|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Жизненный цикл ИО, проектирование ИОСтр 1 из 12Следующая ⇒
Общие понятия ИО
Предметом настоящего курса являются информационные системы, базы данных и системы управления базами данных. Это очень важная область, определяющая характер революции в информационных системах. С начала развития вычислительной техники образовались два основных направления ее использования. Первое направление – применение вычислительной техники для выполнения численных расчетов, которые слишком долго или вообще невозможно производить вручную. Становление этого направления способствовало интенсификации методов численного решения сложных математических задач, развитию класса языков программирования, ориентированных на удобную запись численных алгоритмов, становлению обратной связи с разработчиками новых архитектур ЭВМ. Второе направление – это использование средств вычислительной техники в автоматических или автоматизированных информационных системах. В самом широком смысле информационная система представляет собой программный комплекс, предназначенный для надежного хранения информации, выполнения специфических для данного приложения преобразований информации и вычислений, предоставлении пользователям удобного и легко осваиваемого (дружелюбного) интерфейса. Обычно объемы информации, с которыми приходится иметь дело таким системам, достаточно велики, а сама информация имеет достаточно сложную структуру. Классическими примерами информационных систем в гражданской сфере являются банковские системы, системы резервирования авиационных или железнодорожных билетов, мест в гостиницах и т.д. Для обеспечения гибкости использования данных необходимо учитывать два аспекта разработки баз данных: - во-первых, данные должны быть независимы от использующих их программ, чтобы данные можно было добавлять или перестраивать без изменения программ; - во-вторых, должна быть обеспечена возможность запрашивать и отыскивать информацию в базе данных без трудоемкого написания программ на обычном языке программирования. Таким образом, проектирование баз данных основывается на вполне определенной системе положений – четко сформулированной концепции. Информационные системы – системы обработки данных о какой-либо предметной области со средствами накопления, хранения, обновления, поиска и выдачи данных. Данные - информация (факты и идеи), представленная в формализованном виде, позволяющем передавать или обрабатывать ее при помощи некоторого процесса (и соответствующих технических средств). Информационное обеспечение – совокупность данных и средств работы с ними, предназначенных для поддержки какого-либо вида деятельности или функционирования какого-либо объекта. Для работы с хранимыми данными существуют две основные формы: Файловые системы (ФС) Виды взаимосвязей данных и программ: 1. Программа и данные в одной куче.
2. Данные как попало (отдельно от программы)
3.
Файловая система – набор прикладных программ (приложений), выполняющих обработку данных, каждая из которых самостоятельно хранит свои собственные данные и управляет ими. Недостатки: – несовместимость форматов – изолированность и разделенность данных – дублирование данных – фиксированный набор запросов – проблемы с размерами полей Системы, использующие БД База данных (БД) - именованная совокупность данных, отображающих состояние объектов и их отношений в рассматриваемой предметной области. Организуется так, что данные собираются однажды и централизованно хранятся (и модифицируются) в виде, доступном всем специалистам или системам программирования, которые могут их использовать. Системы, использующие БД, можно разделить на информационные системы и информационные подсистемы. Информационная система для пользователя автономна, существует интерактивный интерфейс. Информационная подсистема – одна из частей более глобальных системы. Обеспечивает информацией другие подсистемы.
