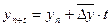|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
ОБЩАЯ ТЕОРИЯ СТАТИСТИКИ. 1 КУРС. 2 СЕМЕСТРСтр 1 из 7Следующая ⇒
С.Г. Бабич
ОБЩАЯ ТЕОРИЯ СТАТИСТИКИ. 1 КУРС. 2 СЕМЕСТР (КУРС ЛЕКЦИЙ) Москва 2004 Лекция №1 Статистика – это общественная наука, изучающая массовые явления и процессы, происходящие в обществе, а также экономические и социальные условия жизни общества. Все явления и процессы, изучаемые статистикой в конкретных условиях места и времени, в непрерывном развитии и взаимосвязи друг с другом. Объектами статистических исследований являются массовые экономические и социальные явления и процессы, происходящие в обществе. Предметом статистики являются размеры и уровни изучаемых явлений и процессов. Статистика создает и анализирует количественные и качественные характеристики изучаемых явлений и процессов в их непрерывном развитии и взаимосвязи друг с другом. Глобальной задачей статистики является подготовка и представление полной и достоверной информации о состоянии и развитии экономики страны. Более конкретными задачами являются:
Главным статистическим органом нашей станы является ГОСКОМСТАТ РФ. Он осуществляет управление статистическим отчетом и отчетностью во всех отраслях экономики и несет полную ответственность за создание и функционирование статистической информационной системы на общегосударственном, отраслевом и региональном уровнях. Курс статистики состоит из следующих разделов: 1. Общая теория статистики 2. Математическая статистика 3. Социально-экономическая статистика 4. Отраслевая статистика (финансовая, международная и т. д.) Исходным понятием статистики является понятие статистической совокупности, под которой понимают массовое явление, изучаемое в данный момент статистикой (например: население страны). Каждая статистическая совокупность состоит из отдельных элементов, которые называют единицами статистической совокупности (для населения – человек, семья, население какого-нибудь региона, национальность и т. д.). Каждая единица совокупности обладает определенными свойствами. Признаком в статистике называют свойство или качество единицы совокупности, которое может быть определено или измерено (для человека – пол, рост, возраст, вес и т. д.). Признаки подразделяются на количественные и качественные (атрибутивные). Каждая единица совокупности имеет определенное значение признака. Изменение величины признака от одной единицы совокупности к другой в статистике называют вариацией признака. По характеру, вариации признака подразделяются на множественные (принимающие различные значения) и альтернативные (принимающие только 2 значения). В любом статистическом исследовании выделяют 3 этапа: 1. статистическое наблюдение 2. сводка и группировка 3. расчет обобщающих показателей и анализ полученных данных. Статистическое наблюдение представляет собой систематизированный и научно обоснованный сбор первичных статистических данных об изучаемом явлении путем регистрации индивидуальных значений признака у отдельных единиц совокупности. Основной задачей статистического наблюдения является получение в возможно короткие сроки полной и достоверной информации об изучаемом явлении. На практике применяют 2 организационные формы статистического наблюдения: 1. Статистическая отчетность, при которой юридические и физические лица по установленной форме в установленные сроки предоставляют необходимую информацию в статистические органы. 2. Специально организованное наблюдение, которое проводится либо для проверки данных статистической отчетности, либо для получения данных, по которым статистическая отчетность не предоставляется (пример: перепись населения). Различают следующие виды статистического наблюдения: 1. По охвату единиц совокупности – сплошное и не сплошное. В свою очередь, не сплошное подразделяется на выборочное, основного массива и монографическое. 2. По основанию для регистрации признака – непосредственное, документальное и опрос. 3. По характеру регистрации признака во времени – прерывное и непрерывное. Для правильной организации статистического наблюдения утверждают программу, в которой устанавливают цели и задачи наблюдения, определяют объект и единицу наблюдения, выбирают вид и способ наблюдения, место и время его проведения, устанавливают круг лиц ответственных за проведение наблюдения и сроки предоставления необходимой информации. Сводка – это второй этап статистического исследования и заключается в том, что первичные данные, полученные при проведении статистического наблюдения, систематизируются и обобщаются. По технике выполнения сводка бывает ручной и механизированной. На стадии сводки применяется группировка – это метод, при котором вся исходная совокупность делится на группы по какому-то существенному признаку. Признак, лежащий в основании группировки, называют группировочным. Различают простую и сложную сводку. При простой сводке производится только подсчет итогов по всей совокупности в целом. При сложной - разделение исходной совокупности на группы, подсчет итогов в каждой группе и совокупности в целом, представление полученных данных в виде статистических таблиц. Если производится группировка единиц исходной совокупности только по первому признаку, то она называется простой, если по второму и более признакам – комбинационной. В зависимости от решаемой задачи различают следующие виды группировок: 1. Типологическая, с помощью которой производится разделение единиц исходной совокупности на количественно-однородные группы (социально-экономические типы) (например: группировка предприятий по формам собственности). 