|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Значение и сущность группировки
Русский статистик Д. П. Журавский (1810—1856) очень точно определил статистику как «счет по категориям». Действительно, среди бесконечного разнообразия явлений мы, как правило, улавливаем наличие некоторого конечного числа групп или типов, Лицо каждого человека неповторимо, и все-таки можно классифицировать лица по типам (скуластое, продолговатое, круглое); предприятия образуют группы по формам собственности, характеру производимой продукции, размерам (крупные, средние, мелкие), финансовому положению; государства делятся на группы по уровню экономического развития и т.д. Примеров можно приводить много, но ясно, что какую бы совокупность мы ни изучали, она всегда подразделяется на группы. Это обусловлено такими объективными свойствами явлений, как вариация, наличие частных совокупностей (см. гл. 1). Группировка — это распределение единиц по группам в соответствии со следующим принципом: различия между единицами, отнесенными к одной группе, должны быть меньше, чем между единицами, отнесенными к разным группам. Группировка лежит в основе дальнейшей работы с собранной информацией. На основе группировки рассчитываются сводные показатели по группам, появляется возможность их сравнения, анализа причин различий между группами, изучения взаимосвязей между признаками. Если рассчитать сводные показатели только в целом по совокупности, то мы не сможем уловить ее структуры, роли отдельных групп, их специфики. Например, можно рассчитать среднюю прибыль на одно предприятие, обобщая данные по всем предприятиям данной территории, а можно первоначально разделить их на прибыльные и убыточные, прибыльные — на подгруппы по величине прибыли и только после этого приступить к расчетам средней прибыли в каждой группе (для убыточных предприятий финансовый результат — это средняя сумма убытка на одно предприятие). Тогда можно сравнить успешность работы предприятий по группам, узнать долю каждой группы в общей численности предприятий. Очевидно, что дифференцированный подход даст больше информации и обеспечит лучшее качество анализа и выводов.
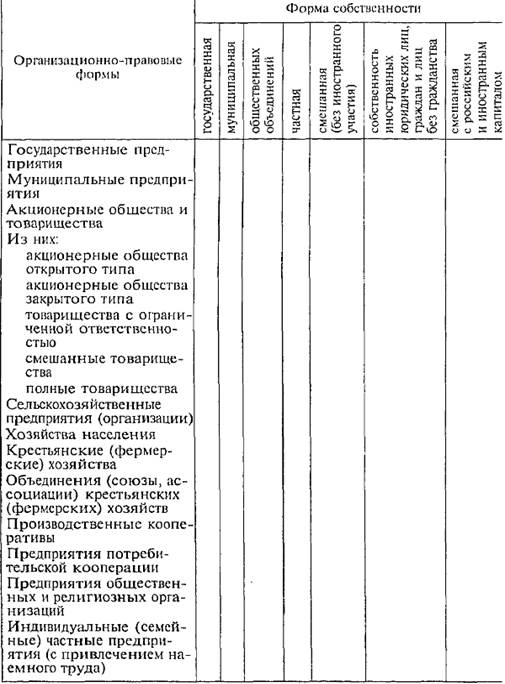
Однородность (гомогенность) данных является исходным условием их статистического описания и анализа — вычисления и интерпретации обобщающих показателей, построения уравнения регрессии, измерения корреляции (гл. 9), статистического умозаключения (гл. 7, 8). Таким образом, значение группировки состоит в том, что этот метод обеспечивает обобщение данных, представление их в компактном, обозримом виде. Кроме того, группировка создает основу для последующей сводки и анализа данных. Для изучения структурных изменений в экономике государственная статистика использует группировку хозяйственных субъектов по формам собственности и организационно-правовым формам (табл. 6.1). Сводные показатели для отдельных групп являются типичными и устойчивыми, если, во-первых, группировка проведена правильно, во-вторых, группы имеют достаточную численность. Первое условие связано с тем, что деление на группы далеко не всегда очевидно. Выполнение второго условия необходимо, так как при достаточно большом числе единиц (не менее пяти в группе) в сводных показателях взаимопогашаются случайные характеристики и проявляются закономерные, типичные. Для решения задачи группировки нужно установить правила отнесения каждой единицы к той или иной группе.
В эти правила входят определения тех характеристик (признаков), по которым будет проводиться группировка (так называемых группировочных признаков), и их значений, отделяющих одну группу от другой (интервалы группировки).