В информационной системе реализуется интерфейс с человеком-пользователем. В подсистеме же реализуется программный интерфейс (API). Подсистема может быть дополнена интерфейсом с пользователем с целью модификации данных для дальнейшего автоматического использования. Одна из важных черт БД – независимость данных от особенностей прикладных программ, которые их используют, а также возможность создания этих программ в такой форме, что изменение особенностей хранения, логической структуры или значений данных не требует изменения программ их обработки. Другой важной чертой БД является возможность изменения физических особенностей хранения данных без изменения их логической структуры. Таким образом, приложение “не знает” форматы данных, все делает СУБД. Если не будут меняться форматы данных и т.д., если не будем использовать несколько программ, в этом случае лучше использовать ФС. СУБД же используется там, где необходима универсальность. Соответственно двум понятиям – «информация» и «данные» – в базах данных различают два аспекта рассмотрения вопросов: инфологический и даталогический. Инфологических аспект употребляется при рассмотрении вопросов, связанных со смысловым содержанием данных независимо от способов их представления в памяти системы. Даталогический аспект употребляется при рассмотрении вопросов представления данных в памяти информационной системы. Данные соответствуют зарегистрированным фактам об объектах реального мира. Чтобы в дальнейшем использовать эти данные, требуется их смысловое содержание – семантика данных. Поэтому в информационной системе должны быть сформулированы правила смысловой интерпретации данных. БД делятся: 1) по размещению: – локальные – на машине пользователя. Одна база, одна программа Плюсы: § Простой доступ к базе Минусы: § Однопользовательский режим § Простота несанкционированного доступа – интегрированные – для обслуживания группы пользователей в рамках подразделения, предприятия. Используется файл-серверная (клиент-серверная) организация. Плюсы: § Простота обмена информацией между пользователями § Возможность параллельной работы пользователей Минусы: § Необходимость повышения надежности, разрешения конфликтов между пользователями, разделение доступа к данным § Замедление в скорости получения данных – распределенные – база распределена по системе, но едина логически. Физически хранятся на удаленных компьютере для приближения данных к пользователю. Плюсы: § Увеличение скорости работы для локальных задач § Улучшение защиты от несанкционированного доступа Минусы: § Усложнение организации § Замедление решения глобальных задач 2) по виду модели данных: – иерархические – масса недостатков, устарела – сетевые – масса недостатков, устарела – реляционные – подавляющее большинство на сегодняшний день – постреляционные – начинают внедряться, расширяют возможности реляционных, добавляя расширение или используя объектно-ориентированный подход. Система управления базами данных – совокупность языковых и программных средств, предназначенных для создания, ведения и конкурентного использования базы данных многими пользователями. Создание и применение СУБД призвано к максимальному удовлетворению требований, предъявляемых к эффективным базам данных. Это приводит к необходимости решения вопроса централизованного управления данными. Специальные средства СУБД обеспечивают секретность данных, т.е. защиту данных от неправомочного воздействия, и целостность данных – защиту от непредсказуемого взаимодействия конкурирующих процессов, приводящих к случайному или преднамеренному разрушению данных, а также от отказов оборудования. Операции, выполняемые СУБД: – работа с данными (выборка, добавление, изменение и т.д.) – служебные операции с данными (защита от несанкционированного доступа, защита от конфликтов многопользовательского доступа, восстановление и резервирование данных, архивирование и т.д.) СУБД разделяются: 1) по размещению: – персональные – размещаются на компьютере пользователя, и обслуживают только его. – серверные – размещаются на серверах и обслуживают несколько пользователей. 2) по виду моделей: так же, как и для БД, то есть: – иерархические – масса недостатков, устарела – сетевые – масса недостатков, устарела – реляционные – подавляющее большинство на сегодняшний день – объектные – считаются прогрессивными. Приложение – разрабатывается под конкретную задачу. Программа и СУБД – это программное обеспечение, но СУБД – это универсальная программа. ИС отличаются по архитектуре ПО. Все ПО можно разделить на три основные компоненты: - компонент представления (П). - компонент обработки (О). - компонент доступа (Д) – поддержка операций работы с БД. В зависимости от размещения программного обеспечения различаются несколько моделей информационных систем:
1. Локальная модель системы. Все находится на одном компьютере пользователя. Плюс: все данные на одном компьютере, следовательно, быстрота работы. Минус: однопользовательский режим доступа. 2. FS – файл-серверная модель. Особенности: - обеспечение одновременного доступа, следовательно, блокировка данных на время работы с ними. - ПО на машине клиента, следовательно, все компьютеры должны быть мощными. - сервер – просто хранилище информации, следовательно, трудность с типовыми операциями (поиск, изменение данных), загруженность сети. 3. RDA - Модель удаленного доступа к данным. На сервере находятся данные и ПО. 4. DBS - Сервер БД. Кроме стандартных команд обращений к базе на сервере выполняется обработка по произвольному коду в виде триггеров или процедур. 5. Main frame – все на сервере, у пользователя только дисплей. 6. AS – модель серверного приложения. Имеется два сервера: сервер СУБД и доступов к ней, сервер с приложением.
