
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
ОРГАНИЗАЦИЯ И ВИДЫ СТАТИСТИЧЕСКОГО НАБЛЮДЕНИЯСтр 1 из 5Следующая ⇒
ВВЕДЕНИЕ
Предмет статистики – количественная сторона массовых явлений, выявление их закономерностей. Термин «статистика» употребляется в 3-х смыслах: - область деятельности, связанная со сбором, обработкой, анализом и публикацией данных о массовых явлениях; - сам цифровой материал; - научная дисциплина. В математической статистике под термином «статистика» понимают также некоторую функцию от результатов наблюдения, которая имеет определенный закон распределения и используется для оценки параметров или проверки статистических гипотез. Базовым понятием статистики является понятие « статистической совокупности » как некоторого множества « элементов совокупности » (предприятий, людей и т. д.) Элемент совокупности может характеризоваться различными признаками, а статистическая совокупности – статистическими показателями. Признак представляет собой качественную или количественную характеристику элемента совокупности (пол, возраст, стаж работы и т. д.). Статистический показатель – некая характеристика статистической совокупности (численность населения, средний возраст и т. д.). В литературе по статистике часто можно встретить термин «единица совокупности», который тождественен понятию «элемента совокупности». Методология статистики в основном опирается на результаты, полученные в математической статистике. Естественно, что курс «Статистика» не может не включать отдельные приемы математической статистики, помогающие раскрыть статистические закономерности. Однако эти приемы рассматриваются в основном в прикладном плане без строгих математических доказательств.
ОРГАНИЗАЦИЯ И ВИДЫ СТАТИСТИЧЕСКОГО НАБЛЮДЕНИЯ В любом статистическом исследовании можно выделить несколько этапов. Статистическое изучение тех или иных явлений требует наличия информации об этих явлениях, Поэтому первый этап, начало статистического исследования, заключается в сборе необходимой информации. Научно организованный сбор сведений, заключающийся в регистрации тех или иных признаков, относящихся к каждой единице (элементу) изучаемой совокупности, именуют статистическим наблюдением. Если при сборе первичных статистических данных допущена ошибка, это повлияет на достоверность как теоретических, так и практических выводов. Поэтому статистическое наблюдение должно быть тщательно продуманным и четко организованным. В результате статистического наблюдения собирается первичная информация о каждой единице совокупности. Чтобы получить характеристику всей исследуемой совокупности в целом, первичные данные должны быть подвергнуты обобщению и оформлению в виде таблиц, что составляет второй этап статистического исследования, именуемый сводкой. И наконец, на основе итоговых данных сводки осуществляется научный анализ исследуемых явлений, рассчитываются различные статистические показатели. Статистическое наблюдение должно носить массовый характер для того, чтобы получить правдивые статистические данные, характеризующие всю совокупность в целом. Статистическое наблюдение может быть сплошным и не сплошным. Сплошное наблюдение предполагает полный учет всех элементов изучаемой совокупности (например, перепись населения). К не сплошному наблюдению прибегают в тех случаях, когда физически невозможно или трудно осуществить сплошное наблюдение. Не сплошное наблюдение может быть осуществлено по разному. Различают следующие его виды: - наблюдение основного массива; - выборочное наблюдение; - монографическое наблюдение. Наблюдение основного массива предполагает исключение из состава совокупности малозначимых единиц и исследование основной ее части. При использовании наблюдения основного массива исходят из соображения, что исключение определенной части малозначимых единиц не отразится существенно на результатах, в то время как включение этих единиц значительно увеличит объем работы и соответственно затраты. Из сказанного очевидно, что применение наблюдения основного массива возможно лишь в случаях, когда можно заранее решить какие единицы малозначимые, а какие нет. При выборочном наблюдении характеристика всей совокупности дается по результатам исследования некоторой ее части (выборки), отобранной в случайном порядке (например, опросы перед выборами). Сама же изучаемая совокупность (множество всех элементов) называется генеральной совокупностью. Выборка должна быть репрезентативной (представительной), чтобы правильно отражать свойства генеральной совокупности (например, не должен быть опрос только мужчин или городских жителей). Для однородной генеральной совокупности репрезентативность гарантируется случайностью отбора. Отбор элементов из неоднородной совокупности предполагает разделение генеральной совокупности на однородные группы с последующей случайной выборкой внутри групп. Объекты разных групп включаются в выборку пропорционально их численности в генеральной совокупности. Отбор может быть повторным (с возвращение выбранного элемента обратно в совокупность) или бесповторным (один элемент не может быть включен в выборку дважды). Монографическое исследование представляет собой детальное изучение какой-то одной единицы совокупности (конкретного рабочего, предприятие и т. д.). Иногда эта единица рассматривается как типичная, и ее детальное изучение дает более широкое представление о всех единицах данной совокупности.
