартала в течение 2005 года.
Средняя численность гостей в течение года:
В динамических рядах определяют вариацию динамики по формулам:
С помощью простейших показателей определим направление и размер изменений уровней во времени по данным потоков туристов в регионе в течение ряда лет:
Исследование тенденций развития явлений Изменение уровней рядов динамики связано с влиянием на изучаемое явление множества факторов, которые различны по силе воздействия, направлению и времени их действия. Постоянно действующие факторы оказывают на явление определяющее воздействие и формируют в рядах динамики основное направление развитие – тренд. Воздействие других факторов, как правило, периодическое и вызывает колебания уровней рядов динамики. Определенное воздействие на динамику развития явления могут оказывать отдельные случайные (спорадические) факторы. Воздействие постоянных, периодических и разовых причин на уровни динамики развития явления вызывает необходимость изучения этих факторов для определения тренда, периодических колебаний и случайных отклонений. Простейший способ обработки динамического ряда с целью выявления тенденции его развития заключается в укрупнении интервалов времени. Предположим, имеются данные о количестве гостей в отеле по месяцам в течение года:
Укрупнив интервалы, устранили случайные колебания и проявили основную тенденцию сезонных колебаний в потоке гостей в течение года. Популярное:
|
Последнее изменение этой страницы: 2016-08-24; Просмотров: 785; Нарушение авторского права страницы
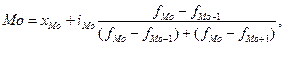
 нижняя граница модального интервала;
нижняя граница модального интервала; 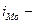 величина модального интервала;
величина модального интервала;  частоты модального, домодального и послемодального интервалов.
частоты модального, домодального и послемодального интервалов. тыс. руб.
тыс. руб.
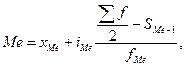
 нижняя граница медианного интервала;
нижняя граница медианного интервала;  - величина медианного интервала;
- величина медианного интервала; 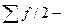 полусумма частот ряда;
полусумма частот ряда;  - сумма накопленных частот, предшествующих медианному интервалу;
- сумма накопленных частот, предшествующих медианному интервалу; 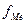 - частота медианного интервала.
- частота медианного интервала. тыс. руб.
тыс. руб. .
.
 для несгруппированных данных и для вариационного ряда
для несгруппированных данных и для вариационного ряда  показатель учитывается без знака этих отклонений.
показатель учитывается без знака этих отклонений.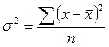 в варианте без частот и
в варианте без частот и 
 в варианте без частот и
в варианте без частот и  в варианте с частотами.
в варианте с частотами.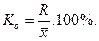













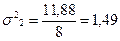
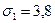



 , что делает ее удобнее для практических расчетов. Этот показатель широко применяется для расчетов показателей вариации в различных отраслях знания и техники. Среднее квадратическое отклонение показывает, на сколько в среднем отклоняются конкретные варианты от среднего их значения.
, что делает ее удобнее для практических расчетов. Этот показатель широко применяется для расчетов показателей вариации в различных отраслях знания и техники. Среднее квадратическое отклонение показывает, на сколько в среднем отклоняются конкретные варианты от среднего их значения. а дисперсия
а дисперсия 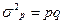 . Если на фирме работает 15 мужчин и 20 женщин, то р=
. Если на фирме работает 15 мужчин и 20 женщин, то р= 
 , следовательно дисперсия альтернативного признака
, следовательно дисперсия альтернативного признака  Максимальное значение дисперсии альтернативного признака равно 0, 25, оно получается при р=0, 5.
Максимальное значение дисперсии альтернативного признака равно 0, 25, оно получается при р=0, 5. ), внутригрупповую дисперсию (
), внутригрупповую дисперсию (  ), среднюю из внутригрупповых дисперсий (
), среднюю из внутригрупповых дисперсий ( 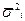 ), межгрупповую дисперсию (
), межгрупповую дисперсию (  ).
). , где
, где  - общая средняя для всей совокупности.
- общая средняя для всей совокупности. , где
, где 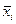 - групповая средняя.
- групповая средняя. , где
, где 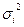 - дисперсии отдельных групп, а f - численность отдельных групп.
- дисперсии отдельных групп, а f - численность отдельных групп. , где
, где  и
и 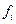 - средние и численности по отдельным группам.
- средние и численности по отдельным группам.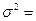
 .
.