Таблица 6.1 Организационно-правовые формы и формы собственности хозяйственных субъектов Российской Федерации
Продолжение
Группировка называется простой (монотетической), если для ее построения используется один группировочный признак. Если группировка проводится по нескольким признакам, она называется сложной (политетической). Обычно такая группировка проводится как комбинационная, т.е. группы, выделенные по одному признаку, подразделяются на подгруппы по другому признаку. Казалось бы, этот метод выделения групп должен быть лучше простой группировки — ведь трудно ожидать, что различия между группами можно уловить лишь на основе одного признака. Однако комбинация признаков приводит к дроблению совокупности в геометрической прогрессии: число групп будет равно произведению числа вы-
ровки, выявления такого варианта, который наилучшим образом позволяет увидеть различия между группами. При определении числа групп следует обращать внимание на то, чтобы в одну группу не попало свыше половины всех единиц совокупности. Если группировочный признак неколичественный, или количественный дискретный с малым числом значений, то группировка данных проводится путем подсчета числа единиц с данным значением признака. Примером такой группировки является табл. 6.2. Таблица 6.2 Группировка станкостроительных заводов по числу производимых типов станков
Очевидно, что метод группировок тесно связан с представлением данных в виде групповых, или комбинационных, таблиц, а также с графиками структуры совокупности, ее частей и соотношений между ними. Виды группировок
Группировка проводится с целью установления статистических связей и закономерностей, построения описания объекта, выявления структуры изучаемой совокупности. Различия в целевом назначении группировки выражаются в существующей в отечественной статистике классификации группировок: типологические, структурные, аналитические. Типологическая группировка служит для выделения социально-экономических типов. Этот вид группировок в значительной степени определяется представлениями экспертов о том, какие типы могут встретиться в изучаемой совокупности. Чтобы пояснить особенность этой группировки, приведем последовательность действий для ее проведения: 1) называются те типы явлений, которые могут быть выделены; 2) выбираются группировочные признаки, формирующие описание типов; 3) устанавливаются границы интервалов; 4) группировка оформляется в таблицу, выделенные группы (на основе комбинации группировочных признаков) объединяются в намеченные типы, и определяется численность каждого из них. Пример. Поставлена задача выделить типы акционерных компаний с высокими, средними и низкими дивидендами и установить распространенность каждого типа в данном регионе. Показатель выплаты дивидендов характеризует долю прибыли на акцию или долю чистого дохода, выплачиваемого как дивиденды.
Этот коэффициент зависит от структуры акционерного капитала фирмы, длительности существования фирмы и перспектив ее роста. Обычно молодые, быстрорастущие компании выплачивают низкие дивиденды, если вообще их выплачивают; тогда как компании, давно работающие на рынке, стремятся дать более высокие дивиденды. Структура капитала и выплата дивидендов зависят от отраслевой принадлежности фирмы. Поэтому при классификации фирм по уровню выплаты дивидендов мы должны использовать в качестве группировочных признаков, во-первых, отрасль (подотрасль), во-вторых, показатель выплаты дивидендов. Первый группировочный признак выполняет роль характеристики условий, второй непосредственно характеризует тип фирмы. Границы интервалов для второго группировочно-го признака могут изменяться при переходе от одной отрасли к другой, так как то, что для одной отрасли может рассматриваться как высокий уровень выплаты, для другой может оцениваться иначе. Изменение границ интервалов группировочного признака при выделении одних и тех же типов в разных условиях называется специализацией интервалов группировочного признака. Иногда условия формирования типов приводят к различиям в их описании, в самих признаках. Например, выделение крупных, средних, мелких предприятий в разных отраслях должно проводиться по разным характеристикам: в энер- гоемких отраслях — по потреблению электроэнергии; в сырь-еемких — по величине товарно-материальных запасов; в трудоемких — по численности рабочих; в капиталоемких — по стоимости оборудования. Изменение круга группировочных признаков при выделении одних и тех же типов в разных условиях называется специализацией группировочных признаков. Вернемся к нашему примеру. Предположим, что мы располагаем данными 15 фирм, представляющих три подотрасли промышленности. Проведем их группировку с учетом двух выше названных признаков (табл. 6.3).
Табли ца 6.3 Группировка акционерных компаний и-го района по уровню выплаты дивидендов за 200_ г.
Использование специализации интервалов как бы уравнивает наши оценки компаний в разных отраслях, что позволяет объединить выделенные группы в три типа независимо от отрасли (табл. 6.4). Это последний шаг типологической группировки. Как видим, данный метод позволяет избежать чрезмерного дробления совокупности, но он слишком субъективен: эксперт определяет, какие типы должны быть выделены, по каким признакам, какими должны быть границы интервалов. К тому же число группировочных признаков ограничено дву-
Таблица 6.4 Распределение акционерных компаний л-го района по типам в 200 г.
В любом случае правильность проведения типологической группировки требует проверки. С этой целью рассчитываются сводные показатели по группам (средние, относительные величины); если различие между группами статистически незначимо (по /-критерию Стыодента или ^-критерию, или критерию х2 и т.д. (гл. 7)), то схема группировки должна быть пересмотрена — схожие группы могут быть объединены, изменены границы интервалов и т.д. Структурная группировка характеризует структуру совокупности по какому-либо одному признаку (табл. 6.5). Если для типологической группировки чаще используются открытые и неравные интервалы, то для структурной группировки более характерны закрытые равные интервалы. Структурная группировка — это ряд распределения. Она позволяет изучать интенсивность вариации группировочного признака (см. гл. 5). На основе структурной группировки можно изучать динамику структуры совокупности.
Таблица 6.5 Распределение крестьянских (фермерских) хозяйств России по размеру земельного участка (на конец года; в процентах)
Если показатели структуры выразить не в долях, а в процентах, то, также как и первый показатель, квадратичный коэффициент абсолютных структурных сдвигов оценивает: на сколько процентных пунктов в среднем различаются удельные веса групп сравниваемых структур. При отсутствии структурных сдвигов оба эти показателя равны нулю; их величина тем больше, чем значительнее абсолютные изменения удельных весов групп. Квадратичный коэффициент более чутко реагирует на структурные изменения. Существуют и другие показатели для измерения структурных сдвигов (см., например, индекс структуры в гл. 14). При сравнениях предполагается, что число групп в одном и другом периодах остается одним и тем же. По данным табл. 6.5 sW1...Wn = 2, 4 процентного пункта, т.е. средний квадратичный показатель превышает средний арифметический (по свойству мажорантно-сти средних).