Задание 1 В табл. 1 приведены 5 показателей деятельности торговых предприятий. В соответствии с таблицей выберите номера 2-х показателей
На основании имеющихся данных выполнить: 1. Структурную группировку по первому и второму показателям, приняв число групп, равным 5. 2. Аналитическую группировку, считая первый показатель признаком-фактором, а второй – признаком-результатом. 3. Комбинационную группировку при числе групп по обоим признакам, равным 3.
Т а б л и ц а 1 Показатели деятельности торговых предприятий за год
СТАТИСТИЧЕСКИЕ ПОКАЗАТЕЛИ ЦЕНТРА РАСПРЕДЕЛЕНИЯ Средняя арифметическая - для несгруппированных данных
- для сгруппированных данных
где xi − ni − частота i-й группы; k − количество групп.
2. Медиана Ме(x) Медиана представляет собой такое значение признака, которое делит объем совокупности пополам в том смысле, что число элементов совокупности со значениями признака, меньшими медианы, равно числу элементов совокупности со значениями признака, большими медианы. Численное значение медианы можно определить по ряду накопленных частот. Накопленная частота для медианы равна половине объема совокупности:
Для интервального ряда сначала определяется интервал, в котором будет находиться медиана. Само же значение Ме(x) может быть приближенно определено с помощью интерполяции
где x0 − начало интервала, содержащего медиану; D − величина интервала, содержащего медиану; F(x0) − накопленная частота на начало интервала, содержащего медиану; n − объем совокупности; n0 − частота интервала, в котором расположена медиана.
3. Мода Мо(Х) – наиболее часто встречающееся значение признака в совокупности. Для дискретного ряда это то значение признака, которому соответствует наибольшая частота распределения. Для интервального ряда вначале определяется интервал, содержащий моду (с наибольшей частотой). Затем приближенно вычисляется значение моды по формуле
где х0 – начало интервала, содержащего моду; D − величина интервала; n0 – частота интервала, в котором расположена мода; n-1 – частота интервала, предшествующего модальному; n1 – частота интервала, следующего за модальным.
Задание 2. 1. На основе структурной группировки по второму показателю, полученной в задании 1, построить гистограмму и кумуляту. 2. Вычислить по сгруппированным данным: - среднее арифметическое; - медиану и моду; - дисперсию и среднее квадратическое отклонение; - коэффициент вариации.