2. Структурная, с помощью которой происходит разделение единиц исходной совокупности на группы, характеризующие ее структуру по какому-то существенному признаку (например: группировка населения по величине среднедушевых денежных доходов). 3. Аналитическая, с помощью, которой изучаются взаимосвязи между различными явлениями или их признаками (например: группировка коммерческих банков по величине уставного капитала, величине прибыли и количеству филиалов). Важнейшим вопросом группировки является определение количества выделяемых групп. Если в основании группировки лежит качественный (атрибутивный) признак, то количество выделяемых групп определяется самим этим признаком. Если в основании группировки лежит количественный признак, то производят специальные расчеты для определения количества выделяемых групп и величин интервалов группировки.
Лекция №2. Интервалом группировки называют значения варьирующего признака, лежащие в определенных границах (например: размер заработной платы от 5 до 12 тыс. руб.). Минимальное значение интервала называют его нижней гранью, максимальное – верхней гранью. Величина интервала обозначается i и определяется, как разность между верхней и нижней границами в каждом интервале. Интервалы группировки бывают открытые и закрытые, равные и неравные. Закрытым считается интервал, который имеет и нижнюю и верхнюю границы. Если одна из границ отсутствует, то интервал считается открытым. При решении задач открытый интервал группировки закрывают по величине смежного с ним интервала. Если в каждой из выделенных групп величина интервала одинаковая, то такие интервалы считаются равными, в противном случае они считаются неравными. Количество выделяемых групп с неравными интервалами зависит от имеющейся исходной информации и целей исследования. Если вариация признака проявляется в сравнительно узких границах, то производят группировку единиц совокупности с равными интервалами. Количество выделяемых групп с равными интервалами определяется по формуле Стерджесса: n = 1+3, 322 * lgN. В этой формуле N – численность единиц исходной совокупности, n – количество выделяемых групп с равными интервалами. При N от 15 до 24: n=5; при N от 25 до 44: n=6; при N от 45 до 89: n=7. Величина равного интервала определяется по формуле: i = (Xmax – Xmin)/n, где Xmax и Xmin соответствуют максимальному и минимальному значениям признака в исходной совокупности, а n - количество выделяемых групп с равными интервалами. После определения группировочного признака, количество выделяемых групп и величин интервалов группировки, данные представляют в виде рядов распределения. Статистический ряд распределения – это упорядоченное распределение единиц исходной совокупности на группы по какому-то существенному признаку. В зависимости от группировочного признака различают атрибутивные и вариационные ряды распределения. Атрибутивным называется ряд распределения, построенный по количественному признаку. Вариационным называют ряд распределения, построенный в порядке возрастания или убывания количественных значений признака. Схематично, вариационные ряды распределения представлены в виде двух столбцов. В первом столбце приводятся индивидуальные значения признака, их называют вариантами и обозначают через Х. Во втором столбце содержатся: 1) Абсолютные числа, показывающие, сколько раз в исходной совокупности встречается данное значение признака (данный вариант). Такие абсолютные числа называют частотами и обозначают буквой ƒ. Сумма всех частот должна быть равна общей численности единиц исходной совокупности. 2) Относительные числа, показывающие долю (удельный вес) каждой группы в общей численности единиц исходной совокупности. Такие относительные числа называют частостями и обозначают через W. Сумма всех частостей должна быть равна 1 или 100%. Схема вариационного ряда распределения:
В зависимости от характера вариации признака различают дискретные и интервальные вариационные ряды распределения. Если значения признака (варианты) представлены в виде целых чисел, то такой вариационный ряд называют дискретным (например: приводится распределение 20 семей по числу детей в них ).