Структуры 3, 4, 6 попадают под архитектуру Клиент-сервер. При выполнении основных функций СУБД должна использовать различные описания данных. Очевидно, что в таких описаниях обязательно должны быть учтены: § сущности интересующей предметной области; § атрибуты, характеризующие неотъемлемые свойства каждой сущности; § связи, ассоциирующие выделенные сущности. С самых общих позиций, в архитектуре современных СУБД выделяют три уровня абстракции, т.е. три уровня описания элементов хранимых данных. Эти уровни составляют трехуровневую архитектуру, представленную на рис. 1.2, которая охватывает внешний, концептуальный и внутренний уровни. Данный подход к описанию данных предложен комитетом ANSI/SPARC (Комитет Планирования Стандартов и Норм Национального Института Стандартизации США). Такое отделение обеспечивает независимость хранимых данных.
Рис. 1.2. Трехуровневая архитектура ANSI/SPARC Внешний уровень – представление базы данных с точки зрения конкретных пользователей. Указанный уровень может включать несколько различных представлений БД со стороны различных групп пользователей. При этом каждый пользователь имеет дело с представлением предметной области, выраженным в наиболее понятной и удобной для него форме. Такое представление содержит только те сущности, атрибуты и связи, которые интересны ему при решении профессиональных задач. На внешнем уровне создается инфологическая модель БД (внешняя схема), полностью независимая от платформы (т.е. вычислительной системы, на которой будет использоваться). Инфологическая модель является человеко-ориентированной: средой ее хранения может быть память человека, а не ЭВМ. Концептуальный уровень – обобщающее представление базы данных, описывающее то, какие данные хранятся в БД, а также связи, существующие между ними. Концептуальный уровень является промежуточным в трехуровневой архитектуре. Содержит логическую структуру всей базы данных. Фактически, это полное представление требований к данным со стороны организации, которое не зависит от соображений относительно способа их хранения. На концептуальном уровне необходимо выделить: § сущности, их атрибуты и связи; § ограничения, накладываемые на данные; § семантическую информацию о данных; § информацию о мерах обеспечения безопасности. На концептуальном уровне создается даталогическая модель (концептуальная схема БД), представляющая собой описание инфологической модели (внешней схемы) на языке определения данных конкретной СУБД. Эта модель является компьютеро-ориентированной (зависит от применяемой на компьютере СУБД). Внутренний уровень – физическое представление базы данных, описывающее методы их хранения в вычислительной системе. Данный уровень описывает физическую реализацию базы данных и предназначен для достижения оптимальной производительности и обеспечения экономного использования дискового пространства. Содержит описания структур данных и отдельных файлов, используемых для хранения данных в запоминающих устройствах. На внутреннем уровне осуществляется взаимодействие СУБД с методами доступа операционной системы с целью эффективного размещения данных на носителях, создания индексов и т.д. Реализация перечисленного производится на физическом уровне вычислительной системы, который контролируется операционной системой. В настоящее время функции СУБД и операционной системы на физическом уровне строго не разграничиваются. В одних СУБД используются все предусмотренные в данной операционной системе методы доступа, в других применяются только основные и реализована собственная файловая система. На внутреннем уровне создается физическая модель БД (внутренняя схема), которая также является компьютеро-ориентированной (зависит от СУБД и операционной системы). С ее помощью СУБД дает возможность программам и пользователям осуществлять доступ к хранимым данным по именам, не заботясь об их физическом расположении. По этой модели СУБД отыскивает необходимые данные на внешних запоминающих устройствах.
Достоинства СУБД § Контроль за избыточностью данных. § Непротиворечивость данных. § Больше полезной информации при том же объеме хранимых данных. § Совместное использование данных. § Поддержка целостности данных. § Повышенная безопасность. § Возможность нахождения компромисса при противоречивых требованиях. § Повышение доступности данных. § Улучшение показателей производительности. § Упрощение сопровождения системы за счет независимости данных. § Улучшенное управление параллельностью. § Развитые службы резервного копирования и восстановления. СУБД призваны решить недостатки файловых систем, но при этом имеют и ряд специфических недостатков. Недостатки СУБД § Сложность. § Размер. § Стоимость. § Производительность. § Серьезные последствия при выходе системы из строя.