АНАЛИЗ ВРЕМЕННЫХ РЯДОВ
Временной ряд представляет собой ряд числовых значений какого-либо показателя в последовательные моменты или периоды времени. Числовые значения, составляющие временной ряд, называются уровнями ряда. По способу построения ряд может быть моментным, когда уровни ряда представлены на определенные моменты времени (конец квартала, начало года и т.д.) и интервальным, когда уровни ряда соответствуют определенным интервалам времени. Изучение различных процессов на основе временных рядов включает следующие этапы: - сбор исходной информации и построение временных рядов; - визуальный анализ временного ряда и формирование набора возможных моделей прогнозирования; - идентификация (подбор) модели; - оценка параметров моделей; - осуществление прогноза по математической модели. В практике анализа временных рядов принято считать, что значения уровней временных рядов складываются из следующих компонент: - тренд; - сезонная составляющая; - циклическая составляющая; - случайная составляющая. Под трендом (тенденцией) понимают изменения, определяющие общее направление развития изучаемого показателя. Это систематическая составляющая долговременного действия. Для описания тренда используют плавно меняющиеся, гладкие функции. Наряду с долговременными тенденциями во временных рядах часто имеют место более или менее регулярные колебания – периодические составляющие рядов динамики. Если период колебаний не превышает одного года, то их называют сезонными. Причины сезонных колебаний могут быть связаны с природно-климатическими условиями, могут носить социальный характер (например, увеличение покупок в предпраздничные дни, увеличение платежей в конце квартала и т. д.). Для описания сезонной компоненты используют периодические функции. При большом периоде колебаний считают, что во временных рядах имеется циклическая составляющая. Примерами могут служить демографические, деловые, инвестиционные и другие циклы. Если из временного ряда удалить тренд и периодические составляющие, то останется нерегулярная компонента. Часто причиной нерегулярных колебаний является действие большого числа различных факторов. Эта компонента рассматривается как случайная. Для временных рядов, не имеющих тренда (стационарных), представляет интерес определение их среднего уровня. Средний уровень интервального ряда рассчитывается как простое среднее арифметическое
где
Моментные ряды отличаются от интервальных принципиальной неполнотой информации. Предположим, что уровни
Показатели динамики – это величины, характеризующие изменения уровней временного ряда. К ним относятся абсолютный прирост, коэффициент (темп) роста и коэффициент (темп) прироста. Различают базисные и цепные показатели динамики. Базисные показатели – это результат сравнения текущего уровня ряда с одним фиксированным уровнем, принятым за базу (обычно это начальный уровень ряда). Цепные показатели – это результат сравнения текущего уровня ряда с предшествующим уровнем. Формулы для расчета показателей представлены в табл. Таблица Показатели динамики
Рассмотрим определение среднего абсолютного прироста (цепного). Предположим, что имеется временной ряд y1, y2, …, yn. Тогда Средний абсолютный прирост
Рассмотрим определение среднего коэффициента роста (цепного) Предположим, что имеется временной ряд y1, y2, …, yn. Тогда Средний коэффициент роста
Временной ряд может быть представлен в виде
где f( et – случайная составляющая; Одним из методов выделения тренда является сглаживание временного ряда с помощью скользящего среднего. Метод состоит в замене уровней ряда динамики
Например, при к=2, 2к+1=5 и
Получаемый таким образом ряд скользящих средних ведет себя более гладко, чем исходный ряд, из-за усреднения отклонений ряда. Действительно, если индивидуальный разброс значений члена временного ряда В результате сглаживания получается ряд с меньшим количеством уровней, так как крайние значения теряются.
Пример. Провести сглаживание временного ряда
Например, при t=2 по приведенной выше формуле получим
при t=3
В результате получим сглаженный ряд
При аналитическом выравнивании подбирают математическую функцию, значения которой наиболее близки к уровням выравниваемого ряда. Выравнивание ряда сводится к определению параметров Предположим, что имеет место линейная зависимость
Найдем оценки коэффициентов a и b по фактическим данным об уровнях ряда (ti; yi) (i=1, …, n) так, чтобы сумма квадратов отклонений теоретической кривой от реальных данных была минимальной
или
Возьмем частные производные Q по параметрам a и b и приравняем их нулю
Задание 3 Выберите из таблицы временной ряд в соответствии с номером Вашего варианта (по последней цифре шифра зачетной книжки)
1. Рассчитать показатели динамики – абсолютный прирост, коэффициент роста, коэффициент прироста (цепные и базисные). 2. Найти средний абсолютный прирост и средний коэффициент роста. 3. Подобрать линейную зависимость вида 4. Сделать прогноз показателя по математической модели тренда на 3 года вперед.
