
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Группировка статистических данныхСтр 1 из 4Следующая ⇒
Группировка - это распределение единиц совокупности по группам в соответствии с группировочным признаком. Назначение группировки состоит в том, что этот метод обеспечивает обобщение данных, представление их в компактном, обозримом виде. На основе группировки рассчитываются сводные показатели по группам, появляется возможность их сравнения, изучения взаимосвязей между признаками. Различия в целевом назначении группировки выражаются в существующей в нашей статистике классификации группировок: типологические, структурные, аналитические. При осуществлении любой группировки решается вопрос об определении числа выделяемых групп. При группировке по количественному признаку вопрос о числе групп решается на основе выделения однородных, близких по значению признака единиц совокупности. Необходимо, чтобы каждая группа характеризовала существенные типы явления. Число единиц в выделенных группах должно быть достаточным, чтобы характеристики, рассчитанные для отдельных групп были статистически устойчивыми. Количество выделяемых групп зависит от вариации признака, числа наблюдений, а также от количества отдельных возможных значений признака, т.е. от числа вариант признака. При небольшом числе вариант признака, положенного в основу группировки, каждая варианта представляет отдельную группу. Если число вариант велико, то значения группировочного признака для отдельных групп указываются в интервалах «от – до». Для этого всю область изменения признака разбивают на несколько интервалов и считают, сколько элементов попадает в отдельный интервал. Интервалы могут быть равными и неравными, открытыми и закрытыми. Группировку с неравными интервалами надо использовать, если размах вариации признака в совокупности велик, неравные интервалы применяются как прогрессивно возрастающие или убывающие. В этом случае границы каждого интервала устанавливаются исследователем. Однако необходимо учесть, что наличие равных интервалов технически значительно облегчает вычисление различных статистических характеристик. Равные интервалы применяются в случаях, когда изменение признака внутри совокупности происходит равномерно. Расчет величины интервала при равных интервалах производится по формуле:
где D - величина отдельного интервала, xmax - максимальное значение признака в исследуемой совокупности, xmin - минимальное значение признака в исследуемой совокупности. K - число групп, Затем определяются границы каждого интервала: для первого интервала: от xmin до xmin +D; для второго интервала: от xmin + D до xmin + 2D; ........................................................................ для интервала: K от xmin + KD до xmax.
Типологическая группировка служит для выявления типов элементов явлений. Структурная группировка служит для исследования совокупности по одному признаку. После того, как в результате сводки статистические данные сгруппированы, они, как правило, представляются в виде таблицы. Макет таблицы для представления результатов структурной группировки может выглядеть следующим образом: Наименование таблицы
Здесь в первой графе указываются варианты (интервалы) значений признака для отдельных групп по возрастанию или убыванию. Аналитические группировки служат для выявления аналитической зависимости между группировочными признаками. При построении аналитических группировок важно правильно определить признак-результат и признак-фактор. Признак, влияние которого на другие признаки исследуется, называется признаком-фактором. Признак, испытывающий влияние факторного, называется признаком - результатом. Чтобы установить связь между признаками аналитическая группировка осуществляется по признаку-фактору. Затем по каждой группе отбираются соответствующие значения признака-результата и рассчитывается его среднее значение. Сопоставляя изменение средних значений признака-результата от группы к группе с изменениями признака-фактора можно сделать вывод о наличии или отсутствии взаимосвязи, а также о ее направлении. Различие групповых средних позволяет утверждать, что признаки взаимозависимы. Если изменение величины признака-фактора в определенном направлении вызывает изменение величины признака-результата в том же направлении, то связь прямая, в противном случае - связь обратная. Макет таблицы для представления результатов аналитической группировки может выглядеть следующим образом: Наименование таблицы
Здесь в первой графе указываются варианты (интервалы) значений признака-фактора для отдельных групп по возрастанию или убыванию. Проследить зависимость между факторами можно также на основе комбинационной группировки. Комбинационная группировка осуществляется одновременно по двум и более признакам, взятым в сочетании. Макет комбинационной таблицы выглядит следующим образом:
Наименование таблицы
Здесь nij - частота совместного появления значения i признака-фактора (i = 1, 2,.., M) и значения j признака результата (j = 1, 2,..., K). Если наибольшие частоты каждой строки и каждого столбца располагаются вдоль диагонали таблицы, идущей от левого верхнего угла таблицы к правому нижнему, то можно сделать вывод, что связь между признаками является прямой и близкой к линейной. Если наибольшие частоты располагаются вдоль диагонали от правого верхнего угла к нижнему левому, то связь -- обратная и близкая к линейной. Если частоты во всех клетках таблицы примерно одинаковы, то связи между признаками нет.
