
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
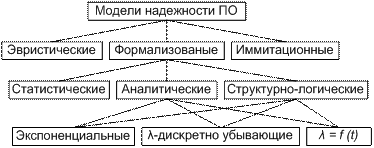
Классификация моделей надежности ПО
Экспоненциальная модель (модель Шумана) Вводится ряд допущений и условий, основным из которых является условие существования программы исследователя системы. Остальные допущения и условия не связаны с какими-то специфическими свойствами ПО. Условия сводятся к следующему:
I – общее число машинных команд. 2. Предполагается, что значение функции частоты или интенсивности отказов
C – коэффициент пропорциональности.
Для нахождения С и Е используются принцип максимального правдоподобия (пропорция). Модель Джелинского-Моранда Модель с дискретным убыванием интенсивности отказов. В этой модели предполагается, что интенсивность ошибок описывается кусочно-постоянной функцией, пропорциональной числу не устраненных ошибок. Т.е. предполагается, что интенсивность отказов
M – неизвестное первоначальное число ошибок i – число обнаруженных ошибок, зависящих от времени t k – константа Частота обнаружения i-ой ошибки
Значения неизвестных параметров k и M может быть оценено на основе последовательности наблюдений интервалов между моментами обнаружения ошибок по методу максимального правдоподобия. Статистическая модель Миллса Эту модель можно использовать для сертификации программных средств. В модели не используются предположения о поведении функции риска Сначала программа «засоряется» некоторым количеством известных ошибок. Эти ошибки вносятся в программу случайным образом, а затем делается предположение, что для ее собственных и внесенных ошибок вероятность обнаружения одинакова и зависит только от их количества. Тестируя программу в течении некоторого времени и отсортировывая собственные и внесенные ошибки можно оценить N – первоначальное число ошибок в программе. Предположим, что в программу было внесено S ошибок. Пусть при тестировании обнаружено (n+V) ошибок. n – число собственных ошибок V – число внесенных ошибок Тогда оценка для N по методу максимального правдоподобия будет следующей
В действительности N можно оценивать после каждой ошибки. Миллс предлагает во время всего периода тестирования отмечать на графике число найденных ошибок и текущие оценки для N. Вторая часть модели связана с выдвижением и проверкой гипотез о N. Примем, что программе имеется не более k собственных ошибок и внесем в нее еще S ошибок. Теперь
С – мера доверия к модели – вероятность того, что модель будет правильно отклонять ложные предположения. Формулы для N и C образуют полезную модель ошибок. Минусы модели С нельзя предсказать до тех пор, пока не будут обнаружены все внесенные ошибки, это может не произойти до самого конца этапа тестирования. Модификация формулы для С, если не все ошибки обнаружены: j – найденные внесенные ошибки, j < S
Еще один график, который полезно строить во время тестирования – это текущее значение верхней границы k для некого доверительного уровня. Модель математически проста и интуитивно привлекательна. Легко представить программу внесения ошибок, которая случайным образом выбирает модуль и вносит логические ошибки, изменяя или убирая операторы. Природа внесения ошибок должна оставаться в тайне, но все их следует регистрировать с целью последующего деления на собственные и несобственные. Процесс внесения ошибок является самым слабым местом модели, поскольку предполагается, что для собственных и внесенных ошибок вероятность обнаружения одинакова, но неизвестна. Отсюда следует, что внесенные ошибки должны быть типичными, но на сегодня непонятно какими именно они должны быть. Однако по сравнению с проблемами других моделей эта проблема кажется не очень сложной и разрешимой. Популярное:
|
Последнее изменение этой страницы: 2017-03-08; Просмотров: 680; Нарушение авторского права страницы
 , которое включает затраты времени на выявление ошибок с помощью тестов, на контрольные проверки и т.д. При этом время исправного функционирования системы не учитывается. В течение времени
, которое включает затраты времени на выявление ошибок с помощью тестов, на контрольные проверки и т.д. При этом время исправного функционирования системы не учитывается. В течение времени  ошибок в расчете на одну команду машинного языка. Т.о. удельное число ошибок на одну машинную команду остающихся в системе после времени
ошибок в расчете на одну команду машинного языка. Т.о. удельное число ошибок на одну машинную команду остающихся в системе после времени 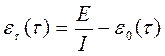
 пропорциональна числу ошибок, оставшихся в ПО после израсходования на отладку времени
пропорциональна числу ошибок, оставшихся в ПО после израсходования на отладку времени 
 Тогда, если время работы системы t отсчитывается от момента времени t0, а
Тогда, если время работы системы t отсчитывается от момента времени t0, а 
 постоянна до обнаружения и исправления ошибки, после чего она опять становится постоянной, но с другим, меньшим, значением. При этом предполагается, что между
постоянна до обнаружения и исправления ошибки, после чего она опять становится постоянной, но с другим, меньшим, значением. При этом предполагается, что между 
 задается соотношением
задается соотношением

 программа тестируется, пока не будут обнаружены все внесенные ошибки. Причем подсчитывается число обнаруженных собственных ошибок n. Уровень значимости С вычисляется по формуле
программа тестируется, пока не будут обнаружены все внесенные ошибки. Причем подсчитывается число обнаруженных собственных ошибок n. Уровень значимости С вычисляется по формуле