Дискретные вариационные ряды изображают в виде полигона распределения. Для его построения по оси абсцисс откладываются индивидуальные значения признака (варианты), по оси ординат частоты (частости).
Если значения признака (варианты) представлены в виде интервалов, то такой вариационный ряд называется интервальным (например: приводится распределение 30 сотрудников фирмы по размеру месячной заработной платы (тыс. руб.)). Интервальные вариационные ряды изображаются графически в виде гистограммы.
Для ее построения по оси абсцисс откладываются отрезки, длина которых соответствует интервалам группировки. Эти отрезки являются нижним основанием образуемых прямоугольников, а соответствующие частота или частость – соответственно высотой этих прямоугольников. В некоторых случаях интервальный вариационный ряд изображается графически в виде кумуляты. Для ее построения, необходимо накопленные частоты (частости). Они обозначаются S и определяются путем последовательного суммирования частот (частостей), предшествующих интервалу. Вычислим для нашего примера интервального вариационного ряда накопленные частоты (см. ранее в таблице). Накопленная частота показывает сколько единиц исходной совокупности имеют значение признака (вариант) не больше, чем рассматриваемая (например: накопленная частота равна 25, значит, 25 сотрудников из 30 имеют размер зарплаты не более 18 тыс. руб. в месяц). При построении кумуляты вся накопленная частота (частость) интервала, присваивается верхней границе данного интервала. Для построения кумуляты по оси абсцисс откладываются верхние границы интервалов, по оси ординат – накопленные частоты (частости).
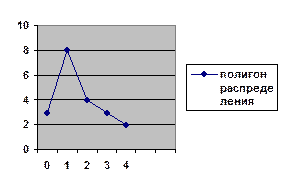
На практике иногда приходится пользоваться уже имеющимися группировками, которые могут быть несопоставимы по следующим причинам: 1) Неодинаковые границы интервалов группировки. 2) различное количество выделяемых групп. Для привидения таких группировок к сопоставимому виду, применяют метод вторичной группировки. Различают 2 способа вторичной группировки: 1) Способ укрупнения интервалов группировки. 2) Способ долевой перегруппировки, который заключается в том, что за каждой группой закрепляется определенная доля единиц исходной совокупности. От группировок следует отличать классификации. Особенностями классификаций является то, что в их основу кладется качественный признак. Они устанавливаются органами государственной и международной статистики и остаются неизменными в течение длительного периода времени. Лекция №3. Лекция №4 Лекция № 5 Медиана – это значение признака при котором исходная совокупность делится на 2 равные части, при этом первая половина совокупности имеет значение признака меньше, чем медиана, а вторая имеет значения признака больше, чем медиана. Квартиль делит исходную совокупность на 4 равные части. На практике вычисляют первый (нижний) квартиль, который делит исходную совокупность в соотношении ¼ : ¾ и третий (верхний) квартиль, который делит исходную совокупность в соотношении ¾ : ¼ . Дециль делит исходную совокупность на 10 равных частей. Например: второй D делит исходную совокупность в соотношении 2/10: 8/10; девятый D делит исходную совокупность в соотношении 9/10: 1/10. В дискретном вариационном ряду для определения Ме, квартилей и децилей необходимо: 1) Вычислить накопленные частоты. 2) Определить порядковый номер единицы, которая делит исходную совокупность в нужном нам соотношении. Например: для Ме: 3) По накопленным частотам найти значение признака, которое имеет нужная нам единица совокупности. Пример (про семьи):
По накопленным частотам определяем, что 10-ой единице совокупности (10-ой семье) соответствует значение признака равное 1, значит Ме равна 1 ребенку. Половина семей имеют 1 ребенка и вообще не имеют детей, а вторая половина имеют 1 ребенка и больше.