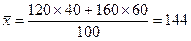 т. рублей
т. рублей
 , следовательно:
, следовательно: 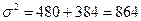 .
. .
. .
.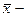 генеральная средняя – среднее значение изучаемого признака в генеральной совокупности;
генеральная средняя – среднее значение изучаемого признака в генеральной совокупности;  выборочная средняя – среднее значение изучаемого признака в выборочной совокупности;
выборочная средняя – среднее значение изучаемого признака в выборочной совокупности;  где m- число единиц, обладающих изучаемым признаком,
где m- число единиц, обладающих изучаемым признаком, 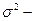 генеральная дисперсия - дисперсия изучаемого признака в генеральной совокупности;
генеральная дисперсия - дисперсия изучаемого признака в генеральной совокупности; 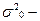 выборочная дисперсия – дисперсия изучаемого признака в выборочной совокупности;
выборочная дисперсия – дисперсия изучаемого признака в выборочной совокупности;  среднее квадратическое отклонение изучаемого признака в генеральной совокупности;
среднее квадратическое отклонение изучаемого признака в генеральной совокупности;  среднее квадратическое отклонение изучаемого признака в выборочной совокупности.
среднее квадратическое отклонение изучаемого признака в выборочной совокупности.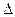 - предельная ошибка выборки, Этот показатель определяется по формуле:
- предельная ошибка выборки, Этот показатель определяется по формуле: 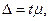 где t – коэффициент, зависящий от вероятности, с которой можно гарантировать определенные размеры предельной ошибки; этот коэффициент называется коэффициентом доверия . Этот коэффициент определяется по таблице значений интегральной функции Лапласа при заданной доверительной вероятности. Ниже приведены наиболее часто употребляемые уровни вероятности и соответствующие значения t.
где t – коэффициент, зависящий от вероятности, с которой можно гарантировать определенные размеры предельной ошибки; этот коэффициент называется коэффициентом доверия . Этот коэффициент определяется по таблице значений интегральной функции Лапласа при заданной доверительной вероятности. Ниже приведены наиболее часто употребляемые уровни вероятности и соответствующие значения t.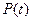
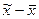 ) довести до сколь угодно малых размеров.
) довести до сколь угодно малых размеров.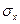 и р по генеральной совокупности как правило неизвестны. Эти величины заменяют выборочными величинами -
и р по генеральной совокупности как правило неизвестны. Эти величины заменяют выборочными величинами - 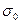 и
и 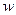 . В таблице приведены формулы расчета предельных ошибок выборки.
. В таблице приведены формулы расчета предельных ошибок выборки.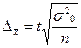
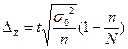
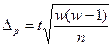
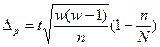
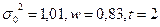 .
.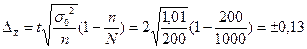 т. руб.
т. руб.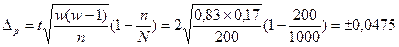 или
или 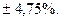
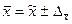 ,
, 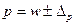 или
или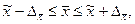
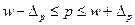 .
.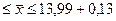 или
или 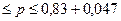 или р может находиться в диапазоне от 0, 7825 до 0, 8775.
или р может находиться в диапазоне от 0, 7825 до 0, 8775.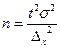
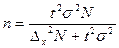
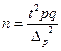
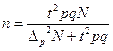
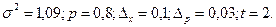
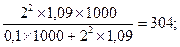
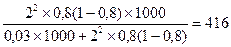 .
.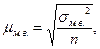 где
где 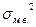 - дисперсия малой выборки, она рассчитывается по формуле
- дисперсия малой выборки, она рассчитывается по формуле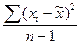 , где n-1 - число степеней свободы.
, где n-1 - число степеней свободы.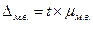 Коэффициент доверия t зависит не только от заданной доверительной вероятности, но и от численности единиц выборки n. Для отдельных значений t и n доверительная вероятность малой выборки определяется по специальным таблицам Стьюдента, где даны распределения стандартизированных отклонений:
Коэффициент доверия t зависит не только от заданной доверительной вероятности, но и от численности единиц выборки n. Для отдельных значений t и n доверительная вероятность малой выборки определяется по специальным таблицам Стьюдента, где даны распределения стандартизированных отклонений: 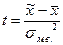 .
.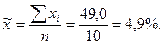 Определяем дисперсию малой выборки; для этого произведем предварительные расчеты:
Определяем дисперсию малой выборки; для этого произведем предварительные расчеты: 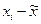
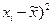
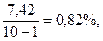
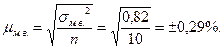
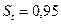 находим значение коэффициента доверия t= 2, 263
находим значение коэффициента доверия t= 2, 263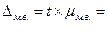 2, 263
2, 263 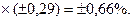
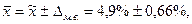 т.е. от 4, 9-0, 66= 4, 24% до 4, 9+0, 66= 5, 56%.
т.е. от 4, 9-0, 66= 4, 24% до 4, 9+0, 66= 5, 56%.  где n – число уровней.
где n – число уровней.  млн. человек.
млн. человек. чел. за 2004 г.
чел. за 2004 г.  =78 чел.
=78 чел. чел. за 2006 г.
чел. за 2006 г.  чел.
чел. чел.
чел.
 чел.
чел.