ER-диаграммы. Сущность Сущность представляет собой различимое множество объектов {экземпляров сущности) реального мира с одинаковым набором атрибутов. Иными словами, сущность описывает некоторый тип объекта, характеризующийся определенным набором свойств.
Сущность идентифицируется именем и списком свойств (атрибутов). База данных о сколько-нибудь значительной предметной области содержит много (несколько) сущностей. Каждый экземпляр сущности обладает уникальным набором значений атрибутов. На ER-диаграммах сущность представляется прямоугольником с именем сущности внутри.
Наименование - существительное в единственном числе, возможно расширенное прилагательным или дополнением. Атрибут Атрибут – неотъемлемое свойство сущности или связи. Именно по значениям атрибутов можно идентифицировать экземпляр сущности. Значения атрибутов представляют основную часть сведений, хранящихся в БД. На ER-диаграммах атрибут представляется овалом (эллипсом), соединенным с соответствующей сущностью линией и с именем атрибута внутри.
Наименование - существительное в единственном числе, возможно расширенное прилагательным или дополнением. Атрибуты связываются с сущностью. Обозначение связи зависит от вида свойства. Атрибуты делятся на: § простые; § составные; § однозначные; § многозначные; § условные; § безусловные § производные. Простой атрибут состоит из одного компонента с независимым существованием. Составной атрибут состоит из нескольких компонентов, каждый из которых характеризуется независимым существованием.
На рисунке: " Дата" – простой атрибут, " Ремонт" – составной. Однозначный (единичный) атрибут содержит одно значение для одного экземпляра сущности. Многозначный (множественный) атрибут может содержать несколько значений для одного экземпляра сущности. Множественное свойство позволяет сохранять набор значений.
На рисунке: " Дата" – однозначный атрибут, " Ремонт" – многозначный. Условные - могут отсутствовать у некоторых экземпляров сущностей. Безусловные – всегда имеющиеся у всех экземпляров сущностей.
На рисунке: " Дата ремонта" – условный атрибут, может присутствовать при условии положительного значения атрибута " Ремонтопригодность" (если последний есть). Производный атрибут представляет значение, производное (вычисляемое) от значения связанного с ним атрибута или некоторого множества атрибутов, принадлежащих некоторой сущности.
В предметной области сущности соответствует множество экземпляров. Все экземпляры имеют одинаковый набор атрибутов, но разное их значение. Вопрос однозначной идентификации экземпляров сущности связан с понятием ключа (идентификатора). Ключ – минимальный набор атрибутов, по значениям которых можно идентифицировать экземпляр сущности. Иными словами, ключ – одно или несколько свойств, по значениям которых все экземпляры различаются. В наборе атрибутов сущности можно выделить несколько потенциальных ключей. Потенциальный ключ, используемый реально для идентификации экземпляров сущности называется первичным ключом. На ER-диаграммах имена атрибутов, выбранных в качестве первичного ключа, подчеркиваются. Связь Связь – указывает связанность экземпляров двух типов объектов. Связи, также как и сущности и атрибуты, идентифицируют именем. На ER-диаграммах связь изображается в виде ромба или шестиугольника, помеченного соответствующим именем. Соединение с ассоциированными сущностями производится линиями. Пример ER-диаграммы с обозначениями сущностей, их атрибутов и связей представлен на рис. 2.3.