В интервальном вариационном ряду для определения медианы, квартилей и децилей необходимо: 1) Вычислить накопленные частоты. 2) Найти порядковый номер единицы, которая делит исходную совокупность в нужном нам соотношении. 3) По накопленным частотам найти интервал, содержащий нужную нам единицу совокупности. 4) Медиану, квартили и децили вычисляют по формулам:
В интервальном вариационном ряду медиану можно вычислить графически по кумуляте:
Квартиль вычисляют по формуле: Дециль вычисляют по формуле: В интервальном вариационном ряду квартиль и дециль можно вычислить графически по кумуляте:
Изменение величины признака от одной единицы совокупности к другой в статистике называют вариацией признака. Кроме средних величин для анализа исходной совокупности вычисляют абсолютные и относительные показатели вариации. К абсолютным показателям относятся: 1) Размах вариации (R) определяется, как разность между максимальным и минимальным значением признака в исходной совокупности R=Xmax-Xmin. 2) Среднее квартильное отклонение. Определяется как половина разности 3-его и 1-ого квартиля: 3) Среднее линейное отклонение (d). Определяется, как средняя арифметическая величина из абсолютных отклонений индивидуальных значений признака от их средней величины. Применяют 2 формулы для не сгруппированных данных и сгруппированных. Для не сгруппированных: 4) Дисперсия ( Для не сгруппированных: 5) Среднее квадратическое отклонение представляет собой квадратный корень из дисперсии. Для не сгруппированных: Среднее квадратическое отклонение показывает на сколько в среднем отличаются индивидуальные значения признака (варианты) в исходной совокупности от средней величины. Показатель среднего квадратического отклонения применяется при оценке возможного риска в финансово-экономических расчетах. Лекция №6. К относительным показателям вариации относятся: 1. Коэффициент квартильной вариации, который вычисляется по формуле:
2. Коэффициент осцилляции: 3. Коэффициент вариации: исходная совокупность считается однородной по изучаемому признаку, если коэффициент вариации меньше 33%. В этом случае средняя величина объективно представляет свою исходную совокупность. Пример вычисления показателей вариации:
В среднем возраст каждого депутата отличается от среднего возраста для депутатов данной фракции на 9, 2 лет. Данная совокупность депутатов считается однородной по возрасту, т. к. коэффициент вариации меньше 33%. Правила сложения дисперсии. Если исходная совокупность разделена на группы по какому-то существенному признаку, то вычисляют следующие виды дисперсий: 1) Общую дисперсию исходной совокупности по формуле: 2) Внутригрупповые дисперсии по формуле: 3) Межгрупповую дисперсию по формуле: Лекция №7 Выборочное наблюдение. Выборочным называют не сплошное наблюдение, при котором обследованию и изучению подвергаются не все единицы исходной совокупности, а только часть единиц, при этом результат обследования части совокупности распространяется на всю исходную совокупность. Совокупность, из которой производится отбор единиц для дальнейшего обследования и изучения называется генеральной и все показатели, характеризующие эту совокупность, называются генеральными. Средняя величина признака в генеральной совокупности обозначается через Совокупность отобранных единиц называется выборочной и все показатели, характеризующие эту совокупность, называются выборочными. Средняя величина признака в выборочной совокупности обозначается через Возможные пределы отклонений выборочной средней величины от генеральной средней величины называют ошибкой выборки. Чем больше ошибка выборки, тем в большей степени выборочные показатели отличаются от генеральных. Задача выборочного наблюдения состоит в том, чтобы на основе данных выборочной совокупности дать верное представление о генеральной совокупности, т. е. необходимо максимально приблизить выборочные показатели к генеральным и знать возможный предел отклонений этих величин. При прочих равных условиях чем больше численность единиц выборочной