Деление группировок на типологические и структурные достаточно условно. Если задать, например, границы среднедушевого дохода, соответствующие определенным типам благосостояния, то можно с полным правом назвать полученную группировку типологической. Аналитическая группировка характеризует взаимосвязь между двумя и более признаками, из которых один рассматривается как результат, другой (другие) — как фактор (факторы). Пример однофакторной аналитической группировки представлен в табл. 6.6. В данном примере оборачиваемость в днях — фактор, обозначенный х, прибыль — результат — у. Очевидно, что при одной и той же продолжительности оборота предприятия могут иметь разную прибыль. Для того чтобы установить связь между признаками, данные группируются по признаку-фактору. Затем по каждой группе рассчитывается среднее значение результата. По обобщенным данным гораздо легче увидеть, есть связь между признаками или нет, прямая связь или обратная, линейная или нелинейная. Эти выводы делаются
Таблица 6.6 Характеристика зависимости прибыли предприятий от оборачиваемости оборотных средств за 200_ г.
Можно с некоторыми оговорками заключить, что на 55% вариация прибыли в этой совокупности предприятий определяется вариацией изучаемых факторов. Многофакторная аналитическая группировка — очень гибкий прием изучения связей. Она позволяет уловить влияние факторов на результат с изменением условий (закреплением прочих факторов на разных уровнях). Однако при всех отмеченных плюсах этот метод имеет огромный минус — дробление совокупности, в результате чего выделяются подгруппы с малым числом единиц. В этом случае средние значения результативного признака неустойчивы, не достигается погашение прочих факторов, соответственно ненадежными становятся и показатели связи. Но если совокупность большого объема и распределение признаков-факторов не являются крайне асимметричными, этот метод, как никакой другой, позволяет получить много информации об отношениях между переменными. В какой-то мере избежать дробление данных и при этом получить «чистые» характеристики связей между переменными позволяет применение метода стандартизации распределений в комбинационной таблице. Если в группах по одной переменной, скажем по г в табл. 6.7, распределение по другой переменной х принять стандартным и на его основе рассчитать групповые средние величины результативного признака, то они будут отличаться за счет принадлежности к разным группам по признаку г при элиминировании признака х. В качестве стандартного применяется распределение в целом по совокупности. Так, по данным табл. 6.7 стандартное распределение по х следующее:
Многомерные группировки Мы убедились, как трудно выбрать какой-то один признак в качестве основы группировки. Еще труднее проводить группировку по нескольким признакам. Комбинация двух признаков позволяет сохранить обозримость таблицы, но комбинация трех или четырех признаков дает совершенно неудовлетворительный результат: ведь даже при выделении трех категорий по каждому из группировочных признаков мы получим 9 или 27 подгрупп. Равномерность распределения единиц по группам в принципе невозможна. Вот и получаются группы, в которые входят 1—2 наблюдения. Сохранить сложность описания групп и вместе с тем преодолеть недостатки комбинационной группировки позволяют методы многомерных группировок. Часто их называют методами многомерной классификации. Эти методы получили распространение благодаря использованию ПЭВМ и пакетов прикладных программ. Цель этих методов — классификация данных, иначе говоря, группиров- --- конец страницы ---
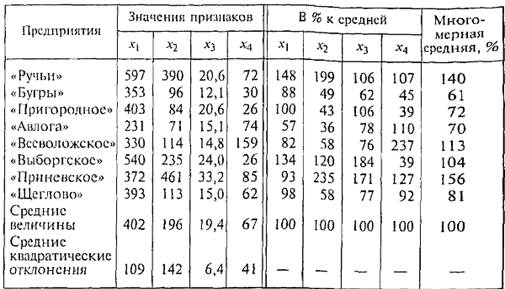
----------стр. 192 ____________________ ка на основе множества признаков. Такие задачи широко распространены в науках о природе и обществе, в практической деятельности по управлению массовыми процессами. Например, выделение типов предприятий по финансовому положению, по экономической эффективности деятельности проводится на основе множества признаков; то же при выделении групп клиентов в банке. Простейшим вариантом многомерной классификации является группировка на основе многомерных средних. Многомерной средней называется средняя величина нескольких признаков для одной единицы совокупности. Поскольку нельзя рассчитать среднюю величину абсолютных значений разных признаков, выраженных в разных единицах измерения, то многомерная средняя вычисляется из относительных величин, как правило, — из отношений значений признаков для единицы совокупности к средним значениям этих признаков:
Таблица 6.9 Характеристики предприятий Всеволожского района Ленинградской области в 1999 г.