Задание 4. Результаты моментного наблюдения за поведением покупателей в магазине самообслуживания приведены в таблице.
1 − ищут нужный отдел; 2 − подходят к прилавку; 3 − изучают ассортимент товаров и их цены; 4 − выбирают необходимый товар; 5 − переносят товар к кассе; 6 − оплачивают товар; 7 − выходят из магазина. Найти выборочную долю покупателей, которые в момент обследования совершают действие, которое указано в таблице в соответствии с номером варианта задания.
и предельную ошибку для оценки доли в генеральной совокупности с доверительной вероятностью Р = 0, 95.
9. КОРРЕЛЯЦИОННЫЙ И РЕГРЕССИОННЫЙ АНАЛИЗ Во многих науках (физика, экономика и т. д.) используются модели, в которых некоторые переменные (не случайные) связаны функциональной зависимостью. Примером таких зависимостей является закон Бойля-Мариотта или формула Ф. Котлера. При статистической зависимости переменные (случайные величины) не связаны функционально. Однако закон распределения одной из них зависит от того, какое значение приняла другая случайная величина. Поэтому речь идет об условном распределении Y при заданном х. В частности, можно рассматривать M(Y/x) как некоторую функцию х (регрессия). При исследовании статистической зависимости между признаками пытаются ответить на следующие вопросы: - существует ли статистическая связь между признаками; - какова степень этой связи; - какова форма связи. Первые два вопроса решаются на основании корреляционного анализа. В качестве меры тесноты связи обычно используется коэффициент корреляции - Выборочный коэффициент корреляции r рассчитывается по формуле
где
n – число наблюдений (объем выборки). На практике используются следующие формулы для «ручных» вычислений
После того, как вычислен выборочный коэффициент корреляции r следует проверить гипотезу об отсутствии корреляционной связи для генеральной совокупности Н0: Для этого вычисляется критерий
и сравнивается с табличным значением Если Для измерения тесноты связи используется не только коэффициент корреляции, но и корреляционное отношение. Рассмотрим аналитическую группировку. Имеет место следующее соотношение
где
Внутригрупповая дисперсия характеризует ту часть дисперсии признака-результата, которая не зависит от признака-фактора. Ее оценка определяется по формуле
где группы по признаку-фактору; ni – численность i-й группы. Межгрупповая дисперсия отражает ту часть общей дисперсии признака-результата, которая объясняется влиянием признака-фактора. Ее оценка определяется по формуле
где Коэффициент детерминации определяет долю объясненной дисперсии в общей дисперсии признака-результата
Корреляционное отношение определяется как
Оно является мерой тесноты связи при любой форме зависимости, а не только линейной, как коэффициент корреляции.
Парная линейная регрессия
Следующий этап исследования корреляционной связи заключается в том, чтобы описать зависимость признака-результата от признака-фактора некоторым аналитическим выражением.
где Если рассчитан коэффициент корреляции r, то коэффициенты a0 и a1 могут быть определены следующим образом
В общем случае такая задача может решаться с помощью метода наименьших квадратов (МНК). Рассмотрим использование метода наименьших квадратов для оценки параметров регрессии На практике имеется серия наблюдений (xi; yi) (i=1,.., n). Будем считать, что
Тогда
Продифференцировав Q по a0 и a1 и приравняв частные производные нулю, получим следующую систему уравнений
решая которую получим оценки
Основное назначение регрессионной модели – использование ее для прогноза экономического показателя y. Прогноз осуществляется подстановкой значения фактора
Чтобы определить точность этой оценки и построить доверительный интервал необходимо найти дисперсию оценки На практике для оценки дисперсии ошибки прогноза можно пользоваться следующим выражением
Из этого выражения следует, что с ростом Пример. Исследуем зависимость розничного товарооборота магазинов (млрд р.) от среднесписочного числа работников. Обозначим: x – число работников; y – товарооборот. Исходные данные и результаты расчетов приведены в таблице
Вычислим выборочный коэффициент корреляции:
Тогда
Проверим значимость выборочного коэффициента корреляции. Для этого вычислим статистику t:
Табличное значение критерия Стьюдента для
Так как 15, 65 > 2, 45, то полученный коэффициент статистически значим. Найдем коэффициенты парной линейной регрессии:
и регрессия имеет вид
Прогнозное значение розничного товарооборота при
Задание 5. С помощью корреляционного и регрессионного анализа изучить связь между показателями, указанными в Вашем варианте. 1. Рассчитать значение коэффициента корреляции для несгруппированных данных табл. 1. 2. По данным аналитической группировки (задание 1) найти межгрупповую дисперсию признака-результата и с учетом полной дисперсии (задание 2) определить коэффициент детерминации и корреляционное отношение. 1. Сделать вывод о тесноте и форме статистической связи. 2. Найти коэффициенты парной линейной регрессии и сделать прогноз признака-результата, если признак-фактор принимает свое среднее значение. 3. На одном рисунке изобразить эмпирическую (по данным аналитической группировки) и теоретическую регрессии. Провести анализ степени их совпадения.