совокупности, тем меньше величина ошибки выборки. Средняя ошибка выборки обозначатся буквой Так как средняя ошибка выборки характеризует среднюю величину возможных отклонений выборочных показателей от генеральных, то всегда найдутся единицы генеральной совокупности, которые будут выходить за возможные пределы, такие, как Если мы увеличим возможные пределы отклонений выборочных показателей от генеральных, то с большей вероятностью сможем утверждать, чтот показатели генеральной совокупности отличаются от выборочных показателей не более чем на какую-нибудь величину, которую называют предельной ошибкой выборки. Предельная ошибка выборки обозначается буквой
Таблица для справки:
По способу отбора единиц в выборочную совокупность различают следующие виды выборочного наблюдения (выборки):
По методу отбора единиц в выборочную совокупность различают повторный и бесповторный отбор. При повторном отборе обследованная единица после изучения вновь возвращается в генеральную совокупность и не исключена возможность дальнейшего отбора этой единицы в выборочную совокупность. При бесповторном отборе обследованная единица не возвращается в генеральную совокупность и не участвует в дальнейшем отборе единиц в выборочную совокупность. 1) Собственно-случайная выборка заключается в том, что отбор единиц в выборочную совокупность производится без определенной системности, например, методом жеребьевки. При этом каждая единица генеральной совокупности имеет одинаковую вероятность быть отобранной в выборочную совокупность. Средняя ошибка выборки рассчитывается по формулам: Для повторного отбора: 2) Механическая выборка является разновидностью собственно-случайной выборки и заключается в том, что вся генеральная совокупность разбивается на определенное количество равных частей и затем из каждой части случайным образом производится отбор единиц в выборочную совокупность. Для определения средней ошибки выборки применяют те же формулы, что и при собственно-случайной выборке. 3) Типическая выборка проводится в тех случаях, когда вся генеральная совокупность разбивается на качественно-однородные группы и затем из каждой группы, случайным или механическим образом производится отбор единиц в выборочную совокупность. Формула для повторного отбора: 4) Серийная выборка состоит в том, что обследованию подвергаются не отдельные единицы совокупности, а целые группы или серии единиц. При этом, в данной группе обследованию подвергаются все единицы. Средняя ошибка выборки определяется по формулам: Для повторного отбора: Для определения необходимой численности единиц в выборочной совокупности используют формулы, применяемые для расчета средней ошибки выборки. Лекция №8. Ряды динамики. Одной из задач статистики является изучение изменения социально-экономических явлений и процессов во времени. Эта задача решается с помощью составления и анализа рядов динамики. Ряд динамики представляет собой последовательность числовых значений изучаемого статистического показателя за определенные периоды времени. Числовые значения, составляющие ряд динамики называются уровнями ряда и обозначаются yi (i=1, 2, …, n). В зависимости от вида показателей, составляющих ряд динамики, различают ряды абсолютных, относительных и средних величин. Уровни ряда динамики могут относиться к определенным моментам или периодам времени. В зависимости от этого ряды динамики подразделяются на моментные и интервальные. Моментным называют ряд динамики, уровни которого характеризуют величину изучаемого показателя на определенный момент времени (на конкретную дату). Например: приводится численность населения Российской Федерации (млн. чел.): на 01.01.1999 – 146, 3; на 01.01.2000 – 145, 6; на 01.01.2001 – 144, 8; на 01.01.2002 – 144, 0; на 01.01.2003 -145, 2. Интервальным называют ряд динамики, уровни которого характеризуют величину изучаемого показателя за определенный период времени. Например: приводится объем кредитных вложений в экономику страны: 2000 г. – 808; 2001 г. – 1286; 2002 г. – 1755.