Эти признаки можно считать однородными, так как большая их величина положительно характеризует экономику предприятия. Предпочтительнее обобщать в многомерной средней признаки, либо все «положительные», либо все «отрицательные» (чем больше, тем хуже). Многомерные средние, приведенные в последней графе табл. 6.9, обобщают четыре признака. При этом значимость признаков для оценки предприятия полагается одинаковой, что, конечно, спорно. Можно усложнить методику, приписав признакам на основе экспертной оценки разные веса, и вычислить взвешенные многомерные средние. Судя по полученным значениям рь предприятия делятся на группы с многомерными средними ниже 100% (четыре предприятия), несколько выше 100% (два предприятия) и резко превышающие 100% (два предприятия). При большом объеме совокупности для выделения групп на основе многомерной средней необходимо установить интервалы значений многомерной средней:
Затем следует провести группировку единиц: определить их количество в каждой группе и постараться указать, в чем состоят качественные различия между группами. Более обоснованным методом многомерной классификации является кластерный анализ. Само название метода этимологически берет начало от слов «класс», «классификация». Английское слово «the cluster» имеет значения: группа, пучок, куст, т.е. объединение каких-то однородных явлений. В данном контексте оно близко к математическому понятию «множество», причем, как и множество, кластер может содержать только одно явление, но не может в отличие от множества быть пустым. Каждая единица совокупности в кластерном анализе рассматривается как точка в заданном признаковом пространстве. Значение каждого из признаков у данной единицы служит ее координатой в этом пространстве по аналогии с координатами точки в нашем реальном трехмерном пространстве. Таким образом, признаковое пространство — это область варьирования всех признаков совокупности изучаемых явлений. Если мы уподобим это пространство обычному пространству, имеющему евклидову метрику, то тем самым получим возможность измерять «расстояния» между точками признакового пространства. Эти расстояния называют евклидовыми. Их вычисляют по тем же правилам, что и в обычной евклидовой геометрии. На плоскости, т.е. в двухмерном пространстве, расстояние между точками А я В равно корню квадратному из суммы квадратов разностей координат этих точек по оси абсцисс и по оси ординат — на основе теоремы Пифагора (рис. 6.1):