Задание 6. 1. Данные о количестве проданных товаров и ценах в базисном и текущем периодах приведены в таблице
На основании вышеприведенных данных вычислить: 1) Индивидуальные индексы цен и физического объема. 2) Агрегатные индексы товарооборота, цен и физического объема.
2. Данные о реализации фруктов и овощей на рынках города приведены в таблице
На основании приведенных данных вычислите: 1) Индивидуальные индексы физического объема 2) Агрегатный индекс физического объема 3) Агрегатный индекс товарооборота 4) На основании агрегатных индексов товарооборота и физического объема найти агрегатный индекс цен.
3. Данные о реализации товаров в универсаме приведены в таблице
На основании приведенных данных вычислите: 1) Индивидуальные индексы цен 2) Агрегатный индекс цен 3) Агрегатный индекс товарооборота 4) На основании агрегатных индексов товарооборота и цен найти агрегатный индекс физического объема.
БИБЛИОГРАФИЧЕСКИЙ СПИСОК
1. Елисеева. И. И., Общая теория статистики: учебник / И. И. Елисеева, М. М. Юзбашев. под ред. И. И. Елисеевой. – 5-е изд. - М.: Финансы и статистика, 2006. – 656 с. 2. Теория статистики: учебник /Под ред. Г. Л. Громыко. – 2-е изд. – М.: ИНФРА-М, 2005. – 476 с. 3. Эконометрика: Учебник /Под ред. И. И. Елисеевой.- 2-е изд. – М.: Финансы и статистика, 2005.- 576 с. 4. Кремер Н. Ш.. Путко Б. А. Эконометрика: Учебник.- 2-е изд. – М.: ЮНИТИ-ДАНА, 2008.- 311 с. Популярное:
|
Последнее изменение этой страницы: 2016-08-24; Просмотров: 1019; Нарушение авторского права страницы
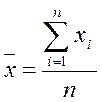 ,
, 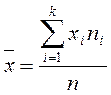 ,
,  варианта или середина интервала i-й группы;
варианта или середина интервала i-й группы; 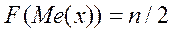 .
. ,
, 

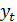 - значение временного ряда в интервале t;
- значение временного ряда в интервале t; 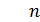 – число уровней временного ряда.
– число уровней временного ряда.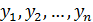 соответсвуют моментам наблюдения
соответсвуют моментам наблюдения 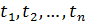 . Исследуемая величина изменяется в период между наблюдениями, поэтому средний уровень моментного ряда может быть оценен лишь приближенно. Для этой цели используется среднее хронологическое
. Исследуемая величина изменяется в период между наблюдениями, поэтому средний уровень моментного ряда может быть оценен лишь приближенно. Для этой цели используется среднее хронологическое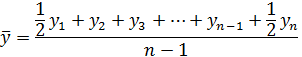
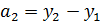 ,
,  ,
,  , …
, …  (цепные приросты).