Контрольное задание №1
На основе данных, приведенных в Приложении 1 и соответствующих Вашему варианту (таблица 1), выполнить: 1. Структурную равноинтервальную группировку по обоим признакам. Если вариация группировочного признака значительна и его значение для отдельных групп необходимо представить в виде интервалов, то при построении группировки по признаку № 1 принять число групп равным 7, а по признаку № 2 - 8. Результаты представить в таблице, сделать выводы. 2. Аналитическую группировку, для этого определить признак-результат и признак-фактор, обосновав их выбор. При построении аналитической группировки использовать равнонаполненную группировку по признаку-фактору (в каждой группе приблизительно одинаковое количество наблюдений). Результаты группировки представить в таблице. Сделать выводы о наличии и направлении взаимосвязи между признаками. 3. Комбинационную группировку по признаку-фактору и признаку-результату. Сделать выводы.
Таблица данных для формирования статистической совокупности Таблица 1
Окончание таблицы 1
Методические указания к выполнению задания №2 Обощающие характеристики совокупностей
Анализ статистических совокупностей включает в себя: построение рядов распределения; графическое представление распределения; определение характеристик центра распределения, показателей вариации. Рядами распределения называют числовые ряды, характеризующие структуру совокупности по некоторому признаку. Ряд распределения может быть получен в результате структурной группировки. Ряд распределения, образованный по количественному признаку (он называется вариационным рядом), может быть дискретным, если значения признака выражены целыми числами и каждая варианта представлена в вариационном ряде отдельной группой, или интервальным (непрерывным), если значения признака выражены вещественными числами или число вариант признака достаточно велико. Ряд распределения состоит из следующих элементов: xi - варианта - отдельное, возможное значение признака i=1, 2,..., K, где K - число значений признака; Ni - частоты - численность отдельных групп соответствующих значений признаков; N - объём совокупности - общее число элементов совокупности; qi - частость - доля отдельных групп во всей совокупности; Di - величина интервала;
Полученный вариационный ряд оформляется в виде таблицы, где в первой графе указываются варианты (интервалы) значений признака, а в следующих графах частота, частость, или если необходимо абсолютная или относительная плотность распределения. Ряд распределения по частоте (частости) в целом характеризует структуру совокупности по данному признаку. Однако для описания распределения совокупность могут использоваться и кумулятивные ряды, т.е. ряды накопленных частот (или частостей), которые иногда имеют даже некоторые преимущества. Накопленная частота (частость) данного значения признака - это число (доля) элементов совокупности, индивидуальные значения признака которых не превышают данного. Обозначим: F(x) - накопленная частота для данного значения x; G(x) - накопленная частость для данного значения x. Эти характеристики обладают следующими свойствами: 0 £ F(x) £ N; 0 £ G(x) £ 1 Рассмотрим интервалы [xi -xi+1], i=1, 2,..., K:
Первым этапом изучения вариационного ряда является его графическое изображение. Способы построения графиков для разных видов рядов распределения различны. Изображением дискретного ряда распределения является полигон. В системе координат по оси абсцисс откладываются варианты (xi), по оси ординат - частоты (частости), затем отмечают точки с координатами (xi; Ni), которые последовательно соединяются отрезками прямой. Интервальный ряд распределения изображается графически в виде гистограммы. При её построении на оси абсцисс откладывают интервалы ряда. Над осью абсцисс строятся прямоугольники, основанием которых является интервал, а высота - соответствующая этому интервалу абсолютная плотность распределения (или частота, частость - если ряд равноинтервальный). Изображением ряда накопленных частот служит кумулята. Накопленные частоты наносятся в системе координат в виде ординат для границ интервалов; соединяя нанесенные точки отрезками прямых, получаем кумуляту. Вторым этапом изучения вариационного ряда является определение характеристик центра распределения. Характеристика центра распределения представляет собой такую величину, которая в некотором отношении характерна для данного распределения и является его центральной величиной. К характеристикам центра распределения относятся: средняя арифметическая, медиана, мода. Для сгруппированных данных, представленных в вариационном ряду средняя арифметическая (`x) определяется как:
т.е. в качестве веса при усреднении берётся частота Ni, соответствующая групповым значениям xi. Если ряд дискретный, то каждое значение признака представлено. Если же ряд интервальный, то его нужно превратить в условно дискретный: в качестве группового значения xi для каждого интервала вычисляется его середина. Медиана (Me[x]) - это такое значение признака, которое делит объём совокупности пополам в том смысле, что число элементов совокупности с индивидуальными значениями признака, меньшими медианы, равна числу элементов совокупности с индивидуальными значениями больше медианы. Численное значение медианы можно определить по ряду накопленных частот. Накопленная частота для Me[x] равна половине объёма совокупности ( F(Me[x]) = N/2 ); имея ряд накопленных частот, можно вычислить, при каком значении признака накопленная частота равна половине объёма совокупности. Для интервального ряда в этом случае определяется только интервал в котором будет находиться Me[x], само значение приближённо можно определить как:
где x0 - начало интервала, содержащего медиану; DMe - величина интервала, содержащего медиану; F(x0) - накопленная частота на начало интервала, содержащего медиану; N - объём совокупности; NMe - частота того интервала, в котором расположена медиана. Квартили (Q1, Q2, Q3) – значения признака, делящие упорядоченную по значению признака совокупность на 4 равные части. 1-ая квартиль (Q1) определяет такое значение признака, что ¼ единиц совокупности имеют значения признака меньше, чем Q1, а ¾ - значения больше чем Q1. 2-ая квартиль (Q2) равна медиане. 3-я квартиль (Q3) определяет такое значение признака, что ¾ единиц совокупности имеют значения признака меньше, чем Q3, а ¼ - больше чем Q3. Значения квартилей для сгруппированных данных определяются по накопленным частотам. При этом для 1-ой квартили накопленная частота сравнивается с величиной N·1/4; для 3-ей квартили – с величиной N·3/4. Значение квартили для интервального ряда распределения может быть уточнено по формуле: Qi=x0+DQi (i*N/4 – F(x0))/NQi. x0- нижняя граница интервала, в котором находится i-ая квартиль; DQi - величина интервала, содержащего i-ую квартиль; F(x0) - сумма накопленных частот интервалов, предшествующих интервалу, в котором находится i-ая квартиль; NQi - частота интервала, в котором находится i-ая квартиль. Децили (D1, D2, D3, D4, D5, D6, D7, D8, D9) – значения признака, делящие упорядоченную по значению признака совокупность на 10 равных частей. Мода (Mo[x]) - наиболее часто встречающееся значение признака в совокупности. Для дискретного ряда — это то значение, которому соответствует наибольшая частота распределения. Для интервального ряда в начале определяется интервал, содержащий моду, - тот, которому соответствует наибольшая плотность распределения. Затем приближённо определяется численное значение моды. Если ряд равноинтервальный, то используется формула:
где x0 - начало интервала, содержащего моду, DMo - величина интервала, содержащего моду, NMo - частота того интервала, в котором расположена мода, NMo-1 - частота интервала, предшествующего модальному, NMo+1 - частота интервала, следующего за модальным. Средняя величина характеризует только уровень, закономерный для данной совокупности. В ряде случаев одно и то же численное значение средней может характеризовать совершенно различные совокупности. Поэтому для того чтобы судить о типичности средней для данной совокупности, её следует дополнить показателями, характеризующими вариацию (колеблемость) признака. Наиболее распространёнными из них являются дисперсия, среднее квадратичное отклонение, коэффициент вариации. Дисперсия (
Если ряд интервальный, то в качестве варианты (xi), также как при расчете средней, берётся середина интервала. При использовании калькулятора, а также для дискретных рядов распределения более удобной может быть другая формула вычисления дисперсии:
где Наиболее широко в статистике применяется такой показатель вариации, как среднее квадратичное отклонение ( Относительным показателем колеблемости признака в данной совокупности, является коэффициент вариации (V):
Коэффициент вариации позволяет сравнивать вариации различных признаков, а также одноименных признаков в разных совокупностях.