Рис. 2.3. Пример ER-диаграммы
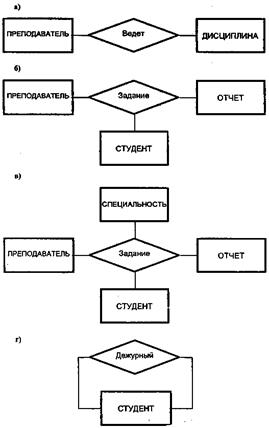
Степень связи – количество сущностей, которые охвачены данной связью. Если связь определена между двумя сущностями, то ее степень – 2, а называется такая связь бинарной. Связь между тремя сущностями называется тернарной, четырьмя сущностями – кватернарной и т.д. В общем случае связь между n сущностями называется n-арной (рис. 2.4). Рекурсивная связь – связь, в которой одни и те же сущности участвуют несколько раз в разных ролях. Рекурсивная связь часто называют унарной. Пример такой связи представлен на рис. 2.4, г. В приведенном примере каждый студент из сущности СТУДЕНТ может исполнять обязанности дежурного по отношению к другим студентам той же сущности.
Для указания вида связи отмечаются: Множественность
Возможны варианты: - один экземпляр сущности A связан с одним экземпляром сущности B (1: 1). Пример: Декан-Факультет; - один экземпляр сущности A связан со многими экземплярами сущности B (1: М). Пример: Квартира-Жилец; - многие экземпляры сущности A связаны со многими экземплярами сущности B (М: М). Пример: Преподаватель-Студент; Обязательность
Пример1: А – деканат, B – замдекана. Малый деканат может не иметь замдекана.
Пример 2: В большом деканате обязательно есть замдеканы.
Расширение нотаций Расширение нотаций ER-модели используется для отображения более сложного характера связей между сущностями. Простые сущности содержат только атрибуты, сложные - другие сущности. 1) Составная сущность: описывается не одной, а несколькими сущностями. Главная обозначает целое, прочие - части объекта. Отражает отношение целого и части. Пример: винчестер – часть компьютера.
2) Обобщенная сущность – отражает отношение, род, вид. Пример: сущность " студент" может подразделяться на виды: " бюджетники" и " ПВЗ".
3) Ассоциация определяет отношение: объект - действия. Расширяет возможности связи: а) Позволяет задать для связи дополнительную информацию. Пример: связь " тест" определена между сущностями " вопросы" и " тестируемые". Связь может иметь свойства: дата, оценка…
б) Соединение трех или более типов
в) Используется для реализации отношения " многих ко многим".
К графическому изображению ER-модели добавляется текстовое описание: 1) описание сущности, свойств, связи. 2) описание ограничения целостности. 3) описание алгоритмических связей (например, вычисляемые поля). 4) описание информационных запросов.
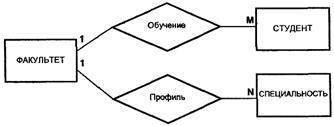
Проблемы ER-моделирования В процессе создания инфологической модели на языке ER-диаграмм, могут возникать нежелательные ситуации, которые в литературе называются ловушками соединения. Причины этих проблем кроются в неправильной интерпретации семантики предметной области, в том числе смысла некоторых связей между выделенными сущностями. Наиболее распространенными являются два вида ловушек соединения: § ловушки разветвления; § ловушки разрыва. Ловушка разветвления имеет место в том случае, если модель отображает связь между сущностями, но путь между отдельными экземплярами этих сущностей однозначно не определяется. Возникает в случае, когда две или больше связей ОДИН-КО-МНОГИМ разветвляются из одной сущности. Потенциальная ловушка разветвления показана на рис. 2.11, где две связи типа 1: М выходят из одной и той же сущности ФАКУЛЬТЕТ. Проблема может возникнуть при попытке выяснить, по какой специальности обучается каждый из студентов факультета.
Рис. 2.11. Пример ловушки разветвления
Устранить такой дефект можно только путем перестройки исходной модели. Результат адекватного преобразования модели представлен на рис. 2.13.
Рис. 2.13. Преобразованная ER-модель
Ловушка разрыва появляется в том случае, если в модели предполагается наличие связи между сущностями, но не существует пути между отдельными экземплярами этих сущностей. Возникает при неправильной интерпретации связей между сущностями На рис. 2.15 потенциальная ловушка разрыва показана на примере связей между сущностями ОБЩЕЖИТИЕ, СТУДЕНТ и КОМНАТА.