(цепные приросты). равен
равен

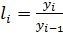 (i=2, …, n) – цепные коэффициенты роста.
(i=2, …, n) – цепные коэффициенты роста.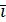 равен
равен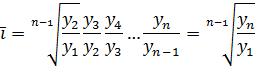
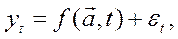
 , t) – регулярная составляющая (тренд, основная тенденция);
, t) – регулярная составляющая (тренд, основная тенденция);  средними арифметическими-
средними арифметическими- 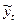 за определенный интервал (окно сглаживания), длина которого определена заранее. При этом сам выбранный интервал времени «скользит» вдоль ряда.
за определенный интервал (окно сглаживания), длина которого определена заранее. При этом сам выбранный интервал времени «скользит» вдоль ряда.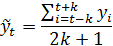

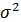 , то разброс средней из 2к+1 членов временного ряда около того же значения m будет характеризоваться существенно меньшей величиной дисперсии, равной
, то разброс средней из 2к+1 членов временного ряда около того же значения m будет характеризоваться существенно меньшей величиной дисперсии, равной 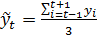
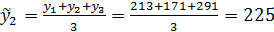 ,
,  и т.д.
и т.д.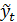
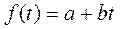 т. е.
т. е.  . (1)
. (1)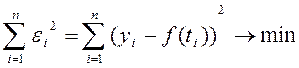 (2)
(2)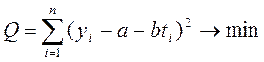 . (2а)
. (2а)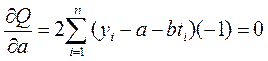 , (3)
, (3)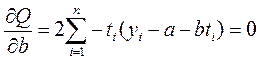 .
.
 . Найти оценки коэффициентов
. Найти оценки коэффициентов  и
и  по методу наименьших квадратов.
по методу наименьших квадратов.
 . При
. При  связь становится функциональной.
связь становится функциональной. .
. - значение случайной величины X для i-го наблюдения (объекта);
- значение случайной величины X для i-го наблюдения (объекта);  - значение случайной величины Y для i-го наблюдения (объекта);
- значение случайной величины Y для i-го наблюдения (объекта); 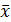 ,
,  - выборочные средние значения случайных величин X и Y;
- выборочные средние значения случайных величин X и Y;  ;
;  ;
;  .
. .
.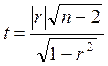
 критерия Стьюдента с
критерия Стьюдента с  степенями свободы уровня значимости
степенями свободы уровня значимости  .
. , то с надежностью
, то с надежностью  можно отвергнуть гипотезу Н0 и считать, что корреляция имеется.
можно отвергнуть гипотезу Н0 и считать, что корреляция имеется.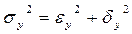 ,
,  − полная дисперсия признака-результата;
− полная дисперсия признака-результата;  − внутригрупповая дисперсия;
− внутригрупповая дисперсия;  − межгрупповая дисперсия.
− межгрупповая дисперсия. ,
,  - оценка дисперсии признака – результата в пределах отдельной
- оценка дисперсии признака – результата в пределах отдельной ,
,  − групповое среднее i-й группы.
− групповое среднее i-й группы. .
. .
.
 ,
,  − средний уровень показателя Y при данном значении x.
− средний уровень показателя Y при данном значении x. ,
,  .
. .
. .
. ;
;  ,
,  и
и 
 ,
,  .
. в оценку детерминированной составляющей:
в оценку детерминированной составляющей: 
 .
. .
. дисперсия ошибки прогноза увеличивается.
дисперсия ошибки прогноза увеличивается.




 ;
; 
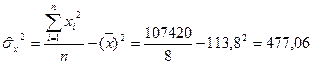 ;
;  ;
;  ;
; 
 ;
;  ;
;  .
.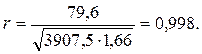

 = n-2 = 6 и
= n-2 = 6 и 

 ;
; 
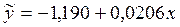 .
. составит
составит