Лекция №9. При сравнении двух и более рядов динамики возникает проблема несопоставимости уровней ряда по следующим причинам: 1) изменение территориальных границ, в пределах которых рассчитываются показатели; 2) изменение уровня цен при расчете показателей; 3) изменение методологии расчета покупателей. Для привидения таких рядов динамики к сопоставимому виду применяют метод смыкания рядов динамики. Он заключается в том, что для периода, в котором произошли определенные изменения, в расчете показателей рассчитывают коэффициент соотношения уровней и затем все последующие (предшествующие), уровни рядов динамики корректируют с учетом этого коэффициента. При изучении рядов динамики важной задачей является выявление основной тенденции изменения уровней рядов динамики. Для этого используют следующие методы: 1) Метод скользящей средней, который заключается в том, что по исходным данным для каждого звена по формуле простой арифметической средней рассчитываются теоретические уровни, в которых исключены случайные колебания уровней рядов динамики. Полученные теоретические уровни присваивают периоду, который находится в середине каждого звена. Например, трехзвенную скользящую среднюю рассчитывают следующим образом: 2) Метод укрупнения интервалов состоит в том, что первоначальный ряд динамики преобразуется в ряд с более продолжительными периодами времени. Например: месячные уровни товарооборота преобразуют в квартальные уровни. 3) Метод механического выравнивания заключается в том, что на основе рассчитанного среднегодового абсолютного прироста вычисляются теоретические уровни ряда динамики. 4) Метод аналитического выравнивания состоит в том, что на основе математической функции, которая наиболее точно отражает основную тенденцию изменения уровней ряда динамики, строится теоретическая функция: y(t)=f(t), где t – параметр времени. При подборе математической функции необходимо свести к минимуму сумму квадратов отклонений фактических уровней ряда от теоретических: Пример:
5) Метод интерполяции заключается в том, что на основе выявленных закономерностей изменения уровней ряда динамики рассчитываются неизвестные уровни внутри этого ряда динамики. 6) Метод экстраполяции состоит в том, что на основе выявленной закономерности в изменении уровней ряда строится прогноз на перспективный период времени. Для этого используются следующие формулы:
Популярное:
|
Последнее изменение этой страницы: 2016-08-24; Просмотров: 628; Нарушение авторского права страницы


 ; для первого Q:
; для первого Q:  ; для девятого D:
; для девятого D:  .
.
 ;
;  Таким образом мы вычислили, что ¾ семей (75%) имеют 2-ух детей и меньше, а 25% семей имеют более 2-ух детей; 90% семей имеют 3-ех детей и меньше, а 10% более 3-ех детей.
Таким образом мы вычислили, что ¾ семей (75%) имеют 2-ух детей и меньше, а 25% семей имеют более 2-ух детей; 90% семей имеют 3-ех детей и меньше, а 10% более 3-ех детей. , где
, где  - нижняя граница медианного интервала (интервала, содержащего единицу, которая делит всю совокупность на 2 равные части);
- нижняя граница медианного интервала (интервала, содержащего единицу, которая делит всю совокупность на 2 равные части);  - величина медианного интервала;
- величина медианного интервала;  - накопленная частота интервала, предшествующего медианному;
- накопленная частота интервала, предшествующего медианному; 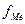 - частота медианного интервала. Пример:
- частота медианного интервала. Пример:  По накопленным частотам определяем, что 41-ая единица совокупности содержится в интервале 40-49 лет. Этот интервал является медианным.
По накопленным частотам определяем, что 41-ая единица совокупности содержится в интервале 40-49 лет. Этот интервал является медианным. Половина депутатов фракции «Единство» моложе 47, 7 лет, 2-ая половина старше 47, 7 лет.
Половина депутатов фракции «Единство» моложе 47, 7 лет, 2-ая половина старше 47, 7 лет.
 ;
; 

 .
. 
 .
. ; для сгруппированных:
; для сгруппированных:  .
. ). Определяется, как средняя арифметическая величина из квадратов отклонений индивидуальных значений признака от из средней величины.
). Определяется, как средняя арифметическая величина из квадратов отклонений индивидуальных значений признака от из средней величины.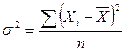 ; для сгруппированных:
; для сгруппированных:  .
. ; для сгруппированных:
; для сгруппированных:  .
.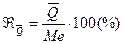
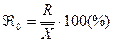 .
.