Совершенно очевидно, что нельзя суммировать квадраты отклонений одной точки от другой в абсолютных значениях
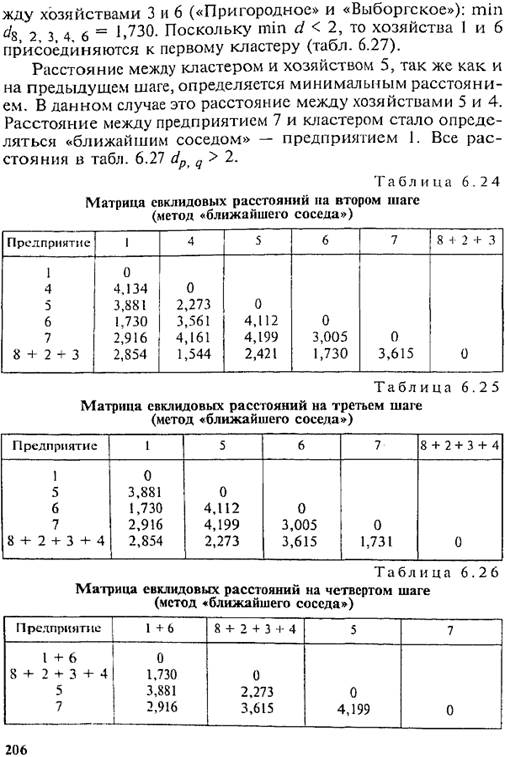
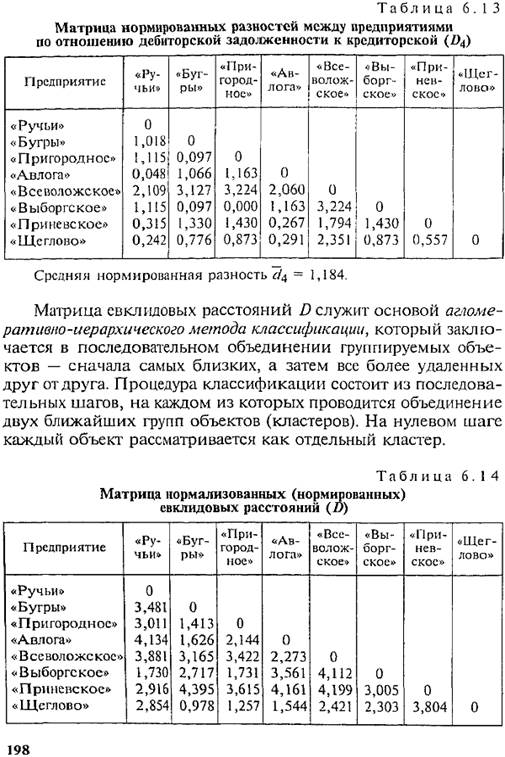
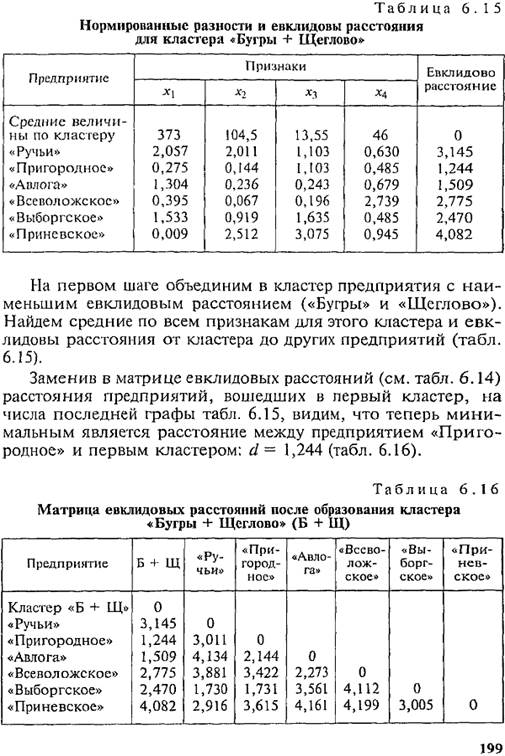
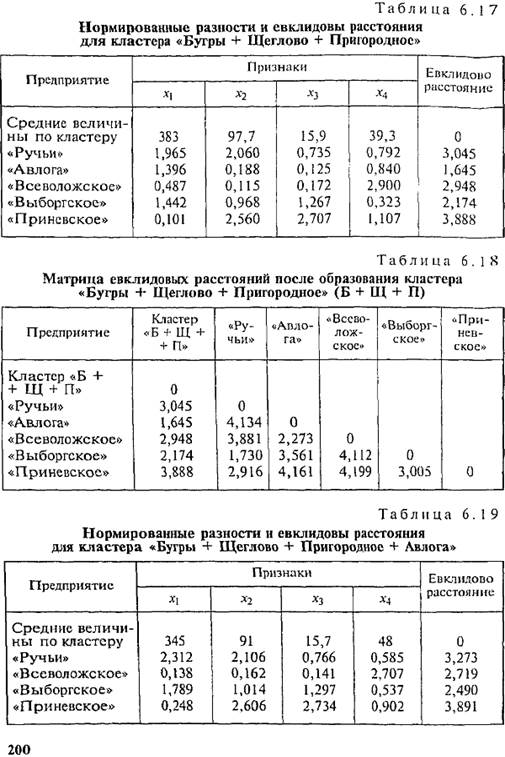
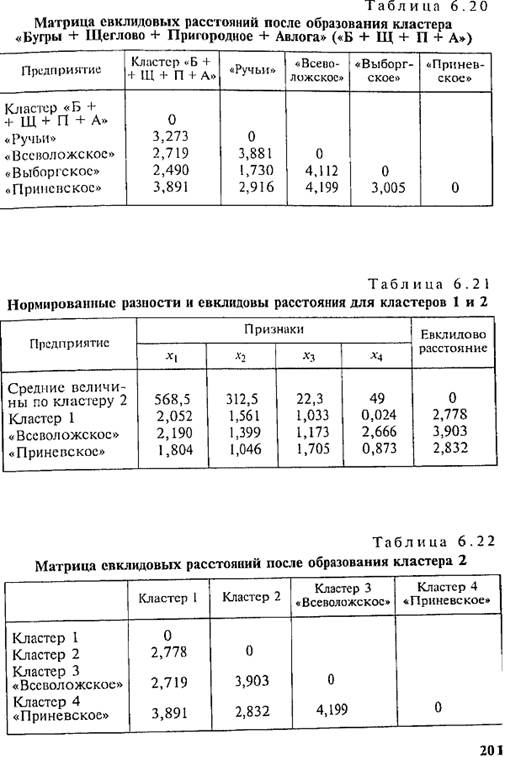
Следовательно, на втором шаге к первому кластеру присоединяется предприятие «Пригородное». Вычисляем средние величины, нормированные разности по каждому признаку и евклидовы расстояния от кластера, включающего три предприятия («Бугры», «Щеглово», «Пригородное»), до каждого из оставшихся предприятий. Результаты представлены в табл. 6.17. Заменив евклидовы расстояния предприятий, вошедших в кластер, данными последней графы табл. 6.17, получим новую матрицу евклидовых расстояний (табл. 6.18). Минимальным является евклидово расстояние от кластера до предприятия «Авлога». На третьем шаге образуем кластер «Бугры + Щеглово + Пригородное + Авлога». Полученные средние величины для кластера, нормированные разности и евклидовы расстояния представлены в табл. 6.19 и 6.20. Минимальное евклидово расстояние между предприятиями «Ручьи» и «Выборгское» меньше двух, следовательно, эти предприятия объединяются в кластер 2 (табл. 6.21). Кластер «Б + Щ + П + А» будем называть кластером 1. После четвертого шага получаем новую матрицу евклидовых расстояний (табл. 6.22). Согласно табл. 6.22 все расстояния больше двух. Оставляем четыре типа предприятий: предприятия, вошедшие в кластер 1, кластер 2, кластер 3 («Всеволожское») и кластер 4 («Приневское»). Сравнивая результат кластерного анализа с многомерными средними (см. табл. 6.9), видим, что состав кластера 1 точно отвечает тем хозяйствам, чьи многомерные средние ниже 100%. Также выделение в самостоятельный кластер предприятия «Приневское» соответствует его высшему значению многомерной средней. А вот объединение в кластер 2 предприятий «Ручьи» и «Выборгское» не соответствует многомерным средним, по которым к предприятию «Ручьи» было ближе предприятие «Всеволожское». В результате резкого отличия по признаку X4 предприятие «Всеволожское» выделилось в отдельный кластер 3. Обобщая рассмотренную процедуру кластерного анализа, представим действия в виде определенной последовательности. 1. Вычисление средних величин для каждого из классификационных признаков х: в целом по совокупности.