Рис. 2.15. Пример ловушки разрыва
ER-модель на рис. 2.15 не даёт возможность получить ответ на вопрос: «В каком общежитии находится комната под заданным номером». Устранить эту проблему можно только путем перестройки ER-модели для представления правильного взаимоотношения между сущностями. Преобразованная ER-модель показана на рис. 2.16. В модель добавлена связь Размещение между сущностями ОБЩЕЖИТИЕ и КОМНАТА.
Рис. 2.16. Преобразованная ER-модель
Логические модели данных. Сетевая модель данных Строится по рекомендациям CODASYL (конференция по символьным языкам). С точки зрения теории графов сетевой модели соответствует произвольный граф (возможно имеющий циклы и петли). В узлах графа помещаются типы записей, а ребра интерпретируются как связи между типами записей. ─ Модель не накладывает ограничения на связи. ─ Узлы сети описывают типы объектов. ─ Дуги – связи между экземплярами разных типов. В описании базы включается множество описаний типов, множество описаний связей. Сетевая БД состоит из набора записей и набора связей между этими записями, а если говорить более точно, из набора экземпляров каждого типа из заданного в схеме БД набора типов записи и набора экземпляров каждого типа из заданного набора типов связи. Тип связи определяется для двух типов записи: предка и потомка. Экземпляр типа связи состоит из одного экземпляра типа записи предка и упорядоченного набора экземпляров типа записи потомка.
Для описания типа о писывается структура записи этого типа. Структура может быть линейной:
По минимуму надо хранить: имя, тип и размерность. Описание связок: Связь описывается набором. Описание набора содержит указание типа владельца набора, указание типа члена набора, описание характеристик связи.
Важный элемент описания связи – класс членства. Указывается для подчиненного типа. Для главного типа – указание связи не обязательно. Три класса членства: 1) Не обязательное членство: подчиненная запись не обязана иметь владельца. 2) Обязательное членство: подчиненная запись обязана иметь владельца, но может его сменить. 3) Фиксированное членство: подчиненная запись обязана иметь владельца и не может его сменить. По соединениям типов разрешается: 1) множественное владение:
2) множественное членство:
3) множественное связывание двух:
4) рекурсивная (петлевая) связь:
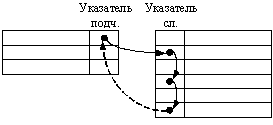
По соединениям типов НЕ разрешается: 1) Отношение " многие ко многим". 2) Включение экземпляра в несколько связей из одного набора. Связывание реализуется с помощью физических указателей: Основной вариант – кольцо:
Сетевая модель базы при выборке работает медленнее, чем реляционная.
Пример: Найти сотрудника Иванова и найти его отпуска. Достоинства сетевой модели: ─ высокое быстродействие ─ компактность Недостатки: ─ низкая надежность за счет возможности потери указателей. ─ " позаписная" работа, т.е. привыборке последовательно просматриваются все записи. ─ невозможность оперативной работы, т.е. сетевая модель способна отвечать только на заранее запрограммированные запросы
Операции сетевой модели 1) операции с данными: ─ удалить ─ добавить ─ изменить 2) операции со связями: ─ подключить ─ отключить ─ переключить 3) навигация по данным: ─ переход на подчиненную ─ возможность перехода на следующую подчиненную ─ переход на владельца Отличие сетевой структуры от иерархической заключается в том, что каждый элемент в сетевой структуре может быть связан с любым другим элементом (см. рис. 2.3). Пример простой сетевой структуры показан на рис. 2.4.
Достоинствомсетевой модели данных является возможность эффективной реализации по показателям затрат памяти и оперативности. Недостаткомсетевой модели данных являются высокая сложность и жесткость схемы БД, построенной на ее основе. Наиболее известными сетевыми СУБД являются IDMS, db_VistaIII, СЕТЬ, СЕТОР и КОМПАС. Простой пример сетевой схемы БД приведен на рис. 2.22.