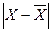


 ; R=69-20=49 (лет);
; R=69-20=49 (лет); 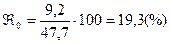
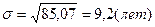 ;
;  , где
, где  - общая средняя величина исходной совокупности; f – частоты исходной совокупности. Общая дисперсия характеризует отклонение индивидуальных значений признака от общей средней величины исходной совокупности.
- общая средняя величина исходной совокупности; f – частоты исходной совокупности. Общая дисперсия характеризует отклонение индивидуальных значений признака от общей средней величины исходной совокупности.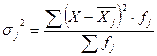 , где j - номер группы;
, где j - номер группы;  - средняя величина в каждой j-ой группе;
- средняя величина в каждой j-ой группе;  - частоты j-ой группы. Внутригрупповые дисперсии характеризуют отклонение индивидуального значения признака в каждой группе от групповой средней величины. Из всех внутригрупповых дисперсий вычисляют среднюю по формуле:
- частоты j-ой группы. Внутригрупповые дисперсии характеризуют отклонение индивидуального значения признака в каждой группе от групповой средней величины. Из всех внутригрупповых дисперсий вычисляют среднюю по формуле:  , где
, где  - численность единиц в каждой j-ой группе.
- численность единиц в каждой j-ой группе. . Межгрупповая дисперсия характеризует отклонение групповых средних величин от общей средней величины исходной совокупности. Правило сложения дисперсий заключается в том. что общая дисперсия исходной совокупности должна быть равна сумме межгрупповой и средней из внутригрупповых дисперсий:
. Межгрупповая дисперсия характеризует отклонение групповых средних величин от общей средней величины исходной совокупности. Правило сложения дисперсий заключается в том. что общая дисперсия исходной совокупности должна быть равна сумме межгрупповой и средней из внутригрупповых дисперсий:  . Результат отношения межгрупповой к общей дисперсии исходной совокупности называется эмпирическим коэффициентом детерминации. Он показывает долю вариации изучаемого признака, обусловленную вариацией группировочного признака.
. Результат отношения межгрупповой к общей дисперсии исходной совокупности называется эмпирическим коэффициентом детерминации. Он показывает долю вариации изучаемого признака, обусловленную вариацией группировочного признака.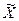 , а численность единиц выборочной совокупности обозначается через n.
, а численность единиц выборочной совокупности обозначается через n.  и характеризует среднюю величину отклонений выборочных показателей от генеральных и при этом должно соблюдаться следующее соотношение:
и характеризует среднюю величину отклонений выборочных показателей от генеральных и при этом должно соблюдаться следующее соотношение:  .
. и
и  .
.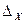 и вычисляется по формуле
и вычисляется по формуле  , где
, где  .
. ; для бесповторного отбора:
; для бесповторного отбора:  ; где
; где  - дисперсия выборочной совокупности.
- дисперсия выборочной совокупности. ; для бесповторного отбора:
; для бесповторного отбора: 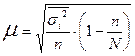 ; где
; где  - средняя из внутригрупповых дисперсий.
- средняя из внутригрупповых дисперсий. ; для бесповторного отбора:
; для бесповторного отбора:  ; где
; где 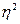 - межгрупповая дисперсия; r – количество групп или серий в выборочной совокупности; R – количество групп или серий в генеральной совокупности.
- межгрупповая дисперсия; r – количество групп или серий в выборочной совокупности; R – количество групп или серий в генеральной совокупности. ;
;  ;
;  , и т. д.
, и т. д. . Рассмотрим аналитическое выравнивание ряда динамики по линейной функции
. Рассмотрим аналитическое выравнивание ряда динамики по линейной функции  , где t – параметр времени; a и b – параметры линейной функции. Для определения параметров линейной функции a и b составляют систему уравнений:
, где t – параметр времени; a и b – параметры линейной функции. Для определения параметров линейной функции a и b составляют систему уравнений: 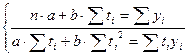 .
. ; b = -0, 63; a =19, 3;
; b = -0, 63; a =19, 3;  .
.