Субъективность экспертных оценок в какой-то мере можно компенсировать статистической обработкой. Например, по каждому признаку перед определением средней оценки его веса можно отбросить максимальную и минимальную оценки, если они существенно отличаются от оценок остальных экспертов. Можно вообще исключить того эксперта, чьи оценки в среднем отличаются от средних оценок признаков более чем, например, на 2а. Однако эти статистические коррективы небезупречны и допустимы при значительном числе экспертов для того, чтобы их средние оценки были надежны. Существует и другая возможность оценки роли группиро-вочных признаков, их значимости для классификации: на основе стандартизованных коэффициентов регрессии или коэффициентов раздельной детерминации (гл. 9).
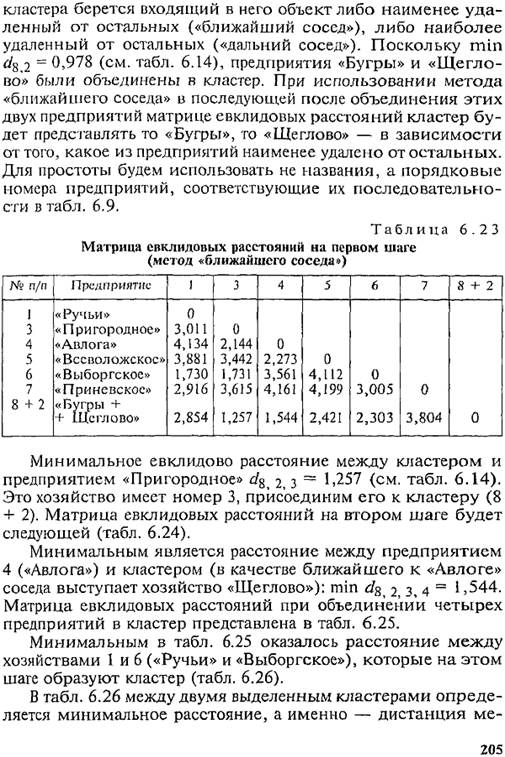
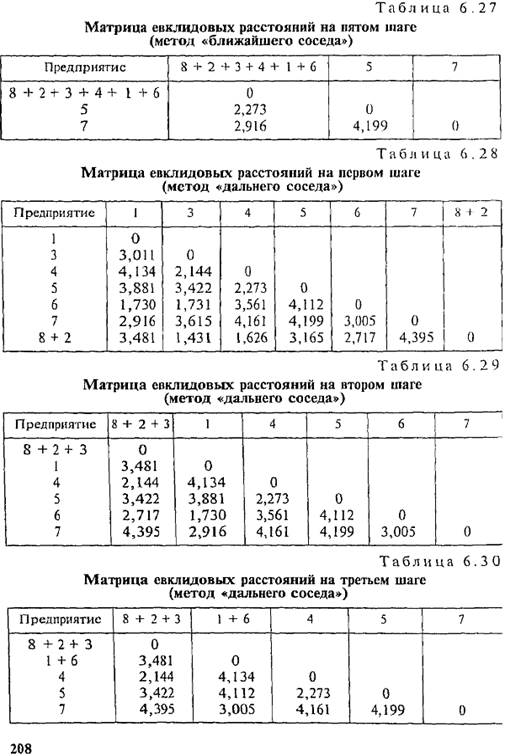
Рассмотренный алгоритм иерархической классификации можно модифицировать, используя метод «.ближайшего» или «дальнего соседа» (табл. 6.23). В этом случае в матрицу евклидовых расстояний вводятся расстояния, полученные не на основе средних величин по кластеру; в качестве представителя
РЕЗЮМЕ
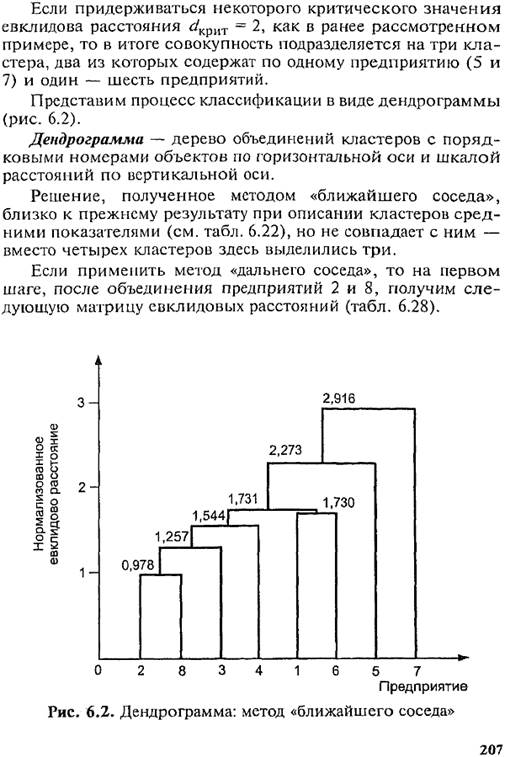
Требование однородности данных выдвигается на всех этапах статистического анализа. Для получения однородных данных проводится группировка. При этом различия между единицами, отнесенными к одной группе, должны быть меньше, чем между единицами, отнесенными к разным группам. Проведение группировки включает выбор группировочного признака (или признаков) и определение границ интервалов. Чаще всего группировки проводятся с равными интервалами, но при неравномерном изменении группировочного признака и его значительной вариации применяются группировки с равнонаполненными интервалами. В зависимости от цели проведения различают следующие виды группировок: типологические, структурные, аналитические. Типологическая группировка проводится с целью выделения социально-экономических типов. Структурная группировка соответствует вариационному ряду. Аналитическая группировка строится для изучения зависимости одного признака от другого. На ее основе измеряются сила и теснота связи, т.е. вычисляется эмпирическое корреляционное отношение. Для погашения влияния прочих факторов в аналитической группировке целесообразно рассчитывать стандартизованные групповые средние. Выводы о характере и интенсивности связи между признаками во многом зависят от выбранного числа групп. При необходимости группировки по многим признакам для каждой единицы рассчитывают многомерную среднюю, а затем по ее значениям группируют данные. Многомерные группировки часто называют многомерными классификациями. Они бывают иерархические, неиерархические, основанные на мерах различия или сходства. В качестве меры различия чаще всего используется евклидово расстояние. Среди иерархических классификаций выделяются метод средних, метод «ближайшего соседа», метод «дальнего соседа».