Рис. 2.22. Пример схемы сетевой БД
Примерный набор операций при использовании сетевой модели может быть следующим [8]. § Найти конкретную запись в наборе однотипных записей (инженера Петрова). § Перейти от предка к первому потомку по некою рой связи (к первому сотруднику отдела 42). § Перейти к следующему потомку в некоторой связи (от Петрова к Иванову). § Перейти от потомка к предку по некоторой связи (найти отдел Петрова). § Создать новую запись. § Уничтожить запись. § Модифицировать запись. § Включить в связь. § Исключить из связи. § Переставить в другую связь и т.д.
Иерархическая модель данных Является частным случаем сетевой модели. Иерархическая БД состоит из упорядоченного набора деревьев; более точно, из упорядоченного набора нескольких экземпляров одного типа дерева. Тип дерева состоит из одного «корневого» типа записи и упорядоченного набора из нуля или более типов поддеревьев (каждое из которых является некоторым типом дерева). Тип дерева в целом представляет собой иерархически организованный набор типов записи
.
Пример типа дерева (схемы иерархической БД) представлен на рис. 2.19.
Рис. 2.19. Пример схемы иерархической БД
На рис. 2.19 ОТДЕЛ является предком для НАЧАЛЬНИК и СОТРУДНИКИ, а НАЧАЛЬНИК и СОТРУДНИКИ - потомки ОТДЕЛ. Между типами записи поддерживаются связи.
Для учета общих данных выполняется связывание деревьев: ─ в одном дереве храниться оригинал ─ в других – копии, содержащие ссылки на оригинал При удалении записей подчиненные записи удаляются каскадно, по связкам:
Виды членства: Класс членства всегда фиксирован. При удалении – каскадирование. Все экземпляры данного типа потомка с общим экземпляром типа предка называются близнецами. Для БД определен полный порядок обхода - сверху-вниз, слева-направо. Примерами типичных операторов манипулирования иерархически организованными данными могут быть следующие. § Найти указанное дерево БД (например, отдел 42, рис.2.19). § Перейти от одного дерева к другому. § Перейти от одной записи к другой внутри дерева (например, от отдела – к первому сотруднику). § Перейти от одной записи к другой в порядке обхода иерархии. § Вставить новую запись в указанную позицию. § Удалить текущую запись. Автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя. Иерархическая структура реализует отношение ОДИН-КО-МНОГИМ между исходным и порожденным типами записей. Это отображение полностью функционально, т.к. дерево не может содержать порожденный узел без исходного узла (за исключением «корня»). Однако для представления отображения МНОГИЕ-КО-МНОГИМ необходимо дублирование деревьев, а значит, реализация сложных связей требует больших затрат памяти. Другой проблемой иерархий является невозможность хранения в БД порожденного узла без соответствующего исходного, т.е. в этом случае необходимо ввести пустой исходный узел. Соответственно удаление данного исходного узла влечет удаление всех порожденных узлов (поддеревьев), связанных в ним. Эти ограничения создают проблемы применения иерархической модели для некоторых приложений. Достоинством иерархической структуры является компактность. Она имеет максимальные характеристики по объёму памяти и быстродействию.
Реляционная модель данных В конце 60-х годов появились работы, в которых обсуждались возможности применения различных табличных даталогических моделей данных, т.е. возможности использования привычных и естественных способов представления данных. Будучи математиком по образованию, сотрудник фирмы IBM доктор Э. Кодд предложил использовать для обработки данных аппарат теории множеств (объединение, пересечение, разность, декартово произведение). Он показал, что любое представление данных сводится к совокупности двумерных таблиц особого вида, известного в математике как отношение – relation (англ.). Реляционное исчисление Исчисление задает не последовательность обработки, а требовательность к результату. Упрощенный вариант формулы реляционного исчисления:
Целевой список – указывает состав выходных результатов. Область определения – набор отношений, в которых выполняется отбор. Условие – требование получаемого результата. Пример:
Первый вариант решения задачи:
Второй вариант решения задачи:
Нормализация отношений Популярное:
|
Последнее изменение этой страницы: 2017-03-03; Просмотров: 815; Нарушение авторского права страницы



















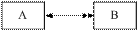

















 Структура – дерево.
Структура – дерево.