Контрольное задание №2
1. На основе равноинтервальной структурной группировки (для любого признака) построить вариационный частотный и кумулятивный ряды распределения, оформить в таблице, изобразить графически. 2. Проанализировать вариационный ряд распределения, вычислив: · среднее арифметическое значение признака; · медиану и моду, квартили и децили (первую и девятую) распределения; · среднее квадратичное отклонение; · дисперсию; · коэффициент вариации. 3. Сделать выводы.
Методические указания к выполнению задания №3
Индексы
В статистике под индексами понимаются относительные величины, характеризующие результаты сравнения двух уровней одноименных объектов. Однако это не любые показатели сравнения, а специальные, построенные при особых условиях обобщения. Каждый индекс включает два вида данных: данные текущего (или отчетного ) уровня, которые принято обозначать «1», и базисного уровня, служащего базой сравнения, обозначаемые «0». В зависимости от степени охвата подвергнутых обобщению единиц изучаемой совокупности индексы подразделяются на индивидуальные(частные) и агрегатные (общие). Индивидуальные индексы характеризуют изменение отдельных единиц статистической совокупности (например, изменение цен на отдельные виды работ и услуг и т.д.):
где x1 - текущий уровень индексируемой величины; x0 - базисный уровень индексируемой величины. Агрегатные индексы выражают сводные обобщающие результаты совместного изменения всех единиц, образующих статистическую совокупность (например, изменение цен на все виды выполняемых работ и услуг и т.д.):
Так как совокупность состоит обычно из элементов, непосредственно не поддающихся суммированию, то агрегатный индекс включает набор значений индексируемой величины {xj} и соответствующих им коэффициентов соизмерения (весов) {wj}. Важной особенностью общих индексов является то, что они обладают синтетическими и аналитическими свойствами. Синтетические свойства индексов состоят в том, что посредством индексного метода производится соединение в целое разнородных единиц статистической совокупности. Аналитические свойства определяются тем, что с помощью индексного метода можно оценить влияние факторов на изменение изучаемого показателя. Различают индексы количественных и качественных показателей. К индексам количественных (объемных) показателей относятся индексы физического объема продукции, работ и услуг, грузооборота, товарооборота и т.д. - показателей, которые характеризуются абсолютными величинами. К индексам качественных показателей относятся индексы цен, выработки, себестоимости единицы продукции, заработной платы и др., - показателей, уровень которых дается в форме средних (относительных) величин. Систему этих индексов можно рассмотреть на примере таких показателей, как цена, физический объем работ или услуг и стоимость работ или услуг. Обозначим цену отдельного вида работ или услуг (качественный показатель) p, а физический объем, т.е. объем работ или услуг отдельного вида в натуральном выражении (количественный показатель) q. Тогда индивидуальные индексы этих показателей имеют вид: * физического объема работ или услуг * цены * стоимости При определении общего индекса цен Ip существует два подхода: Популярное:
|
Последнее изменение этой страницы: 2016-08-24; Просмотров: 578; Нарушение авторского права страницы
 ,
, 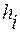 - абсолютная плотность распределения;
- абсолютная плотность распределения; 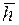 - относительная плотность распределения.
- относительная плотность распределения.
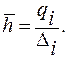
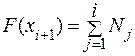 .
. ,
,  ,
, 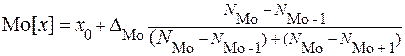 ,
, 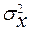 ) - это среднее из квадратов отклонений от средней величины, для вариационного ряда она определяется по формуле:
) - это среднее из квадратов отклонений от средней величины, для вариационного ряда она определяется по формуле:  ,
, 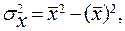

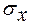 ), который представляет собой квадратный корень из дисперсии.
), который представляет собой квадратный корень из дисперсии.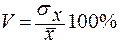
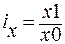
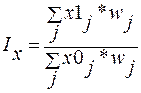 , где
, где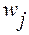 - коэффициент соизмерения;
- коэффициент соизмерения; 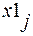 - текущий уровень индексируемой величины;
- текущий уровень индексируемой величины; 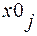 - базисный уровень индексируемой величины.
- базисный уровень индексируемой величины. ,
,  ,
,  .
.