Исходя из структуры типа (ядро + слой) развиваются вероятностные классификации, так называемые классификации в размытых (нечетких) множествах.
РЕКОМЕНДУЕМАЯ ЛИТЕРАТУРА
1. Айвазян С. А., Мхитарян В. С. Теория вероятностей и прикладная статистика. Т. 1: Учебник для вузов. — 2-е изд. — М.: ЮНИТИ, 2001. 2. Афифи А., Эйзен С. Статистический анализ. Подход с использованием ЭВМ: Пер. с англ. — М.: Мир, 1982. 3. Елисеева И. И., Рукавишников В. О. Группировка, корреляция, распознавание образов. — М.: Статистика, 1977. 4. Енюков И. С, Методы — алгоритмы — программы многомерного статистического анализа. — М.: Финансы и статистика, 1986. 5. Козлов А, Ю., Шишлов В. Ф. Пакет анализа MS Excel в экономико-статистических расчетах / Под ред. В. С. Мхитаряна. — М.: ЮНИТИ, 2003. 6. Кулаичев А. П. Методы и средства анализа данных в среде Windows. Stadia 6.0. — М.: НПО «Информатика и компьютеры», 1996. 7. Манделъ И. Д. Кластерный анализ. — М.: Финансы и статистика, 1988. 8. Миркин Б. Г, Группировки в социально-экономических исследованиях. — М.: Финансы и статистика, 1985.
Популярное:
|
Последнее изменение этой страницы: 2016-08-24; Просмотров: 1218; Нарушение авторского права страницы
 174
174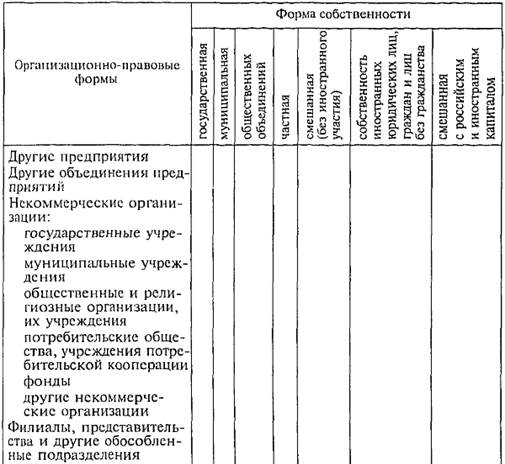
 Бывает, что число групп заранее неизвестно и определяется опытным путем на основе перебора вариантов группи-
Бывает, что число групп заранее неизвестно и определяется опытным путем на основе перебора вариантов группи-
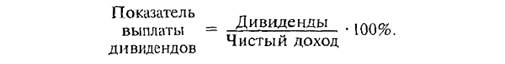
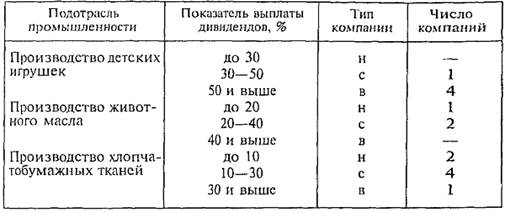 Примечание. Здесь: н — с низким показателем выплаты дивидендов; с — со средним показателем выплаты дивидендов; в — с высоким показателем выплаты дивидендов.
Примечание. Здесь: н — с низким показателем выплаты дивидендов; с — со средним показателем выплаты дивидендов; в — с высоким показателем выплаты дивидендов. мя-тремя. Однако если объект исследования хорошо изучен, если имеется развитая теория, то этот метод может дать хорошо интерпретируемые результаты.
мя-тремя. Однако если объект исследования хорошо изучен, если имеется развитая теория, то этот метод может дать хорошо интерпретируемые результаты.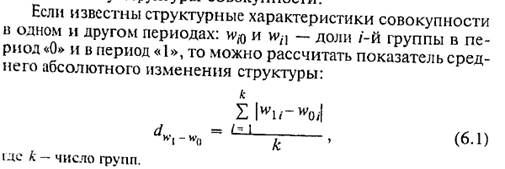 180
180
 182
182


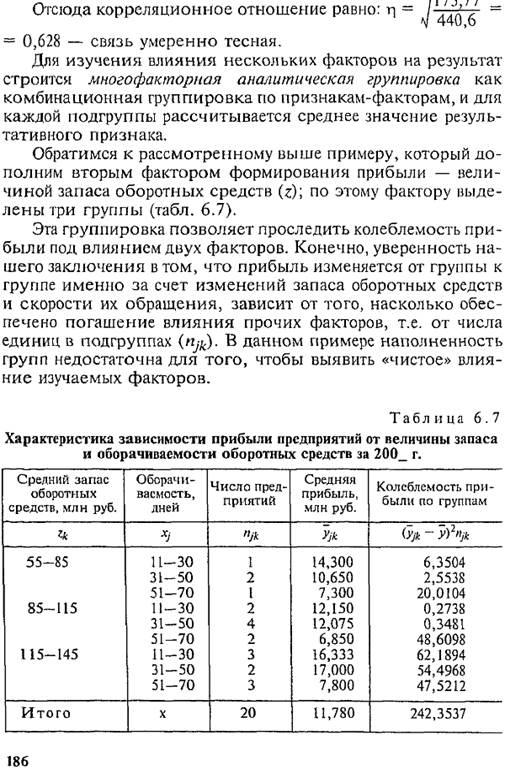



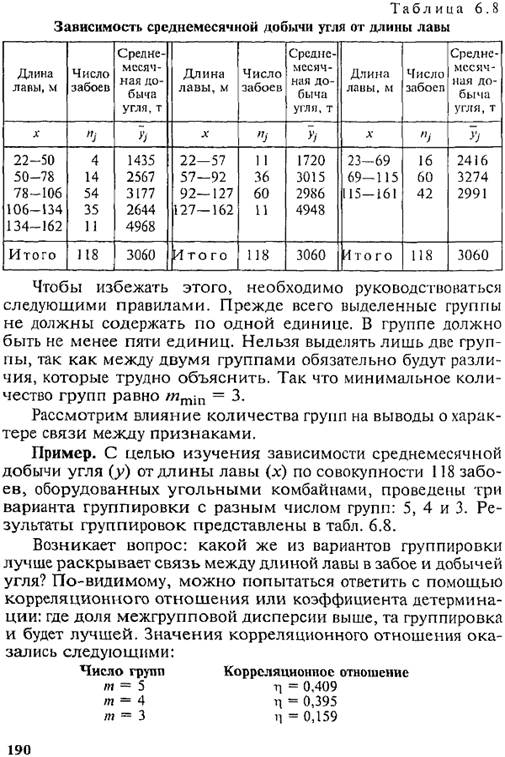
 В рассмотренном примере группировка с четырьмя группами максимально раскрывает действие признака-фактора на результат.
В рассмотренном примере группировка с четырьмя группами максимально раскрывает действие признака-фактора на результат.
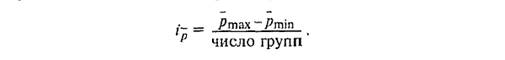
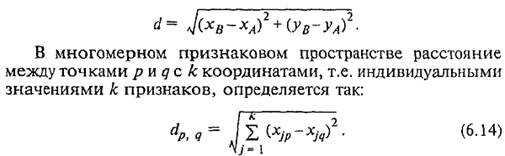
 195
195

 Опоеделение весов - весьма сложная задача, выходящая за пределы компетенции статистики. О том какие признаки важнее при классификации тех или иных объектов, могут судить не статистики, а специалисты в соответствующей отрасли. Поэтому одним из способов определения весов признаков при кластерном анализе являются оценки экспертов. Опросив специалистов-экспертов (не менее 6-10), статистик сможет определить по их оценкам место (роль) каждого группировоч-ного признака. Затем найти средний «вес» признака. Можно просить экспертов ранжировать признаки по порядку значимости и определять «среднее место», но оценка при этом будет очень грубая: признак, поставленный на первое место, будет вдвое важнее второго и в двадцать или тридцать раз важнее последнего. Для того чтобы различия весов были не столь значительными, можно просить экспертов распределить общую сумму оценок (100 или 1000%) между группировочными признаками в соответствии с их значениями. Тогда каждому из признаков будет приписана некоторая доля этой общей суммы, можно двум-трем признакам приписать одинаковые веса. Но этот способ взвешивания требует от экспертов большей точности и напряжения, чем простое ранжирование признаков.
Опоеделение весов - весьма сложная задача, выходящая за пределы компетенции статистики. О том какие признаки важнее при классификации тех или иных объектов, могут судить не статистики, а специалисты в соответствующей отрасли. Поэтому одним из способов определения весов признаков при кластерном анализе являются оценки экспертов. Опросив специалистов-экспертов (не менее 6-10), статистик сможет определить по их оценкам место (роль) каждого группировоч-ного признака. Затем найти средний «вес» признака. Можно просить экспертов ранжировать признаки по порядку значимости и определять «среднее место», но оценка при этом будет очень грубая: признак, поставленный на первое место, будет вдвое важнее второго и в двадцать или тридцать раз важнее последнего. Для того чтобы различия весов были не столь значительными, можно просить экспертов распределить общую сумму оценок (100 или 1000%) между группировочными признаками в соответствии с их значениями. Тогда каждому из признаков будет приписана некоторая доля этой общей суммы, можно двум-трем признакам приписать одинаковые веса. Но этот способ взвешивания требует от экспертов большей точности и напряжения, чем простое ранжирование признаков.